注: 以下の翻訳の正確性は検証されていません。AIPを利用して英語版の原文から機械的に翻訳されたものです。
マーキング
概要
マーキングは、Foundry 内のファイル、フォルダー、およびプロジェクトに対する追加のアクセス制御レベルを提供します。マーキングは、特定の条件を満たすユーザーにのみ可視性と操作を制限する資格基準を定義します。リソースにアクセスするには、ユーザーはそのリソースに適用されるすべてのマーキングのメンバーでなければなりません。プラットフォーム管理者は通常、組織内でマーキングを管理します。
マーキングへのアクセスは二者択一方式です(すべてか何もないか)。役割に関係なく、ユーザーがすべてのマーキング要件を満たさない限り、ファイルへのアクセスは一切できません。
マーキングは、データ保護責任者が特定のデータカテゴリーにアクセスできるユーザーを中央で管理および監査することを目的としています。マーキングの一般的な使用例は、個人を識別できる情報 (PII) へのアクセスを制限することです。たとえば、一連のトレーニングを完了した後にのみ、機密性の高い PII データにアクセスできるユーザーグループがあるかもしれません。プラットフォーム管理者は PII マーキングを作成し、それを機密性の高いデータセットに適用することができます。このマーキングにより、PII へのアクセスが適切なユーザーに制限され、そのグループ以外に共有されることはありません。
マーキングは必須の制御であり、役割は任意の制御です。必須の制御は、データにアクセスするために特定のマーキングを持つことをユーザーに要求することによりアクセスを制限します。マーキング自体のアクセス拡張権限は、マーキングを削除するために必要な中央管理の権限です。たとえば、ユーザーが PII マーキングが付いたデータセットのオーナー役割を持っていても、マーキングのアクセス拡張権限を持っていない限り、そのマーキングを削除することはできません。対照的に、任意の制御はアクセスを拡張し、中央の制限なしにデータ共有ワークフローを通じて付与されます。たとえば、リソースのオーナー役割を持つユーザーは、別のユーザーまたはグループにオーナー役割を付与することができます。
マーキングは論理積(boolean AND)であるため、ファイル、フォルダー、またはプロジェクトのすべてのマーキングのメンバーでなければアクセスできません。
継承
