注: 以下の翻訳の正確性は検証されていません。AIPを利用して英語版の原文から機械的に翻訳されたものです。
LIKE を使った検索パターン
SQL LIKE 演算子 ↗ を使用して、行の値の中のパターンを検索します。
A で終わるすべての国名に一致します:
式を使ったデータの集計
このモードでは、グループ化式と集計式を使用してデータを集計できます。グループ化式は0個、1個、または複数個持つことができ、集計式は1個または複数個持つことができます。各グループ化式と集計式には名前を付ける必要があり、結果として得られるテーブルには、各式に対応する1つの行が含まれる新しいスキーマが構成されます。
例えば、開始地点の近所別にタクシーの平均旅行距離を集計する以下の式を考えてみましょう。
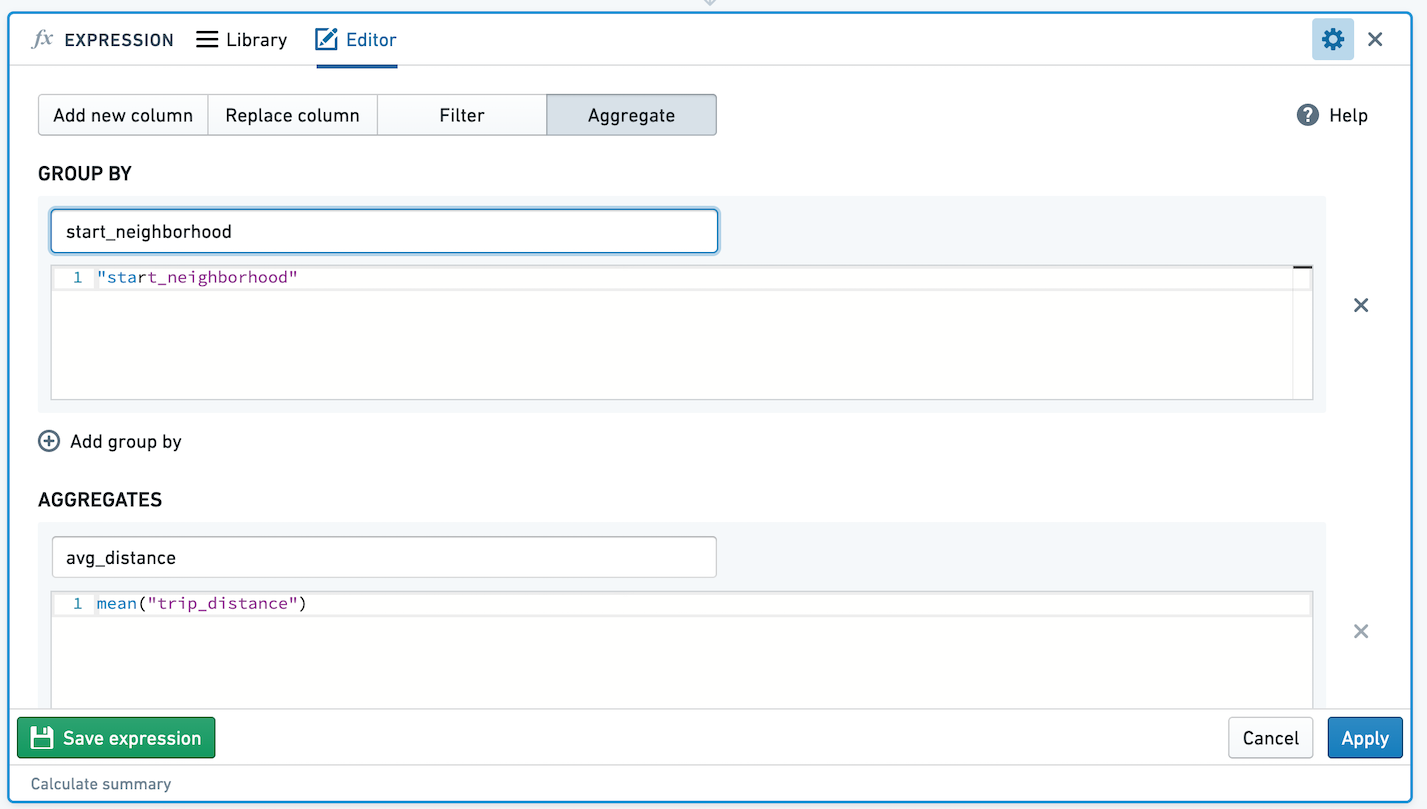
結果として得られるテーブルは以下のようになります。
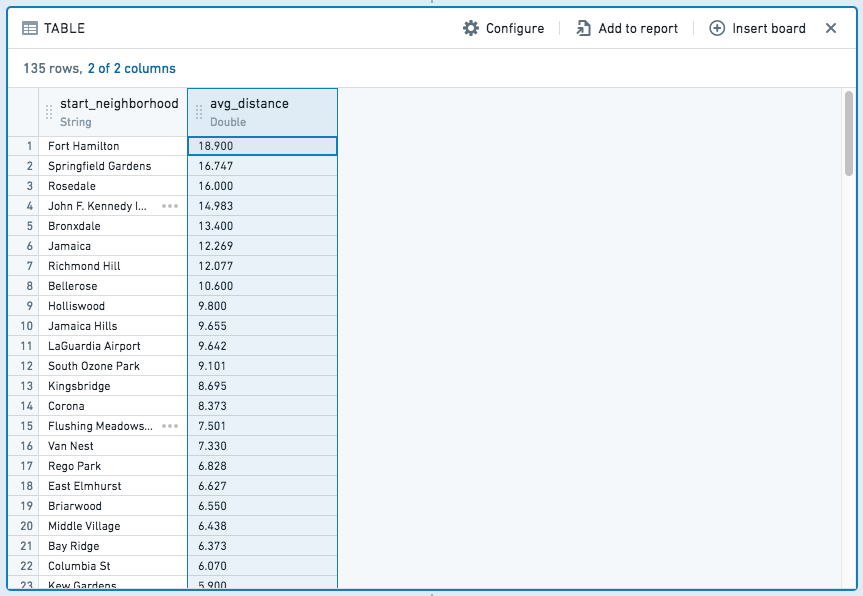
add-column や filter 式とは対照的に、集計式はまったく新しいテーブルを生成し、各集計とグループ化パーティションに対応する行が含まれます。
例えば、以下のような仮定のデータセットを考えてみましょう。
