注: 以下の翻訳の正確性は検証されていません。AIPを利用して英語版の原文から機械的に翻訳されたものです。
リソース割り当てと最適化
組織は毎日、どのようにリソースを割り当てるかを決定しています。これには、どの製品を生産するか、投資対効果を最大化するための EV 充電ステーションのポートフォリオを割り当てることや、輸送コストを節約するための出荷の統合を行うことが含まれます。
組織の運用現実をデジタルツインとして作成することで、Foundry は組織のデジタル表現を活用してリソース割り当ての意思決定を最適化します。
ソリューション
リソース割り当てと最適化は、制約条件の下で特定の目的を最大化または最小化する方法で利用可能なリソースを活用するタスクです。組織は、このような割り当てと最適化の問題をさまざまな形で抱えています。
リソース割り当てと最適化のワークフローでは、組織は関連するデータを収集、クリーニング、変換、モデル化して、最適な割り当ての意思決定ができるようにする必要があります。これは、新しい現実や変化する組織ダイナミクスに適応できない単一のデータソースを基にした専門的なソフトウェアを介して行われることが多いです。また、多数のスプレッドシートやデータベースにまたがる多数のデータソースの綿密な収集を通じて行われることもあります。これにより、以下のような問題が発生します。
- 割り当ての意思決定がアドホックで、大幅なリードタイムがかかり、反応性がない
- 不完全なデータによる最適でない意思決定
- 時間をかけて改善されないオープンループの意思決定:
- 意思決定の影響が測定されず、フォローアップされない
- モデリングの前提条件が検証されず、改善されない
Foundry を使用することで、組織は組織環境が進化するにつれて適応し、改善することができる、繰り返し可能でタイムリーな意思決定を可能にするクローズドループの割り当て最適化ワークフローを作成することができます。
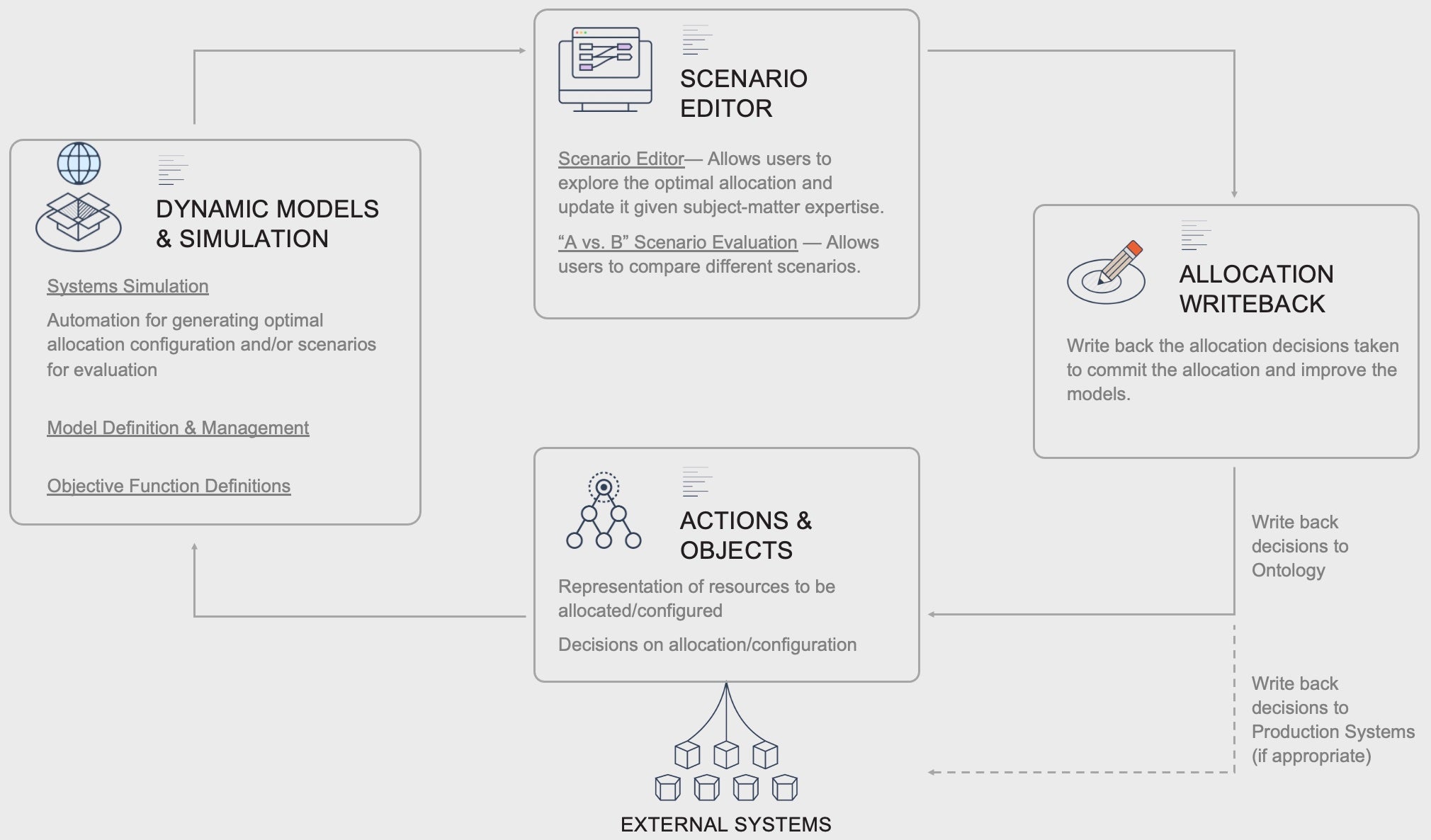
主要要素
アイデアと探索
まず、主題専門家が最大化または最小化すべき目的関数を特定し、関連するダイナミクスを特定し、システムとその制約を定義します。ソースシステムから収集および統合する必要がある関連データが特定されます。これは、Contour や Quiver を使ってデータを掘り下げ、何が可能かを理解する反復プロセスであることが多いです。
関連製品:
動的モデリングとシミュレーション
システムダイナミクス、目的関数、および制約は、Objects 上の Functions を通じて符号化されるか、Code Workbook で開発され、Foundry ML で管理される ML モデルを使って観察されることで学習されます。Foundry ML スイートは、機械学習、人工知能、統計、および数学モデルを Foundry エコシステムの主要コンポーネントと統合し、モデルを運用化し、時間をかけてパフォーマンスを監視することができます。
