注: 以下の翻訳の正確性は検証されていません。AIPを利用して英語版の原文から機械的に翻訳されたものです。
一致条件を作成する
Sensitive Data Scanner には一連の組み込み一致条件が付属しています。また、Sensitive Data Scanner で使用するカスタム一致条件を定義することもできます。
組み込み一致条件
Sensitive Data Scanner は、社会保障番号、メールアドレス、電話番号など、一般的なタイプの PII を検出するための組み込み一致条件を提供します。これらは、右サイドバーの Built-in Match Conditions セクションを展開するための Arrow を選択することで見つけることができます。
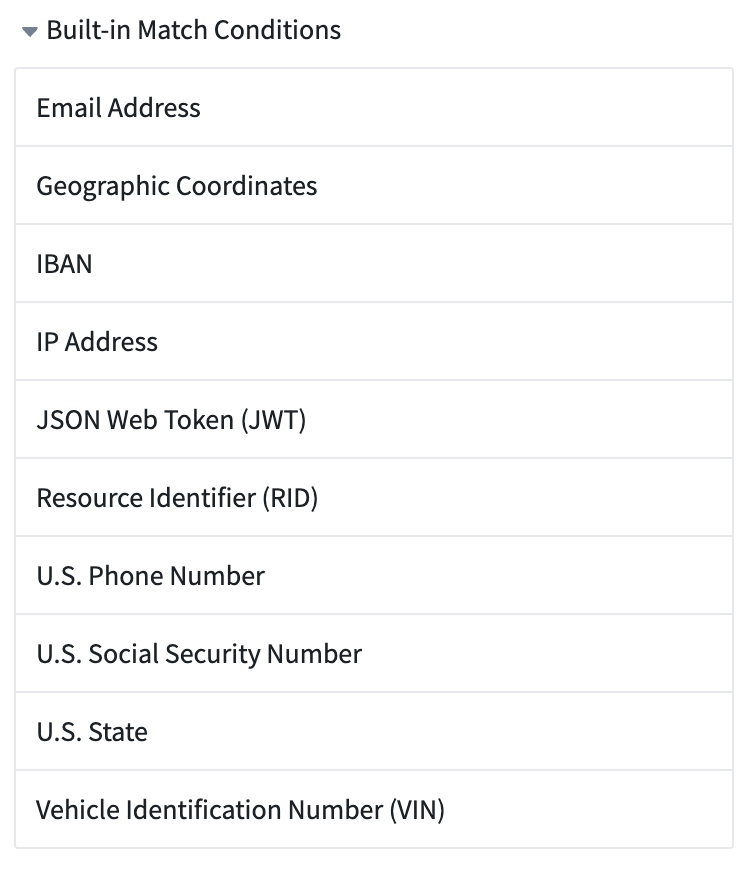
組み込み一致条件は、一般的な個人データのタイプを検出するように設計されています。ただし、その有効性はユーザーの特定のデータ構造や形式に依存します。これらの条件がユーザーのデータ標準に合致していることを確認し、必要に応じてカスタム条件を作成することを検討してください。さらに質問がある場合は、ユーザーのデータ保護担当者に相談してください。
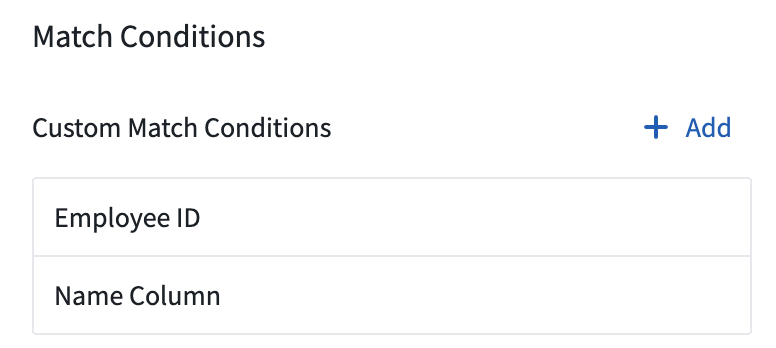
カスタム一致条件を作成する
ユーザーのスペース用のカスタム一致条件を作成するには、2 つの方法があります。
- Sensitive Data Scanner のランディングページから。
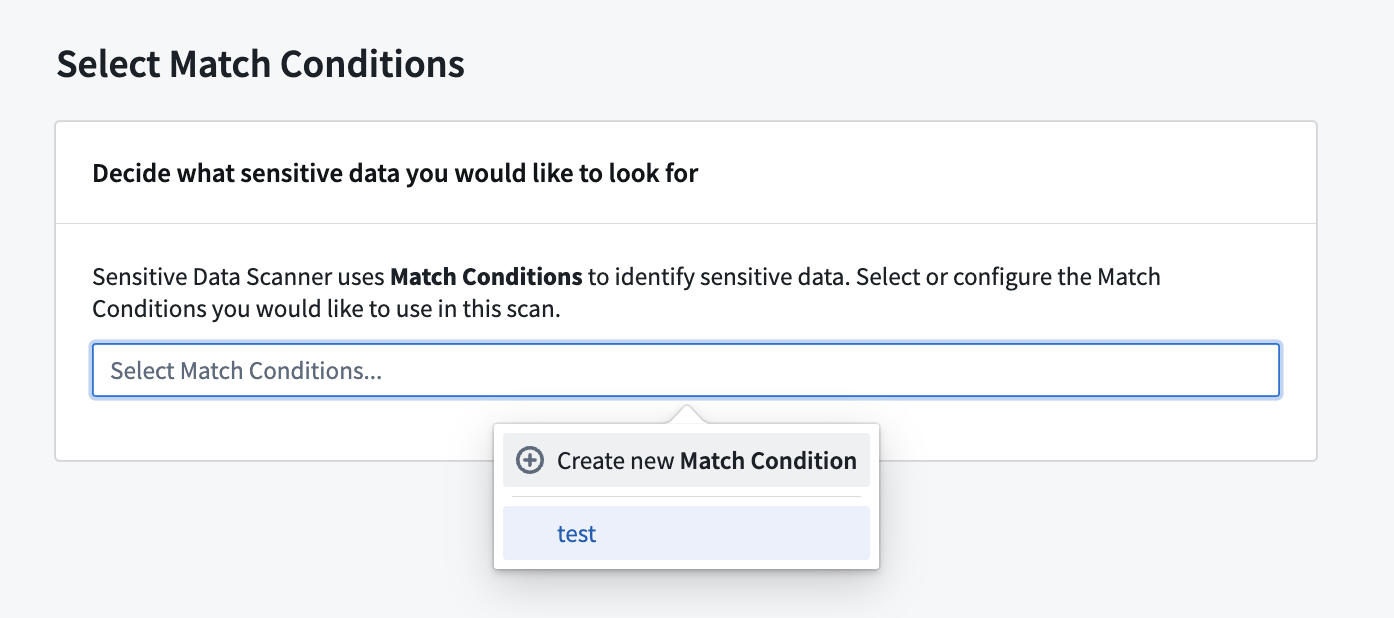
- 機密データスキャンを作成する際。
ランディングページからは、Custom Match Conditions が一致条件のサイドバーにリストされている上部にある Add を選択します。
