注: 以下の翻訳の正確性は検証されていません。AIPを利用して英語版の原文から機械的に翻訳されたものです。
Contour FAQ
以下は、Contourに関するよくある質問です。 一般的な情報については、Contourドキュメンテーションをご覧ください。
- 新しい分析を開始するには?
- プラットフォーム内で関連するデータを探すには?
- 同僚と分析を共有するには?
- 分析を行うための初期データセットを作成するには?
- 分析のビューを変更するには?
- 計算を適用するには?
- Foundryでの一般的なMicrosoft Excel分析との対応関係は?
- ピボットテーブルを作成するには?
- データの全系列に機能を適用するには?
- Foundryでの一般的なMicrosoft Excel集計の対応関係は?
- 分析をチェックする方法は?
- Contourでデータセットを保存するとCode RepositoriesまたはCode Workbookで作成するのと何が違う?
- エクスポートを試みると、行数が100,000行に制限されます。これは正しい?
- Contourの分析パスを自動的に更新できますか?
- Contourの分析に対する変更を元に戻すことはできますか?
- 分析を複製しようとすると、スピナーが表示されて何も起こりません。何をすればいいのですか?
- Contourからデータセットを作成できません
- ピボットテーブルがすべてのデータを表示していません
- ピボットテーブルに重複した行が見つかりました
- 一般的なパフォーマンス問題
- 式ボードのウィンドウ関数で
count_distinct()が失敗する
新しい分析を開始するには?
Foundryでは、各ユーザーにはユーザーのファイルという名前のフォルダーがあります。これは、ユーザーがデータでプロトタイプを作成し、その結果を他のユーザーと共有するためのフォルダーです。フォルダー内で、ユーザーは最初の分析を作成することができます:
- ワークスペースのナビゲーションバーからファイルセクションに移動します。
- ユーザーのファイルタブに移動します。
- +新規を選択し、ドロップダウンメニューから分析を選択して新しい分析を作成します。
- 新しい分析が生成された後に**+新規パスを作成**を選択します。
- 分析したいデータセットを対応するフォルダーで選択します。
プラットフォーム内で関連するデータを探すには?
データを探す主な方法は2つあります:
-
検索: Foundryには、ページの左側のワークスペースサイドバーにあるプラットフォーム全体の検索ツールがあります。このツールはプラットフォーム内のすべてのリソースを検索し、データセットの名前を知っている場合にデータを見つけるのに非常に有効な方法です。スプレッドシート、Contour分析、コードワークブックを含むプラットフォーム内の任意のリソースを検索するために検索ツールを使用できることに注意してください。
-
Data Catalog: FoundryのData Catalogには、ビジネスアナリストやデータサイエンティストが利用できるようにクリーニングされ、キュレーションされたデータセットが含まれています。Data Catalogは、プラットフォーム内に既に存在するデータについて知りたい場合の優れた出発点であり、ホームページから直接アクセスできます。ワークスペースサイドバーでホームを選択することでホームページに戻ることができます。
同僚と分析を共有するには?
リソースを同僚と共有するということは、彼らがあなたが作業しているプロジェクトにアクセスできる必要があるということです。共有を選択し、共有URLを送信するか、同僚を直接リソースに追加して自動的に通知します。同僚がアクセス権限がありませんのエラーを受け取った場合、アクセスをリクエストする必要があります。同僚のプロジェクトへのアクセスが承認されると、メールで共有した分析を見ることができます。
分析を行うための初期データセットを作成するには?