| id | name | sport | birthday | number_of_gold_medals |
|---|---|---|---|---|
| 1 | Jane | Swimming | 6/29/1985 | 6 |
| 2 | John | Gymnastics | 2/19/1971 | 3 |
| 3 | Mike | Swimming | 3/23/1971 | 7 |
| 4 | Michelle | Gymnastics | 9/12/1971 | 5 |
獲得した金メダルの合計数を知りたい場合は、以下のようにします。

これにより、以下のテーブルが得られます。
| sum |
|---|
| 21 |
誕生年とスポーツ別に、金メダルの合計数と平均数を知りたい場合は、以下のようにします。

これにより、以下のようになります。
| birth_year | sport | sum | average |
|---|---|---|---|
| 1971 | Swimming | 7 | 7 |
| 1971 | Gymnastics | 8 | 4 |
| 1985 | Swimming | 6 | 6 |
集計の結果得られる新しいテーブルで分析を行いたい場合は、集計されたデータに切り替える を参照してください。
保存された式
Contour では、式を保存して、分析やパスでのロジックの再利用や他のユーザーとの共有が簡単に行えます。例えば、列room_type の値がPrivate room の場合はTrue、それ以外の場合はFalse という値を持つ新しい列を作成する式を考えてみましょう。この式を保存して他のユーザーがこのロジックを利用できるようにしたいと思います。
式ボードの左下にある Save Expression をクリックします。
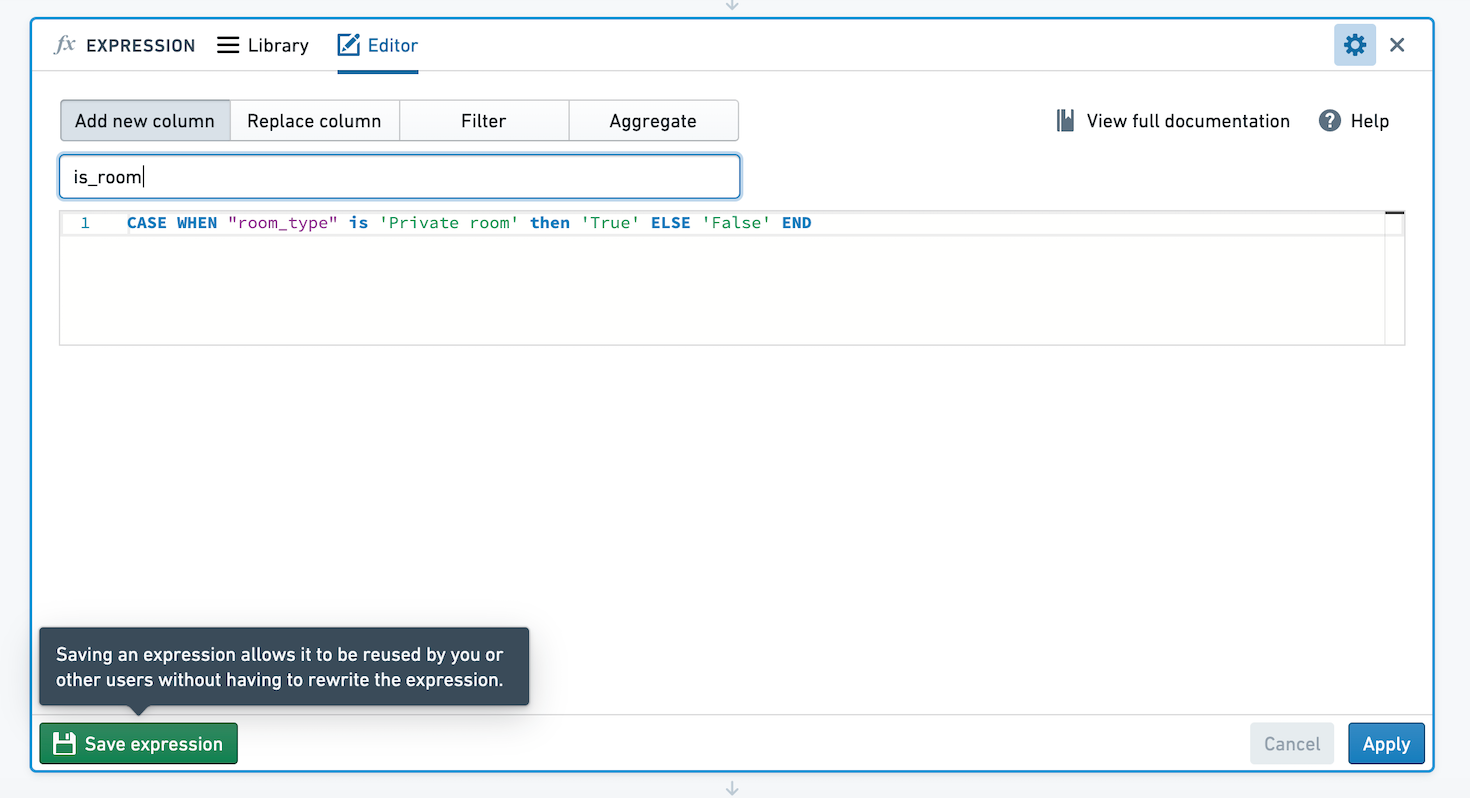