EV 充電ステーションの割り当て のユースケースでは、地理データ、財務データ、および潜在的な充電ステーションのポートフォリオの特徴が統合され、スコア化されます。
顧客は、Data Connection を介してそれらに接続することにより、サードパーティのシミュレーションおよび最適化ツールを活用することもできます。
関連製品:
シナリオ評価と最適化探索アプリケーション
シミュレーションされた最適な割り当て、シナリオ候補、または「What-If」シナリオは、自動化された Transform を通じて生成されます。最適な割り当てやシナリオの選択肢は、Workshop または Slate アプリケーションで構築されたノーコードからローコードのアプリケーションで探索および評価することができます。
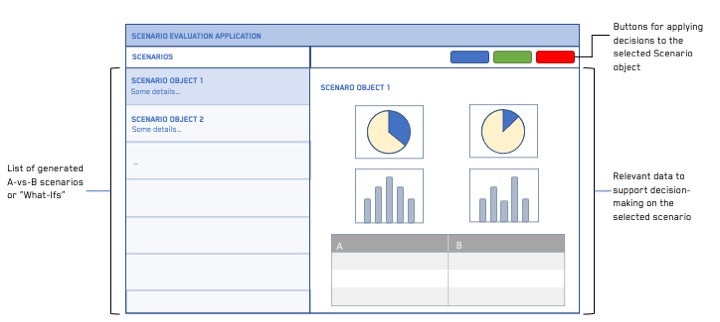
例えば、Load Utilization Improvement のユースケースでは、ユーザーは、輸送コストを節約するために出荷(トラック積載量)を統合する機会を提案されます。ロードプランナーは、自分が担当する出荷を含む潜在的な統合機会に関するオポチュニティダッシュボードを確認し、関連するステークホルダー(工場、顧客、運送業者など)に通知します。これらの機会は、追加の停車、予定の変更、工場や顧客の制約を考慮しています。ロードプランナーは、オポチュニティを承認、拒否、統合、または再割り当てします。
それぞれの意思決定が行われた文脈とともに割り当ての意思決定が書き戻されることで、予測された結果と実際の結果を時間をかけて比較および評価することができます。観察結果に基づく新しいモデルのトレーニングや、符号化されたダイナミクスの更新を通じて、モデルの精度を向上させ、意思決定を改善することができます。
関連製品:
要件
使用されるパターンに関係なく、基礎となるデータ基盤は、パイプラインと外部ソースシステムへの同期から構築されます。
データ統合パイプライン
データ統合パイプラインは、SQL、Python、Java などのさまざまな言語で記述され、主題専門家のオントロジーにデータソースを統合するために使用されます。
Foundry は、FTP、JDBC、REST API、S3 などの幅広いソースからデータを同期することができます。さまざまなソースからのデータの同期と、可能な限り最も完全な真実のソースのコンパイルは、最高の価値を持つ意思決定を可能にするための鍵です。
このパターンを実装するユースケース
- EV 充電ポイントの利益を統合された位置最適化を通じて向上させる
- サプライチェーン全体で ERP データを利用して生産を最適化する
- インテリジェントなメンテナンス優先順位付けを通じて鉄道の遅延を減らす
- コンテナの最適な利用により、出荷されるコンテナの数を減らす
このユースケースパターンに関する詳しい情報が欲しいですか? 似たようなものを実装したいですか? Palantir で始めましょう。↗