データはFoundryプラットフォーム内で生の形式で利用可能であることが多いため、分析を作成する前にフィルター処理する方法を知ることが重要です。データのフィルター処理を行うことで、関連性のないデータによる混乱を避けながら、分析に重要な要素に焦点を当てることができます。
- ソートとフィルター:ヒストグラムデータフィルター:
- Foundryでは、ソートとフィルターは最もよく使われる機能の1つです。ヒストグラムボードで特定の行のすべての異なるオプションを表示し、作業したい特定のカテゴリを選択できます。
- 属性データフィルター:
- セットした基準を満たすデータのみに絞り込む場合は、KEEPを使用します。
- セットした基準を満たすデータのみを除外する場合は、REMOVEを使用します。
- 複数のデータフィルター:
- 複数の条件を同時に満たすデータに絞り込む場合は、AND MATCHINGを使用します。
- 複数の条件を満たすデータに絞り込む場合、同時にではなく、同じ行のデータ内では必ずしも同時に満たす必要はない場合は、OR MATCHINGを使用します。
- フィルターの調整:
- ユーザーが特定のフィルター(例えば、
carrier_code=DL)の新しい分析を作成した場合、他のユーザーはフィルターを自分の使用例(例えば、carrier_code=UA)に変更したり、フィルターを全体から取り除いて全体分析を得ることで、その分析を簡単に複製することができます。
- ユーザーが特定のフィルター(例えば、
分析はデフォルトで全体の行に適用され、大規模なデータセットの分析を容易にします。Excelで特定のセル範囲を選択するのと同様に、特定の行の選択範囲で分析を実行したい場合は、操作を適用する前にデータを必要な行に絞り込みます。
より多くのフィルター処理のオプションを見るには、データフィルターのドキュメンテーションをご覧ください。
分析のビューを変更するには?
分析のビューを変更するための4つのオプションがあります。以下の操作を行うことができます:
-
SORT 列を昇順または降順に並べ替える
-
REORDER 列を並べ替える
-
REMOVE 列を削除する
-
ADD 列を追加する:Foundryでの一般的なExcel分析との対応関係にあるVLOOKUPセクションを参照してください
-
自動化されたノートパッドドキュメントを作成する:Contour分析の出力を自動化されたノートパッドに追加するオプションがあり、エグゼクティブサマリーでデータを提示することができます。このレポートは、Foundryでリフレッシュされたデータに基づいて変更され、同じレポートを再作成する必要がなくなります。
計算を適用するには?
新しい計算をContourで行うには、式ボードで列を追加を選択する必要があります。しかし、Foundryはセルレベルの操作ではなく、列レベルの操作を行います。式がA1 * B1を掛けてセルC1を返す代わりに、Foundryはcolumn1 * column2を掛けます(column1とcolumn2の各対応する行レベルのエントリを掛け合わせます)してcolumn3を返します。
Foundry で一般的な Microsoft Excel 解析はどのように等価になりますか?
以下に、最も一般的な Microsoft Excel 関数とそれらの Contour での式の等価物を示します。これらの計算は 計算をどのように適用するか? で述べた方法と同様に適用できます。
-
Excel: IF(論理テスト, 真の場合の値, [偽の場合の値])
- Foundry:
CASE WHEN 論理テスト THEN 真の場合の値 ELSE 偽の場合の値 END - 例: もしフライトが
JFKで始まる場合にyesを返し、それ以外の場合にnoを返す行を作成したい場合、式は以下のようになります:CASE WHEN "origin" = 'JFK' THEN 'yes' ELSE 'no' END
- Foundry:
-
Excel: CONCAT(セル1, [セル2],…)
- Foundry:
CONCAT("列1", ["列2"],...) - 例:
timestampとorder_ID_number列を連結して各オーダーに対するユニークキーを含む列を作成したい場合、式は以下のようになります:CONCAT("timestamp","order_ID_number")
- Foundry:
-
Excel: VALUE(テキスト)
- Foundry:
CAST("列1" AS DOUBLE) - 注:列のデータタイプを