マーキングはファイル階層および直接の依存関係に沿って継承され、トランスフォームおよび分析ロジックを通じて伝播します。マーキングされたファイル、フォルダー、またはプロジェクトから派生したすべてのリソースは、マーキングが明示的に削除されない限りマーキングを引き継ぎます。データがプラットフォーム内のどこにあるかに基づく役割ベースのアクセスとは異なり、マーキングはデータと共に移動します。ファイルは ファイル階層 および/または データ依存関係 を介してマーキングを継承する場合があります。
ファイル階層
ファイルは含まれるプロジェクトまたはフォルダーを介してマーキングを継承する場合があります。プロジェクトまたはフォルダーにマーキングがある場合、その中のすべてのファイルまたはフォルダーはマーキングを継承します。これは、プロジェクトまたはフォルダーへのアクセスを制限することが、常にその中のすべてのものへのアクセスを制限することを意味します。
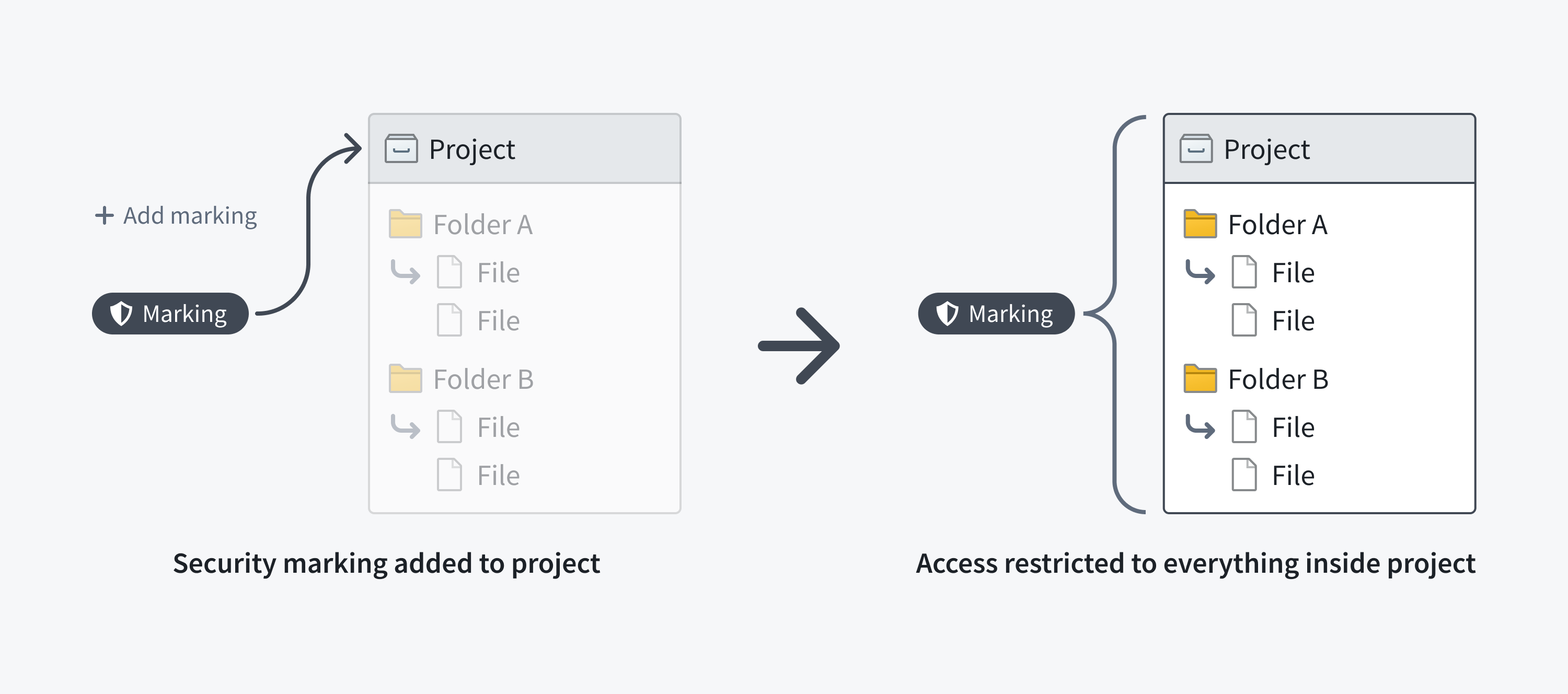

以下のスクリーンショットは、ファイル階層に沿って継承された概念的なデータセットにおける PII マーキングを示しています。
データ依存関係
データセットへのアクセスを制限することは、常にそれに由来するすべてのデータへのアクセスを制限します。これは、データセットファイルが上流のデータセットのように依存するデータセットからマーキングを継承する可能性があるためです。データセットにファイルマーキングがある場合、それに依存するすべてのデータセットはそのマーキングを継承し、継承されたマーキングはデータマーキングとして知られています。
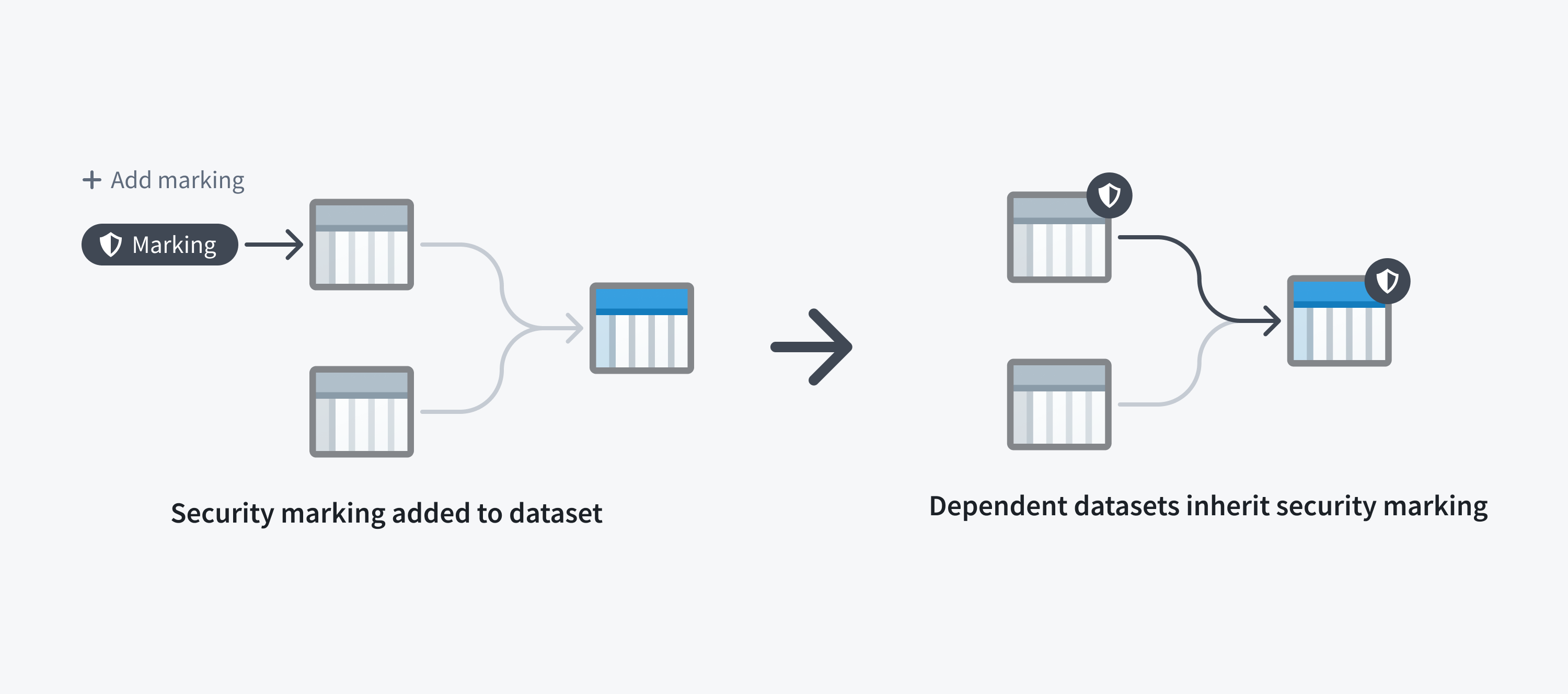
以下のスクリーンショットは、データ依存関係に沿って継承された概念的なデータセットにおける PII マーキングを示しています。
ユーザーが上流のデータセットから継承されたデータアクセス要件を満たさずにファイルアクセス要件を満たす場合があります。このシナリオでは、ユーザーは派生データセットの存在を検出し、ファイルメタデータを表示できますが、ファイルデータセット内のデータにアクセスすることはできません。これは、ファイルマーキング要件を満たさないためにリソースを発見できない場合とは異なります。
マーキングの適用は敏感な操作と見なされます。なぜなら、マーキングはすべてのファイルおよびデータ依存関係に沿って即座に継承されるためです。これにより、下流の他のユーザーが意図せずロックアウトされる可能性があります。マーキングを使用する前に、マーキングの適用 の安全な方法を確認してください。
同様に、マーキングの削除も敏感な操作と見なされます。マーキングは、元々適用されたファイル、フォルダー、またはプロジェクトから削除することができ、これにより下流のファイルおよびデータ依存関係からマーキングが即座に削除されます。また、マーキングはトランスフォーム内で削除することもでき、これにより データ依存関係 に沿ってのみマーキングが削除されます。マーキングを削除する前に、マーキングの削除 の安全な方法を確認してください。
マーキングの使用
マーキングは、ファイル、フォルダー、およびプロジェクトなどのリソースへのアクセスを制限するために設計されています。マーキングはアクセスを提供するために使用されるべきではありません。ユーザーが特定のマーキング基準を満たすと、そのマーキングおよび関連するリソースへのアクセス権を受け取ります。ただし、アクセスの資格があるユーザーが常にアクセス権を持つべきではありません。ユーザーは、プロジェクトの役割ベースの権限に基づいてファイルへのアクセス権を付与されるべきです。
たとえば、PII マーキングが Foundry のすべての従業員 PII を含むデータへのアクセスを制限するために使用されると仮定します。この PII は、財務記録(たとえば、社会保障番号)や健康記録(たとえば、年齢、性別、診断に関する情報)、名前や住所などの個人データに含まれる可能性があります。
PII を扱うためには、ユーザーは適切なトレーニングを受ける必要があります。たとえば、財務部門のユーザーが必要なトレーニングを完了し、PII マーキングへのアクセス資格を取得したとします。このユーザーは財務部門のため、財務データプロジェクトのViewer 役割が付与されます。このユーザーが従業員 PII を含む他のデータを見る資格があっても、プロジェクト内での役割がユーザーのアクセスレベルを制御します。
マーキングは、追加の保護が必要な機密データに対するアクセス制限を定義するために使用されるべきです。データの感度に関連するマーキングを適用する方法はいくつかあります。
- 機密データカテゴリーごとの 1 つのマーキング
- 最も一般的に使用されるマーキング構造では、機密データのカテゴリーごとに 1 つのマーキングが作成されます。各マーキングは、そのデータカテゴリーを含むすべてのリソースへのアクセスを制限します。データに複数のタイプの感度がある場合、すべての対応するマーキングがリソースに適用されます。関連するすべての機密カテゴリーにアクセスする資格があるユーザーのみがリソースにアクセスできます。
