注: 以下の翻訳の正確性は検証されていません。AIPを利用して英語版の原文から機械的に翻訳されたものです。
Board descriptions
Contour での探索と分析は、一連のボードを使用して実行されます。一部のボードはチャートを作成したり計算を行ったりしますが、他のボードはフィルター処理、列の削除などによってユーザーのデータセットを操作するために使用されます。
このサマリーテーブルのリンクを使用して、このページのボードタイプ間を移動してください。
| ボード | 説明 | 可視化 | 行をフィルター処理する | 集約 | 列を操作する | 重複を削除する |
|---|---|---|---|---|---|---|
| Summary | テーブルの行数を報告します。 | はい | いいえ | いいえ | いいえ | いいえ |
| Filter | データセットを数値、テキスト、または日時の値でフィルター処理します。 | いいえ | はい | いいえ | いいえ | はい |
| Expression | 式言語を使用して新しい列を導出したり、複雑なフィルター処理を行ったりします。 | いいえ | はい | いいえ | はい | いいえ |
| Table | 生データの一部を表示し、スキーマを探索し、データカバレッジメトリクスを計算します。 | はい | いいえ | いいえ | いいえ | いいえ |
| Histogram | データのヒストグラムを作成し、特定のグループにフィルター処理します。 | はい | はい | はい | はい(ピボットオプションを使用) | いいえ |
| Distribution | データの分布プロットを作成します。 | はい | はい | いいえ | いいえ | いいえ |
| Time series | x軸に日時を設定したチャートを作成し、特定のグループにフィルター処理します。 | はい | はい | いいえ | いいえ | いいえ |
| Edit columns | 列を結合、複製、削除、名前変更、または分割します。 | いいえ | いいえ | いいえ | はい | いいえ |
| Transform data | データの匿名化、値の検索と置換、または日付の解析を行います。 | いいえ | いいえ | いいえ | はい | いいえ |
| Chart | カスタマイズ可能な複数層のチャートを作成します。 | はい | はい | はい | いいえ | いいえ |
| Grid | 2つのカテゴリー列のマトリックスを作成します。セルはフィルター処理可能で、ヒートマップとして表示されます。 | はい | はい | いいえ | いいえ | いいえ |
| Heatmap | 座標データに基づいたヒートマップを表示します。 | はい | はい | いいえ | いいえ | いいえ |
| Pivot table | 1つ以上のメトリクスに対するピボットテーブルを作成します。 | はい | はい | はい | はい(ピボットオプションを使用) | いいえ |
| Column editor | 新しい列を導出したり、不必要な列を削除します。 | いいえ | いいえ | いいえ | はい | はい |
| Multi-column editor | 列の名前変更、削除、並べ替え、または重複行の削除を行います。 | いいえ | いいえ | いいえ | いいえ | いいえ |
| Enrich | 別のデータセットでデータを強化し、両方のデータセットから列を返します。 | いいえ | いいえ | いいえ | はい | はい |
| Link | 別のデータセットに結合し、そのデータセットの一致するレコードを返します。 | いいえ | いいえ | いいえ | はい | はい |
| Set math | 外部データセットに基づいて行を保持、追加、または削除します。 | いいえ | はい | いいえ | いいえ | いいえ |
| Join | キュレートされた結合を実行します。 | いいえ | はい | いいえ | いいえ | いいえ |
| Export | 最終的にフィルター処理された観測セットをCSVまたはXLSにエクスポートします。 | いいえ | いいえ | いいえ | いいえ | いいえ |
| Reorder columns | テーブル内の列を並べ替えます。 | いいえ | いいえ | いいえ | いいえ | いいえ |
| Macro | パスにテンプレート化された変換を適用します。 | いいえ | いいえ | いいえ | いいえ | いいえ |
| Sort | データの行を1つ以上の列に基づいて並べ替えます。 | いいえ | いいえ | いいえ | いいえ | いいえ |
| Calculation | 複数の集計計算を表示します。 | はい | いいえ | はい | いいえ | いいえ |
| Unpivot | 一部の列を行に変換することでデータを再構築します。 | いいえ | いいえ | いいえ | はい | いいえ |
Summary
Summary ボードは、パスの現在の位置にあるテーブルの行数と列数を表示します。
データを全くフィルター処理していない場合、これは開始セットの行数です。フィルター処理を適用している場合(たとえば、ヒストグラムを追加して特定のバーを選択した場合)、これはフィルター処理後に残る行数です。
Filter
Filter ボードの目的は、カスタマイズ可能なフィルターをデータセットに適用することです。他のボード(distribution、histogram)でもフィルター処理を適用できますが、Filter ボードでは複数の変数を含むより複雑なフィルターを一箇所で構築できます。
Filter ボードでリストを使用することは、SQL の WHERE IN (x,y,z) 句に似ています。Contour は Filter ボードで数千のアイテムリストを処理できます。ただし、大規模なリストはブラウザに負担をかけ、リストが大きすぎるとブラウザがクラッシュする可能性があります。このような場合、リストを別のセットとして Contour にインポートし、リンクまたは Set math ボードを使用してフィルターを実装する必要があります。リンクまたは Set math ボードの使用方法を学びます。
設定
Add filter をクリックし、フィルター処理する列を選択し、ドロップダウンからフィルタータイプを選択します。選択した列に基づいて、Contour は適切なフィルターのカテゴリー(たとえば、数値列の場合は数値)を選択します。
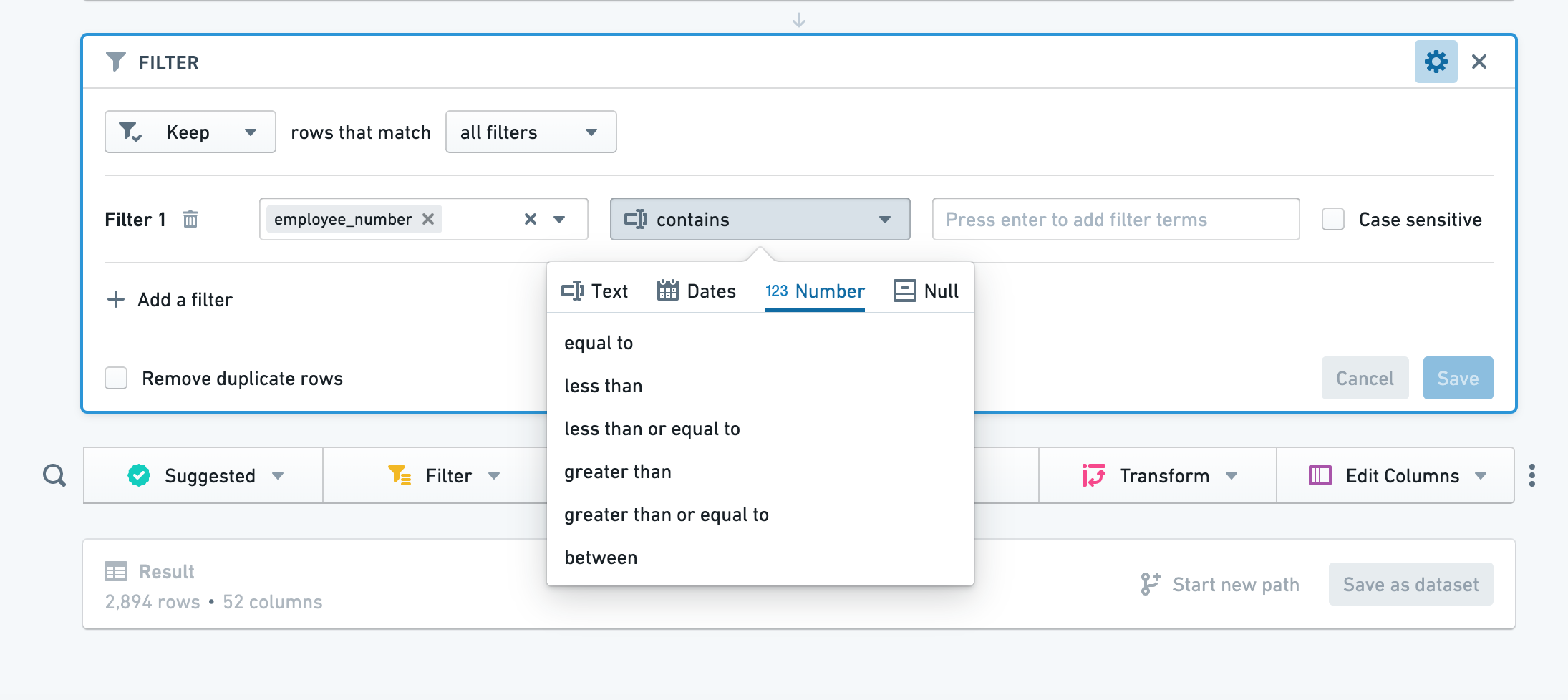
一部のテキストフィルターではワイルドカードを使用できます。* は複数の文字に置き換えることができ、? は単一の文字に置き換えることができます。
「matches」(正規表現)テキストフィルターでは、正規表現を直接入力できます(引用符や文字列インジケーターは不要です)。
別のフィルターを追加するには、Add filter をもう一度クリックします。all filters または any filter に一致するように選択できます。フィルターを削除するには、フィルターの隣にあるゴミ箱ボタンをクリックします。 Save をクリックしてフィルターを適用します。
テキストフィルターの詳細
テキストフィルターは現在、以下のオプションを提供しています:
- contains: ユーザーの検索語を含む行を返します。検索語はテキストのみを含む必要があります。たとえば、「hello」という語は「hihellohi」を含む行に一致します。
- contains (with wildcards): ユーザーの検索語を含む行を返します。検索語には、単一文字のワイルドカードを示す
?や、複数文字のワイルドカードを示す * を含めることができます。たとえば、h?l*oという語は「hi hello hi」や「hi halqqqqqo hi」に一致します。 - is: ユーザーの検索語に等しい行を返します。検索語はテキストのみを含む必要があります。たとえば、「hello」という語は「hello」に一致しますが、「hi hello hi」には一致しません。
- is (with wildcards): ユーザーの検索語に等しい行を返します。検索語には、単一文字のワイルドカードを示す ? や、複数文字のワイルドカードを示す * を含めることができます。たとえば、
h?l*oという語は「hello」や「halqqqqqo」に一致します。 - matches: 正規表現を用いて検索語に一致する行を返します。このオプションは、正規表現の評価に Java Pattern ↗ を使用します。
Expression
ヒストグラムやチャートのような視覚的ツールに加えて、Contour は Expression ボードも提供しており、Contour の豊富な式言語を使用してデータから新しい列を導出したり、複雑なフィルター処理を行ったり、複雑な集約を行ったりできます。
- Expression エディタを使用する際、? アイコンをクリックすると、式言語のクイックリファレンスが表示されます。
- 入力中に、ドロップダウンに提案された関数が表示されます。クリックするか Enter キーを使用して、目的の関数を選択します。
列名は大文字小文字を区別します。また、列を選択する際には、列名を二重引用符付きでもなしでも記述できます。たとえば、year("birthdate_col") は year(birthdate_col) と同等です。このドキュメントでは一貫性のために、列名は二重引用符付きで記載されています。
Table
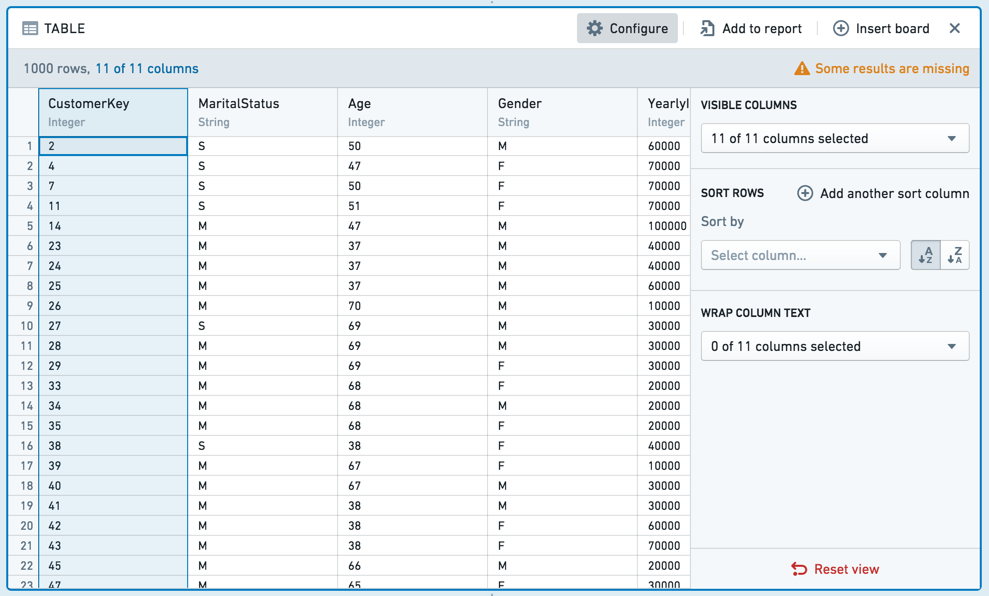
Table ボードは、ユーザーのデータセットのスナップショットを表形式で表示します。データセット内の最初の limit(デフォルトでは 1,000)行のみが表示されることに注意してください。この制限はブラウザのパフォーマンス問題を防ぐために存在し、一般的には構成可能ではありません。
Table ボードは、データが期待どおりに見えるかどうかをスポットチェックするのに便利です。テーブルと対話することができ、列をドラッグアンドドロップして並べ替えたり、各列のドロップダウンから選択したりできます。テーブルのこれらのフォーマット変更は元データを変更しません(列のサブセットのみを表示している場合でも、すべての列が元データに存在します)。

複数の列を同時に移動するには、Shift キーを押しながら列を選択します。 Configure パネルを使用して、複数の列を同時に変更することもできます。
条件付きフォーマット
Table ボードに条件付きフォーマットを追加するには、列のドロップダウンをクリックします。
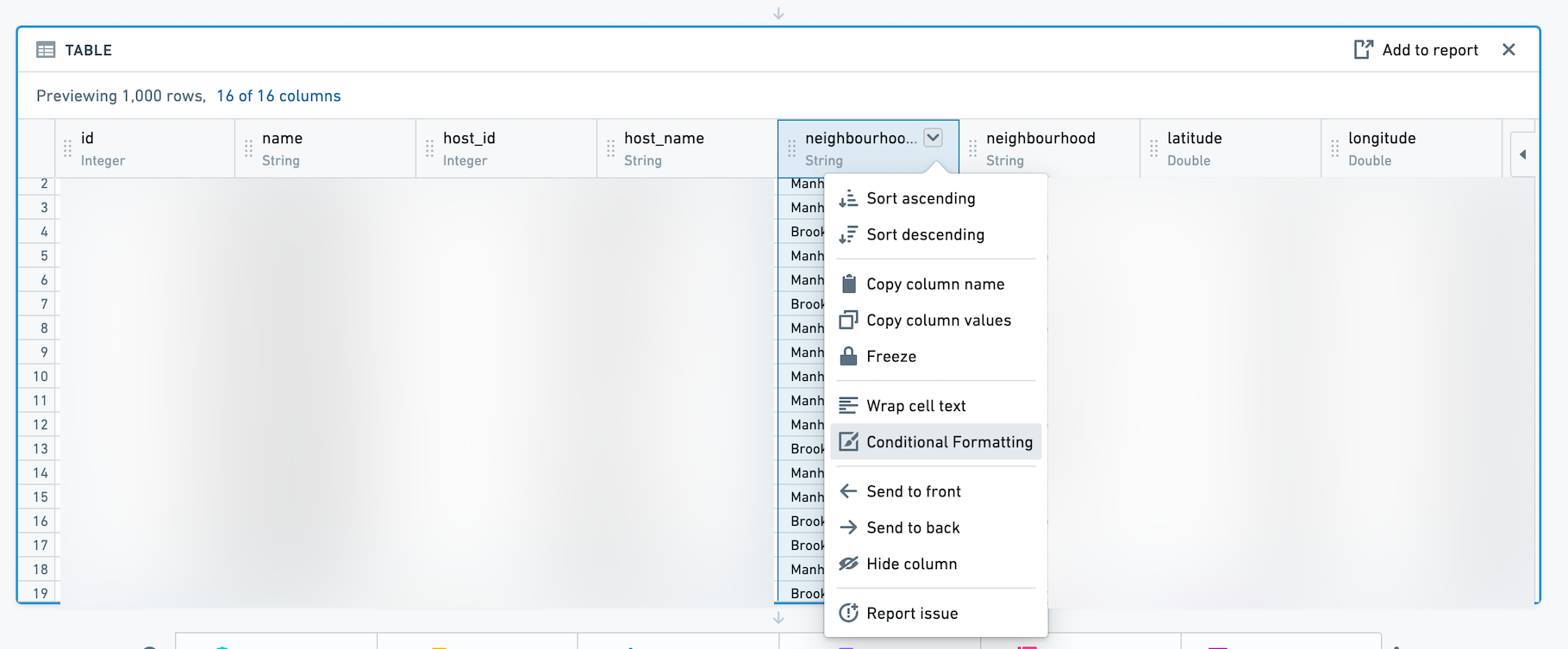
次に、ダイアログを使用して特定の列に対する Rules を追加します。条件付きでフォーマットされたセルは、選択された色のテキストと背景で表示されます。Date 列には Rules はサポートされていません。
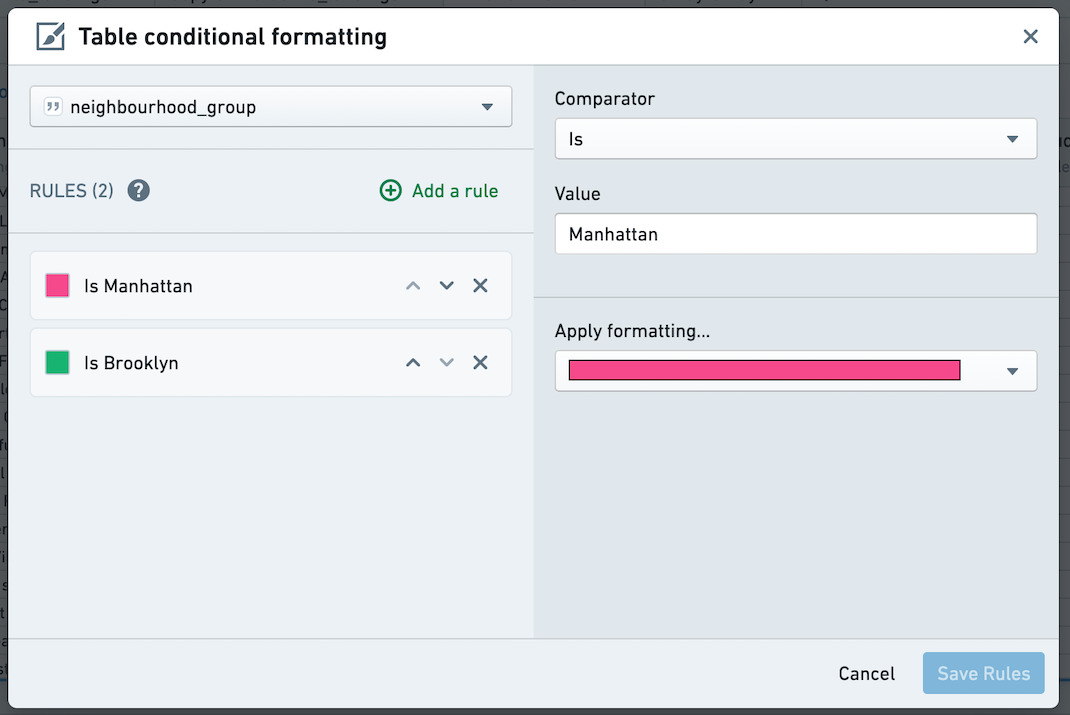
Table ボード vs. Table パネル
ユーザーのパスの任意のポイントで Table ボードを追加して、その時点でのデータのクイックプレビューを取得するか、パスビューから Table パネル に切り替えることができます。
Table パネルはテーブル(ボードではなく)を中心にするため、各ボードを追加する際にデータがどのように変化するかを確認できます。これは特に expressions を書くときに役立ちます。
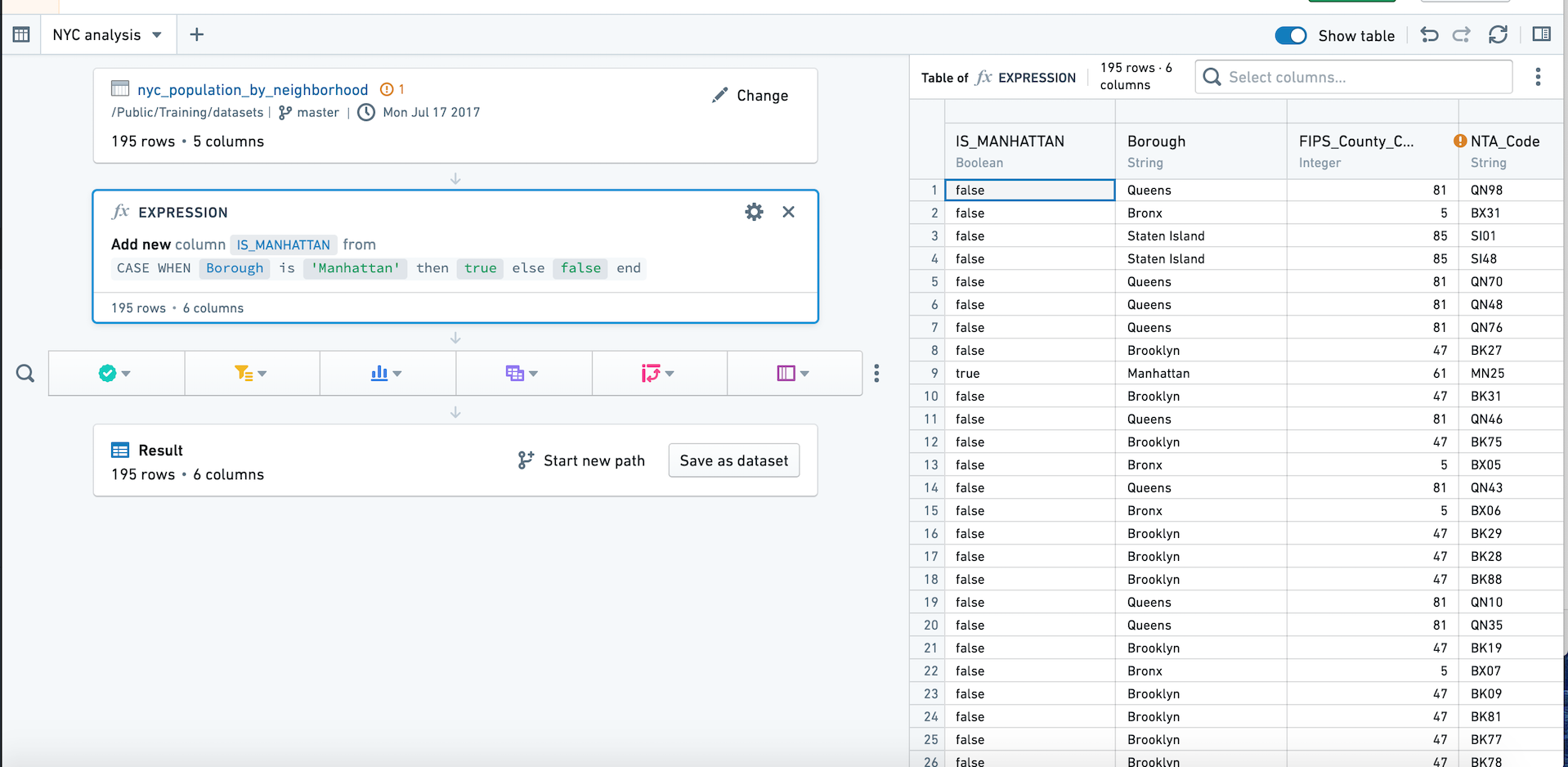
右上の Table をクリックして Table パネルに切り替えます。再度ボタンをクリックするか Hide table をクリックしてパスビューに戻ります。
Table パネルは条件付きフォーマットをサポートしていません。
Histogram
Histogram ボードは、特定の列の異なる値を集約し、結果を棒グラフとして表示します。
たとえば、次のヒストグラムは、ニューヨークのどの地区でタクシー乗車が始まったかによって、タクシー乗車の平均時間を計算します。
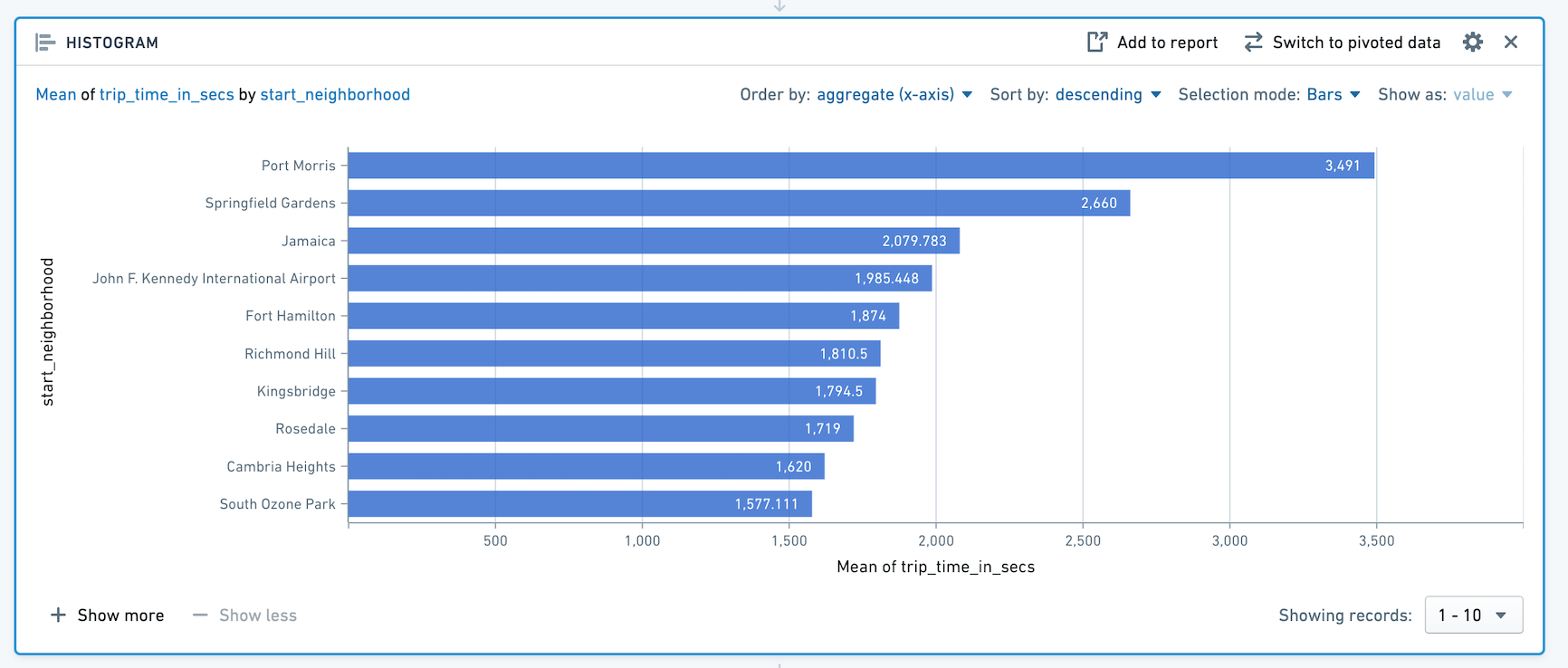
上位 10 本のバーのみが表示されることに注意してください。さらに多くのバーを表示するには、+ Show More をクリックします。一度に最大 50 個の値を表示できます。50 個以上の値がある場合は、ドロップダウンを使用して範囲の他の部分に移動します。
SQL Equivalent
Histogram ボードは SQL の GROUP BY 句の視覚化です。
上記のヒストグラムは、次の SQL クエリと同等です。
Copied!1 2 3SELECT start_neighborhood, mean(trip_time_in_secs) FROM <table name> GROUP BY start_neighborhood
-- 各スタート近隣エリアごとの平均旅行時間(秒単位)を計算するクエリ
-- start_neighborhood でグループ化し、trip_time_in_secs の平均を求める
### 設定
* **Y 軸**
* データをグループ化するための行を選択します。この行の離散値に基づいてデータがグループ化され、その後、集計が計算されます。
* **X 軸**
* 計算する集計を選択し、集計が **Count** でない場合は、適用する列を選択します。
* **集計**
* 使用可能な集計指標は、**Count**(レコード数)、**Unique Count**、**Min**、**Max**、**Sum**、**Mean**、**Approx. Median**、**Standard Deviation**、および **Variance** です。
* **Count** を除くすべての集計には、集計が適用される列を指定する必要があります。**Unique Count** の場合は、任意の列を選択できます。
* **Min**、**Max**、**Sum**、**Mean**、**Approx. Median**、**Standard Deviation**、および **Variance** は、数値列にのみ適用されます。
* 集計は、Y 軸として選択された列の各異なる値に対して計算されます。
:::callout{theme=neutral title="Approximate median"}
**Approx. Median** 集計は概算です。Contour は、パーセンテージ値 0.5 およびデフォルトの精度を持つ [percentile_approx ↗](https://spark.apache.org/docs/2.3.0/api/sql/index.html#percentile_approx) 関数を呼び出します。
:::
### ピボットデータに切り替える
**Switch to Pivoted Data** をクリックすると、ヒストグラムの後に追加されるボードは、元のデータセットではなく、テーブルで計算された集計データを使用します。
新しいデータセットには、元のヒストグラムの設定で Y 軸に選択した列と、集計の列が含まれます。例えば:

### ソート
ヒストグラムは、デフォルトで、降順の集計でソートされます。非常に大きなヒストグラムでは、集計の最大 1,000 の値に対してソートが実行されます。
ドロップダウンを使用して、代わりに Y 軸の列の値でソートするか、またはソートの方向を変更することができます。
### フィルタリング
ヒストグラム上のデータを選択して、今後のボードのデータセットをフィルタリングします。
**選択モード:**
* Y 軸として選択した列の 1 つまたは複数の異なる値でフィルタリングするには、**Bar** を選択します。

* 集計値でフィルタリングするには、**Range** を選択します。例えば、Range 選択を使用して、特定のしきい値以上の値を持つカテゴリーだけを選択することができます。

次に、選択された値*のみ*をフィルタリングするには **Keep** を選択し、選択されていない値のみを保持するには **Remove** を選択します。

---
## 分布
分布ボードは、集計指標の数値変数の分布を表示します。
分布ボードはヒストグラムに似ていますが、特定の値ではなく、値の*範囲*に基づいて集計されたデータを表示します。例えば、次の分布では、顧客の年齢に関するデータが表示されます。年齢は、10 の範囲(または「バケット」)に分けられます。

### SQL 相当
分布ボードの計算では、まず X 軸の最小値と最大値を見つけ、バケットを計算する関数を作成します。その後、分布の SQL 相当は、以下のようになります。
```sql
SELECT X_AXIS_BUCKET_FUNCTION([x-axis-column]), <AGGREGATE_METRIC>([aggregate-column])
FROM <PARENT_BOARD>
GROUP BY X_AXIS_BUCKET_FUNCTION([x-axis-column])
### 設定
* **X軸**
* 数値の行を選択します。この行の値は等幅の範囲(つまり、データが10、100、または1000の「バケット」に等しく分割される)にグループ化され、その後、集約が適用されます。また、この軸のスケール(線形または対数)を設定することもできます。
* **Y軸**
* 各範囲で計算するための集約メトリクスを選択します。
* 利用可能な集約メトリクスは、**Count**(レコード数)、**Unique Count**、**Min**、**Max**、**Sum**、**Mean**、**Approx. Median**、**Standard Deviation**、そして **Variance** です。**Count** を除き、どの行に集約を適用するかを指定する必要があります。
* Y軸のスケールも設定できます(線形または対数)。
:::callout{theme=neutral title="Approximate median"}
**Approx. Median** 集約は近似値です。Contour はパーセンテージ値0.5とデフォルトの精度で [percentile_approx ↗](https://spark.apache.org/docs/2.3.0/api/sql/index.html#percentile_approx) 関数を呼び出します。
:::
### フィルター処理
フィルターする範囲を選択するには、チャート上で希望の区間をクリックしてドラッグします。

その後、編集可能なボードフッターで区間をより細かく調整できます。

選択した区間の値を**Keep**することも、それらの値を**Remove**して選択されていない値のみを保持することも選択できます。選択をクリアするには、**Clear** ボタン(**x**)をクリックします。
---
## タイムシリーズ
タイムシリーズボードでは、時間間隔でデータをグループ化し、そのデータに集約メトリクスを計算することができます。
例えば、顧客に関する個人情報を含むデータセットを持っている場合、以下のタイムシリーズボードは各年に生まれた人数を計算します。

さらに、**series** として使用する行を指定することができます。上記の例では、性別を series として使用することを選択できます。すると、タイムシリーズボードは series 行の各値ごとに1つのラインに分割されます。この場合、**F**(女性)または **M**(男性)です。

タイムシリーズは、その集約を*全*データセットで実行し、表示時に出力を最初の1000値に減らすことに注意してください。
### 設定
* **X軸**
* データを時系列にグループ化するためのDateTime行を選択します。その後、時間の単位を選択します - データはその長さの間隔でグループ化されます。利用可能な単位は、**Second**、**Minute**、**Hour**、**Day**、**Week**、**Month**、そして **Year** です。
* **集約**
* 各時間間隔に適用する集約を定義します。