STRING,INTEGER,BOOLEAN,DATE,TIMESTAMP, またはLONGに変換できます。式中のDOUBLEタイプを置き換えることで行えます。 - 例: いくつかの列に乗算を行いたいが、必要な列の一つ
costが文字列として分類されている場合、式は以下のようになります:CAST("cost" AS DOUBLE)
- Foundry:
-
Excel: LEFT(テキスト, [num_chars])
- Foundry:
SUBSTRING("列1", 数値2, 数値3) - 注:
数値2は開始インデックスで、数値3は部分文字列の長さです。 - 例:
airport_display_nameの列から[ALB] Albany International + Albany, NY,[AZA] Phoenix - Mesa Gateway + Phoenix, AZ,[CLT] Charlotte Douglas International + Charlotte, NCのような括弧内の文字を抽出したい場合、式は以下のようになります:SUBSTRING("airport_display_name", 2, 3)とすると、列にALB,AZA, そしてCLTが返されます。
- Foundry:
式ボードとサポート式構文のドキュメンテーションを詳細に読んでください。
- Excel: VLOOKUP(値, テーブル, 列_インデックス, [範囲_ルックアップ]) & 別のデータセットからの列の追加
- Foundry: JOIN ボード。
- JOIN ボードを使用すると、現在作業中のデータセットを別のデータセットに結合し、一致する結果をデータにマージすることができます。
例:データセット
flightsを使用して作業していて、データセットaircraftからmanufacturerとnumber_of_seatsの列を追加したい。
FLIGHTS DATASET EXAMPLE
| flight_id | date | origin | tail_num |
|---|
| 999 | 2018-04-01 | LAS | N227FR |
|---|---|---|---|
| 997 | 2018-07-27 | MIA | N303FR |
| … |
AIRCRAFT DATASET EXAMPLE
| tail_number | manufacturer | number_of_seats |
|---|
| N303FR | Airbus | 186 |
|---|---|---|
| N227FR | Airbus | 180 |
| … |
JOIN ボードを使用して、データセット aircraft から manufacturer と number_of_seats の列で flights データセットを豊富にすることができます。両方のデータセットがテール番号を参照する列を共有しているので、この列を結合に使用できます。データセットが結合キーでない同名の列を持っている場合、Contour は列名に接頭辞を追加するように促します。次に、以下のフィールドを記入します:
- 実行する結合タイプを選択します:左結合 (
Add columns), 内部結合 (Intersection), 右結合 (Switch to dataset) またはフル結合。 - 現在の作業セットに追加する他のデータセットからの列を選択します。デフォルトでは、両方のセットからのすべての列が返されます。
- 各セットから一つまたは複数のキーを選択します。複数の結合キーを使用する場合、
Match AnyまたはMatch Allの条件を選択できます。
豊富なデータセットの例
豊富なデータセットは次のようになります:
| flight_id | date | origin | tail_num | manufacturer | number_of_seats |
|---|
| 999 | 2018-04-01 | LAS | N227FR | Airbus | 186 |
|---|---|---|---|---|---|
| 997 | 2018-07-27 | MIA | N303FR | Airbus | 180 |
ピボットテーブルを作成するにはどうすればよいですか?
ピボットテーブル ボードを使用して、データの複数の次元を通じてデータの複数の集計値を素早く計算することができます。
ピボットデータの全体と対話するために、ボード上の Switch to pivoted data オプションを使用します。これにより、Contour の分析がピボットテーブルボードの下のすべてのボードの完全に計算されたピボットデータに切り替わります。
データの全シリーズにわたって関数を適用するにはどうすればよいですか?