機密データスキャンを作成する際には、Select match conditions ページで Create new match condition を選択することで、新しい一致条件を作成し、すぐにスキャンに使用することができます。
これらの開始ポイントはどちらも同じ一致条件作成プロセスを開きます。そこから、regex (正規表現)一致条件またはoverlap (値の重複)一致条件を作成するかを選択できます。
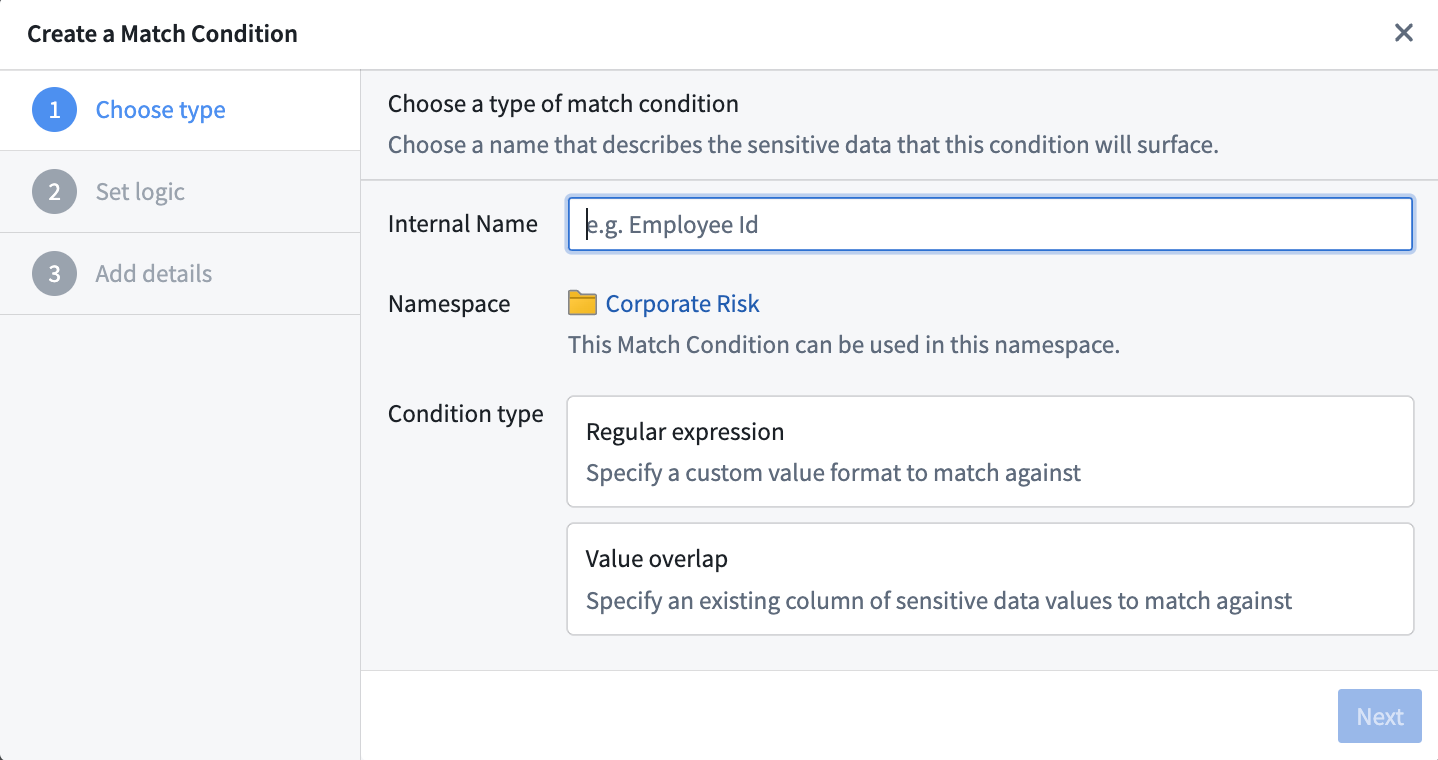
正規表現一致条件を作成する
正規表現(regex)一致条件を作成する際には、指定できる 2 種類の正規表現オプションがあります。コンテンツ正規表現と列名正規表現です。
- コンテンツ正規表現: Sensitive Data Scanner がデータセットのコンテンツに対してチェックする正規表現(データセットの列名ではありません)。
- 列名正規表現: Sensitive Data Scanner がデータセットの列名に対してチェックする正規表現(コンテンツ自体ではありません)。
Sensitive Data Scanner は、最大の特異性を確保するためにこれらの 2 つの正規表現オプションを組み合わせることができます。
- コンテンツ正規表現が一致する場合にデータセットをハイライトします。
- 列名正規表現が一致する場合にデータセットをハイライトします。
- コンテンツおよび列名の両方の正規表現が一致する場合にデータセットをハイライトします。
- コンテンツまたは列名のいずれかの正規表現が一致する場合にデータセットをハイライトします。
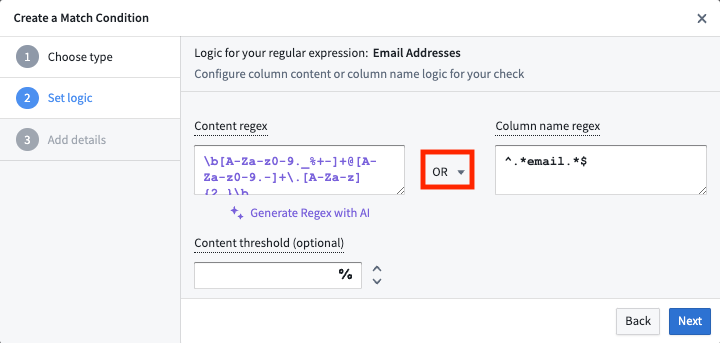
