注: 以下の翻訳の正確性は検証されていません。AIPを利用して英語版の原文から機械的に翻訳されたものです。
データセットの列にCipher操作を適用する
Cipherを使用すると、データセットの行全体を暗号化、復号化、およびハッシュ化できます。これは Pipeline Builder、Contour、および Pythonトランスフォーム でサポートされています。
コードリポジトリのプレビュー や Pipeline Builderのプレビューを使用する際、ユーザーはCipher操作の実際の出力を表示できません。代わりに、プレビューでプレースホルダー値が表示されます。データはビルド時に暗号化されることに注意してください。Cipher操作の実際の出力を表示するには、ユーザーはビルドを実行する必要があります。
Pipeline Builder
Pipeline Builderは、Foundryで高品質なデータ統合を簡単に実行できるようにするデータ統合アプリケーションです。このセクションでは、Pipeline Builderでデータセットの列を暗号化するためにCipher操作をデプロイする方法を示します。Pipeline BuilderでCipher操作を実行するには、Cipher Data Manager License または Admin License にアクセスできる必要があります。
暗号化
まず、Cipher暗号化トランスフォームを選択します。次に、Expression(暗号化される列)を選択します。次に、暗号化許可を持つData Manager Licenseを選択し、通常、Cipherアプリケーションでの以前の発行後、プロジェクトフォルダーにあります。最後に、出力列の名前を付けます。
