注: 以下の翻訳の正確性は検証されていません。AIPを利用して英語版の原文から機械的に翻訳されたものです。
コアコンセプト
Sensitive Data Scanner は、一致条件、一致アクション、およびスキャンのコアコンセプトに基づいて構築されています。スキャンは一度限りか定期的のいずれかです。
一致条件
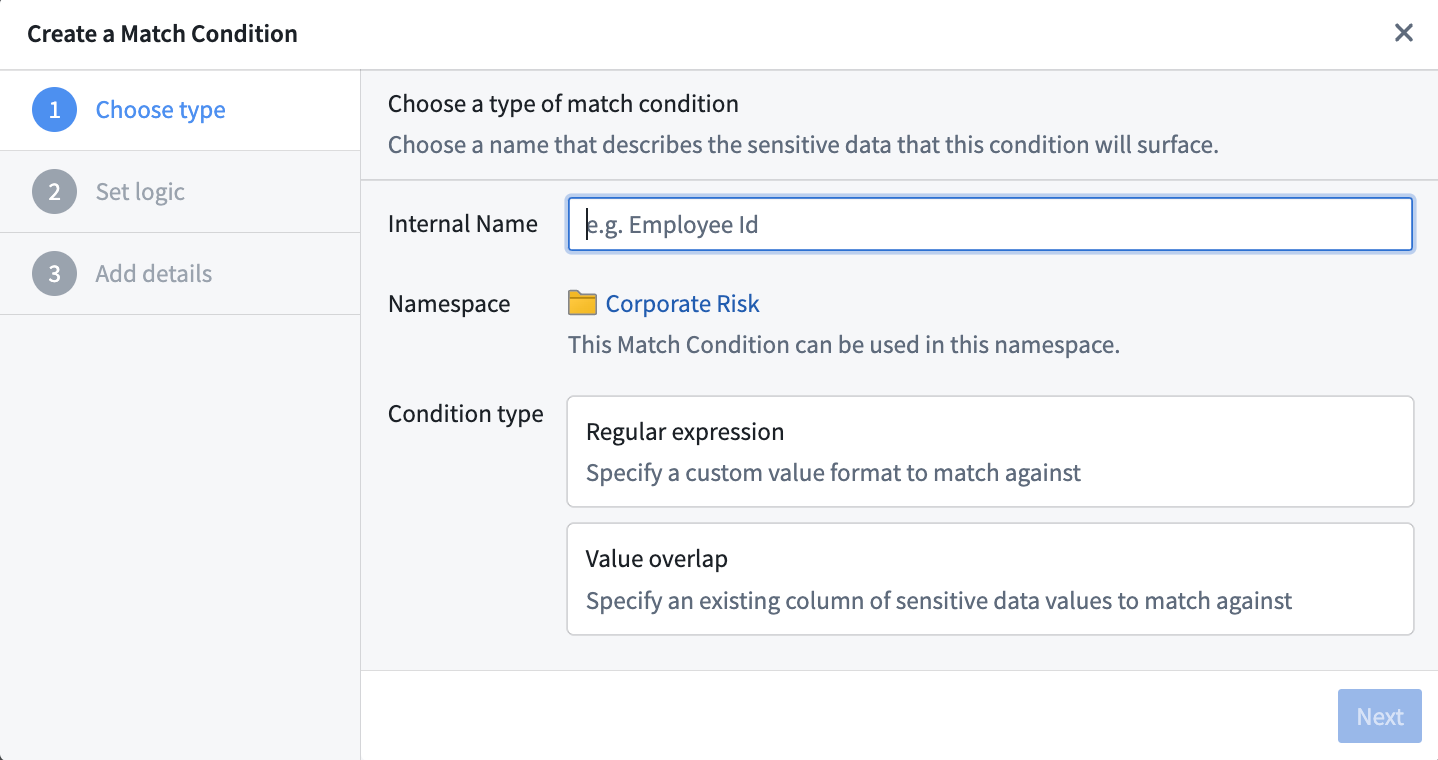
一致条件は、データの形式または値に基づいて機密データを特定するために Sensitive Data Scanner が使用する事前定義されたパターンです。2 種類の一致条件があります。
- 正規表現一致条件: 正規表現(regex)を使用して指定された一致条件です。正規表現は、テキストの一致パターンを表す文字列のシーケンスです。正規表現に不慣れなユーザーのために、AIP が目的の機密データに一致する有効な正規表現の作成を支援します。
- 重複一致条件: 重複一致条件では、列に含まれる既存の Foundry データセットの値と一致させることで、事前定義された機密データ(たとえば名前のリスト)の正確な重複を検索できます。
ユーザーは、自分が気にする個人識別情報(PII)のタイプをカバーするためにカスタム一致条件を作成できます。Sensitive Data Scanner は、社会保障番号、メールアドレス、電話番号など、一般的な PII タイプを検出するためのさまざまな組み込み一致条件も提供しています。
一致アクション
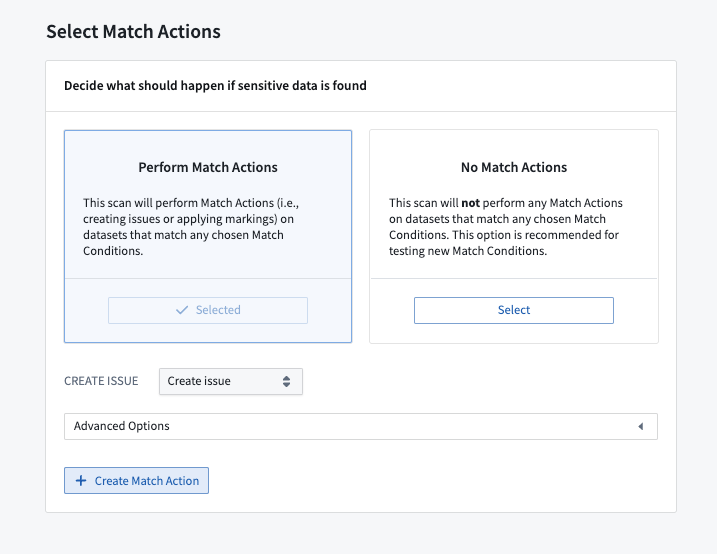
一致アクションにより、機密データがプラットフォーム内でどのように処理されるかについて自動化されたアクションを定義できます。ユーザーは 2 種類の一致アクションを実行できます。
- Issues の作成: ユーザーは、一致が見つかった列に Issues を作成する一致アクションを設定できます。これにより、ガバナンスチームは Sensitive Data Scanner によって検出された一致を手動でレビューおよび分類できます。
- マーキングの適用: ユーザーは、一致が見つかったデータセットに 1 個以上のマーキングを適用してアクセス制御を確保できます。
一度限りのスキャン
一度限りの機密データスキャンは、一致条件に基づいてユーザーが選択したデータセットを 1 回だけ検索し、一致が見つかった場合に指定された一致アクションを実行します。一度限りのスキャンは、組織のデータガバナンスポリシーに一致しない Foundry 内の既存データを特定するのに役立ちます。
定期的なスキャン
定期的な機密データスキャンは、一度限りのスキャンと似ていますが、定期的なスキャンはユーザーが選択したデータセットに新しいデータが追加されるたびに実行されます。定期的なスキャンは、新しいデータがプラットフォームに追加されても、潜在的に非準拠のデータを継続的に特定するための継続的な支援を提供します。