- マーキング要件と感度タイプの明確な基準を設定することが有益です。たとえば、性別、年齢、民族などの個人属性を含むデータを
PIIマーキングでマーキングすることができます。
- 機密データ所有者ごとの 1 つのマーキング
- この構造では、データ所有者が自分のデータへのアクセスをどのように制限するかを決定できます。機密データ所有者ごとの 1 つのマーキングにより、チームやユーザーグループが所有する機密データがマーキングされ、データ所有者の裁量でユーザーがマーキングへのアクセス権を取得できます。たとえば、営業チームが生成、消費、管理するすべてのデータは
Sales Dataマーキングでマーキングされ、データ所有者が適格なユーザーにのみ営業データへのアクセス権を付与します。 - データ所有者にデータ資産に対する追加の制御を提供するために、マーキングは伝播します。これは、データにアクセスできるユーザーがデータから派生リソースを作成して他のユーザーと共有しようとした場合、データ所有者が他のユーザーにマーキングへのアクセス権を付与して派生リソースへのアクセスを解除する必要があることを意味します。
- この構造では、データ所有者が自分のデータへのアクセスをどのように制限するかを決定できます。機密データ所有者ごとの 1 つのマーキングにより、チームやユーザーグループが所有する機密データがマーキングされ、データ所有者の裁量でユーザーがマーキングへのアクセス権を取得できます。たとえば、営業チームが生成、消費、管理するすべてのデータは
- 異なるパイプラインステージのマーキング
- データセットは Foundry に未処理の形式で取り込まれ、通常、エンドユーザーと共有する準備が整う前に処理および変換されます。未処理データには、下流のユーザーに適さない機密情報が含まれている場合があり、管理者は
Raw Dataマーキングを適用して不正なユーザーからアクセスを制限することを選択する場合があります。PII を削除するために処理された後(ハッシュ化や暗号化など)、管理者はRaw Dataマーキングを削除し、パイプラインのさらに先でデータを安全にするために他の関連マーキングを適用できます。
- データセットは Foundry に未処理の形式で取り込まれ、通常、エンドユーザーと共有する準備が整う前に処理および変換されます。未処理データには、下流のユーザーに適さない機密情報が含まれている場合があり、管理者は
- データ検出を制限するためのマーキングの使用
- マーキングは、すべてまたは何もない方式でアクセスを制限するため、ファイル、フォルダー、またはプロジェクトなどのリソースの存在を隠す必要がある場合に使用する必要があります。マーキングは、マーキングへのアクセス権を持たないユーザーが検索結果やプロジェクト/フォルダー ビューでマーキングされたデータを表示しないようにすることができます。
Foundry におけるマーキングの実装は、上記の戦略を組み合わせて使用する場合があります。たとえば、パイプラインの最初に Raw Data マーキングを適用し、処理後に機密データカテゴリーごとのマーキングを適用することができます。
例: 医療データの保護
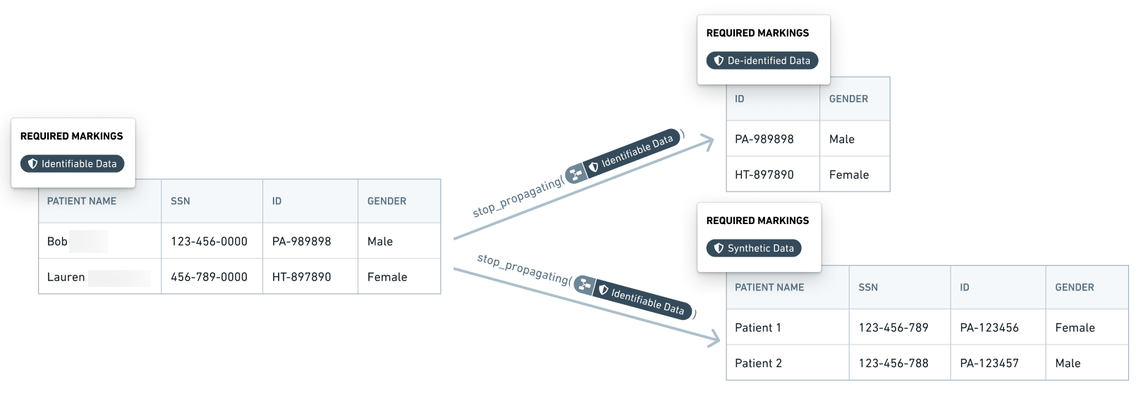
仮想上の医療機関における 3 層の機密患者データを考えてみます。
- 合成データ: これは実際の患者記録を模倣するために作成された最も機密性の低いデータです。すべての合成データは
Synthetic Dataマーキングでマーキングされます。 - 匿名化データ: このタイプのデータには一部の機密フィールドが含まれていますが、すべての直接識別子は削除されています。このデータは、他のデータファイルと組み合わせて患者を識別するために使用される可能性があります。このようなデータはすべて
De-identified Dataマーキングでマーキングされます。 - 識別子を含むデータ: このタイプのデータには個々の患者を直接識別するために使用できる識別子が含まれている可能性があります。これは患者データの最も高い機密レベルです。このようなデータはすべて
Identifiable Dataマーキングでマーキングされます。
この場合、データ層は階層的であり、Identifiable Data マーキングへのアクセス権を持つユーザーは De-identified Data マーキングおよび Synthetic Data マーキングへのアクセス権も持っています。同様に、De-identified Data マーキングへのアクセス権を持つユーザーは Synthetic Data マーキングへのアクセス権も持っています。