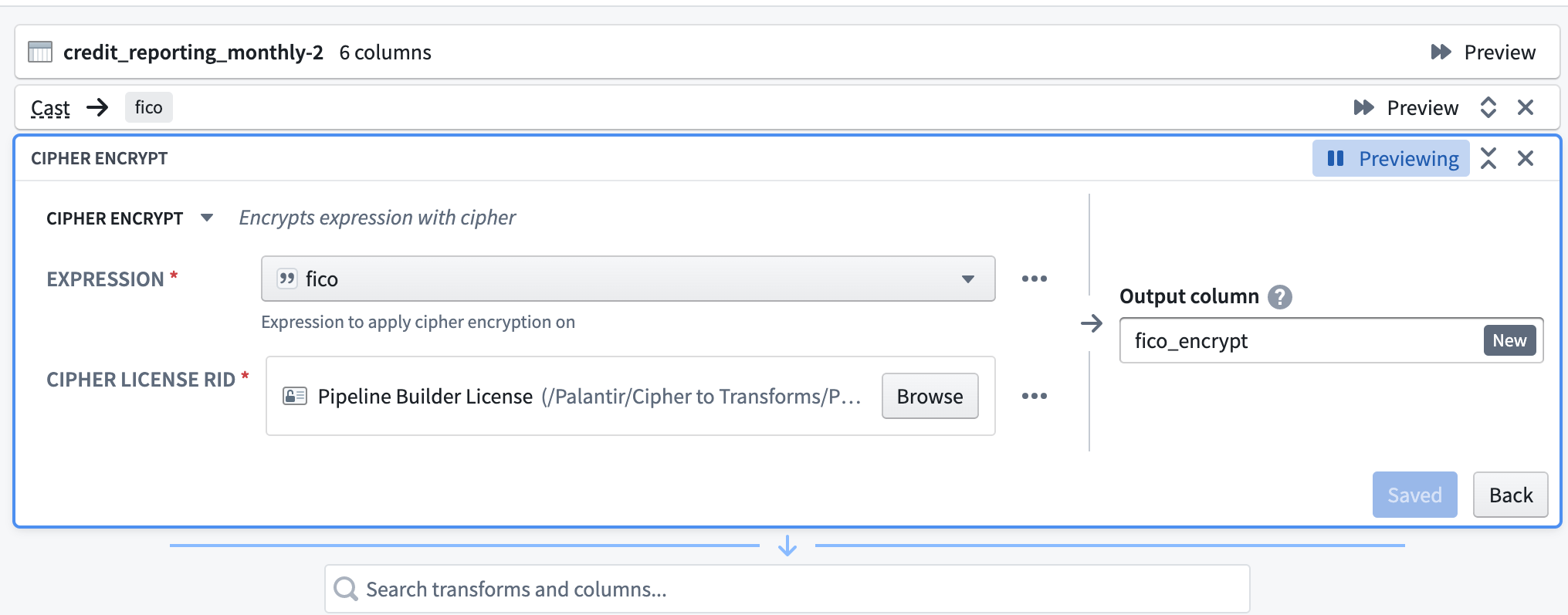
復号化
まず、Cipher復号化トランスフォームを選択します。Expressionを選択する際、Cipherトランスフォームを介してすでに暗号化された列を指定します。Cipher License RIDについては、復号化許可を持つData Manager Licenseを選択し、通常、Cipherアプリケーションでの以前の発行後、プロジェクトフォルダーにあります。ライセンスは、関連する列を暗号化するために使用された同じCipherチャネルの一部でなければなりません。最後に、出力列の名前を付けます。
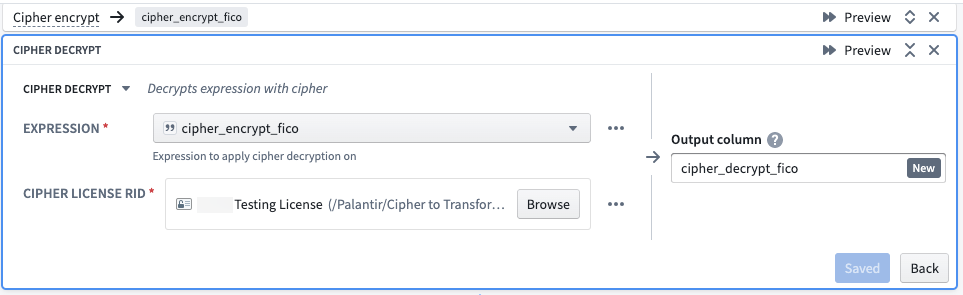
ハッシュ化
Cipherハッシュトランスフォームを選択します。Expressionについては、ハッシュ化する列を指定します。次に、ハッシュCipherチャネルから暗号化する権限を持つData Manager Licenseを選択します。ライセンスは、Cipherアプリケーションで発行され、プロジェクトフォルダーに保存されています。最後に、出力列の名前を付けます。
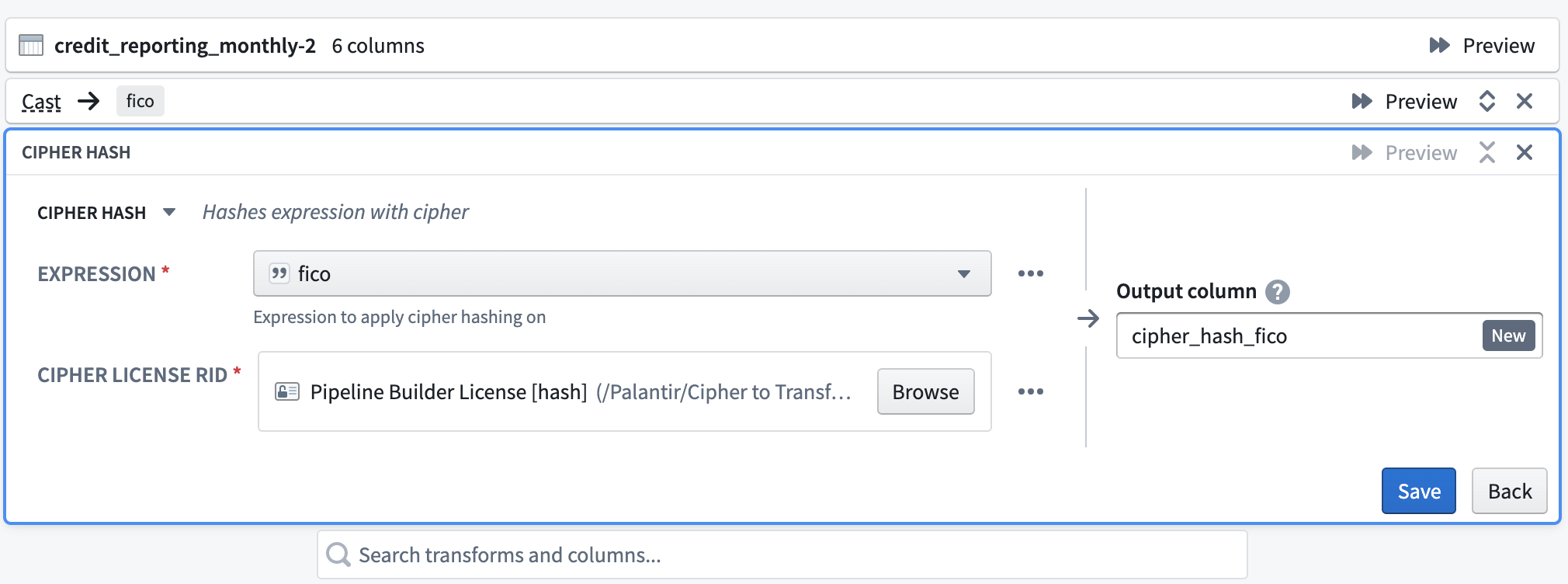
Cipherでパイプラインを暗号化する方法(AdminおよびData Managerライセンスのみ)
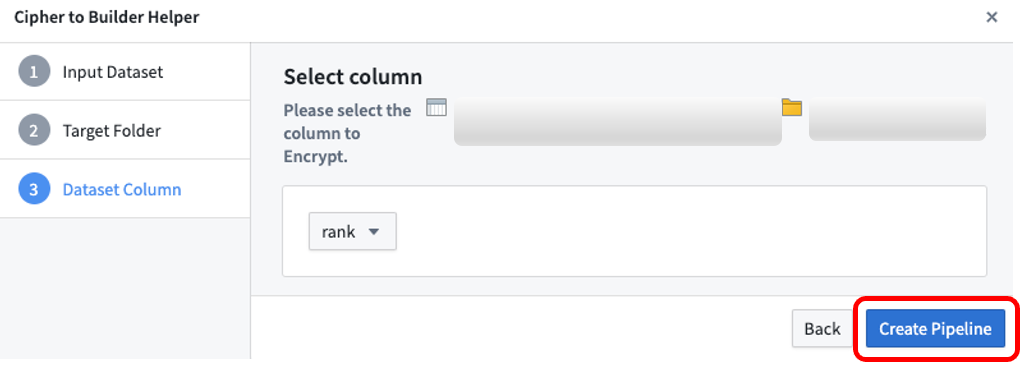
