注: 以下の翻訳の正確性は検証されていません。AIPを利用して英語版の原文から機械的に翻訳されたものです。
概要
トランスフォームは、1つ以上の入力を受け取り、単一の出力を返すロジックの部品です。入力と出力は、Foundryのデータセットやモデルであることができます。
現在、Code Workbookは以下の3種類のトランスフォームをサポートしています:
- コード トランスフォームは、ユーザーが選択した言語で任意のロジックを作成できるようにします。
- テンプレート トランスフォームは、再利用可能なシンプルでフォームベースのインターフェースの背後にコードを抽象化します。これにより、ワークブックやユーザー間で再利用できます。
- 手動入力 トランスフォームは、ユーザーがノードにデータを入力できるようにします。
トランスフォームの追加
Code Workbookに新たなトランスフォームを追加する方法はいくつかあります。
グラフの左上にある New Transform ボタンを使用して、追加するトランスフォームのタイプを選択します。例えば、新しいPythonコードノードを追加するには Python code を選択し、テンプレートブラウザを開くには Templates を選択します。
また、グラフ上の既存のトランスフォームをホバーし、表示される青色の + ボタンをクリックして選択ドロップダウンを開くこともできます。新しく作成されたトランスフォームは、選択したトランスフォームの子となります。
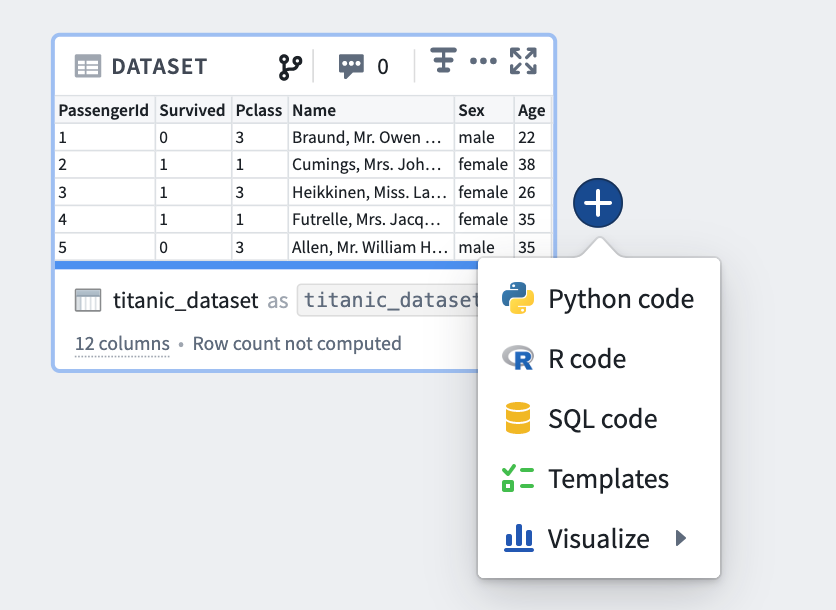
トランスフォームの編集
名前の編集
Code Workbookのトランスフォームはデータセットとして保存することができます。データの永続性について詳しくはこちらをご覧ください。
データセットとして保存されないトランスフォームは、コード内でトランスフォームを参照するためのワークブック固有のエイリアスで識別されます。入力データセットやデータセットとして保存されたトランスフォームの場合、Code Workbookは各データセットの2つの異なる名前を表示します:基礎となるFoundryデータセットの名前と、ワークブック固有のエイリアス。

エイリアスには以下のようないくつかの利点があります:
- ワークブック内のロジックに直感的な方法でデータセットを参照できます。例えば、異なる更新頻度に対応する異なるフォルダーに「Titanic」という名前の2つのデータセットがある場合、一方を