* 利用可能な集約メトリクスは、**Count**(レコード数)、**Unique Count**、**Min**、**Max**、**Sum**、**Mean**、**Standard Deviation**、そして **Variance** です。
* **Count** を除き、どの行に集約を適用するかを指定する必要があります。**Unique Count** の場合、任意の列を選択できます。
* **Min**、**Max**、**Sum**、**Mean**、**Approx. Median**、**Standard Deviation**、そして **Variance** は数値列にのみ適用します。
* **Series**
* データを series に分割する行を選択します。列の各離散値に対して1つの series(チャート内の線として表現される)があります。
:::callout{theme=neutral title="Approximate median"}
**Approx. Median** 集約は近似値です。Contour はパーセンテージ値0.5とデフォルトの精度で [percentile_approx ↗](https://spark.apache.org/docs/2.3.0/api/sql/index.html#percentile_approx) 関数を呼び出します。
:::
### フィルター処理
タイムシリーズ上で日付範囲を選択して、未来のボードのためのデータセットをフィルター処理します。 をクリックし、その後、希望の区間をクリックしてドラッグします。(編集可能なボードフッターで区間をより細かく調整することができます。)選択をクリアするには、 アイコンをクリックします。
ドロップダウンから **Keep** を選択して選択した値のみをフィルター処理するか、または **Remove** を選択して選択されていない値のみを保持するかを選択します。

---
## 行の編集
次のボードを使用してContourで行を編集できます:
* 2つ以上の行を**Combine**します。
* 行を**Duplicate**します(例えば、その行に対して操作を試すために、オリジナルのデータに影響を与えずに)。
* 行をテーブルから**Remove**します。
* 行の名前を**Rename**します。
* ある区切り文字で行を**Split**します。
---
## データの変換
次のボードを使用して列のデータを変換できます:
### Obfuscate
* セル値の**Hashing**(例えば、名前のような機密データを覆い隠すため)。列の各値は、[SHA-1 ↗](https://en.wikipedia.org/wiki/SHA-1) ハッシュ関数を使用して値のハッシュ表現に置き換えられます。
:::callout{theme=warning}
SHA-1ハッシュは解読でき、完全に安全とは言えません。したがって、データコンプライアンスの目的のためには使用しないでください。
:::
* 値の一部の文字数を**Masking**します(例えば、電話番号の最後の2桁を除いてすべてをマスクします)。
* `k`の閾値をデータセットに適用して、同じセットの機密情報を持つインスタンスが少なくとも`k`数存在することを確保し、再識別のリスクを減らすプライバシーテクニックとして、データの列を**K-anonymizing**します。このプロセスは、データの再識別に役立つ特定のフィールドを「抑制」することによって行われます。
:::callout{theme=neutral}
使用ケースに適したk値はコンテキストによって決まります。組織は通常、分析のコンテキストと再識別の統計的リスクに基づいてk値の設定について自身のポリシーを設定します。ポリシーの例としては、[National Center for Education Statistics ↗](https://nces.ed.gov/pubs2011/2011603.pdf) や [U.S Department of Health & Human Services ↗](https://www.hhs.gov/guidance/document/cms-cell-suppression-policy) があります。最低限、k値は常に1より大きく、データセットの行数より小さいべきです。
:::
k匿名化機能を使用すると、ボードはk匿名化する列、k値ターゲット、抑制の戦略、そして抑制後のk値を満たさない行をどうするかを尋ねます。
1. **Columns**: 「準識別子」または外部データとリンクして個々を一意に識別できる属性を表します。
2. **k-value**: 同じセットの機密情報を持つインスタンスが少なくとも`k`数存在するところの閾値`k`を表します。
3. **Strategies**: データをどのように抑制し、どの順序で行うかを表します。指定したk値に到達するための操作の順序を設定できます。列ごとに、k値を満たすためにデータに適用される異なる戦略から選択できます:
* **Bucket**: 整数を範囲で置き換えます。数値型の列が選択された場合のみ利用可能です。
* **Mask**: 最後のn文字を*で置き換えます。
* **Replace:** 全体の値を文字列で置き換えます。デフォルトの動作は`***`を置換値として提案しますが、これはユーザーが提供した値に置き換えることができます。
* **Suppress Column** フラグがチェックされている列は、k値を満たしているかどうかに関係なく、全ての値に戦略が適用されます。この動作は、年齢の範囲化のような場合に特に関連があります。ここでは、全ての値に対して一貫した範囲化戦略があると便利です。
4. **Rows that do not meet the k-value post-suppression:** 一部の行がk値の閾値を満たさず、`k`より大きいカウントに抑制することができない場合、以下のオプションが利用可能です:
* **Keep:** データが失われないように行を保持します。これらの行を保持すると、データセットはk匿名化されません。これは、k匿名化の結果を確認するための有用なステップです。
* **Drop:** k値を満たさない全ての行を削除します。削除を選択する場合、匿名化前後の行数を計算して、削除された行数を理解することが重要です。
* **Redact:** テーブル内の全ての値を`***`で匿名化します。このオプションは、行数を同じに保持したい場合に特に関連があります。

5. 列内のテキストを**Find and replace**します、または空のセルまたは null セルを見つけます。このボードは、String または Numeric タイプのプロパティをサポートします。
6. 文字列から**Parse dates**します。

---
## チャート
Contour のチャートボードでは、データを分析するためのカスタムチャートを作成できます。
### 設定
メインのチャートレイヤーのチャートタイプを選択し、次にx軸とy軸を設定します。現在、チャートボードでは以下のタイプのチャートが提供されています:
**Bar**

**Horizontal Bar**

**Line**

**Scatter**

**Heat Grid**

**Pie**

**Segment by**
ヒートグリッドとパイ以外のチャートタイプでは、**データを series に分割する**ことも選択できます。
**Sorting**
**Options** セクションを展開して、チャートデータの並べ替え方法を変更します。
チャートデータを主要な層の値で順序付けすることができます:
* Xの値
* Yの値
* カスタムの列値。このソート値はデータセットの*任意の*列(チャートにプロットされていないものも含む)であることが可能です。
以下の例は、オリンピックで国が受け取った金メダルの数によって棒グラフをソートします:

データは昇順または降順でソートできます。オーバーレイプロットの値はチャートデータの順序付けには使用できません。
**Formatting**
Format タブを使用してチャートを設定します。X軸とY軸のタイトル、軸の書式設定、凡例の位置、シリーズの並べ替え、シリーズの色を変更することができます。
**Adding Overlays**
**+ Add Overlay** をクリックしてオーバーレイプロットを追加できます。例えば、棒グラフの上に折れ線グラフを重ねることができます。
オーバーレイを追加すると、チャートが現在のパスのデータを使用するか、別のデータセットから使用するかを選択できます。
:::callout{theme=neutral}
別のデータセットからデータをプロットすることは、そのデータセットを作業セットに結合することでは*ありません*。データセットを結合するには、[Join board](#join) を使用する必要があります。
:::
*データパスの一部であるのはメインのチャートレイヤーのみ*であることに注意してください。他のレイヤーは純粋に表示目的のものです。つまり、オーバーレイレイヤーのデータを選択したり、それ以外の方法で操作したりしても、パスの下流のデータには影響し*ません*。
個々のレイヤーの値が関連していない場合、またはデータ範囲やプロットスケールが大幅に異なる場合は、チャートレイヤーを別のy軸にプロットすることができます。

**Bucket selection**
**Group by**の列(例えば、x軸)と**Segment by**の列を設定する際に、データポイントをバケット化する方法を選択できます。数値、日付、または時間の列のみがバケット化できます。例えば、棒グラフを作成し、x軸の**Group by**列として日付列を選択し、バケットタイプとして**Year**を選択すると、結果のチャートには毎年の棒が表示されます。利用可能なバケットタイプは以下の通りです。
数値列のバケットタイプ:
* **Exact value:** データはバケット化されず、正確な値が表示されます。
* **Optimal:** バケットの数は、基礎となるデータ範囲のポイントの平方根と等しくなります。データ範囲は、列の最大値と最小値の差です。
* **Most granular:** チャートは、[Result limit](#result-limit) 内に収まる最大数のバケットを使用します。可能な場合は正確な値が使用されます。
* **Custom:** バケットの数を手動で選択できます。ただし、バケットの数は[Result limit](#result-limit) を超えることはできません。

日付と時間の列のバケットタイプ:
* **Exact time:** データはバケット化されず、正確な値が表示されます。
* **Rounding:** データは最も近い**Second**、**Minute**、**Hour**、**Day**、**Week**、**Month**、または**Year**にバケット化されます。これは選択によります。例えば、**Year**でバケット化する場合、データポイントの日付が2018年6月15日であれば、そのデータポイントは2018年のバケットに入ります。
* **Ordinals:** データは序数の日付にバケット化されます。例えば、**Day of week**を選択すると、データは週の各日に対して一つずつ、合計7つのバケットにバケット化されます。

:::callout{theme=neutral}
バケットの選択が結果の制限に収まらない場合、収まる最も詳細なオプションが適用され、データが削除されることはありません。詳しくは<a href="#result-limit">Result limit</a>をご覧ください。
:::
### Result limit
Contourは、ブラウザ上に表示するデータポイントの数に制限があります。実際には、Contourは画面にあるピクセル数以上のデータポイントを表示することはできません。正確なチャートを作成し、データを落とさないために、チャートボードは結果の制限内に収まる最も詳細なバケット選択にチャート設定をリバケット化します。
結果の制限はPalantir管理者によって設定され、デフォルトでは1000ポイントに設定されています。数値、日付、または時間の列に対してリバケット化が行われます。
リバケット化を説明するために、以下の例を考えてみてください:
* 生年月日を含むデータセットでチャートボードが作成されました。
* ボードは棒グラフに設定され、x軸は誕生日の列に設定されています。例えば、同じ誕生日を持つ人数をカウントします。
* 生年月日の列は秒単位で日付を指定しているので、Second バケットタイプが選択されます。
* このデータセットでは、秒ごとの一意の誕生日の数が結果の制限を超えています。
* そのため、計算時にチャートボードは自動的にデータをSecondではなくHourにバケット化します。Hourはこの特定のデータセットに対して結果の制限内に収まる最も詳細なバケットサイズです。

### フィルター処理
チャート上でデータを選択して、未来のボードのためのデータセットをフィルター処理します。Ctrl+Click または Cmd+Click を使用して複数選択します。
チャート上でパンとズームを使用して、データをより容易に確認できます。また、チャート上の棒や点にマウスを置くと、ツールチップが表示され、何を見ているのかを強調表示します。
---
## グリッド
グリッドボードは[histogram](#histogram)に似ていますが、グリッドボードはデータを1つではなく2つの列で集約し、結果をヒートグリッドチャートで表示します。(2つ以上の列については、[pivot table](#pivot-table)を使用できます。)例えば、以下のグリッドは教育レベルと年収を比較します:

### SQL Equivalent
グリッドボードは、ヒストグラムとピボットテーブルボードと同様に、集約クエリの視覚化です。
グリッドは、次のSQLクエリに近似しています:
```sql
SELECT [x-axis-column], [y-axis-column], <AGGREGATE_METRIC>([aggregate-column])
-- [x-axis-column]:X軸の値
-- [y-axis-column]:Y軸の値
-- <AGGREGATE_METRIC>:集約関数(例:SUM、AVG、COUNTなど)
-- [aggregate-column]:集計対象のカラム
FROM <PARENT_BOARD>
-- <PARENT_BOARD>:データを取得するテーブルまたはビューの名前
GROUP BY [x-axis-column], [y-axis-column]
-- GROUP BY:指定されたカラムでデータをグループ化
### 設定
* **X軸** と **Y軸**
* 2つの列を選択します。これらの列のユニークな値の組み合わせがグリッドのセルを形成します。
* **集計**
* グリッドの各セルに対して計算する集計メトリックを選択します。集計の結果がセルの色を決定します。
