注: 以下の翻訳の正確性は検証されていません。AIPを利用して英語版の原文から機械的に翻訳されたものです。
セキュリティ監査
概要
監査ログは、Foundry ユーザーによって行われた操作を理解するための主要な手段です。
Foundry の監査ログには以下の情報が含まれています。
- 誰 が操作を行ったか
- 何 の操作が行われたか
- いつ 操作が行われたか
- どこで 操作が行われたか
場合によっては、監査ログにはユーザーの名前やメールアドレスなどの個人識別情報 (PII) が含まれることがあります。そのため、監査ログの内容は機密性が高く、必要なセキュリティ資格を持つ者のみが閲覧するべきです。
監査ログは通常、顧客が所有するセキュリティ情報イベント管理 (SIEM) ソリューションなどの目的に特化したシステムに取り込まれ、監視に利用されます。
このガイドでは、監査ログの抽出と利用のプロセスを 2 つのセクションで説明します。
顧客は以下のメカニズムを通じて独自の監査ログをキャプチャおよび監視することを強く推奨します。詳細なガイダンスについては Monitoring Security Audit Logs を参照してください。
監査の配信
監査ログは、顧客のセキュリティインフラストラクチャおよび SIEM 要件に応じて、いくつかのメカニズムを通じて下流消費のために配信されます。Foundry サービスによって生成された監査ログのバッチは、24 時間以内にコンパイル、圧縮され、ログバケットに移動されます (多くの場合 S3 環境依存)。ここから、Foundry は Audit Export To Foundry を介して顧客にログを直接配信できます。
Audit Export to Foundry
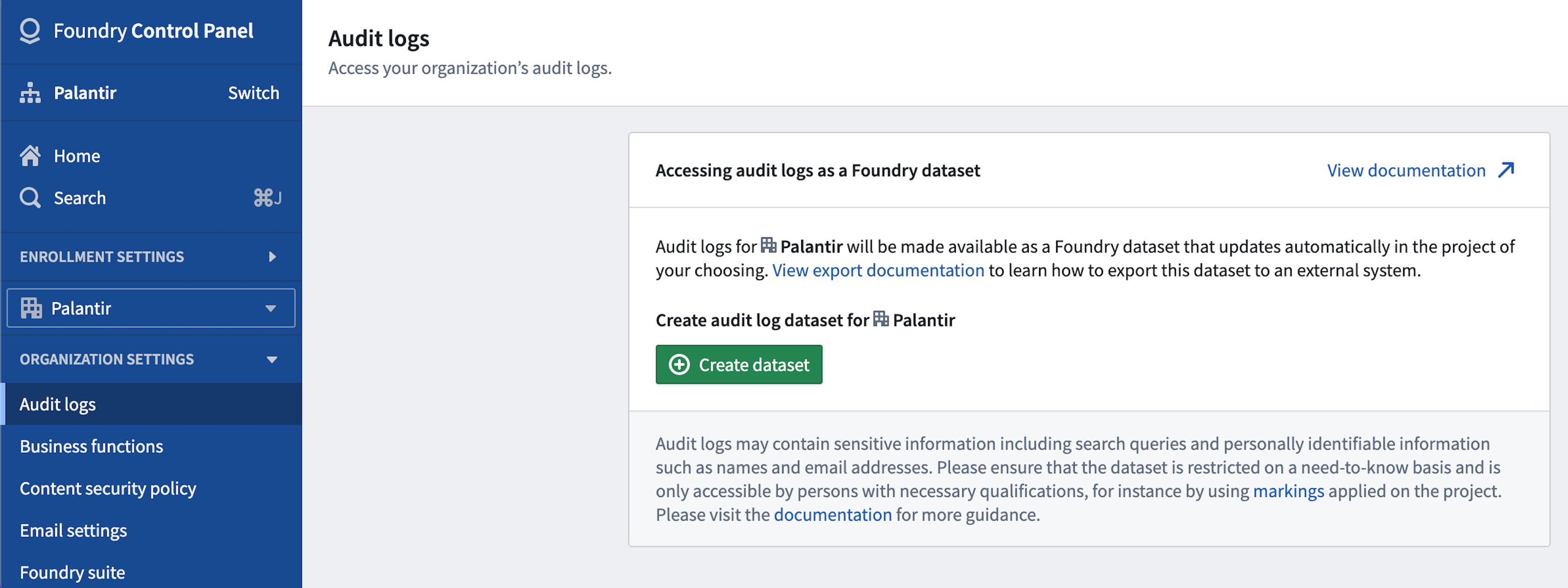
監査ログは、組織ごとに Foundry データセットに直接エクスポートすることができます。設定の一環として、組織管理者は Foundry ファイルシステム内のどこにこの監査ログデータセットが生成されるかを選択します。
ログデータがデータセットに着地すると、顧客は Foundry の Data Connection アプリケーションを介して監査データを外部 SIEM にエクスポートすることを選択できます。
エクスポート権限
監査ログをエクスポートするには、対象の組織に対して audit-export:orchestrate-v2 操作が必要です。これは Control Panel の Organization administrator ロールを介して Organization permissions タブで付与できます。詳細は Organization Permissions を参照してください。
エクスポート設定
Audit Export to Foundry を設定するには:
- Foundry Control Panelに移動します。
- 左側のサイドバーで、ドロップダウンメニューから該当する組織を選択します。
- 左側のサイドバーで Organization Settings の下にある Audit Logs を選択します。
- Create dataset を選択して監査ログデータセットを生成します。このデータセットの場所を Foundry 内で選択します。デフォルトでは、監査ログデータセットは上記で選択した組織のマーキングが付けられます。詳細は Organization Markings を参照してください。
- 任意で、指定した日付以降のイベントにこのデータセットを制限するための開始日フィルターを設定します。
- 任意で、エクスポートデータセットにログが保持される期間を制限するための保持ポリシーを設定します。保持ポリシーは、ログエントリ自体のタイムスタンプではなく、エクスポートデータセットにログが追加された取引のタイムスタンプに基づいています。関連する取引を削除するには、削除されるまでに最大 7 日かかる場合があります。以下は、この仕組みを実際にどのように機能するかを示す 2 つの例です。
- 例 1:
- 開始日: 1 年前
- 保持ポリシー: 90 日
- この場合、エクスポートデータセットには最初に過去 1 年間のログが含まれます。データセットの作成から 90 日後に保持ポリシーが発効し、データセットに最初に含まれていた全期間ではなく、直近 90 日間のログのみが保持されます。実際には、古いログが削除される 90 日後にデータセットのサイズが大幅に減少します。
- 例 2:
- 開始日: 30 日前
- 保持ポリシー: 90 日
- このシナリオでは、エクスポートデータセットは最初に過去 30 日間のログを含みます。新しいログが追加されると、データセットは直近 90 日間のデータを保持するローリングウィンドウとして成長します。保持ポリシーに従って、取引が 90 日を超えると、ログは削除されます。