まず、暗号化許可を持つCipherライセンスを開きます。ライセンスは、通常、Cipherアプリケーションでの以前の発行後、プロジェクトフォルダーにあります。次に、右上の「Create Pipeline」を選択します。
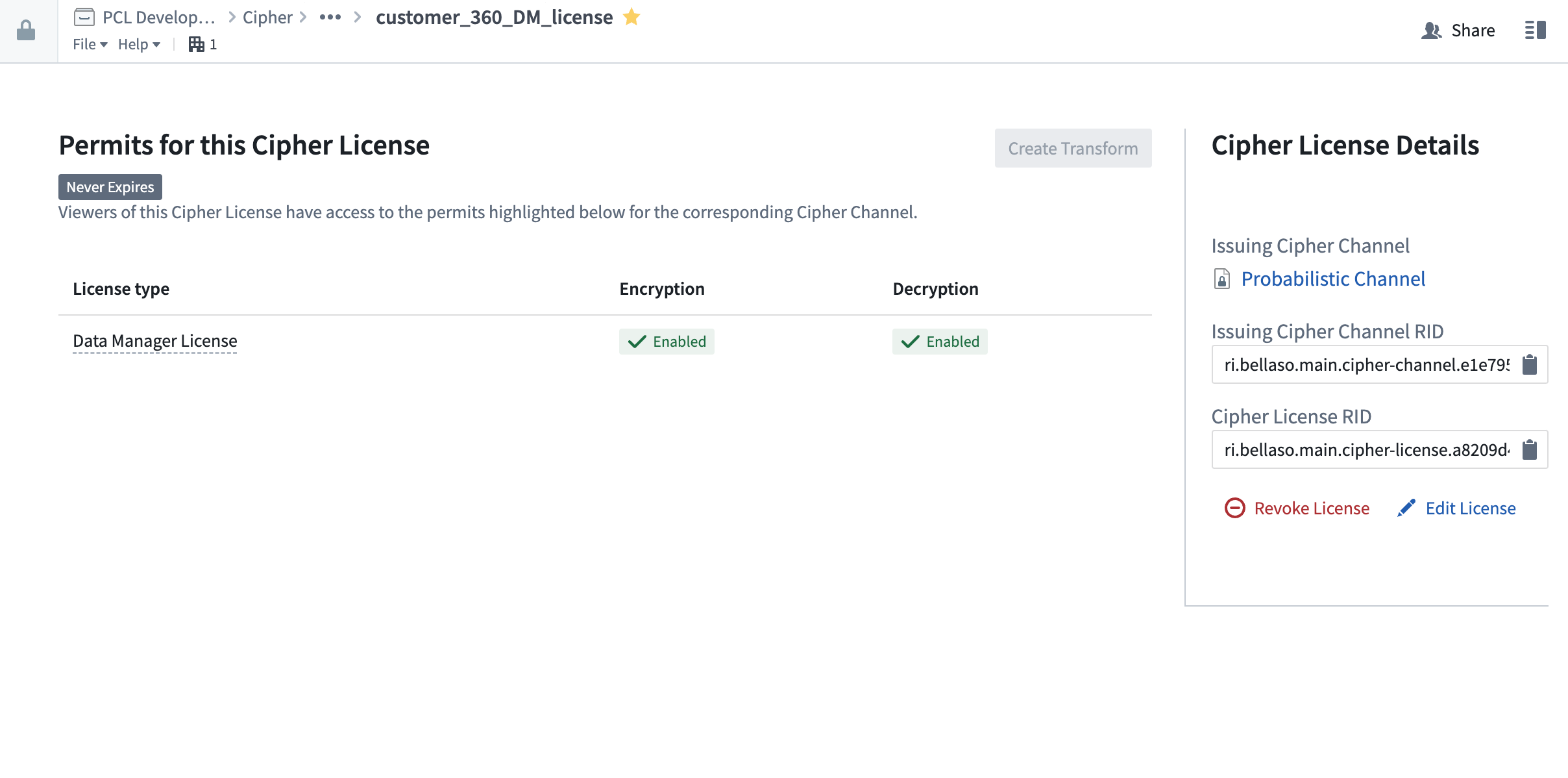
暗号化する入力データセットを選択し、パイプラインが保存されるターゲットフォルダーを選択し、暗号化するデータセット列を選択します。String列のみが暗号化可能であることに注意してください。別の列を暗号化する必要がある場合は、まずStringにキャストしてください。Create Pipeline を選択すると、Cipherは自動的に新しいパイプラインを生成し、以前に選択した列を暗号化します。
Contour
Contourは、大規模なテーブル上でのデータ分析を行うためのポイントアンドクリックのインターフェースを提供します。このセクションでは、Contour Analysisでデータセットの列を(非)暗号化するためにCipher操作を使用する方法を示します。ContourでCipher操作を実行するには、Cipher Data Manager License または Admin License にアクセスできる必要があります。始めるには、Contourツールバーの 検索モード を使用して、分析にCipherボードを追加します。
Cipherボードを使用するContour分析パスは、データセットとして保存 することはできません。
暗号化
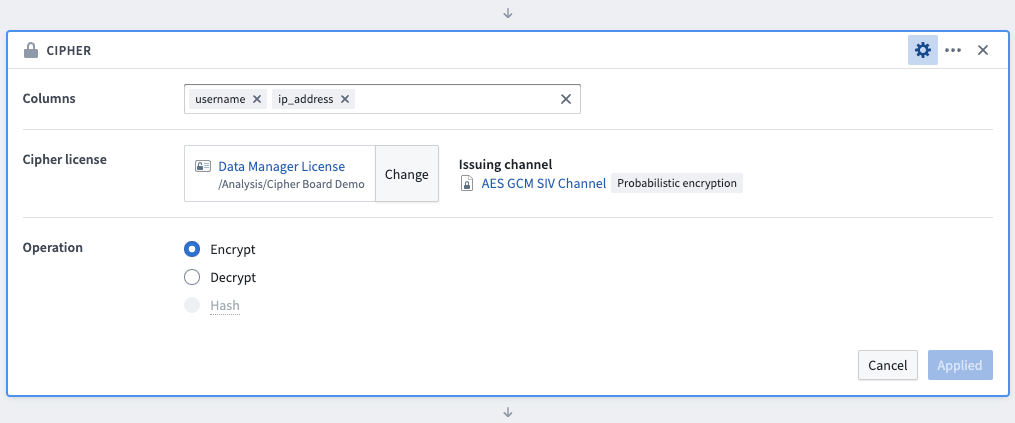
