注: 以下の翻訳の正確性は検証されていません。AIPを利用して英語版の原文から機械的に翻訳されたものです。
機密データスキャンを作成する
一度きりのスキャンと定期的なスキャンの両方は、同じユーザーフローを使用して設定されます。まず、Sensitive Data Scannerアプリケーションに移動し、Create new sensitive data scanを選択します。これにより、機密データスキャンを作成する手順を説明する概要ページが表示されます。
- スキャンするリソースを選択する: このセクションでは、スキャンしたいデータセットを指定できます。詳細はスキャンするリソースを選択するを参照してください。
- 一致条件を選択する: 現在ユーザーのスペースで利用できる一致条件に機密データの種類がない場合、このセクションで一致条件を作成することもできます。詳細は一致条件を作成するを参照してください。
- 一致アクションを選択する: ユーザーのスペースで存在しない一致アクションが必要な場合、このセクションで新しい一致アクションを作成することもできます。詳細は一致アクションを作成するを参照してください。
- 確認 & 実行: スキャンを作成する前の最終確認。
スキャンするリソースを選択する
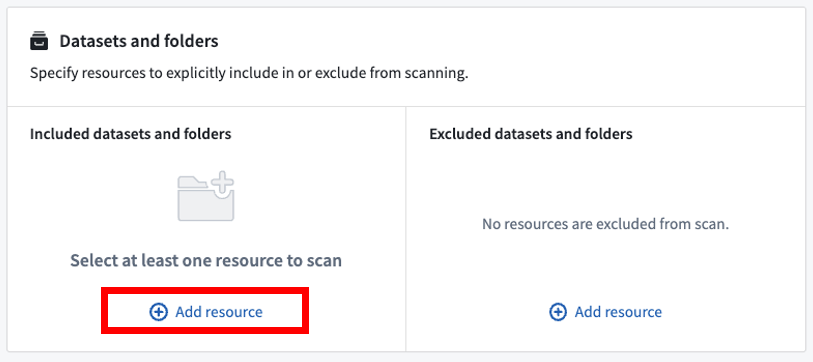
含まれるデータセットとフォルダー
Included datasets and foldersでAdd resourceを選択することで、スキャンするデータセットやフォルダーを明示的に含めることができます。フォルダーを追加すると、そのフォルダー内のすべてのデータセットがスキャンされます。ただし、明示的に除外されている場合を除きます。このセクションには、少なくとも1つのフォルダー(スペース/プロジェクトを含む)またはデータセットを含める必要があります。
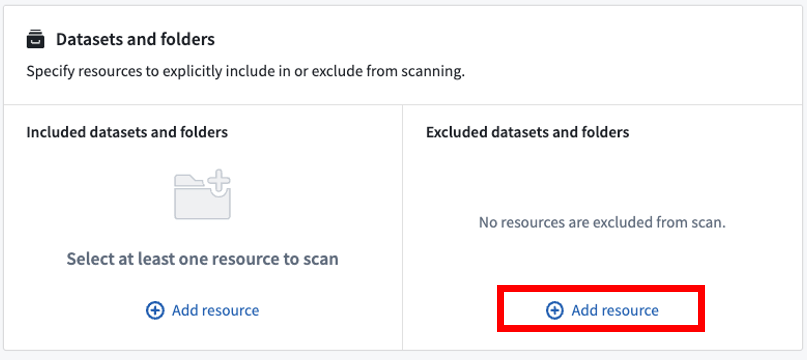
除外されたデータセットとフォルダー
同様に、Excluded datasets and foldersでAdd resourceを選択することで、スキャンから除外するデータセットやフォルダーを明示的に除外することができます。フォルダーを追加すると、そのフォルダー内のすべてのデータセットがスキャンから除外されます。ただし、明示的に含まれている場合を除きます。リソースを明示的に除外する必要はなく、このセクションは空のままにしておくことができます。
リソースが含まれている場合と除外されている場合が重複する稀なケースでは、最も具体的な包含または除外が優先されます。たとえば、データセットが含まれているが、除外されたフォルダーにある場合、データセット(含まれている)が親フォルダー(除外されている)よりも具体的であるため、データセットがスキャンされます。
スキャン戦略
以下のスキャン戦略オプションを使用して、機密データスキャンの動作をさらに細かく調整できます。
選択されたトランザクションタイプ
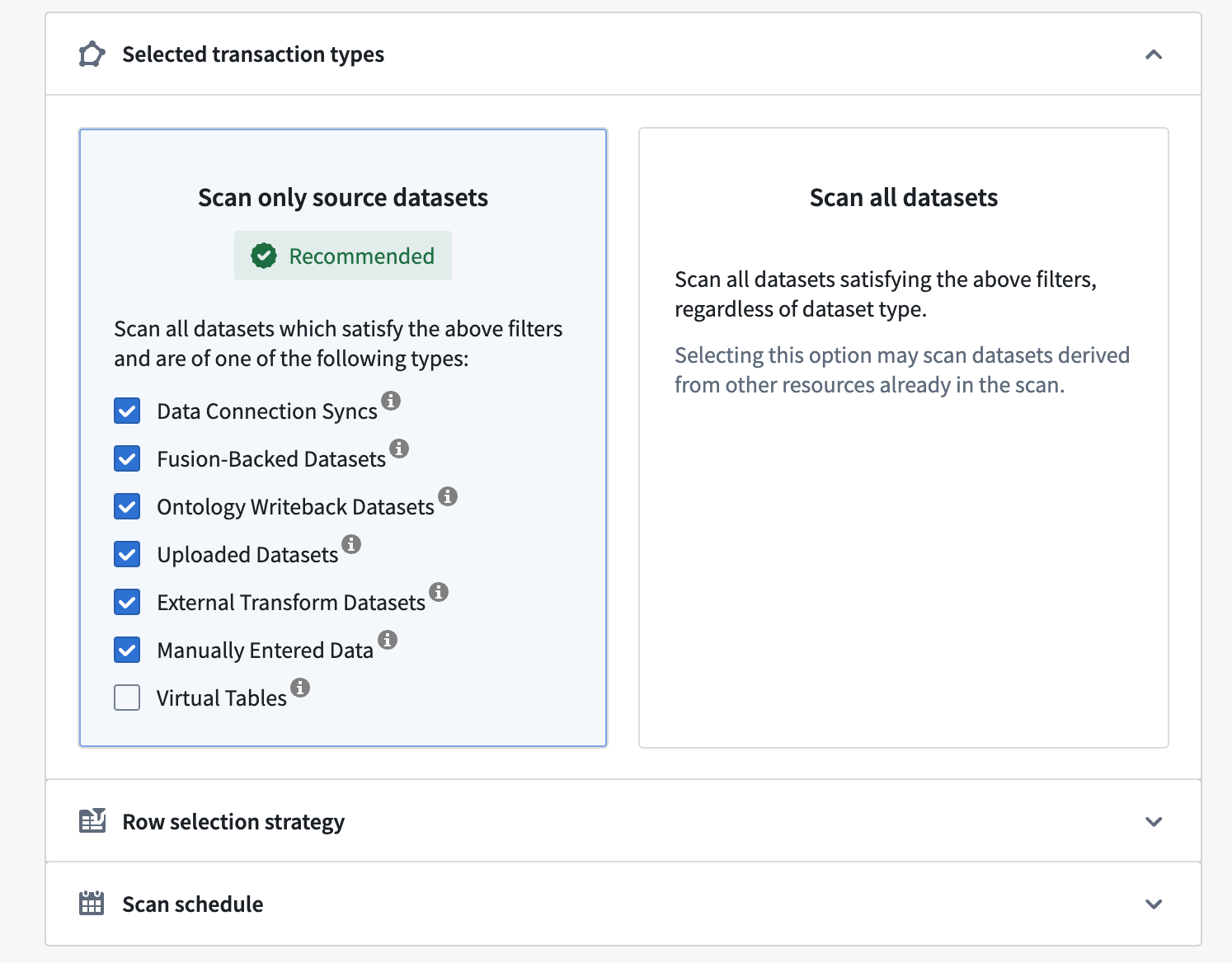
Sensitive Data Scannerは、特定のデータセット属性に基づいてスキャンするデータセットを指定できます。次の2つのオプションがあります。
- ソースデータセットのみをスキャンする: 一般的なソースデータセットタイプのみをスキャンできます。これらのデータセットは、他のデータセットから派生していない新しいデータを表すことが一般的です。 ソースデータセットのみをスキャンオプションは、スペース内のすべてのデータセットをスキャンすることなく、Foundryでの「データ境界」を監視することで機密データを見つけることができるため、推奨されるオプションです。
- 各リソースタイプのチェックボックスを(選択)解除することで、スキャンする/しないデータセットのタイプをさらに正確に絞り込むことができます。たとえば、手入力データ、アップロードされたデータセット、データ接続同期などです。
- PIIのためにバーチャルテーブルをスキャンするオプションも選択できます。 バーチャルテーブルはFoundry外のソースシステムのテーブルへのポインターです。このオプションを有効にすると、PIIのためにフェデレーテッドデータをスキャンできます。このソースシステムは、スキャン時に到達可能である必要があることに注意してください。
- すべてのデータセットをスキャンする: 派生データセットを含むすべてのデータセットをスキャンします。スキャンするデータセットが増えるため、このオプションは、ソースデータセットのみをスキャンする場合よりも多くの計算リソースを必要とします。
以下の例では、Sensitive Data Scannerは選択されたフォルダー内のソースデータセットのみをスキャンします。
行選択戦略
さらに、スキャンする行数を設定するオプションがあります。
- すべての行をスキャンするオプションは、_全データセット_をスキャンします。選択した一致条件をトリガーする値を含むすべてのデータセットがフラグ付けされるため、正しいスキャン結果を保証する唯一の方法であるため、一般的に推奨されるオプションです。このオプションは、一致条件の複雑さやスキャンするデータセットのサイズに応じて、スキャン時間が長くなる可能性があることに注意してください。
- ランダムに抽出された一部の行のみをスキャンするオプションは、データセット全体をスキャンする代わりに、行のランダムに抽出されたサブセットをスキャンします。このアプローチは、リソース集約型の一致条件を実行する際の計算コストを削減できます。
- 注: 指定された行数は概算であり、指定された行数より少ない行を含むデータセットは完全にスキャンされます。
スキャンスケジュール
スキャンスケジュールセクションでは、スキャンを実行するタイミングを設定するために2つのオプションがあります。
- 一度きりのスキャン: 指定されたリソースフィルター内のすべてのデータセットでスキャンが直ちに実行されます。後で更新、作成、追加されたデータセットはスキャンされないことに注意してください。
- 定期的なスキャン: 指定されたリソースフィルター内のデータセットに新しいデータが追加されるたびにスキャンが実行されます。
- すべての一致するデータセットの初期スキャンを実行するオプションを選択すると、Sensitive Data Scannerが指定されたリソースフィルター内のすべてのデータセットで直ちにスキャンを実行します。これにより、後で更新されない場合でもデータセットがスキャンされることが保証されます。
含まれるおよび除外されるマーキング
データセットやフォルダーを明示的に含めたり除外したりするのと同様に、データセットのマーキングに基づいてデータセットを含めたり除外したりすることができます。これは一般的に、既に保護されているデータセットを除外するために使用される高度な機能です。たとえば、以下のスクリーンショットでは、PII(個人を特定できる情報)とマークされたデータセットがスキャンされないことがわかります。これは、以前の機密データスキャンで一致した後にこのPIIマーキングが適用された可能性があるためです。