titanic_historical、もう一方をtitanic_daily_feedというエイリアスにすることができます。 - データセットのエイリアスを自由に編集しても、同じデータセットをFoundryの他の場所で使用している人々のデータセット名は変更されません。
- ブランチ上でデータセットのエイリアスを変更し、この変更をブランチ間でマージすることができます。
データセット名またはそのエイリアスを編集するには、ロジックパネルで名前をクリックし、新しい名前を入力し、編集が完了したらEnterキーを使用します。データセット名またはエイリアスを変更すると、他の名前を自動的に更新するかどうかを求められます。
入力の追加
任意のトランスフォームをクリックするとロジックパネルが開きます。入力を追加するには、上部の入力バーで + ボタンをクリックし、目的の入力をクリックします。
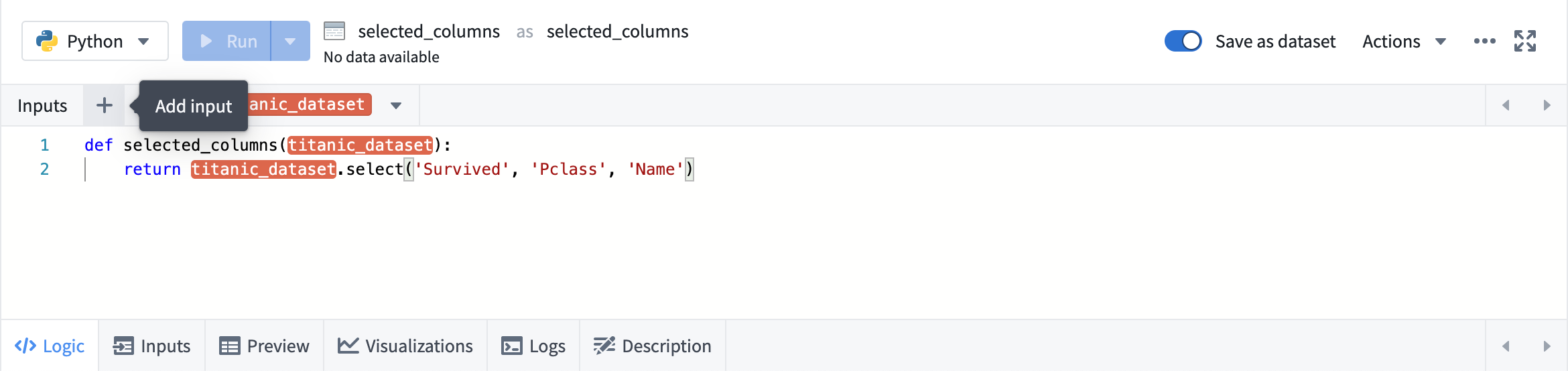
複数の入力を追加するには、+ の隣のボタンを使用します。
コード
コードトランスフォームは、現在のワークブックで使用している言語の基本的な構造が事前に入力されたコードエディタとして表示されます。各言語でコードを書く具体的な詳細については、言語のドキュメンテーションをご覧ください。
グローバルコード
グローバルコードパネルでは、ワークブック内の各コードトランスフォームの前に実行されるコードを定義することができます。グローバルコードパネルは、ワークブック内のトランスフォーム全体で利用可能な変数や関数を定義するために使用できます。
テンプレート
テンプレートトランスフォームの場合、ロジックパネルはテンプレートパラメータを編集するためのフォームを表示します。
- データセットパラメータをクリックした後、グラフ内の任意のデータセットをクリックして、そのパラメータの値として設定します。
- 列パラメータは、入力データセットが指定されていることに依存しています。指定された後、列名のドロップダウンリストから選択できます。
- 整数や文字列などの値パラメータの場合、カスタム値を入力できます。
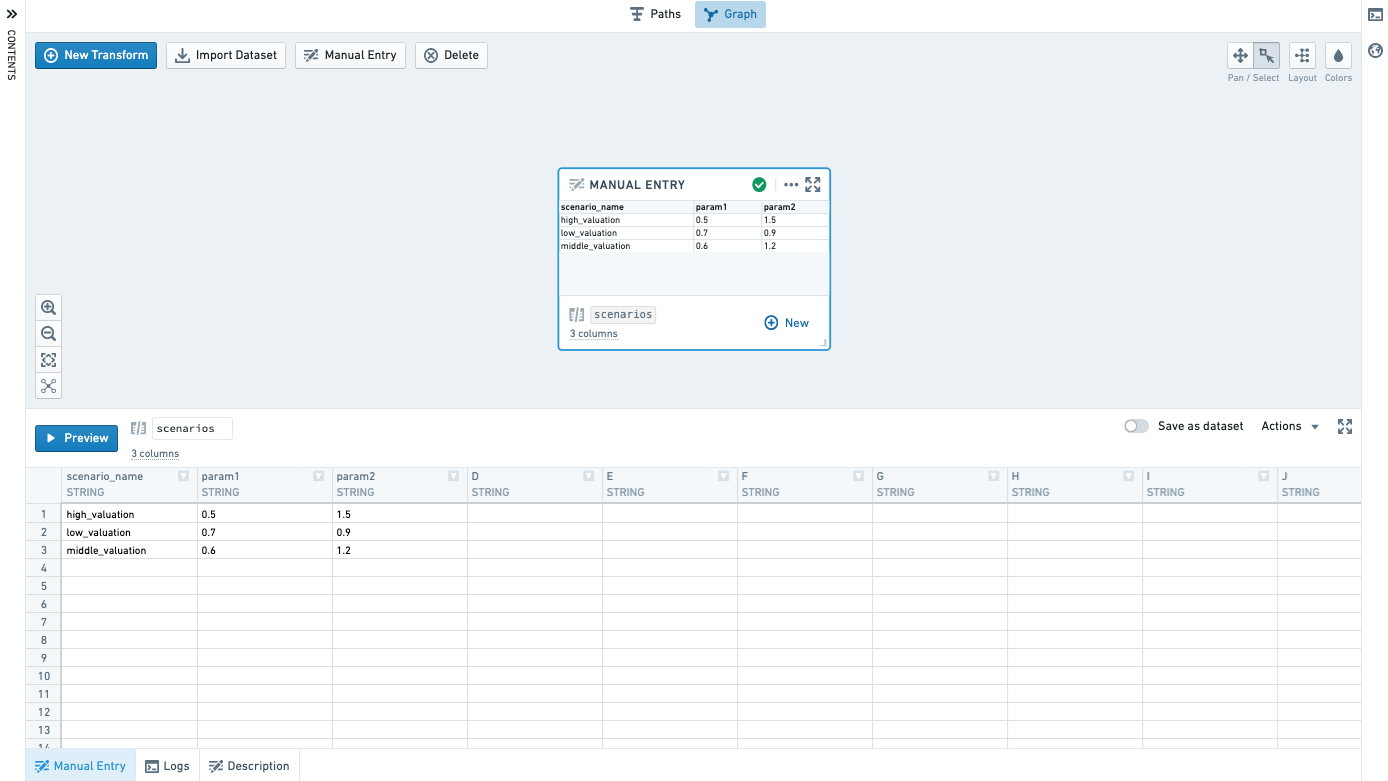
手動入力
グラフ上の Manual Entry ボタンをクリックして手動入力ノードを追加します。