式を引数なしで保存するか、引数として値を選択して式を保存することができます。引数なしで式を保存すると、適用されるときに式のロジックは定義したままになります。引数を定義すると、ユーザーは引数の値を変更できます。以下の画像では、True と False の値をパラメーター化しています。
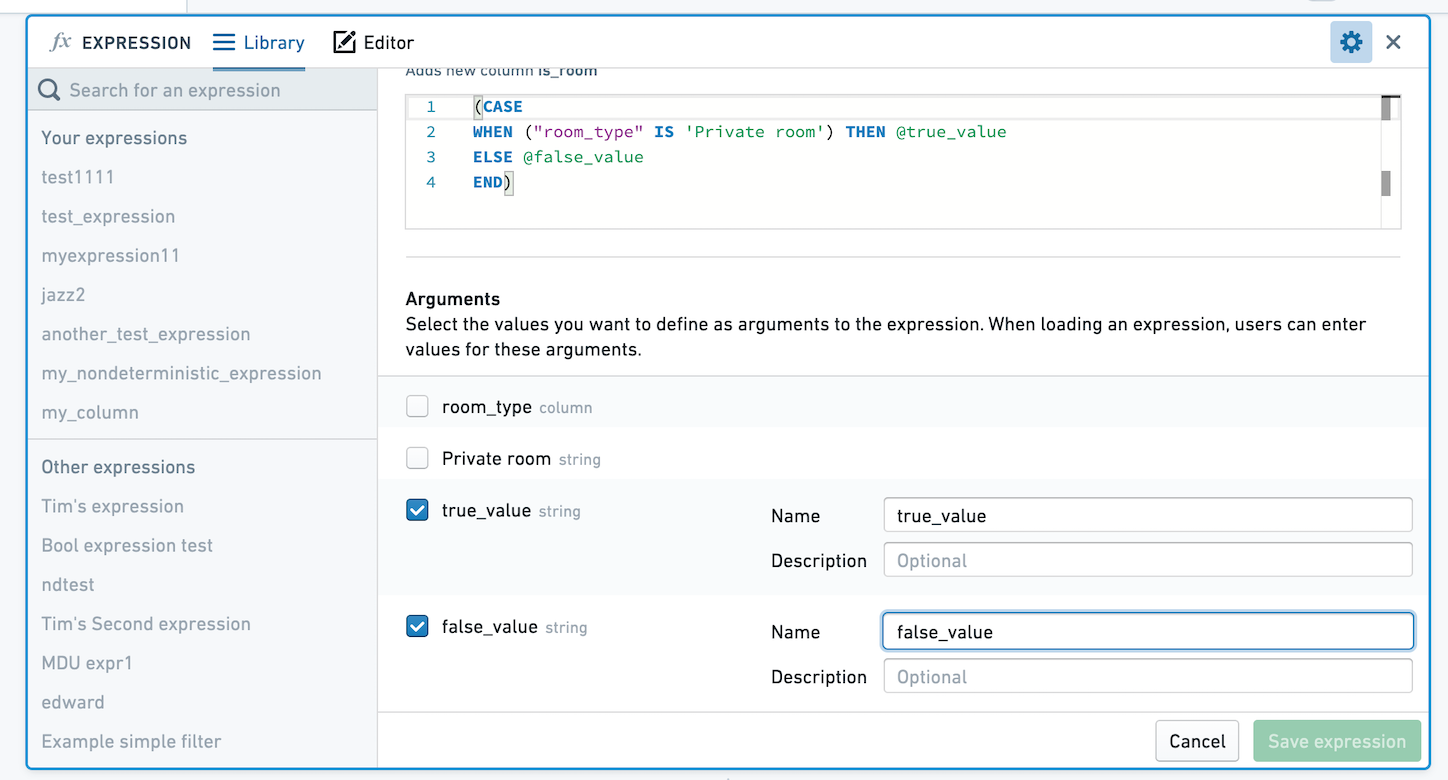
この式を適用する際に選択すると、true_value と false_value の値を選択するように求められます。ここでは、これらの値が Private room と Not private room にマッピングされています。