Foundry では、expression ボードの Aggregate オプションを使用してこれを行うことができます。他のスプレッドシートソフトウェアで選択できる範囲レベルの操作ではなく、Foundry は列レベルの操作で動作するため、列は興味のある行に適切にフィルター処理される必要があります。
- 関数:
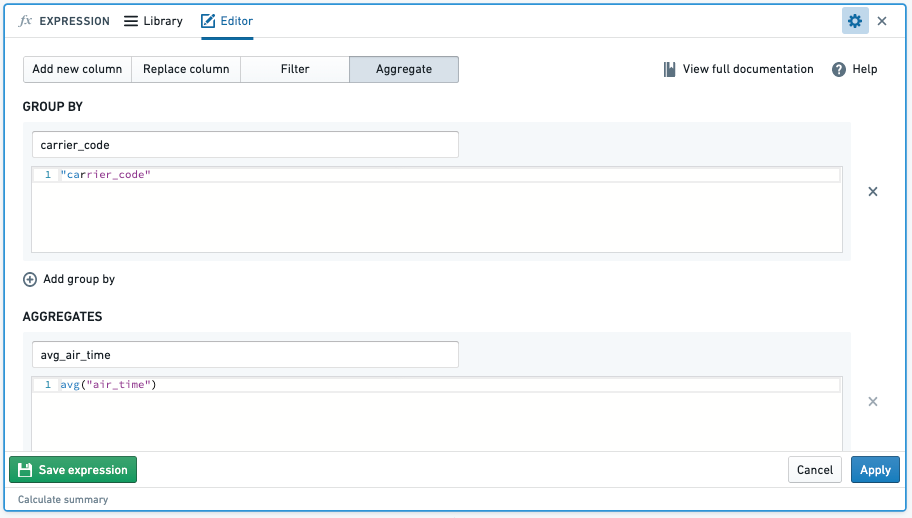
- 結果:
Foundry で一般的な Microsoft Excel 集計の等価物は何ですか?
以下に、最も一般的な Excel 集計関数と Contour 式の等価物を示します。これらの計算は データの全シリーズに関数を適用するにはどうすればよいですか? の質問で表示された方法と同様に適用できます。
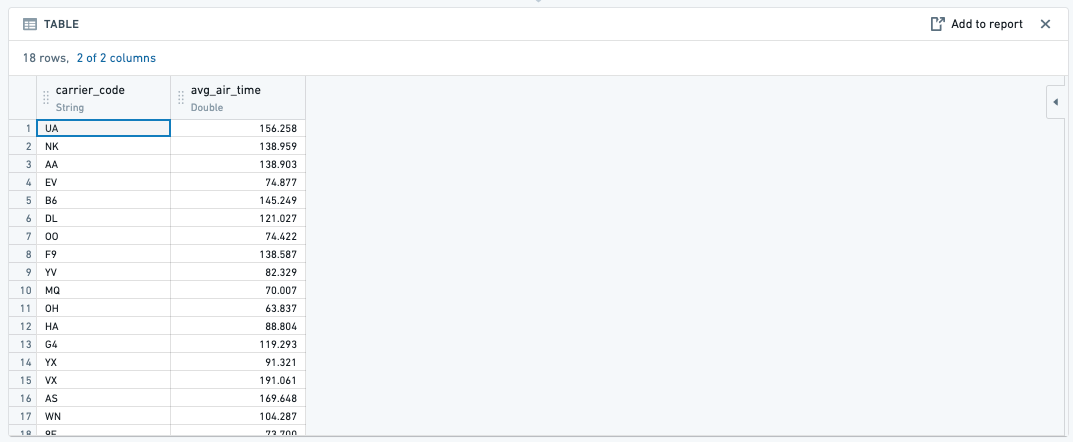
- SUM(): sum 関数で集計すると、指定した列のグループ全体で集計列の値を合計します。
- 例: 各航空会社 (
carrier_code) のtotal_distance_flownを見つける- 関数:
- 関数:
- 例: 各航空会社 (
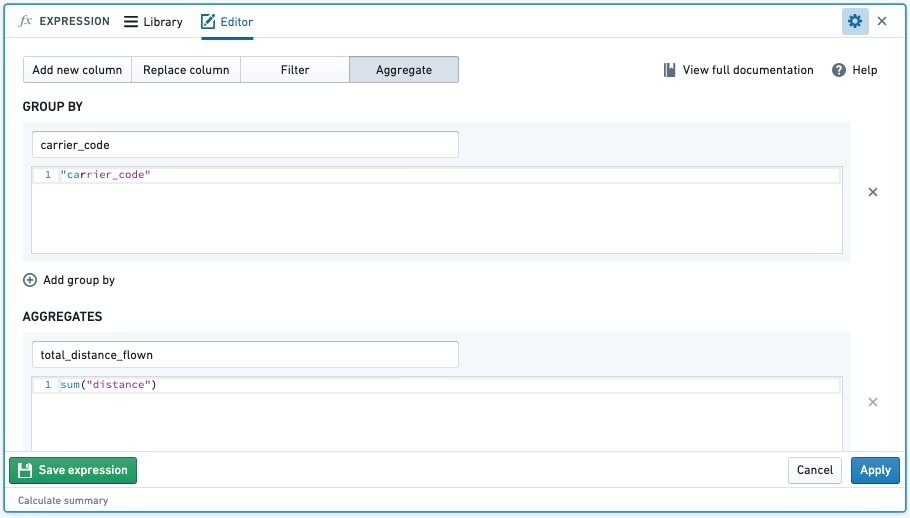
- 結果:

-
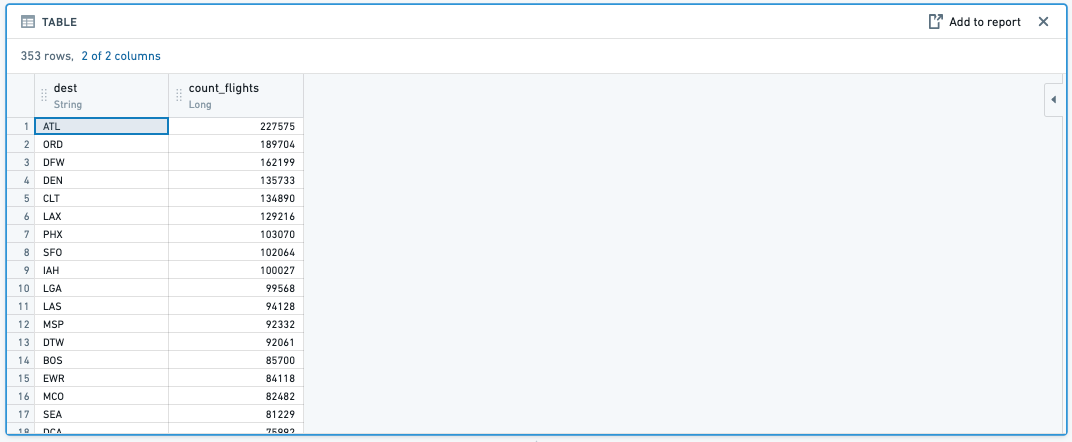
COUNT(): count 関数で集計すると、指定した列のグループ全体で集計列のエントリ数をカウントします。
-
例:
carrier_codeごとのフライト数を、合計flight_idのカウントを集計して見つける -
関数:
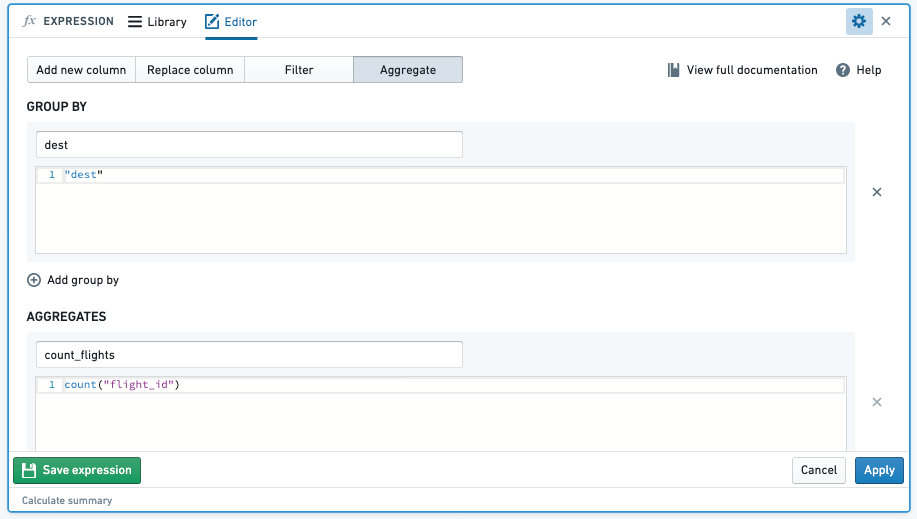
-
結果:
-
-
AVG(): avg 関数で集計すると、例えば、各
carrier_codeのair_timeの平均を見つけます。 -
MAX(): max 関数で集計すると、例えば、各
carrier_codeのair_timeの最大値を見つけます。 -
MIN(): min 関数で集計すると、例えば、各
carrier_codeのair_timeの最小値を見つけます。
分析結果をどのようにチェックできますか?