一致条件を選択する
機密データスキャンを作成するための最初のステップは、探したい特定の一致条件を選択し、一致が見つかった場合にSensitive Data Scannerが実行する特定の一致アクションを選択することです。
一致条件を選択する際には、探したい機密データと、スペース内で既に利用可能な一致条件を考慮してください。希望するタイプの機密データに対応する一致条件がない場合は、新しい一致条件を作成することができます。
一致アクションを選択する
一致アクションを選択する際には、機密データを検出した際の適切な対応を考慮してください。マーキングを適用することを選択すると、機密データを含むデータセットにアクセス制御がかかり、問題を作成することを選択すると、指定されたユーザーセットに機密データが見つかったことが通知されます。一致アクションを適用しないことを選択することもできます。
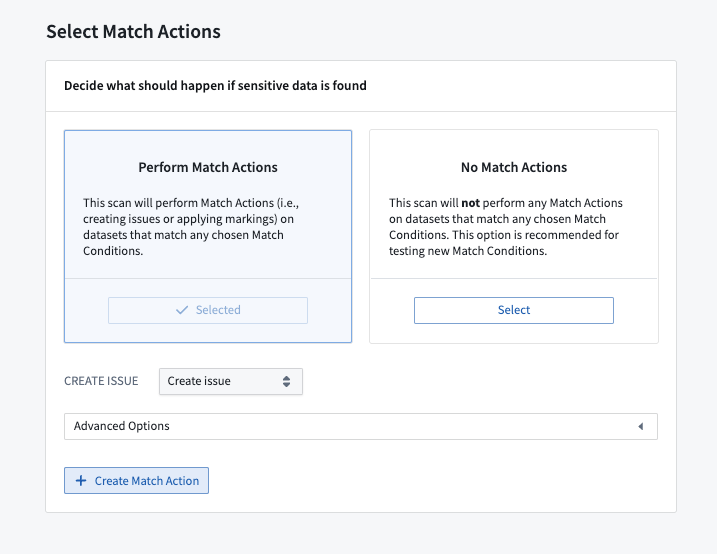
適切な一致アクションがスペースに存在しない場合、新しい一致アクションを作成することができます。詳細は一致アクションを作成するを参照してください。
大量のデータセットを含む機密データスキャンを行う場合、一致条件をテストしてから進むことをお勧めします。誤って設定された一致条件は、データセットに不要な問題やマーキングを引き起こす可能性のある誤検知を生成することがあります。一致条件をテストするには、スキャンのためにNo Match Actionsを選択してください。スキャンが終了し、一致条件が予期されたデータ形式に一致していることを確認したら、スキャンの概要ページから追加の一致アクションを適用できます。
詳細は追加の一致アクションを適用するを参照してください。
確認と実行
機密データスキャンの作成の最終段階では、スキャンのために選択した一致条件、一致アクション、リソースを確認できます。
このステップで、Sensitive Data Scannerは、スキャンを調整する際に選択したリソースフィルターに基づいてスキャンに必要なデータセットを計算します。
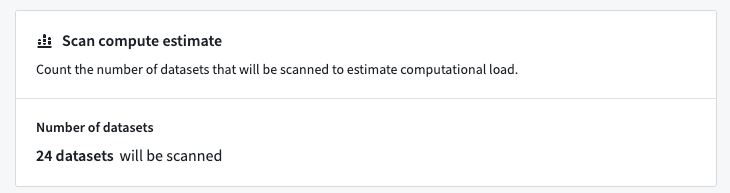