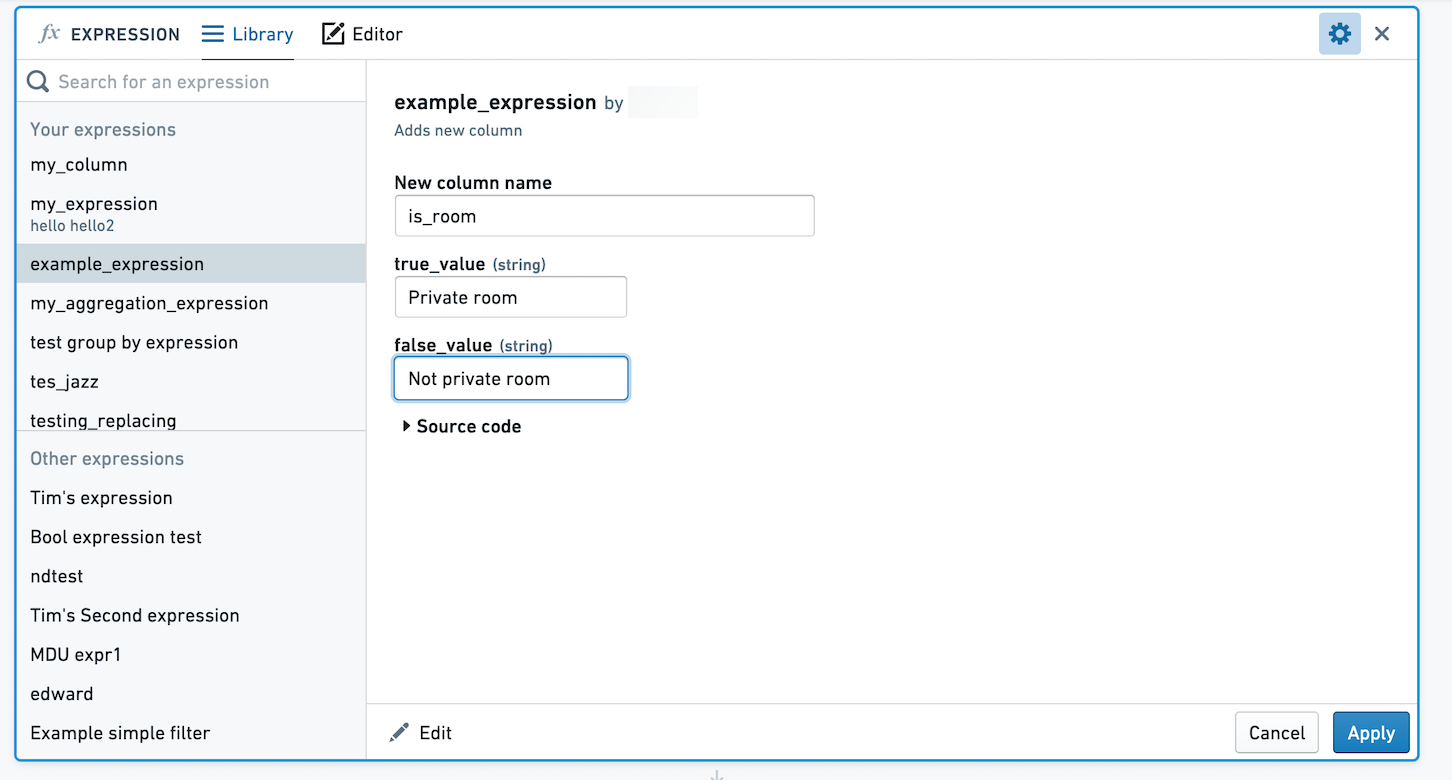
保存された集計式
集計式は、0個以上のグループ化に基づいてデータを集計するために使用されます。グループ化が0個の集計式を保存すると、式のユーザーは任意の数の列グループ化を選択できます。
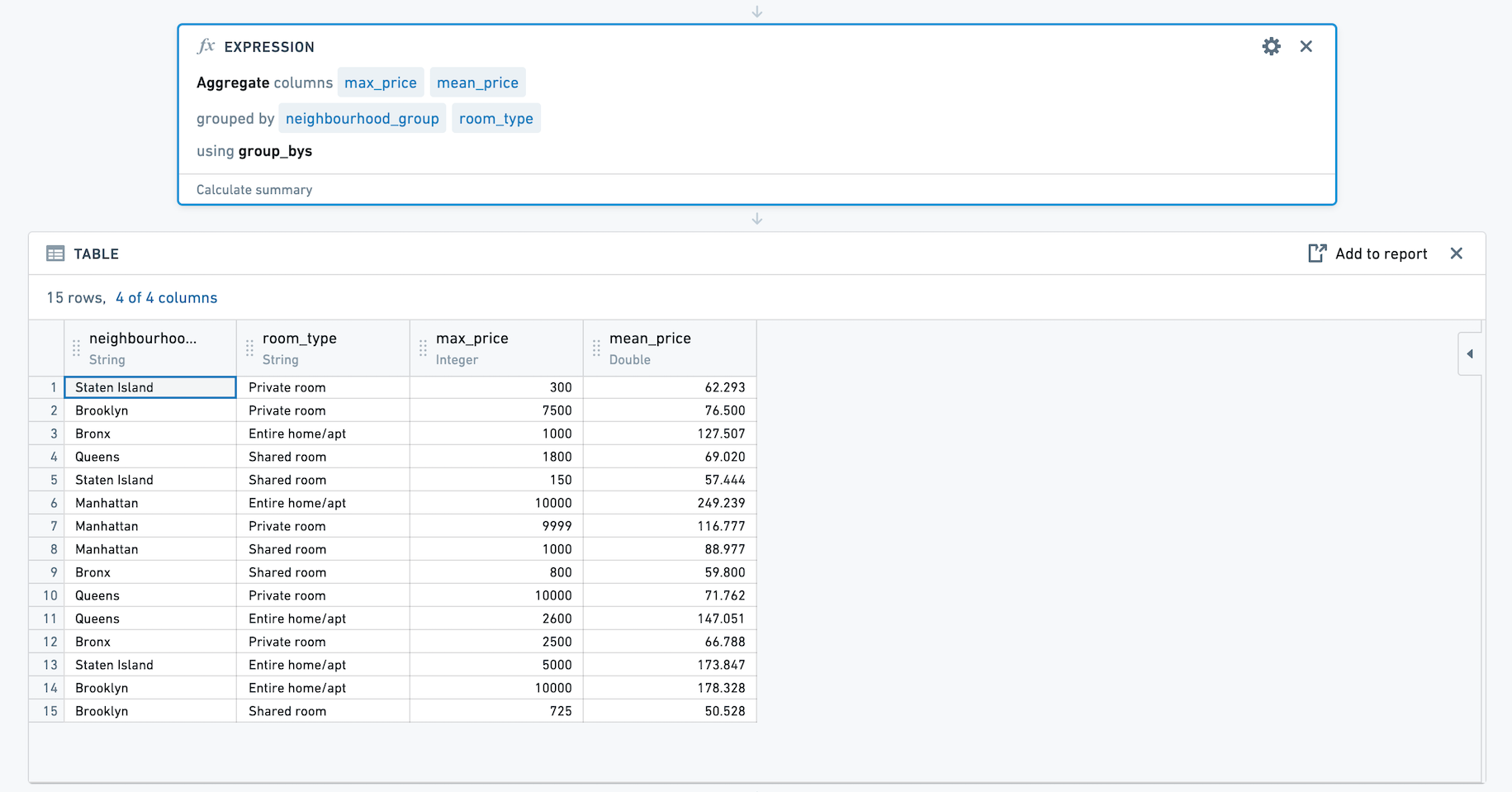
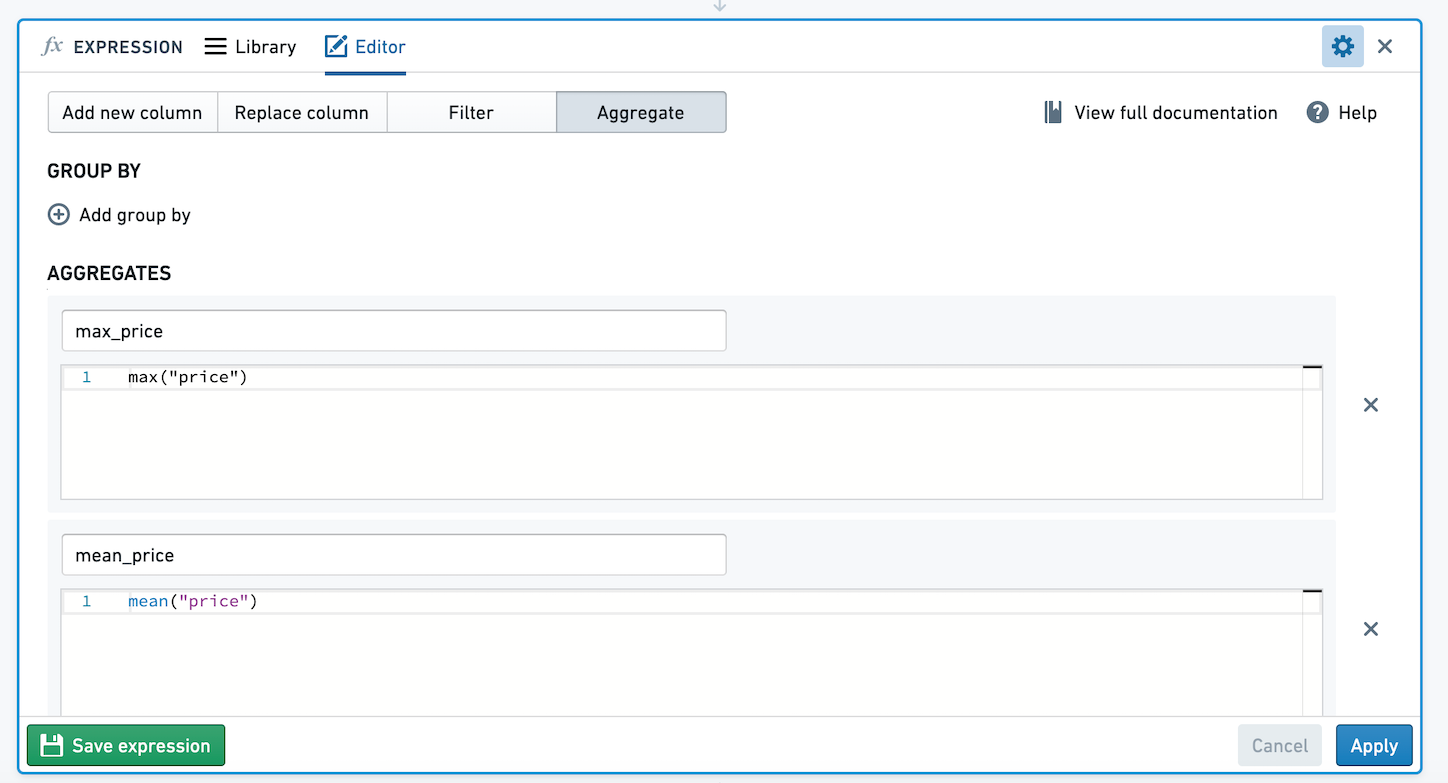
例えば、以下は Inside Airbnb ↗ のオープンソースデータを使用した、グループ化が0個で2つの集計式を持つ集計式です。