注: 以下の翻訳の正確性は検証されていません。AIPを利用して英語版の原文から機械的に翻訳されたものです。
分析の最適化
以下の提案に従って、Contour分析とダッシュボードのパフォーマンスを向上させます。
分析の構造化
重複ロジックの最小化
分析が複数の出力を計算するために、大部分が重複したロジックを適用する複数のパスを含む場合(例えば、同じフィルター基準を複数のパスに適用し、最後の数パスを新しいメトリックを計算するために使用する)、これらのパスの重複を最小化します。代わりに、共通の入力パスを使用し、そのパスの結果を他のパスの入力として使用します。
結合
結合する前にできるだけデータセットをフィルター処理します。新しいContourパスでデータセットを開き、フィルター条件を追加し、そのパスの結果に結合することで、データセットを結合する前にフィルター処理することができます。これにより、パフォーマンスが大幅に向上することがあります。
"any match" を使用した複数条件での結合
"any match" を使用した複数条件の結合は、データの分散方式のためにSparkで特にリソースを多く消費します。操作の前に可能な限りスケールを縮小することを確認してください。たとえば、フィルターを上流に押し上げるなどです。複数条件の結合は、分析を異なる方法で設計することで避けることができることがよくあります。たとえば、複数の別々の結合を適用し、結果をユニオンすることです。
データセットとして保存
ボードまたは一連のボードの出力が複数の下流ボード(同じパスまたは異なるパス内)で使用される場合、出力をFoundryデータセットとして保存すると、この新しく保存したデータセットからすべての下流計算を開始すると非常に有益であることがあります。これは、出力が複雑な計算(例えば、結合、ピボットテーブル、または正規表現フィルター)を含む場合に特に当てはまります。
パラメーターの使用
ユーザーがパラメーターの値を変更すると、分析のすべてのボードが再計算されます。始点データセット、パラメーターを使用しない多くの計算、そしてパラメーターを使用するフィルターを持つ分析を想像してみてください。可能であれば、パラメーターを使用しない計算の後で出力をデータセットとして保存します。これにより、新しいパラメーター入力のためにレポート内のチャートとグラフを再計算するのがすばやく再読み込みされることが確認されます。
フロントエンドのパフォーマンス