Manual Entry タブでデータを入力します。現在、サポートされている列タイプはDouble、Integer、Boolean、Stringです。サポートされている行数は500行までです。
コピー&ペーストを使って、他の場所から簡単にデータを取り込むことができます。
トランスフォームの実行
選択したトランスフォームを実行するには、下部パネルで Run を選択します。すべての下流トランスフォームを実行するには、矢印アイコンを選択し、Run all downstreamを選択します。
トランスフォームを実行するには、ワークブックの編集権限と、ワークブックが使用する任意のデータセットに使用されているすべてのマーキングへのアクセスが必要です。
また、コードを迅速に実行するためのいくつかのホットキーも利用できます。ホットキーのリストを表示するには、?を入力します。
一度に多くのトランスフォームを実行する方法は2つあります:
- Ctrl + Click または Cmd + Click を使用して、グラフ内の複数のデータセットを選択します。その後、グラフの任意の箇所を右クリックし、メニューから Run N datasets を選択します。
- 上部バーの設定アイコン (
 )をクリックし、 Run all transforms を選択します。
)をクリックし、 Run all transforms を選択します。
トランスフォームが実行中の場合、出力された印刷結果はLogsタブにストリームされます。これにより、トランスフォームがまだ実行中のときに結果を表示するために、トランスフォームの途中で出力を印刷することができます。これは、デバッグやロジックのタイミングを測定するのに役立ちます。
データセットに保存された後、コード内で適用されたデータのソートは保持されない場合があります。つまり、データをソートするトランスフォームを実行した場合、データセットとして表示したときにその順序でソートされていない場合がありますが、トランスフォームで適用された他の操作は適用されています。
タブ
グラフまたはフルスクリーンエディタで作業するときは、ノードの下部タブを使用してトランスフォームの入力と出力をナビゲートします。
入力
入力タブを使用して、トランスフォームへの入力を表示し、追加の入力を追加し、または入力タイプを変更します。
他のSparkベースのアプリケーションと同様に、Code Workbookはデフォルトではデータセットを読み込む際に行の順序を保持しません。分析が特定の行の順序を必要とする場合は、コード内でデータをソートしてください。