集計式では、price の平均と最大値を計算しています。この集計式を保存しましょう。
この式を使用する際に、列セレクターが表示されます。複数の列でグループ化することができます。ここでは、neighbourhood_group と room_type の組み合わせごとに price の平均と最大値を計算します。
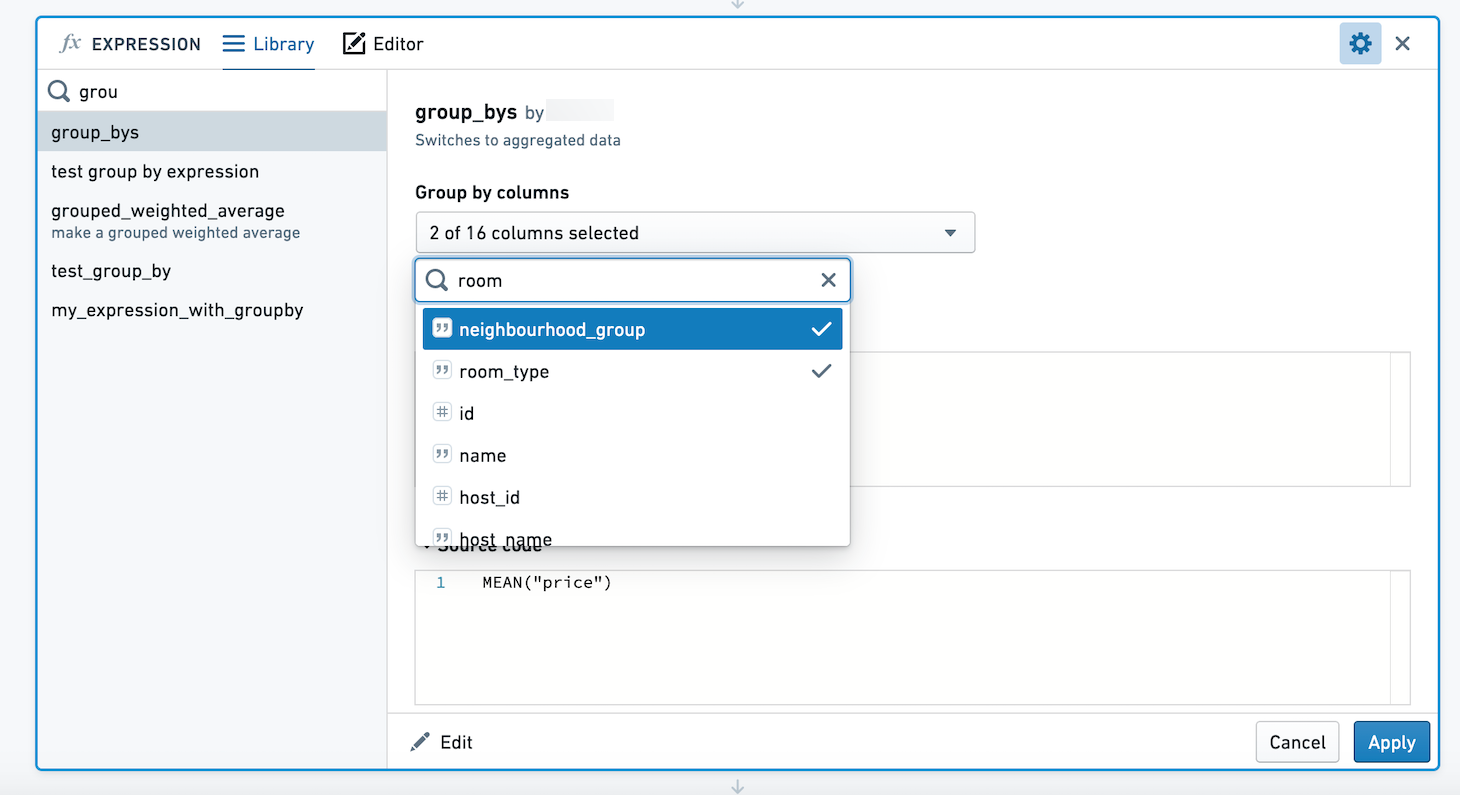
結果のセットには4つの列が含まれており、neighbourhood_group、room_type、max_price、およびmean_priceです。