Cipherボードを使用してデータを暗号化するには、まず暗号化される列を選択します(列を選択する順序は操作に影響しません)。次に、暗号化許可を持つData Manager LicenseまたはAdmin Licenseを選択し、通常、Cipherアプリケーションでの以前の発行後、プロジェクトフォルダーにあります。Encrypt 操作を選択し、ボードを保存します。この変換によって列の値が更新されますが、列名は変更されません。
復号化
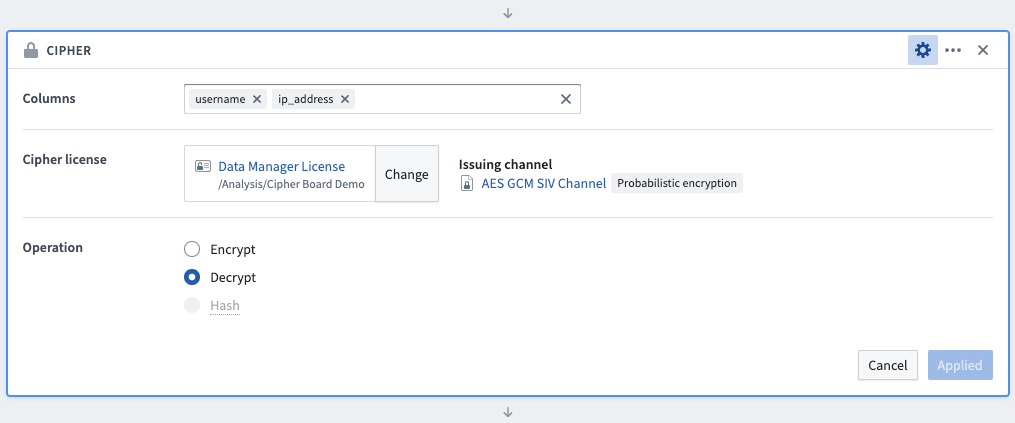
Cipherボードを使用してデータを復号化するには、まず復号化される列を選択します(列を選択する順序は操作に影響しません)。次に、復号化許可を持つData Manager LicenseまたはAdmin Licenseを選択し、通常、Cipherアプリケーションでの以前の発行後、プロジェクトフォルダーにあります。Decrypt 操作を選択し、ボードを保存します。この変換によって列の値が更新されますが、列名は変更されません。
ハッシュ化
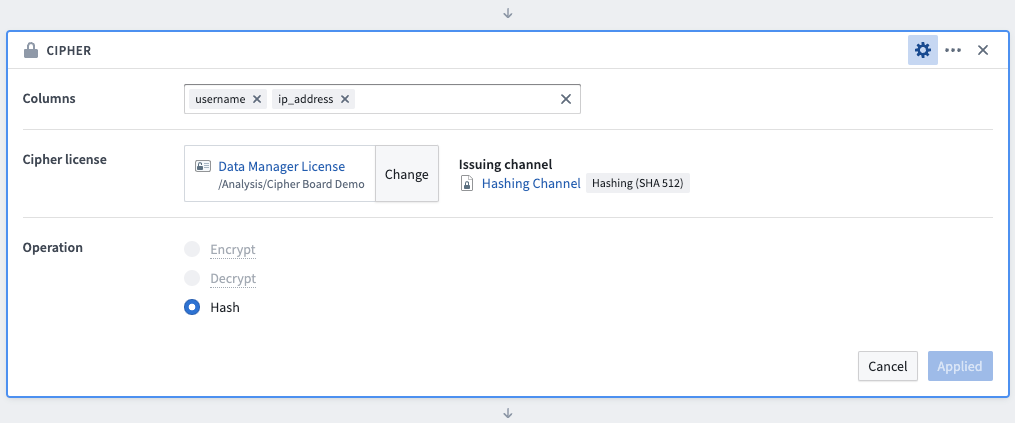
Cipherボードを使用してデータをハッシュ化するには、まずハッシュ化される列を選択します(列を選択する順序は操作に影響しません)。次に、ハッシング許可を持つData Manager LicenseまたはAdmin Licenseを選択し、通常、Cipherアプリケーションでの以前の発行後、プロジェクトフォルダーにあります。Hash 操作を選択し、ボードを保存します。この変換によって列の値が更新されますが、列名は変更されません。
Pythonトランスフォーム
リポジトリの設定
conda_recipe/meta.yml の requirements.run ブロックに bellaso-python-lib を追加します。また、Code Repository環境 の Libraries パネルでこれを自動的に追加することもできます。TransformsでCipher操作を実行するには、Admin License が必要です。
暗号化
列を暗号化するには、@transforms ブロック内で EncrypterInput を定義する必要があります。EncrypterInput は、CipherライセンスへのRIDまたはファイルシステムパスのいずれかを取ります。Cipherライセンスは暗号化許可を持つ必要があります。
例:
復号化
列を復号化するには、@transforms ブロックで DecrypterInput を定義する必要があります。DecrypterInput は、Cipher License の RID またはファイルシステムのパスのいずれかを取ります。Cipher License には復号化権限が必要であることに注意してください。
例:
ハッシュ化
列をハッシュ化するには、@transforms ブロックで HasherInput を定義する必要があります。HasherInput は、RID または Cipher ライセンスへのファイルシステムパスのどちらかを取ります。Cipher ライセンスには、ハッシュ化の権限が必要であることに注意してください。
例: