注: 以下の翻訳の正確性は検証されていません。AIPを利用して英語版の原文から機械的に翻訳されたものです。
機密区分に基づくアクセス制御
機密区分に基づくアクセス制御は、Foundryではデフォルトで有効化されていません。機密区分マーキングは機関ごとに異なるため、Palantir環境ごとに異なる設定が可能です。機密区分マーキングの設定にはPalantirの関与が必要です。
機密区分に基づくアクセス制御(CBAC)は、機密の政府情報を保護するために必須の制御です。CBACマーキング(機密区分マーキングとも呼ばれます)は、特定の機密区分マーキングを持つユーザーのみが情報にアクセスできるように制限します。
機密区分マーキングへのアクセスは、Palantirプラットフォーム外で行われるセキュリティクリアランスプロセスと関連していることがあります。一般的に必須の制御と同様に、機密区分マーキングは任意の役割やリソースに適用される必須マーキングと組み合わせることができます。
機密区分マーキングの主な特徴
機密区分マーキングに特有の3つの特徴があります。
- 階層構造: 機密区分マーキングの一般的な使用例は、情報の機密性が階層的に定義されている場合に、機密情報へのアクセスを制限することです。たとえば、あるユーザーグループは「機密」以下に分類されたデータにのみアクセスできるとします。別のユーザーグループは「最高機密」以下に分類された機密情報にアクセスでき、「機密」データを含むことができます。
- 機密区分マーキングの非連結要素: 非機密区分マーキングは連結的に機能し、リソースに適用されたすべてのマーキングをユーザーが持っている必要があります。機密区分マーキングには非連結要素があり、機密区分マーキングの非連結要素に属するグループの1つに所属するユーザーがCBACアクセス条件を満たすことができます。これは、異なる組織や国との共有を定義する際によく使用されます。たとえば、「国A」または「国B」のユーザーが機密区分マーキング内の非連結要素を満たすことができます(以下を参照)。
- 機密区分マーキングの普遍性: CBAC必須制御を使用する環境では、すべてのプロジェクトにプロジェクト分類を設定する必要があります。さらに、すべてのデータセットにはデータ分類が必要であるため、生のデータセット(つまり、入力がないデータセット)にはファイル分類が必要です。
主要な概念
機密区分マーキング
機密区分マーキングはカテゴリーで設定されます。たとえば、1つのカテゴリーはデータの種類を定義し、別のカテゴリーはそのデータがどのように配布されるべきか(つまり、共有されるべきか)を記述します。
ある機密区分には複数の機密区分マーキングが存在することがあります。ある機密区分は異なるカテゴリーからの機密区分マーキングで構成されることがあります。機密区分マーキングの有効な組み合わせを構成するルールはPalantirによって設定され、プラットフォーム上で適用されます。
連結および非連結の機密区分マーキングカテゴリー
機密区分マーキングカテゴリーの特徴的な機能は、非連結(OR)動作をサポートできることです。カテゴリーが連結(AND)である場合、ユーザーはそのカテゴリーから使用されるすべての機密区分マーキングにアクセスする必要があります。カテゴリーが非連結である場合、ユーザーはそのカテゴリーのいずれか1つのマーキングを持つことで、マーキングされた機密データにアクセスする許可を得ることができます。
全体の機密区分の構成要素は連結的に結合されます。これは、ある機密区分が複数のカテゴリーからの機密区分マーキングを含む場合、ユーザーは各機密区分マーキングカテゴリーからのすべての要素を満たす必要があることを意味します。
単純な構成を考えてみましょう。1つのカテゴリーと2つの機密区分マーキングがあります。以下の単純な構成には、マーサ・ワシントン(mwashington)とジョン・アダムズ(jadams)の2人のユーザーがいます。
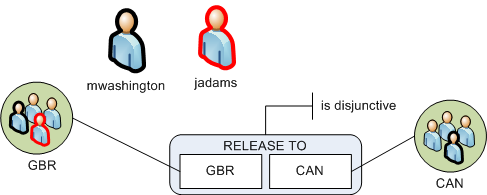
mwashingtonユーザーはGBRとCANの機密区分マーキンググループの両方に属しています。jadamsユーザーはGBRグループにのみ属しています。RELEASE TOカテゴリーは非連結であるため、ユーザーは少なくとも1つのマーキングにアクセスできる必要があります。非連結カテゴリーでは、機密区分マーキングの1つのマーキングにアクセスできるユーザーは、同じカテゴリーの他のマーキングもラベル付けされている場合でもデータを表示できます。つまり、GBR、CANで分類されたデータは、mwashingtonまたはjadamsのどちらかがアクセスできるため、表示することができます。
前の例は単一のカテゴリーを単独で示しています。実際には、機密区分マーキングは複数のカテゴリーのマーキングを含むことができます。
ファイルとデータの分類
ファイル分類は、ファイルを発見するためにユーザーが満たさなければならない機密区分マーキングです。これは、プロジェクトの最大分類や他の必須マーキングなどの他の要件に加えて必要です。
データ分類はデータセットなどの特定の種類のファイルに適用されます。データ分類は、ユーザーがファイル内のデータを表示するために満たさなければならない分類を指します。ユーザーはデータ分類を満たさなければファイル内のデータを表示できませんが、データセットの存在を発見し、そのメタデータ(名前、説明、スキーマなど)を表示する能力には影響しません。データ分類は直接編集できません。代わりに、データ分類は以下を組み合わせて形成されます。
- リソースのファイル分類(設定されている場合)。
- すべての上流のデータ依存関係のデータ分類。
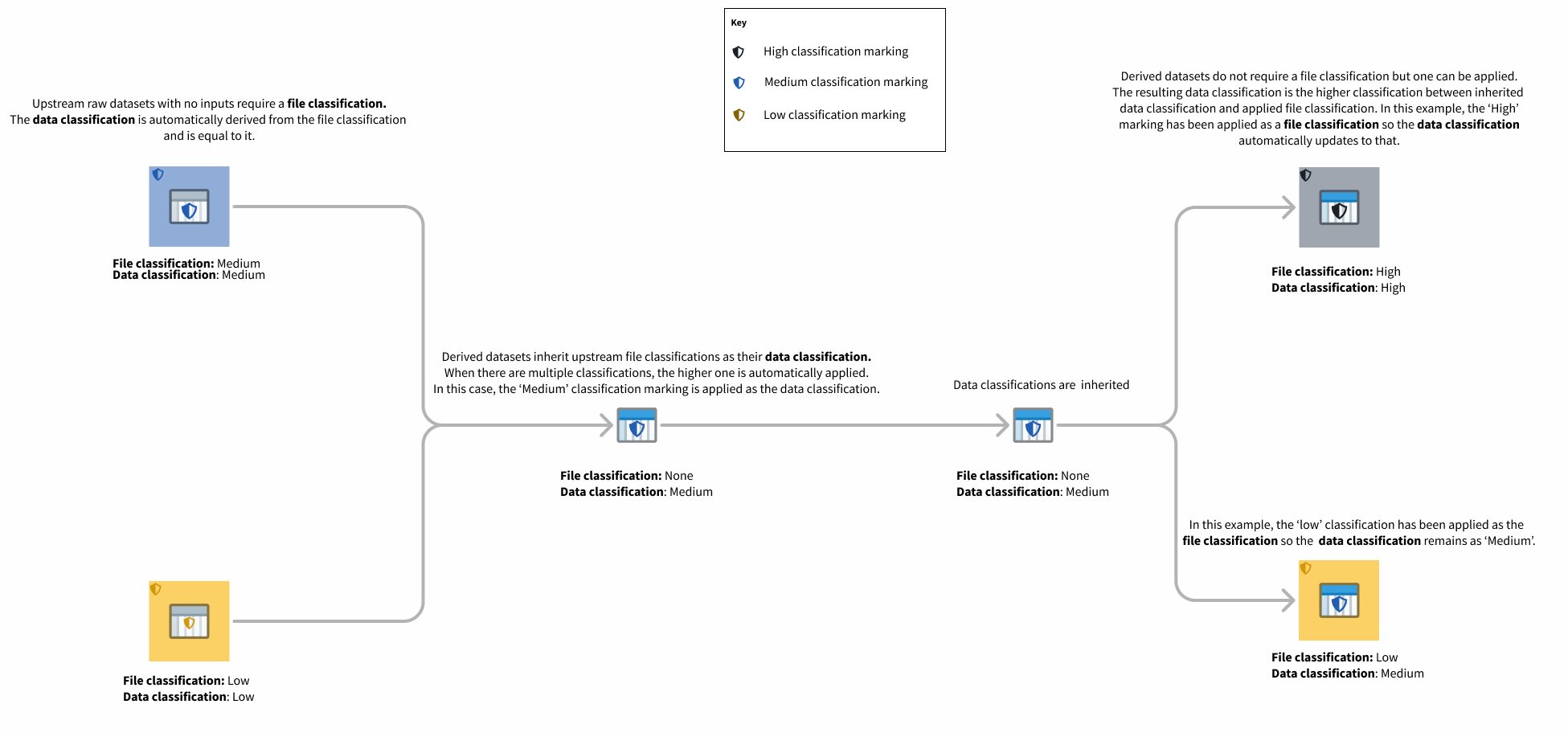
これは、データ分類が常にファイル分類およびすべての上流データ依存関係のデータ分類と同じかそれ以上に厳しいことを意味します。
ファイル、データ、およびプロジェクトの分類は、他の適用可能なアクセス要件とともにPalantirプラットフォームで伝達されます。データ分類とは異なり、自動的に継承されるファイル分類は、以下に示すようにリソースサイドバーで編集できます。
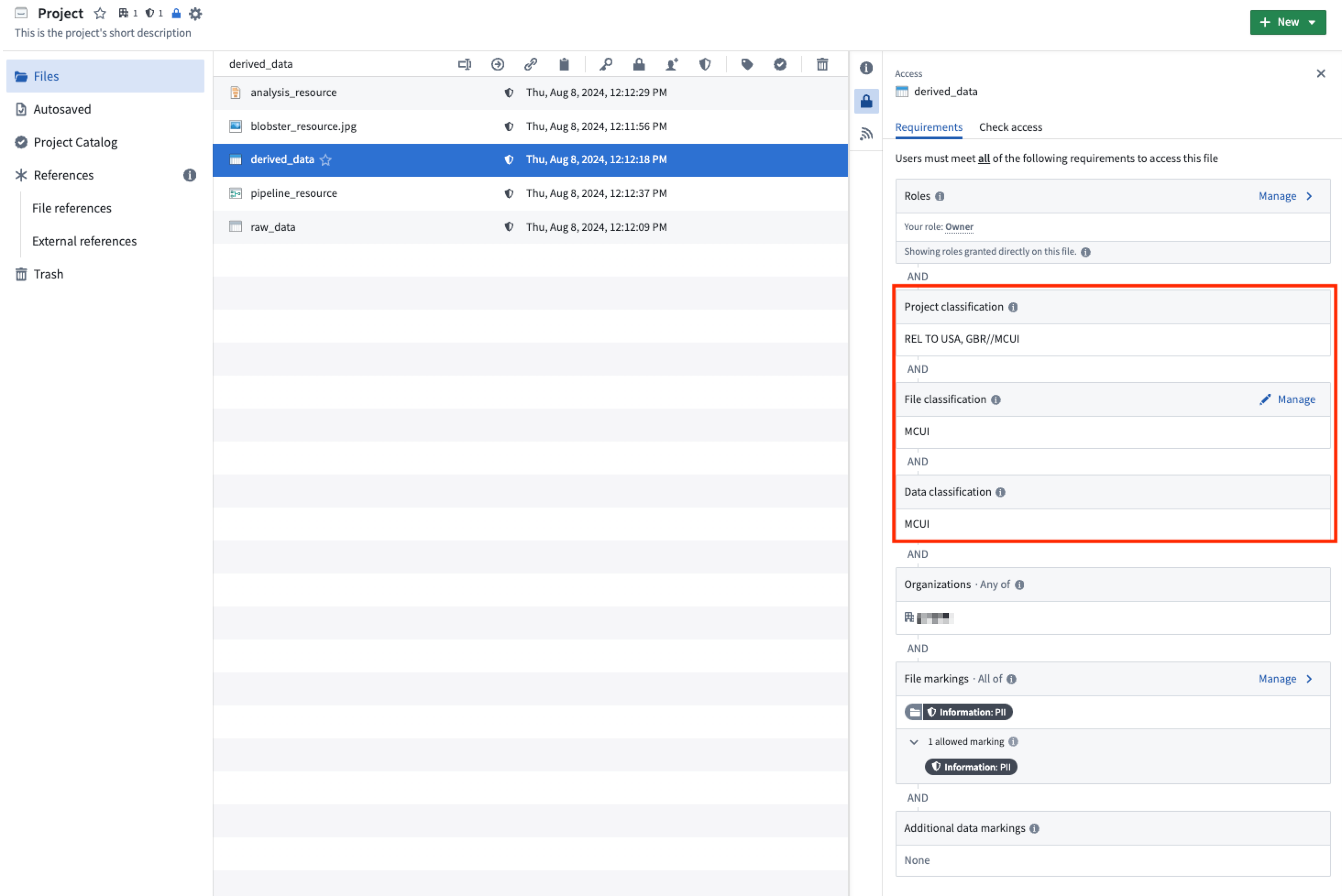
入力上流データセットのない新しい非導出データセットを作成する際には、作成するユーザーがファイル分類を設定する必要があります。
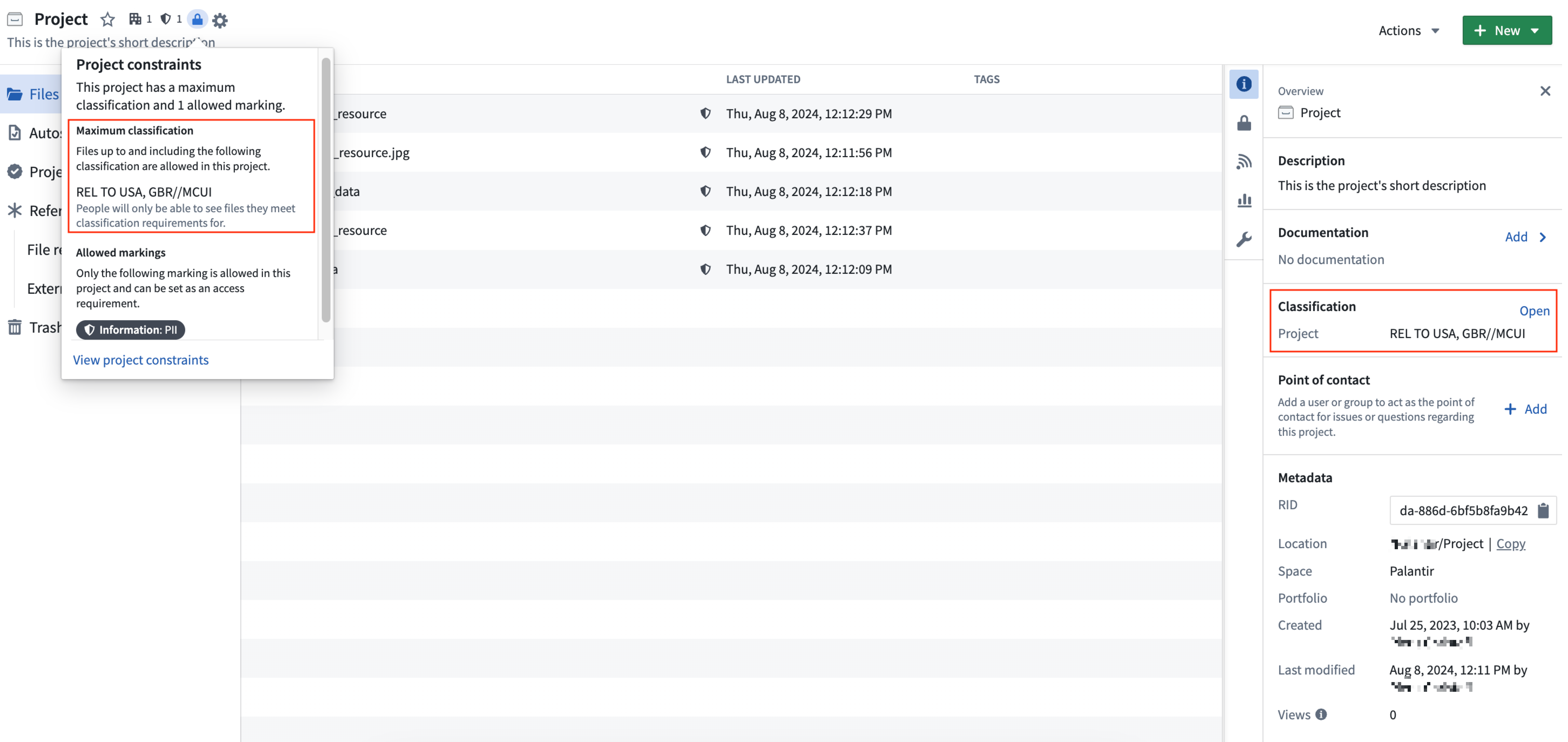
プロジェクト分類
プロジェクト分類は、プロジェクトの最大分類としても参照されます。機密区分マーキングを使用する環境のすべてのプロジェクトは、作成時にプロジェクト分類を設定する必要があります。
プロジェクト分類は2つの動作を管理します。
- プロジェクト分類は、プロジェクトの存在を発見し、内部のリソースにアクセスできるユーザーを制御します。ユーザーはプロジェクトを発見したり、そのリソースにアクセスしたりするためにプロジェクト分類を満たす必要があります。
- プロジェクトの最大分類よりも高いデータまたはファイル分類を持つリソースは、プロジェクト内に作成または移動することはできません。プロジェクトの最大分類と同じかそれ以下の分類のリソースはプロジェクト内に存在することができますが、プロジェクトの分類を満たすユーザーにのみ表示されます。
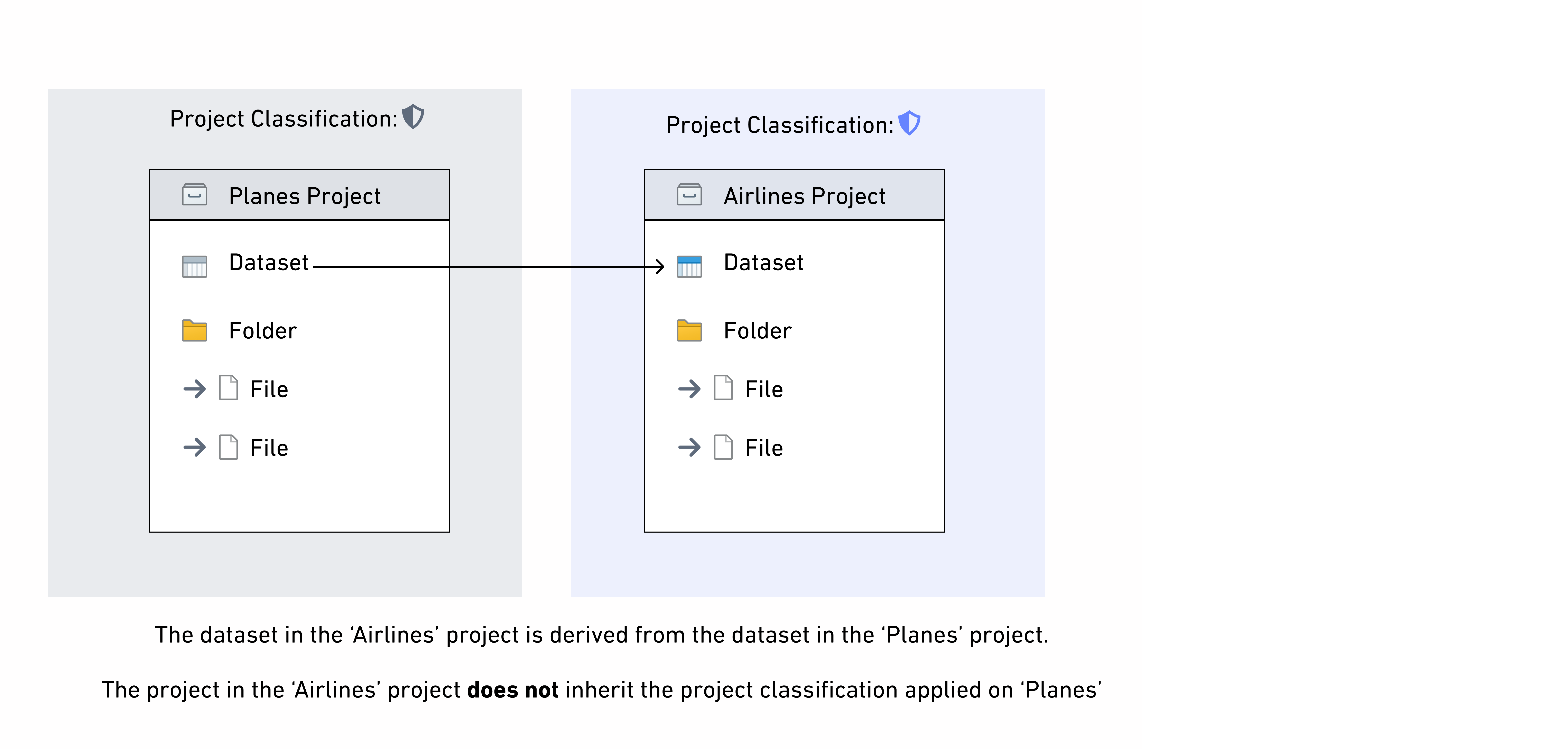
別のプロジェクトの上流データセットにファイル分類として高い分類が追加され、このプロジェクト内のデータセットにデータマーキングとして継承された場合、そのデータマーキングはプロジェクトの最大分類に違反します。
- この場合、データは引き続きその高い分類で保護されますが、警告が表示され、違反が解決されるまでデータセットまたはその下流にあるプロジェクト内のリソースを構築することはできません。
- 違反は、上流データセットの分類を修正するか、その上流データセットを入力から削除してデータセットを再構築するか、プロジェクトの最大分類を更新することで解決できます。これはプロジェクト制約違反と同じ動作です。
プロジェクト分類はプロジェクト内のデータセットのデータ分類に影響を与えません。したがって、プロジェクト分類はデータ依存関係に沿って継承されません。他のプロジェクトに導出された下流データセットがある場合、継承されるのはデータ分類のみです。これは、下流データセットに継承されるプロジェクトマーキングの動作とは異なります。