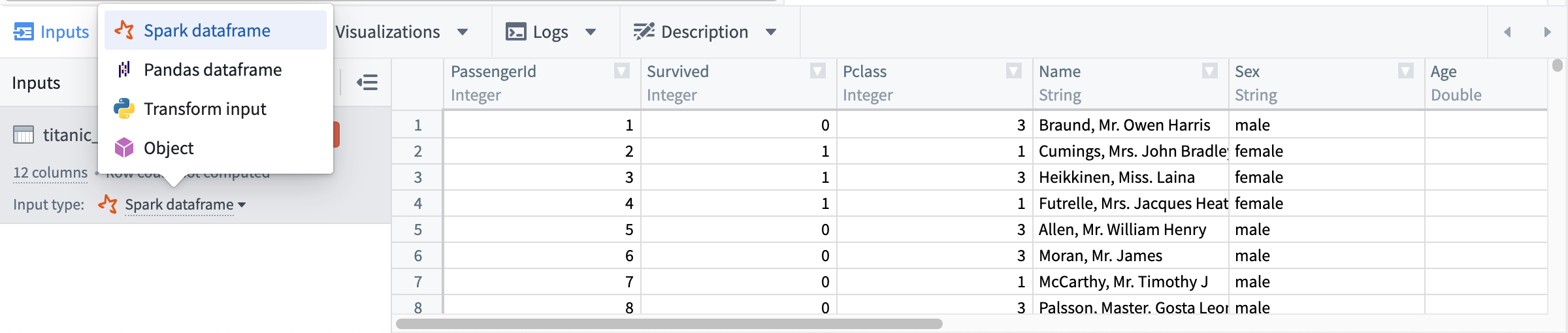
各ノード言語には以下の入力タイプが利用可能です:
| ノード言語 | 利用可能な入力タイプ |
|---|---|
| Python | Sparkデータフレーム、Pandasデータフレーム、Pythonトランスフォーム入力、オブジェクト |
| SQL | Sparkデータフレーム |
| R | Sparkデータフレーム、Rトランスフォーム入力、Rデータフレーム、オブジェクト |
新しいトランスフォームが追加されると、その入力トランスフォームは、新しいトランスフォームの言語と各入力トランスフォームタイプに基づいて、入力タイプをデフォルトにします。詳細は以下の通りです:
| 入力トランスフォームタイプ | 下流トランスフォーム言語 | デフォルト入力タイプ | 追加詳細 |
|---|---|---|---|
| スキーマなしのインポート | Python | Pythonトランスフォーム入力 | |
| R | Rトランスフォーム入力 | ||
| SQL | Sparkデータフレーム | スキーマなしの入力トランスフォームを持つSQLノードを作成することはできますが、SQLノードはSparkデータフレーム入力のみをサポートしており、スキーマなしの入力を分析するのには効果的ではありません。 | |
| スキーマありのインポート | Python | Sparkデータフレーム | |
| R | Rデータフレーム | ||
| SQL | Sparkデータフレーム | ||
| カスタムファイルフォーマットを含むインポート、モデルを含む | Python | オブジェクト | 詳細はmodel training tutorialを参照してください。Code Workbookでのオブジェクト入力タイプはカスタムファイルフォーマットであり、オントロジーオブジェクトとは関連していません。 |
| R | オブジェクト | 詳細はmodel training tutorialを参照してください。Code Workbookでのオブジェクト入力タイプはカスタムファイルフォーマットであり、オントロジーオブジェクトとは関連していません。 | |