- 例 1:
大規模なスタックの場合、最初の数時間のビルドで空の追加取引が生成されることがあります。これは、パイプラインが監査ログのバックログを処理するため、予想される動作です。
監査ログの機密性のため、作成されたデータセットは必要に応じて制限され、必要な資格を持つ者のみがアクセスできるようにすることを強く推奨します。markings を使用して監査ログデータセットを制限し、識別情報や検索クエリなどの潜在的に機密性の高い使用詳細を表示できるプラットフォーム管理者のセットを指定します。
エクスポートを無効にする
エクスポートを無効にするには、監査ログデータセットをゴミ箱または別のプロジェクトに移動します。
監査ログデータセットを移動すると、そのデータセットのさらなるビルドは停止します。データセットを後でゴミ箱から復元するか、元のプロジェクトに戻しても、これらのビルドを再開する方法はありません。
監査ログの更新
ビルド時、監査ログデータセットは新しいログが利用可能になると特定の条件に従って追加されます (変更される可能性あり):
- 監査ログがログバケットに利用可能になると、通常は 24 時間以内に取り込みが行われ、エクスポートデータセットの上流にある非公開の中間データセットにログが配置されます。
- 新しいログは 10 分ごとに中間データセットからエクスポートデータセットに追加されます。各追加では最大 10 GB のログデータが引き出されます。10GB のログデータの追加は、通常、監査ログデータセットが最初に作成されたときのみ必要です。
- 新しいログデータが利用できない場合、エクスポートデータセットのスケジュールは 1 時間の間一時停止し、その後再開されます。
- ほとんどの場合、監査ログデータセットが完全に最新の状態になると、ジョブは毎時間実行され続けます。通常、3 つのジョブのうち 1 つは新しいデータを監査ログデータセットに追加します。他のジョブは追加の内容なしで中止されます。
- 各監査ログ追加の実行時間は、監査ログデータセットに追加される新しいログの量に比例します。
- エクスポートデータセットのビルドを制御するスケジュールは audit-export によって制御され、ユーザーの表示からは非表示です。
監査ログデータセットの分析
監査ログデータセットには非常に大量のデータが含まれる可能性があるため、集計や視覚化を行う前に、このデータセットを time 列を使用してフィルター処理することをお勧めします。フィルター処理には、Contour で効果的に分析できないほど大きい監査データセットのために、Pipeline Builder や Transforms を使用することをお勧めします。
監査スキーマ
Palantir 製品が生成するすべてのログは 構造化 されたログです。つまり、特定のスキーマに従っており、下流システムで信頼して使用できます。
Palantir の監査ログは現在 audit.2 スキーマ で提供されており、一般的には "Audit V2" と呼ばれています。更新されたスキーマである audit.3 または "Audit V3" は開発中ですが、まだ一般提供されていません。
audit.2 および audit.3 スキーマの両方で、監査ログはそれを生成するサービスによって異なる場合があります。これは、各サービスが異なるドメインを扱っており、説明する必要がある異なる懸念事項があるためです。この違いは audit.2 でより顕著です。
サービス固有の情報は主に request_params と result_params フィールドにキャプチャされます。これらのフィールドの内容は、ログを生成するサービスとログされるイベントによって形状が変わります。
監査カテゴリー
監査ログは、プラットフォームでユーザーが行ったすべての操作の要約された記録として考えることができます。これは通常、冗長性と精度の間の妥協点であり、過度に冗長なログはより多くの情報を含む一方で、理解しにくくなる可能性があります。
Palantir のログには、監査ログをサービス固有の知識をほとんど持たずに理解しやすくするための 監査カテゴリー という概念が含まれています。
監査カテゴリーを使用すると、監査ログは監査可能なイベントの結合として説明されます。監査カテゴリーは、data と metaData と logic などのコアコンセプトに基づいており、これらのコンセプトに対するアクションを説明するカテゴリーに分かれています。たとえば、dataLoad (システムからデータを読み込む)、metaDataCreate (データを説明するメタデータの新しい部分を作成する)、および logicDelete (システム内の論理を削除する。論理は 2 つのデータ間の変換を説明する) などです。