分析の読み込みが速く反応性が高いことを確保するために、分析あたりのパスは15 - 20パスを推奨します。この限度を超える場合は、分析を複数の分析に分割します。
フィルターの使用
可能な限り特定のフィルターを使用する
フィルターを適用するときは、大文字小文字を区別する設定を有効にし、"contains" よりも "exact match" フィルターに偏ったり、基礎となるデータをすべて大文字またはすべて小文字にするなどします。特に、正規表現の使用は計算上高価です。
たとえば、データセットをすべて小文字またはすべて大文字にすることで(大文字小文字を区別するフィルタリングを有効にするため)、フィルタリング基準が可能な限り精確で、完全一致を使用することでパフォーマンスを向上させることができます(例えば、テキストの場合はcontainsの代わりにis)。
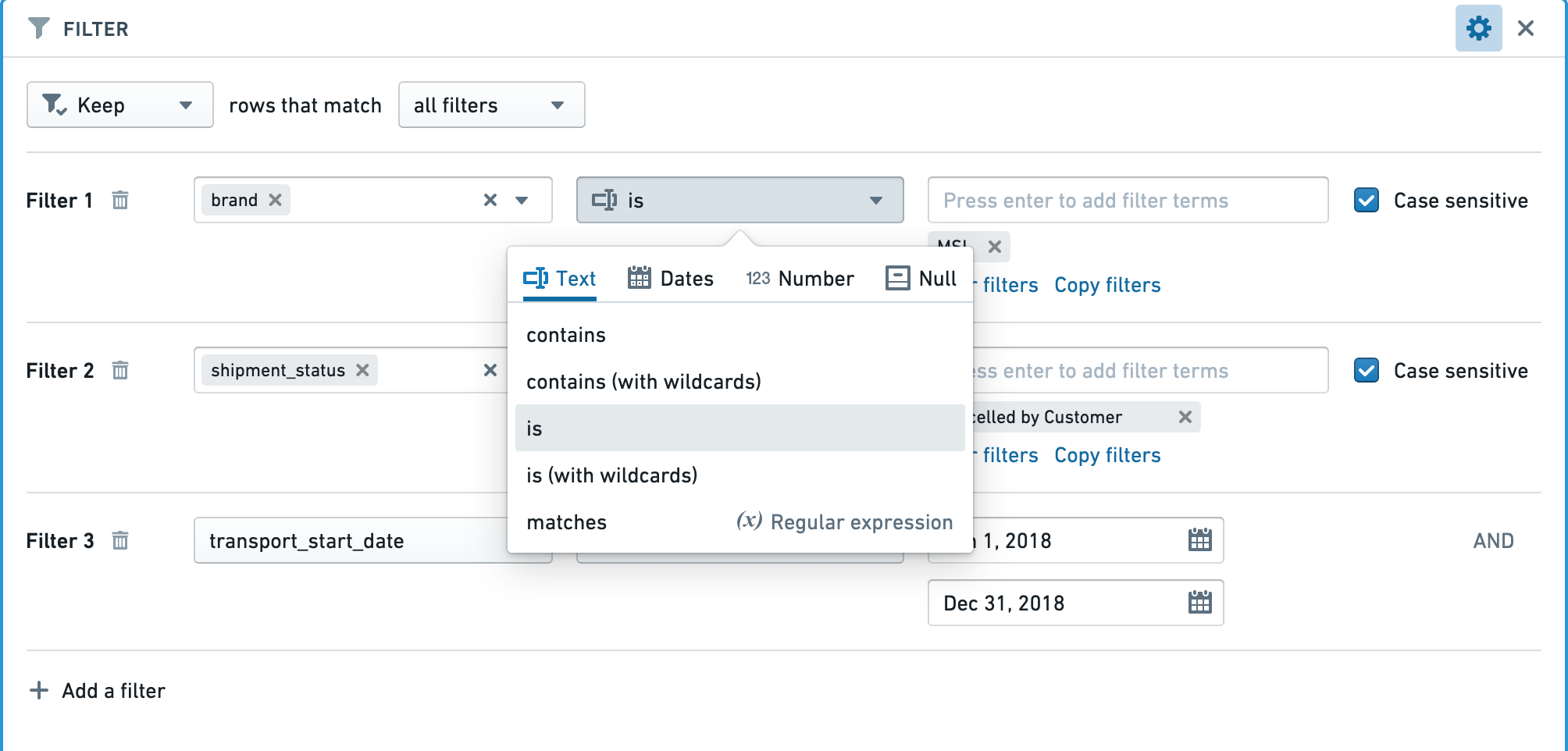
行のタイプに対して正しいフィルターを適用する
行のタイプに対して正しいタイプのフィルターが使用されていることを確認します。
たとえば、integer、long、またはdoubleタイプの行で正確な数値にフィルターを適用するとき、"Number equal to"フィルターを使用すると、"String exact match"フィルターよりも大幅に高速になります。

入力データセット
パーティショニング
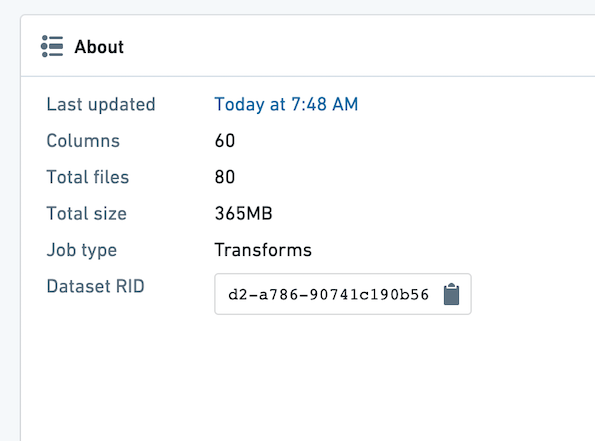
Contour分析で使用するデータセットが適切にパーティショニングされていることを確認します。データセット内のファイルの平均ファイルサイズは、少なくとも128 MBであるべきです。データセットを開いて "About" タブを選択することで、データセットのファイル数とサイズを確認できます。
下の例では、ファイルが80個あり、データセットは365 MBです。これは、最大で3つのファイルであるべきなので、パーティショニングが不適切です。
入力データセットが適切にパーティショニングされていないと判断した場合、上流の変換でそれをパーティショニングすることができます。
上流のPythonトランスフォームをパーティショニングするには、次の行のコードを追加します:
# 再分割 – df.repartition(num_output_partitions)
# 以下のコードは、データフレームdfを3つのパーティションに再分割します。
df = df.repartition(3)