| SQL | Sparkデータフレーム | カスタムファイルフォーマットが入力トランスフォームであるSQLノードを作成することができますが、SQLノードはSparkデータフレーム入力のみをサポートしており、カスタムファイルフォーマット入力を分析するのには効果的ではありません。 | |
| 派生ノード | N/A | 入力ノードの出力タイプ | 入力ノードの出力タイプが派生ノードの言語と互換性がない場合、派生ノードはインポートノードタイプのデフォルトを使用します。例えば、Node AがPandasデータフレームを返し、派生Node BがRノードである場合、Node BはNode AをRデータフレームとして読み込むことをデフォルトとします。 |
プレビュー
Code Workbookでトランスフォームを実行すると、結果の形状を確認するために50行のプレビューが計算されます。このプレビューは、データセットがFoundryに書き込まれる前にプレビュータブに表示されます。データセットがFoundryに永続化された後、プレビュータブは完全な結果に更新されます。
可視化
トランスフォームで使用される言語によっては、プロットライブラリを使用して可視化を返し、それをCode Workbookのユーザーインターフェースに伝播させることができます。各言語でこれを行う方法については、言語のドキュメンテーションを参照してください。
結果の可視化は、デフォルトではグラフに表示され、Visualizationsの下部タブでも利用できます。
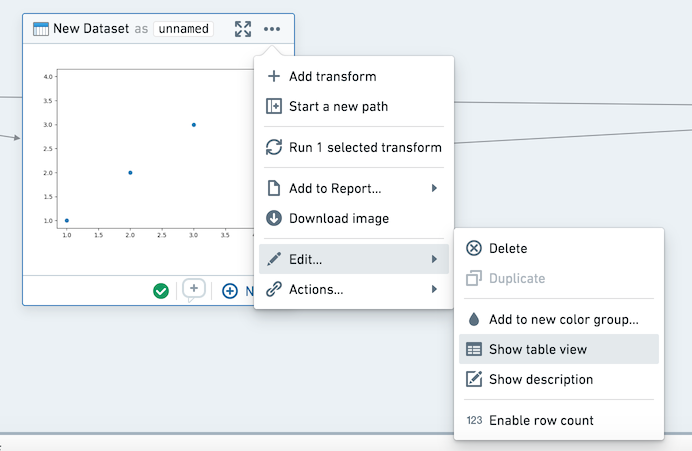
コンテキストメニューを使用して、グラフの表示をテーブルモードとグラフモードの間で切り替えることができます。
可視化タブでは、グラフを画像としてダウンロードしたり、レポートに追加したりすることができます。これらのアクションはコンテキストメニューでも利用できます。
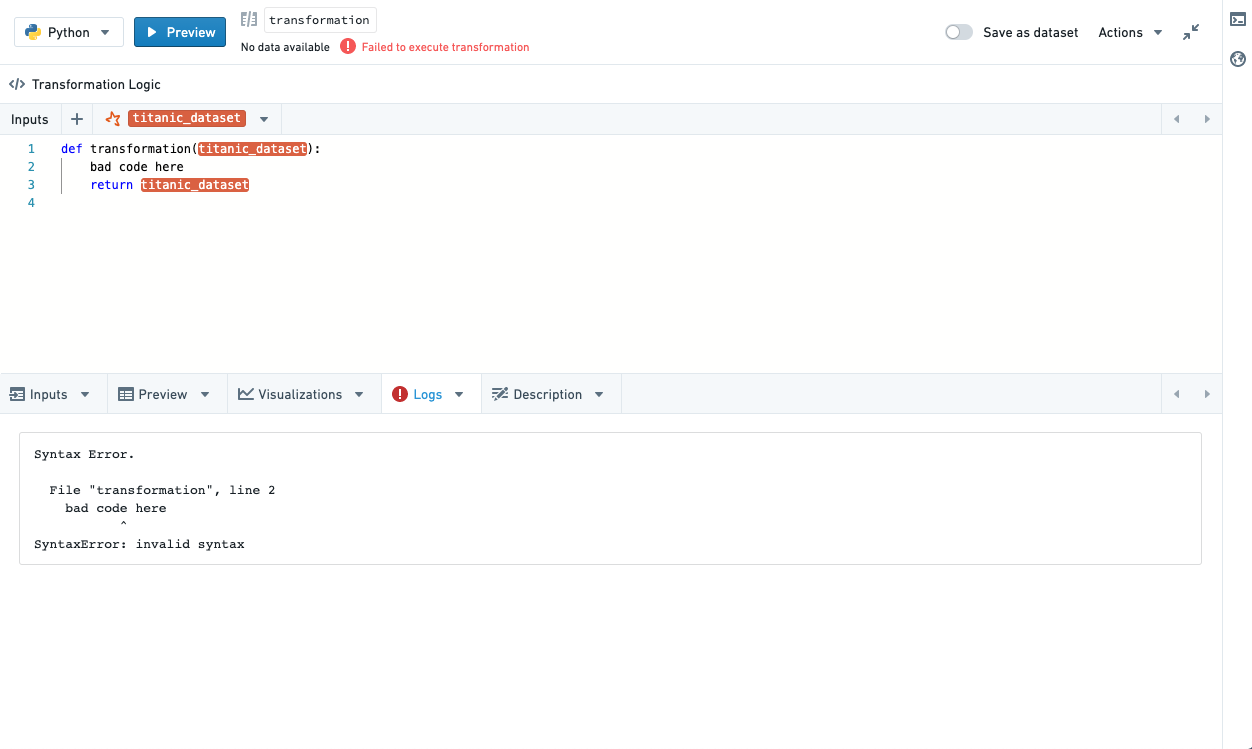
ログ
トランスフォームの実行からのプリントステートメント(標準出力)、警告とエラー(標準エラー)を表示します。標準エラーがある場合、ログタブが自動的に選択され、小さなコールアウトが表示されて警告/エラー出力があることを通知します。
説明
データセットの説明を更新します。説明を更新すると、すべてのブランチで更新されます - 説明は Open Dataset ビューでも利用可能です。