一度きりのスキャンスケジュールを選択した場合、Run One-Time Scanを選択することでスキャンを開始できます。
定期的なスキャンスケジュールを選択した場合、スキャンの名前と説明を追加することもできます。Save as Recurring Scanを選択することでスキャンを保存できます。
追加の一致アクションを適用する
過去7日以内に作成された非アクティブなスキャンに対しては、スキャンによって発見された機密データに追加の一致アクションを適用することができます。
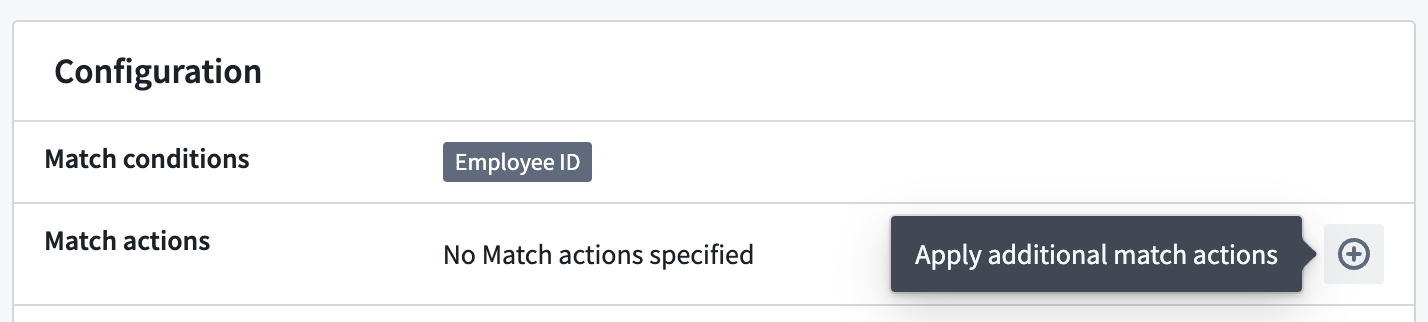
定期的なスキャンに対しては、追加の一致アクションは追加一致アクションが選択された時点までに識別された一致にのみ適用されます。スキャンが後で再アクティブ化される場合、定期的なスキャンによって発見された将来の機密データには、以前に選択された追加の一致アクションは自動的に適用されません。
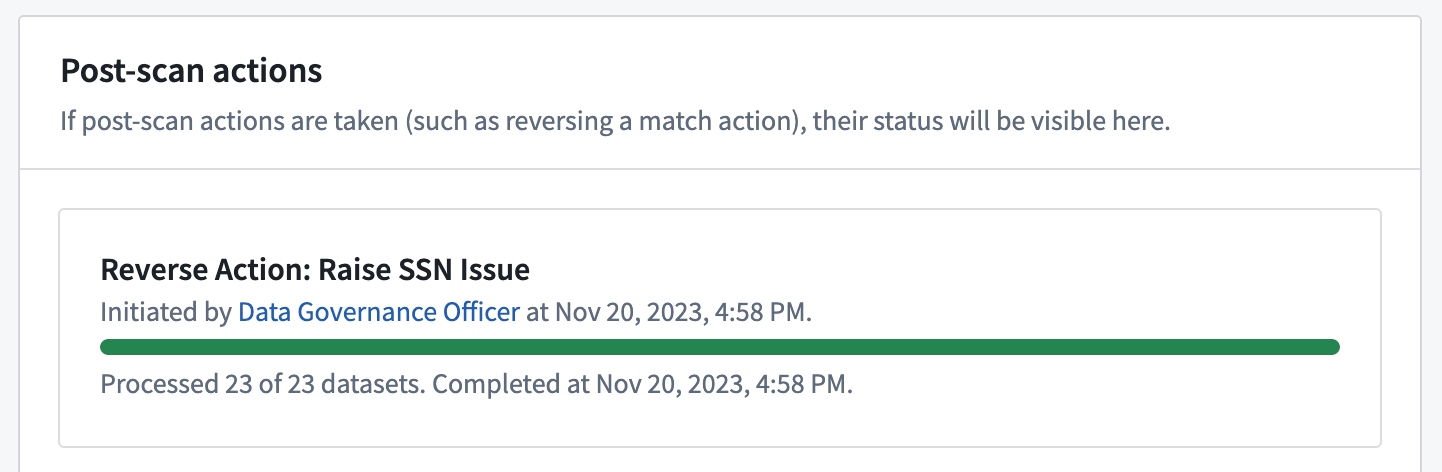
スキャンの概要ページの下部で、追加一致アクションの適用状況を確認できます。
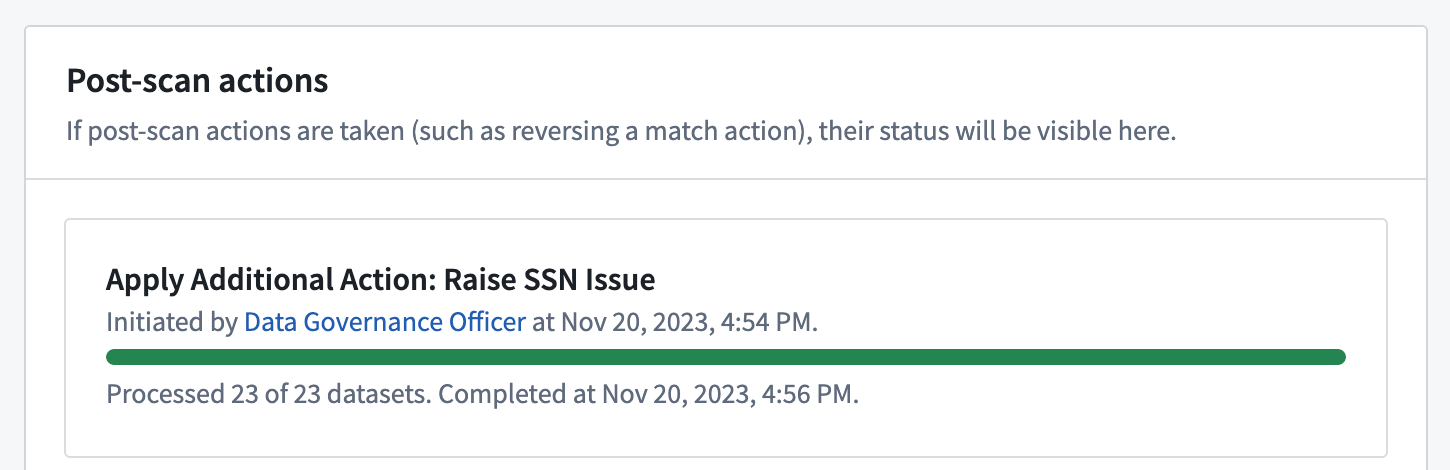
一致アクションを逆転させる
過去7日以内に作成された非アクティブなスキャンに対しては、スキャンによって発見された機密データに以前適用された一致アクションを逆転させることができます。Create issues一致アクションに対しては、このアクションによって作成された問題が削除されます。Apply markings一致アクションに対しては、このアクションによって適用されたマーキングが削除されます。
定期的なスキャンに対しては、一致アクション逆転が実行された時点までのアクションの結果のみが逆転されます。スキャンが後で再アクティブ化される場合、初期スキャン設定で構成された一致アクションがまだ適用されるため、将来の機密データが発見された場合でも引き続き一致アクションが適用されます。スキャンを再アクティブ化する前に、定期的なスキャンが特定の一致アクションを実行し続けないようにするためには、定期的なスキャンを編集して一致アクションを削除してください。
スキャンの概要ページの下部で、一致アクションの逆転状況を確認できます。