Foundry 内では、識別子を含むデータ(Identifiable Data マーキングでマーキングされたもの)は、識別子フィールドを削除することで匿名化データ(De-identified Data マーキングでマーキングされたもの)に変換されます。マーキングマネージャーまたはデータ所有者は、匿名化データに識別子が存在しないことを確認するために変換ロジックの変更をレビューします。追加の複雑なトランスフォームにより合成データが生成され、Synthetic Data マーキングでマーキングされます。これらの変換ステージごとに、以下のスクリーンショットに示されているように、以前のマーキングが削除され、データの更新状態を示すマーキングが追加されます。
例: 調査データの保護
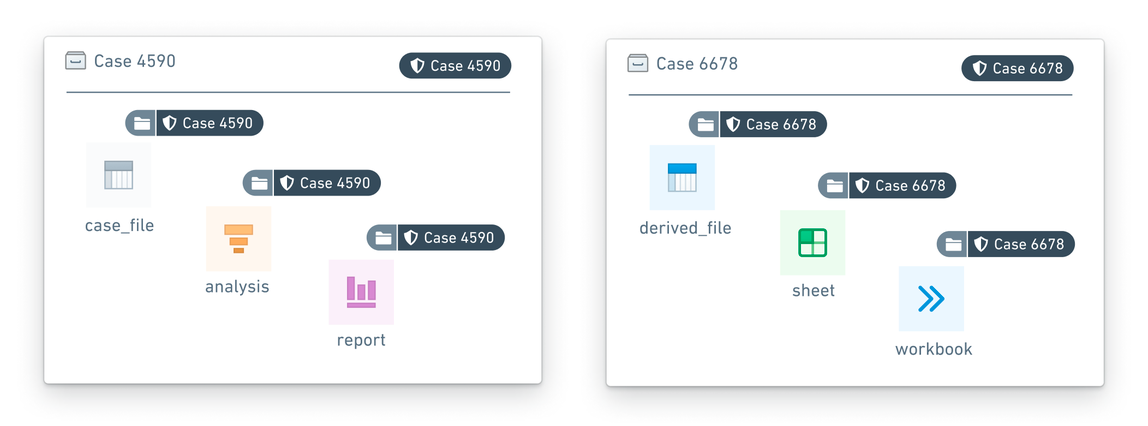
ケース調査データは特に機密性が高く、たとえばマネーロンダリング防止調査の場合も同様です。あるケースのデータは他のケースのデータと混合してはいけません。さらに、あるケースのデータは、別のケースをレビューしている調査員には表示されるべきではありません。マーキングはこれらのケースアクセス制限を可能にします。
- 特定のケースに関するデータ(リソース、画像、データセット、その他の証拠を含む)は、ケース番号を表す
Case - xxxxxxマーキングでマーキングされます。 - 特定のケースの調査員だけが、そのケースマーキングへのアクセス権を付与されます。調査員は特定の時点で複数のケースにアクセスできる場合がありますが、そのようなアクセスは個々のマーキングによって区別されます。
例: 銀行データの保護
仮想上の銀行では、各チームまたは部門が生産または管理するデータに対する完全な制御を行使します。つまり、各チームは、データ資産全体または一部にアクセスできる他のチームを決定します。この例では、組織設定を簡略化するために、対応するマーキングを持つチームを考慮します。コンシューマーファイナンス、内部コンプライアンス、およびマーケティングです。
- コンシューマーファイナンスチームおよびマーケティングチームが内部コンプライアンスチームにそれぞれ
Consumer FinanceおよびMarketingマーキングへのアクセス権を付与すると仮定します。その後、内部コンプライアンスチームは、データが事前承認されたワークフローに適切に使用されていることを確認し、四半期ごとの監査を実施できます。 - 四半期ごとの監査結果は
Internal Complianceマーキングが付いたレポートにキャプチャされ、他の 2 つのマーキングは削除されます。これらの監査