注: 以下の翻訳の正確性は検証されていません。AIPを利用して英語版の原文から機械的に翻訳されたものです。
機密データの保護
概要
データ基盤のセキュリティで見たように、さまざまなプロジェクトのデータへのアクセスは、プロジェクトオーナーによって管理されます。これは、任意アクセス制御 ↗として知られています。しかし、機密データに関しては、より強力で集中化されたアクセス制御モデルが必要です。
私たちの例では、乗客の生年月日(DOB)を含む仮想のデータセットがあり、これは個人識別情報(PII)を構成しています。この PII を厳密に制御し、このデータにアクセスできるのは、PII トレーニングを受けた人だけにしたいと考えています。これは、マーキングを使用して解決できます。
マーキングは、Foundry における強制アクセス制御 ↗の実装です。マーキングは、特定のユーザーやグループがアクセスできるデータの種顥(PII のような)を表します。マーキングがデータセットに適用されると、そのマーキングにアクセスできないユーザーは、プロジェクトオーナーがそれらと共有しようとしても、そのデータにアクセスできないことが保証されます。重要なのは、この制約がプラットフォーム内のどこかでこのデータセットから派生したすべてのデータに伝播することです。
この機能は、データガバナンスに非常に強力であり、データ保護責任者がデータカテゴリーにアクセスできる人を中央で管理および監査できるようになります。
エンドユーザーにアプリケーションを導入する前に、機密データを保護することを確認したいと思います。再び、私たちの例では、データパイプライン内でロックダウンしたい乗客の生年月日(DOB)があります。