Sparkにおけるパーティショニングとその影響についての詳細は、Spark最適化コンセプトをご覧ください。
プロジェクション
データセットの所有者は、各種クエリのパフォーマンスを向上させるために、データセットにプロジェクションを設定することができます。
入力データセットにプロジェクションが設定されている場合、プロジェクションは下記のように、開始ボードの Optimized セクションにリストされます。リストされた行の一つに完全一致フィルター処理することで、プロジェクションを利用することができます。現在、Contourでは、フィルター処理に最適化されたプロジェクションの情報のみを公開しており、そのプロジェクションは入力データセットの全行を含んでいます。
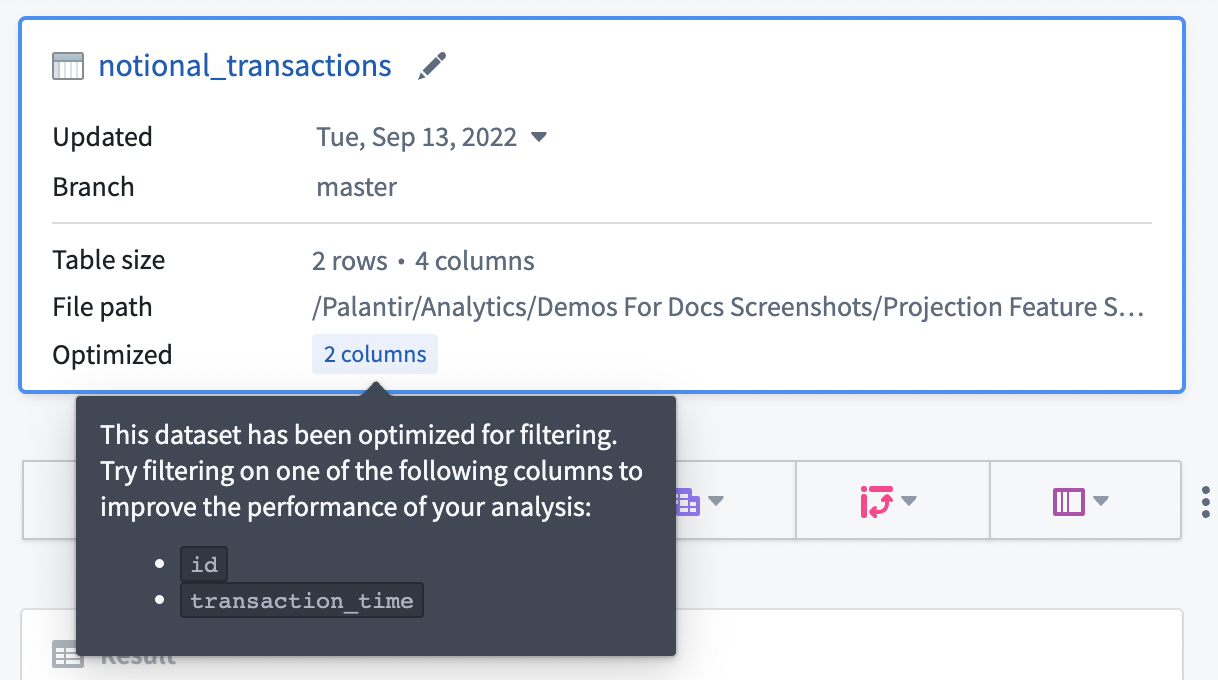
一般的に、Contourでのパフォーマンスを向上させるために、予測可能なクエリパターンのデータセットにプロジェクションを設定することをお勧めします。計算使用量を削減する手段として、データセットが頻繁に使用される場合(つまり、書き込みごとに特定のパターンで10〜100回の読み取りがある場合)にのみプロジェクションを設定することをお勧めします。プロジェクションの構築と保存には、データセットが書き込まれるたびに追加の計算が必要なので、その計算が一貫して下流で活用される場合にのみ節約が実現します。
解析の維持と共有
上記のすべての最適化は、あなたのContour解析が大規模な視聴者に消費される場合、特に重要になります。
ビルドのスケジューリング
Contourで構築されたデータセットのスケジュールを設定する際は、頻度を適切に計画してください。スケジュールを設定した後は、ビルドを監視して、必要な頻度でデータが表面化していることを確認し、不要にビルドしてリソースを消費していないことを確認してください。たとえば、Contourで構築されたデータセットが毎日更新されるデータセットを取り込む場合、データセットが毎時構築される必要はありません。
パラメーターの制限
あなたのContour解析が大規模な視聴者によるレポートで消費される場合、パラメーターの数を最小限にすることが最善です。
理想的なレポートウィジェットは、ユーザーが入力するパラメーター値に基づいてフィルター処理を行い、その後、ユーザーに関連する視覚化を示すための集計を行います。理想的には、他のすべての複雑なロジック(結合とピボット)はFoundryのデータセットで事前に計算されているため、パラメーターの変更ごとに再計算が必要となりません。