結果のデータセットをチェックするために、別のボードを追加できます。
-
テーブルボード: 分析後にテーブルボードを挿入すると、追加した新しい行が正しいか、または以前のボードのロジックが意図した結果をもたらしたかどうかをすばやく確認できます。
-
ヒストグラムボード: 分析後にヒストグラムボードを挿入すると、異なるデータカテゴリの概要が提供され、データの全体的な感じやフィルター処理されたカテゴリが正しいかどうかを確認できます。
Contour でデータセットを保存すると Code Repositories や Code Workbook でデータセットを作成するのとどう違いますか?
Contour の分析からデータセットを保存するプロセスは、コードリポジトリや Code Workbook からデータセットを作成するのとほぼ同じです - ロジックは一連の Spark 変換に変換され、クラスター全体で実行され、分散ファイルシステムに保存されるデータセットに保存されます。新しいデータセットとして分析を保存する際に行の制限はありません。ただし、データのスケールが大きいほど、保存に時間がかかり、基礎となる計算がより計算コストがかかります。ただし、Contour からデータをエクスポートする際には行の制限がありますが、これはパスをデータセットとして保存することとは別です。
エクスポートを試みると、行の制限が 100,000 行になっています。これは正しいですか?
はい、それは正しいです。Contour からのエクスポートの行制限は 100K 行です。それ以上をエクスポートする必要がある場合は、Contour の結果をデータセットとして保存し、その後、データセットプレビューページのアクションドロップダウンからダウンロードすることができます。
Contour のエクスポートとデータセットのダウンロードの制限は、パートナー要件に基づいて Foundry のエンロールメント間で異なる場合があります。
Contour の分析パスを自動的に更新することはできますか?
現時点では、Contour の分析パスを自動的に更新する方法はありません。これは手動で完了する必要があります。しかし、分析の結果となるデータセットのスケジュールを設定することは可能です。データセットを保存したら、データセットプレビューを開き、アクションドロップダウンメニューからスケジュールの管理を選択できます。結果となるデータセットは、設定したスケジュールに基づいて構築されます。
Contour の分析に対する変更を元に戻すことはできますか?
はい、画面の右上隅で元に戻すを選択することで、変更を元に戻すことができます。
分析を複製しようとすると、スピナーが表示されるだけで何も起こりません。何をすればいいですか?