マーキングの作成
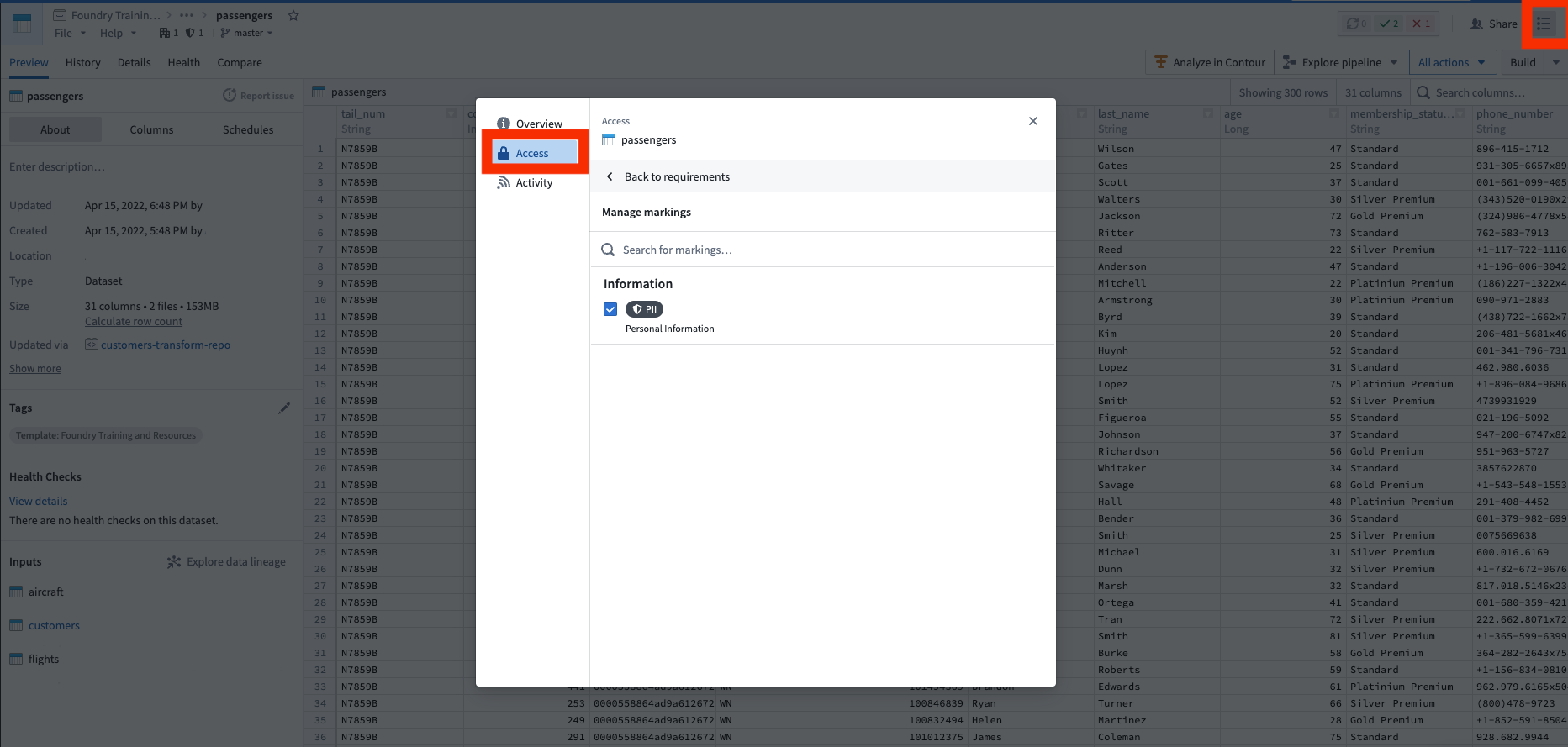
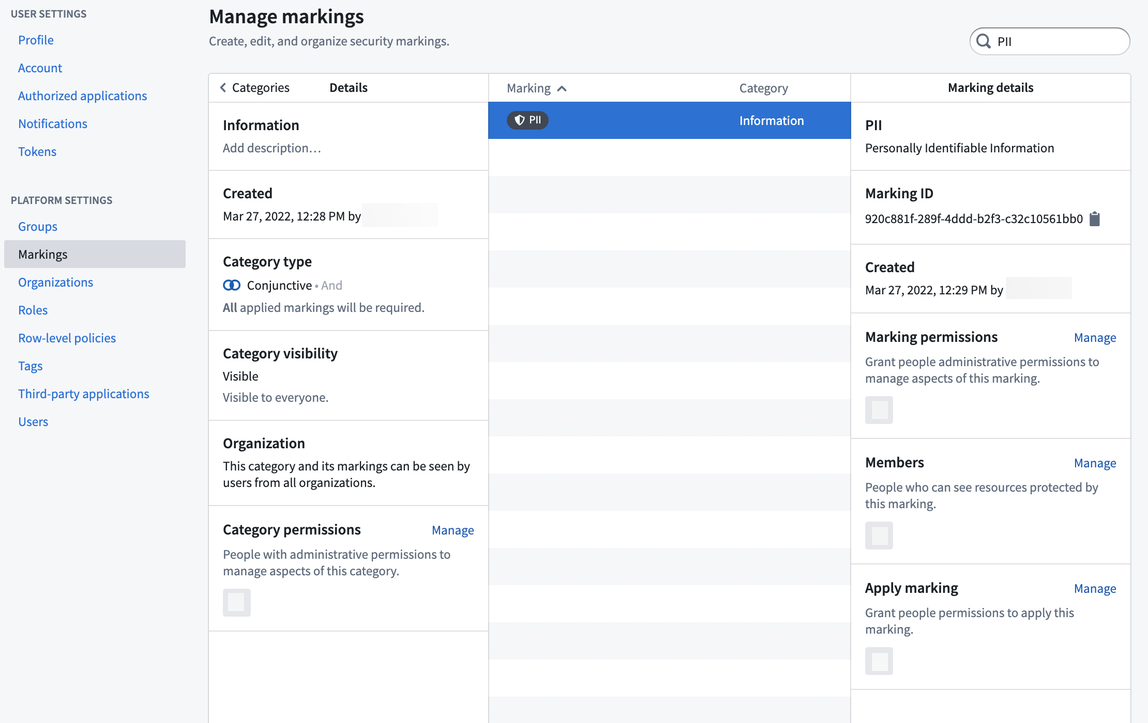
まず、マーキングカテゴリーを作成する必要があります。これは、マーキングのセットの名前です。この場合、「情報」というマーキングカテゴリーを作成します。これは、今後も他の情報関連のマーキング(たとえば、個人の健康情報や PHI)が必要になると考えられるためです。カテゴリーを作成した後、PII マーキングを作成できます。次に、PII データを表示する権限がある人々をマーキングのメンバーとして追加し、管理チームをマーキングの管理者として追加します。
マーキング変更をシミュレートする
マーキングは、データフローに沿って伝播するという強力な動作を持っています。したがって、既存のパイプラインに新しいマーキングを適用すると、下流のユーザーが予期せずロックアウトされるリスクがあるため、マーキングをパイプラインに適用する前に、常にシミュレートして伝播する場所を確認することがベストプラクティスです。これを行うには、パイプラインのデータフローを開いてシミュレーションモードをオンにし、raw/passengers データセットのマーキングを編集して作成した PII マーキングを適用します。そうすると、PII マーキングが適用されると影響を受けるすべての下流のデータセットが表示されます。
データのすべての消費者に PII アクセスを持たせたくないため、パイプラインのどこかで機密性の高い DOB 列を削除したいと考えています。これを行うには、パイプラインをクリックして、PII マーキングを削除するのに最適な場所を確認します。通常、これはデータセットを選択したときに下部にプレビュー表示を開くことで行われ、データと列を確認できます。