説明をスタイリングするためにマークダウンを使用することができ、グラフで説明を表示するには右クリック(アクション)メニューで Show Description を有効にします。ワークブック内のすべてのノードの説明を表示するには、ヘッダーのツールコグをクリックし、 Show all descriptions を選択します。
モデル
モデルを返すトランスフォームは、FoundryのMLインターフェースの使用を可能にするため、自動的にモデルとしてFoundryに書き込まれます。各言語でモデルを使用する方法については、言語のドキュメンテーションを参照してください。
非決定的なトランスフォーム
一部の変換は非決定的であり、同じ入力データと変換ロジックにもかかわらず、異なる結果を返す可能性があります。現在のタイムスタンプ、行番号、単調増加IDの呼び出し、重複値を含む列でのソート後の変換など、非決定的な変換を引き起こす可能性のある関数があります。
Code Workbookでは、トランスフォームの実行は2つのジョブを開始します:1つのジョブは50行のプレビューを計算し、もう1つのジョブは全データセットの変換を計算し、結果をFoundryに書き込みます。非決定的なトランスフォームがある場合、50行のプレビューで見る結果は、Foundryのデータセットの結果と一致しない可能性があります。
非決定的なコードをトランスフォーム内で実行すると、データフレームが必ずしも実体化されるわけではありません。例えば、非決定的なトランスフォームであるTransform Aがあり、Transforms BとCの親であるとします。Code Workbook内でそれぞれの変換を個別に実行すると、各データセットは順次Foundryに書き込まれ、Transforms BとCの結果が一貫しています。しかし、Aで "Run all downstream" を選択すると、AがBとCを実行するときに必ずしも実体化されないため、結果に矛盾が生じる可能性があります。データラインエージからビルドを実行することもこれを防ぐことができますし、Pandasデータフレームに変換することも可能です。
非決定的な変換を引き起こす関数の例にはcurrent_date(), current_timestamp(), row_count()などがありますが、他の関数でも非決定性が生じる可能性があります。Sparkが変換を計算する方法により、予想外の振る舞いを引き起こす可能性がある詳細な情報は、Apache Spark docs ↗で見つけることができます。