これは、分析にパスが多すぎる場合に発生することがあります。不要なパスを削除してから再度複製を試みてください。
一般的なパフォーマンスの問題のセクションを参照してください。
Contour からデータセットをビルドできない
Contour からデータセットをビルドする際にエラーメッセージが表示されます。
ビルドとチェックエラーに関するガイダンスを参照してください。
ピボットテーブルがすべてのデータを表示していない
ピボットテーブルのプレビューは、テーブル内のすべてのデータを表示しません。ピボットテーブルは全体のデータセットを対象に集計を計算し、出力を最初の 100 行または 10,000 値にまで縮小します。これは、ブラウザのパフォーマンスを低下させないようにするためです。これらの大きなピボットテーブルに対する確定的な答えを得るには、ピボットデータに切り替える必要があります。このことについては、ピボットテーブルのドキュメンテーションで詳しく説明しています。
トラブルシューティングを行うには、以下の手順を実行します:
- ピボットデータに切り替えるを試してみてください。これにより、Contour はデータセット全体を計算します。
- データをテーブルボードで表示します。ピボットボードは不完全なままです。
- 可能であれば、ピボットテーブルの上にフィルターボードを挿入して、通過させるデータを削減します(これにより全体的なパフォーマンスが向上します)。しかし、それでもピボットテーブルボードはピボットテーブルの最初の 10,000 セルだけを計算します(パフォーマンス上の理由から)。
- 完全なエクスポートを得るには、ピボットデータに切り替えるを選択し、エクスポートボードを使用するか、現在のパスの最後からエクスポートオプションを使用します。
ピボットテーブルで重複した行が見つかりました
ピボットテーブルが重複した行のために計算に失敗します。これは一般的に、行の名前が大文字と小文字を除いて同じであるためです。
トラブルシューティングを行うには、以下の手順を実行します:
- ピボットテーブルの行部分にある任意の行が、大文字と小文字の違いだけで同じ値を含んでいないか確認します(例えば、
Testとtest)。Foundry のデータセットの行名は大文字と小文字を区別しないため、行をピボットすると、Testとtestの行は重複と見なされます。 - そのような値を単一の大文字または小文字にマップします。これにより、行をピボットしたときに衝突が起こらなくなります。
一般的なパフォーマンスの問題
ユーザーの Contour が遅く、パフォーマンスが低下している原因を特定したいと思っています。
トラブルシューティングを行うには、以下の手順を実行します:
-
まず、分析で使用される入力データセットが Parquet ファイルまたは Avro ファイルを使用しているかどうかを確認します。そうでない場合は、適切な、クリーンなバージョンのデータセットで作業していることを確認します。
-
CSV ファイルとして保存されたデータセットの生の、取り込み版を使用しているかどうかを確認します。これは非パフォーマンスであり、この問題の最も一般的な原因です。
-
入力データセットのパーティションを確認します。分析で使用されるデータセットが貧弱にパーティション化されている場合、パフォーマンスは遅くなります。
-
入力データセットのファイルのサイズを確認するには、データセット → 詳細 → ファイル → データセットファイルに移動します。
-
ファイルはそれぞれ少なくとも 128 MB であるべきです。もし小さすぎるか、あまりにも大きすぎる場合は、パーティションを再作成する必要があります。
-
非常に長いパスを持っている場合は、中間のデータセットを具体化し、これら新たに具体化されたデータセットから始まる新しいパスを作成するべきです。これにより、各ボードはボードを作成するために必要な全クエリパス(前のすべてのボードで使用された変換ロジックなど)を実行するため、ロジックの実行における冗長性が減少します。
-
分析に含まれるパスの数を減らすことを考慮してください。これは特にパスの概要画面を使用している場合、ブラウザのパフォーマンスを遅くする可能性があります。
さらに詳しくは、Contour 分析パフォーマンスの最適化のドキュメンテーションをご覧ください。
式ボードのウィンドウ関数内で count_distinct() が失敗する
count_distinct() 関数は、Spark の制限により、ウィンドウ関数内では利用できません。公式の Spark ドキュメンテーション ↗を参照してください。
ユーザーは、使用したいウィンドウロジックによりますが、同じことを実現することが可能です(一意のカウント集計オプションを提供するピボットテーブルボードで)。行/列の組み合わせを "ウィンドウ" として定義し、各交差点で一意のカウントを生成できます。