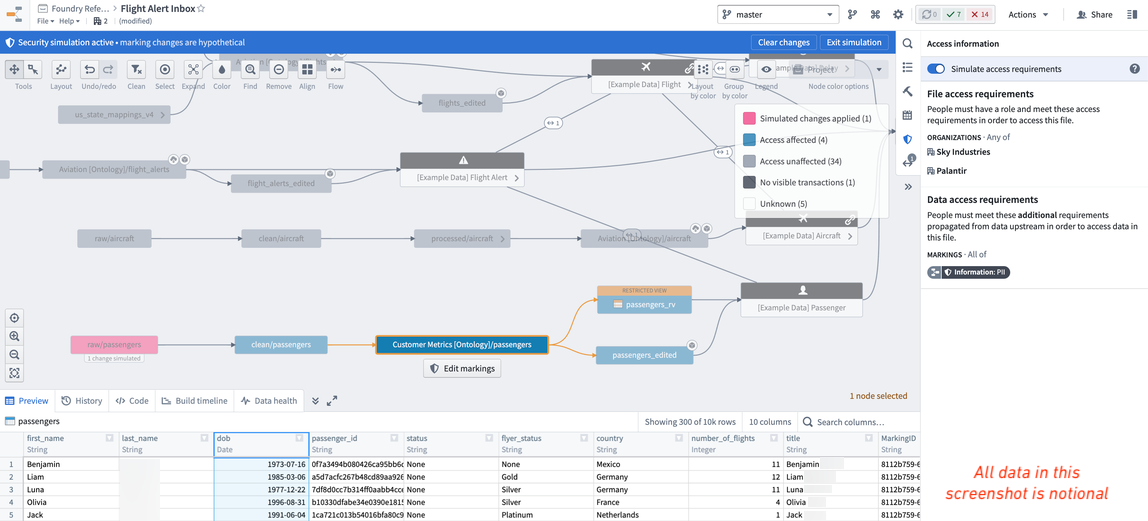
私たちの仮想的な例では、PII マーキングがオントロジーのデータセットまで伝播し、PII にアクセスできないすべてのエンドユーザーがロックアウトされることがわかります。したがって、パイプライン内でできるだけ長く機密データを保持することが最善であり、乗客データのオントロジーバージョン(つまり、/Sky Industries/Customer Metrics [Ontology]/passengers)で「dob」列を削除することにしました。
まもなく継承されるマーキングを削除する
データフローの表示で、Customer Metrics [Ontology]/passengers データセットをクリックし、コードをクリックしてリポジトリで表示をクリックします。これにより、この仮想データセットを作成するために使用されたコードリポジトリが開きます。コードリポジトリでは、1) ブランチを作成し、2) 機密性の高い列(つまり、dob 列を削除)を削除し、3) 入力データセットからまもなく継承される PII マーキングを削除し、4) プルリクエストを作成します。継承されたマーキングと組織を削除する方法に関するドキュメントを確認することをお勧めします。
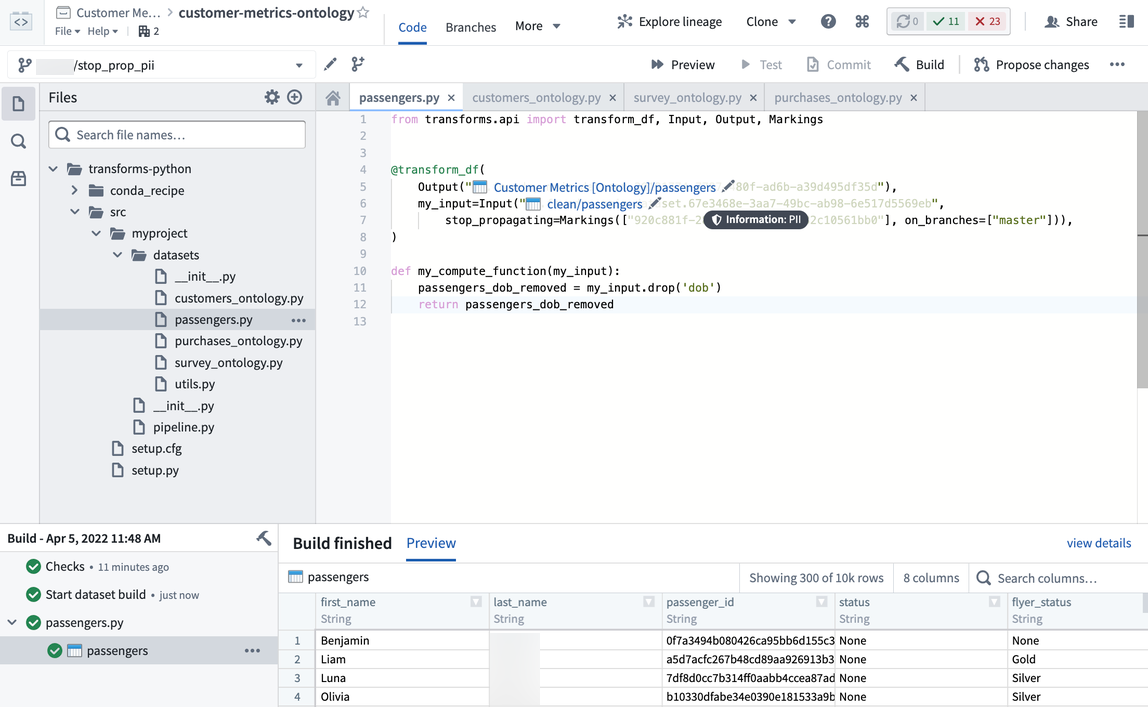
