注: 以下の翻訳の正確性は検証されていません。AIPを利用して英語版の原文から機械的に翻訳されたものです。
調査とコホート分析
例えば、電力網のリスクを特定する、潜在的な不正を調査する、材料の利回りを改善する機会を特定する、次に最適な販売行動を見つけるなど、組織はそれらを探すためのツールがあれば、大きな収益またはコスト削減の機会が通常あります。調査とコホート分析のワークフローは、ユーザーが組織の共通の運用画像を作成し、専門知識とデータ分析を組み合わせて機会を明らかにし、現実の世界の解決策を実装することを可能にします。
ソリューション
調査とコホート分析のワークフローは、収益または節約の機会を代表するデータの実世界の異常または問題を理解し、グループ化し、問題の詳細を理解し、解決策を促進するように設計されています。これらは、問題を予測的に特定したり、関係を理解したりするために使用され、この中でコホート分析のロジックが分析家からの専門知識を指導し、異常を発見するために使用されます。データ量が増え続ける中で、複雑な統計アプリケーションを扱うための技術スキルが不足していると、分析家や組織がデータの複雑さを大幅に減らすことを余儀なくされることがよくあります。
これらのワークフローは、大規模で、しばしば孤立したデータ資産の迅速な分析と探索を可能にするツールセットがほぼ常に必要です。その結果は、保存され再利用される必要があり、通常は再現可能である必要があります。
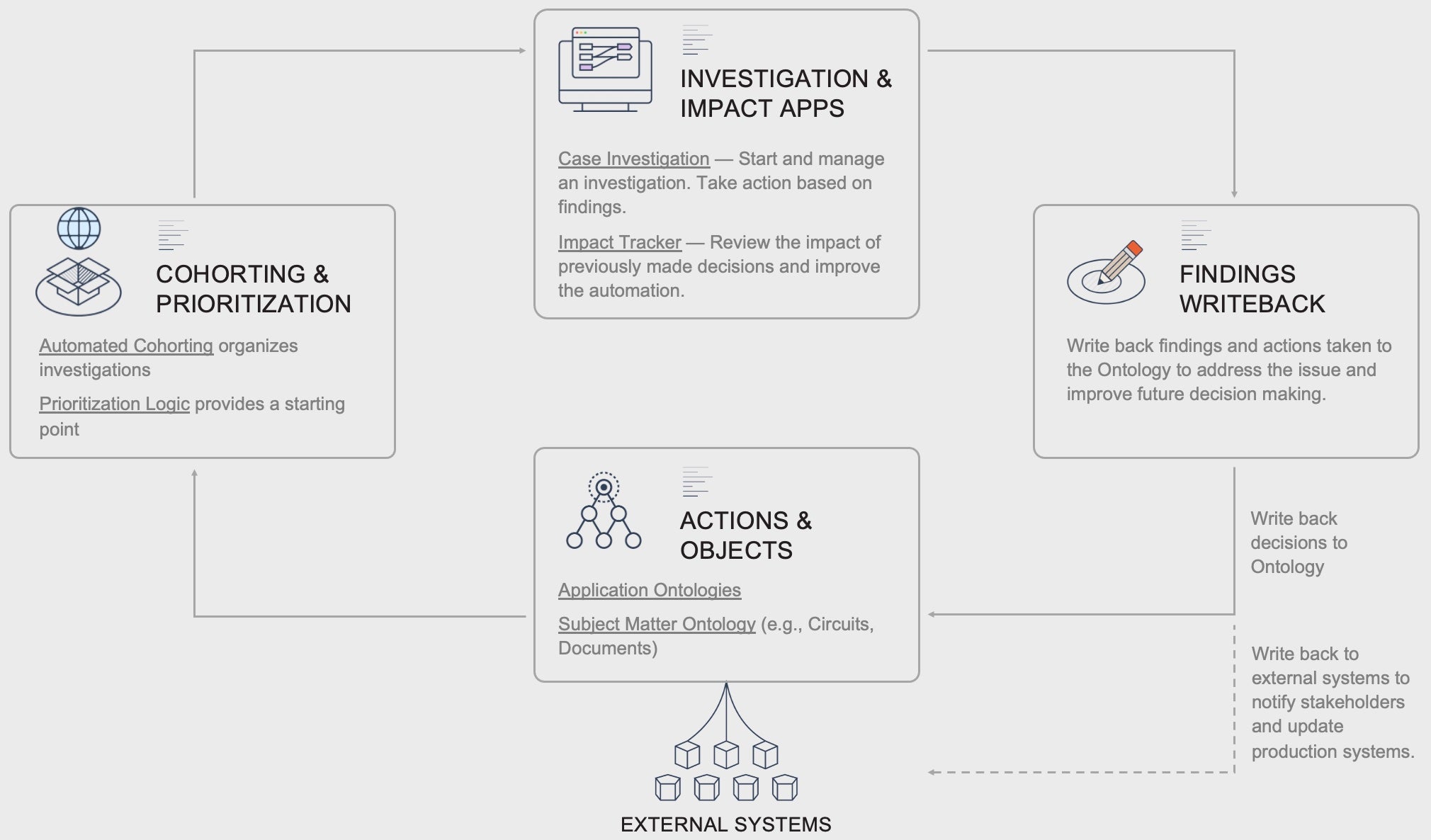
Foundryでは、これらのワークフローは、異なるスキルセットを持つユーザー向けの異なるツールを組み合わせますが、すべてが同じデータ資産、つまり関連する組織のオブジェクトとそれらの間の関係をモデル化するオントロジーに依存しています。自動化されたビジネスロジックおよび/またはMLコホート分析が適用されて調査の出発点を提供し、Foundryの様々な分析ツールが問題の詳細を理解するために使用されます。最後に、オントロジーの書き戻しが使用されてオントロジーと外部のソースシステムを更新し、問題を修復または対処します。
主要な要素
ユーザーインターフェース
探索的分析
データを調査し、仮説を検証するために、分析家はしばしば探索的分析に依存します。彼らはトップダウンのアプローチを開始し、大規模なデータセットを高レベルで見てから、それを変換したり、フィルター処理したり、集計したりして仮説を検証するためにそれを削減します。例えば、材料収率アプリケーションでは、分析家は週ごとに最もパフォーマンスが悪い材料をレビューし、Contourを通じて節約の機会を特定します。
過去には、この方法は大規模なデータセットを扱い、結果を比較するツールを使用できる高度に技術的な分析家のために予約されていました。これは、プロセスがいくつかのユーザーにボトルネックとなり、反復速度が遅くなることを意味していました。
Foundryでは、ユーザーはコードとノーコードのツールセットに頼って任意のデータセットを秒単位で分析します。これは、データを視覚的に探索するツールを提供し、エントリーバリアを下げるだけでなく、オントロジーを活用することで、ユーザーに多くの運用コンテキストを提供します。
関連製品:
ケース調査
調査は、アラートワークフローパターンからの結果(例えば、電力網のトレンドや停電)、優先されるコホート(例えば、最もパフォーマンスが低い製造プロセス)、またはユーザーが機会を探している(例えば、次のアクションを特定する営業担当者)という結果として開始するかもしれません。
それらは単一のオブジェクトまたは小さなオブジェクトのサブセットから始まります。調査はほとんどの場合、オープンエンドではなく、むしろ明確な目標があり(例えば、顧客のクレームの源を理解する)、それは分析家のタスクがトリガーからその根本原因までのイベントを遡ることです。