監査カテゴリーもバージョン変更を経ており、audit.2 ログの緩やかな形式から audit.3 ログの厳密で豊かな形式に変更されています。詳細は以下を参照してください。
利用可能な audit.2 および audit.3 カテゴリーの詳細なリストについては Audit log categories を参照してください。
監査ログの帰属
監査ログは、環境ごとに単一の ログアーカイブ に書き込まれます。監査ログが配信パイプラインを通じて処理されるとき、スキーマ にある uid および otherUids フィールドのユーザー ID が抽出され、ユーザーは対応する組織にマッピングされます。
特定のオーケストレーションに対してオーケストレーションされた監査エクスポートは、その組織に帰属する監査ログに限定されます。サービス (非人間) ユーザーによってのみ行われた操作は、通常、組織メンバーではないため、組織に帰属しません。ただし、クライアント資格情報付与を使用するサードパーティアプリケーションのサービスユーザーは、登録組織によってのみ使用され、その組織に帰属する監査ログを生成します。
Audit.2 ログ
audit.2 ログには、リクエストおよびレスポンスパラメーターの形状について サービス間の保証はありません。したがって、監査ログについての推論は通常、サービスごとに行われる必要があります。
audit.2 ログには、検索を絞り込むのに便利な 監査カテゴリー が表示される場合があります。ただし、このカテゴリーにはさらなる情報が含まれておらず、監査ログの他の内容を規定しません。さらに、audit.2 ログには監査カテゴリーが含まれていることが 保証されていません。カテゴリーが存在する場合、それらは request_params 内の _category または _categories フィールドに含まれます。
以下に audit.2 ログエクスポートデータセットのスキーマを示します。
| フィールド | タイプ | 説明 |
|---|---|---|
filename | .log.gz | ログアーカイブからの圧縮ファイルの名前 |
type | string | 監査スキーマバージョンを指定 - "audit.2" |
time | datetime | RFC3339Nano UTC 日時文字列、例: 2023-03-13T23:20:24.180Z |
uid | optional<UserId> | ユーザー ID (利用可能な場合); 最も下流の呼び出し元 |
sid | optional<SessionId> | セッション ID (利用可能な場合) |
token_id | optional<TokenId> | API トークン ID (利用可能な場合) |
ip | string | 発信元の IP アドレスのベストエフォート識別子 |
trace_id | optional<TraceId> | Zipkin トレース ID (利用可能な場合) |
name | string | 監査イベントの名前、例: PUT_FILE |
result | AuditResult | イベントの結果 (成功、失敗など) |
request_params | map<string, any> | メソッド呼び出し時に知られているパラメーター |
result_params | map<string, any> | メソッド内で導出された情報、一般的には戻り値の一部 |
Audit.3 ログ
Audit V3 は開発中であり、まだ一般提供されていません。
audit.3 ログは、ログ内容を理解するために特定のサービスを理解する必要性を減らすために、監査カテゴリーの使用を厳格にします。audit.3 ログは以下の保証を念頭に置いて生成されます。
- すべての監査カテゴリーは、適用される値/項目を明示的に定義します。たとえば、
dataLoadはロードされる正確な リソース を説明します。 - すべてのログは監査カテゴリーの結合として厳密に生成されます。これは、ログに自由形式のデータが含まれないことを意味します。
- 監査ログ内の特定の重要な情報は
audit.3スキーマのトップレベルに昇格されます。たとえば、すべての名前付きリソースはトップレベルに存在し、リクエストおよびレスポンスパラメーター内にも存在します。
これらの保証は、特定のログについて (1) どの監査可能なイベントがそれを作成したか、および (2) どのフィールドが含まれているかを正確に判断できることを意味します。これらの保証はサービスに依存しません。
以下に audit.3 スキーマを示します。この情報は包括的ではなく、変更される可能性があります。
| フィールド | タイプ |