PII マーキングの伝播を停止するプルリクエストが同僚に承認された後、このデータセットとそれ以降のすべてのデータセットをビルドする必要があります。これにより、最新のデータセットトランザクションがすべて「伝播停止」のマーキングを追加することになります。また、APPEND または UPDATE トランザクションタイプには、特別な注意が必要な考慮事項があります。ただし、この例では、Foundry のデフォルトのトランザクションタイプである SNAPSHOT としてすべてがビルドされています。
マーキングを適用する
マーキングを適用する前に、それが予想どおりのデータセットに伝播し、他のデータセットには影響しないことを確認したいと考えています。これを行うには、パイプラインのデータフローの表示を再度開き、シミュレーションモードをオンにし、raw/passenger データセットにマーキングを適用して、ontology/passenger データセットが影響を受けないことを確認します。これは、前のセクションで適用された stop_propagating ロジックが正しく適用されたことを意味します。
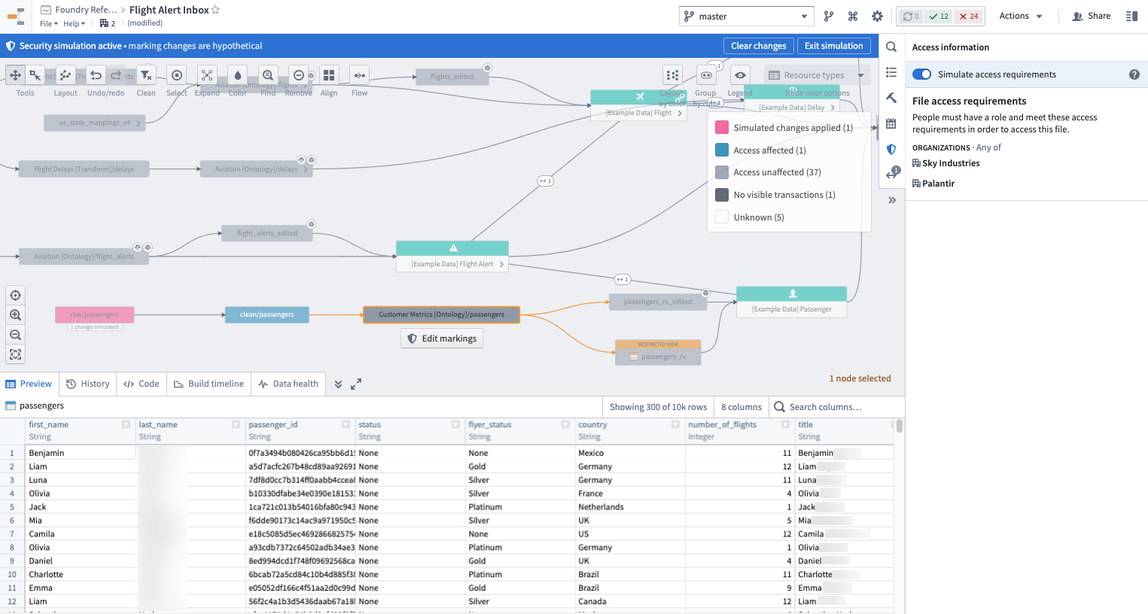
これで、マーキングを適用する準備が整いました。これは、仮想データのスクリーンショットで示されています。これを行うには、raw/passenger データセットに移動し、セキュリティヘルパーを開いてマーキングを適用します。保存をクリックすると、PII マーキングがすぐに適用され、すぐに下流に伝播します。これは、データフローを見て、マーキングがあるデータセットにマーキングバッジが表示されることで確認できます。機密性の高い PII データを保護することに成功しました。