関連製品:
インパクトトラッカー
調査が完了し、仮説が確認されたり、分析が結論したりすると、実世界のイベント(例えば、リスキーなアセットの修復を行うチームをトリガーする)をトリガーする運用上の決定がなされます。
理想的には、これらの実世界のイベントは、同じ状況に再び陥るリスクを減らすこともできます。これが起こると、取られた決定と行動は自体が重要なデータ資産となります。いつ、どこで、なぜ決定が下されたかを知ることは、今後の調査や分析で活用でき、分析家が時間をかけて異なる状況を比較し、一貫性を高めることができます。
関連製品:
(オプション) 自動クラスタリング
手動ルール作成
理想的には、調査は積極的にトリガーされます。専門家は、どのようなエラーや異常が発生する可能性があるかを推定でき、特にこれらを監視するためにデータを特定の方法で監視したいかもしれません。仮説は非常に具体的なものである場合(この場合、彼らは資産失敗の操作のようなアラートパターンに頼る)または緩やかなものである場合(この場合、彼らはデータで見ておくべきKPIやビジネスロジックを定義する、材料収率アプリケーションのような)。最も簡単な場合、ロジックは分析家がそれぞれの調査や分析の開始時に手動で行う手順に従います。
(少なくとも部分的に)自動化されたアプローチは、規制者が要求するか、一貫性を確保し、リスクの発生可能性を減らすために価値があるかもしれない確定的な振る舞いを確保するためにも使用できます。
アラートパターンと同様に、ユーザーはFoundryのアラートオートメーションに頼ることも、調査と探索と同じツールを使用することもできます。
関連製品:
場合によっては、調査やデータの異常を検出するために、専門知識をケースごとに適用する必要はありません。堅牢で一貫したデータ資産が存在する場合、統計的なアプローチが問題に対してより適している可能性があります。人間にとっては、大量のデータの中に複雑なパターンを検出するのは難しいことがあります、特にパターンが絶えず変化している場合は特にです。Foundry MLを使用すると、大規模なデータセットの上にモデルを訓練し、実装することができます。その結果(クラスターまたは予測)はプラットフォームの他のどのデータポイントと同様に使用でき、つまり、それをオントロジーの一部にすることができ、探索分析や調査で取り上げることができます。
関連製品:
オントロジー
オントロジーは、異なる資産が互いにどのように関連しているかの情報を保存します(例えば、出荷、顧客、注文がどのように接続されているかなど)、ユーザーが自然に質問をし、答えを出すことができます。
オブジェクト:
- コホート
- Rules
- 専門的なコンテキストオブジェクト
関連製品:
要件
使用されるパターンに関係なく、基礎となるデータ基盤は、パイプラインと外部ソースシステムへの同期から構築されます。
データ統合パイプライン
SQL、Python、Javaなどの言語で記述されたデータ統合パイプラインは、データソースを主題のオントロジーに統合するために使用されます。
FoundryはFTP、JDBC、REST API、S3など、さまざまなソースからデータを同期できます。さまざまなソースからデータを同期し、可能な限り最も完全な真実のソースをコンパイルすることは、最高の価値決定を可能にするための鍵です。
このパターンを実装するユースケース
- 標準化されたKPIレポートを通じて生産収率を改善する
- インテリジェントな再価格設定を通じて保持および回収のパフォーマンスを改善する
- 統合キャンペーン管理を通じてクライアントエンゲージメントを増加させる
- アラートと調査サポートによるトランスフォーマーの故障の防止
このユースケースパターンについて詳しく知りたいですか?同様のものを実装しようとしていますか?Palantirで始めましょう。↗