コンテンツ正規表現には、コンテンツ閾値フィールドがあり、0 より大きく 100 以下の数値を指定できます。このコンテンツ閾値は、特定の列のセルのうち、コンテンツ正規表現と一致する割合を示します。このフィールドは任意です。値が指定されていない場合、Sensitive Data Scanner はコンテンツ正規表現と少なくとも 1 つ一致する場合にデータセットを一致としてハイライトします。
AIP を使用した正規表現の生成
Foundry でユーザーのエンロールメントにAIP が有効になっている場合、AI の助けを借りてコンテンツ正規表現を指定することもできます。Generate Regex with AI ボタンを選択すると、検出したい機密データのタイプを説明するように求められます。たとえば、「すべてのメールアドレス」などです。提案された正規表現と一致する例を示し、その後アプリケーションで使用するための正規表現を生成します。以下のグラフィックはこのプロセスを示しています。
重複一致条件を作成する
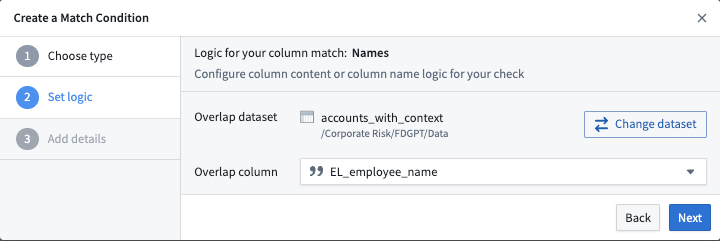
重複一致条件は、正規表現に抽出できない機密データを検索する場合に役立ちます。たとえば、名前に一致するコンテンツ正規表現を作成するのは困難ですが、列名正規表現を作成することは一部のケースで十分である場合があります。しかし、すでにスキャンしたい機密データのリストを持っている場合、重複一致条件が役立ちます。
以下のスクリーンショットは、特定の列を選択する方法の例です。この例では、accounts_with_context データセットの EL_employee_name 列が重複列として設定されており、この列と他のデータとの一致を検索します。重複列の任意のセルが他のデータセットの任意のセルと一致する場合、その他のデータセットはこの一致条件に一致するものとしてハイライトされます。