* 利用可能な集計メトリックは以下の通りです: **Count** (レコード数), **Unique Count**, **Min**, **Max**, **Sum**, **Mean**, **Approx. Median**, **Standard Deviation**, および **Variance**。
* **Count** 以外では、どの列に集計を適用するかを指定する必要があります。**Unique Count** では任意の列を選択できます。
* **Min**, **Max**, **Sum**, **Mean**, **Approx. Median**, **Standard Deviation**, および **Variance** は数値列にのみ適用されます。
:::callout{theme=neutral title="Approximate median"}
**Approx. Median** 集計は近似値です。Contour は [percentile_approx ↗](https://spark.apache.org/docs/2.3.0/api/sql/index.html#percentile_approx) 関数をパーセンテージ値 0.5 とデフォルトの精度で呼び出します。
:::
### フィルタリング
グリッド上で1つ以上のセルを選択して、今後のボードのためにデータセットをフィルター処理することができます。もう一度セルをクリックして選択を解除します。
**Keep** を選択すると選択された値のみにフィルター処理され、**Remove** を選択すると選択されていない値のみが保持されます。

---
## ヒートマップ
ヒートマップボードは、ジオコーディングされたデータを地図上に表示し、値を色で表現します。

### 設定
* 緯度/経度データを含む列を指定します。
* 任意で、Geohash列を指定します。
* 次に、計算する集計メトリックを選択します。
* 利用可能な集計メトリックは以下の通りです: **Count** (レコード数), **Unique Count**, **Min**, **Max**, **Sum**, **Mean**, **Approx. Median**, **Standard Deviation**, および **Variance**。
* **Count** 以外では、どの列に集計を適用するかを指定する必要があります。**Unique Count** では任意の列を選択できます。
* **Min**, **Max**, **Sum**, **Mean**, **Approx. Median**, **Standard Deviation**, および **Variance** は数値列にのみ適用されます。
:::callout{theme=neutral title="Approximate median"}
**Approx. Median** 集計は近似値です。Contour は [percentile_approx ↗](https://spark.apache.org/docs/2.3.0/api/sql/index.html#percentile_approx) 関数をパーセンテージ値 0.5 とデフォルトの精度で呼び出します。
:::
### フィルタリング
ヒートマップ上で円を描いて、その半径内にあるジオデータを含むすべての行を選択することができます。
 をクリックし、クリックしながらドラッグして地図上に円を描きます。

選択した半径内の値を **Keep** するか、選択されていない値のみを保持する **Remove** を選択します。
選択をクリアしてフィルターを解除するには、地図上の円の外側をクリックします。
---
## ピボットテーブル
ピボットテーブルボードを使用すると、複数の次元にわたるデータの複数の集計値を迅速に計算できます。この計算結果はサンプリングされているため、テーブルに表示される内容が完全でない場合があります。このサンプリングについては以下で詳しく説明します。
顧客の人口統計情報を含むデータセットを例にとると、以下のピボットテーブルは、年齢ごとの既婚女性、既婚男性、独身女性、独身男性の顧客数を計算します。

### サンプリングに関する重要な注意点
フロントエンドおよびバックエンドのパフォーマンスの低下を防ぐため、計算する行数は制限されています。ほとんどの環境では制限は1,000行であり、一般的には構成変更できません。

上記のスクリーンショットのように、ピボットテーブルの行集計が `PERIOD` と `PRACTICE` で、列集計が `POSTCODE` であると仮定します。各組み合わせについて、行数と列 `NAME` の最大値を取得したい場合、ユーザーの環境での制限がデフォルトの1,000行である場合、1,000の完全な行だけが計算されます。各行は完全であることが保証されていますが、一部の行が存在しない場合があります。
ピボットテーブルの列をソートすると、ソートはプレビュー上で行われ、データセット全体に対してではありません。データセット全体をソートするには、Sort Board を使用します。詳細は [Sort](#sort) を参照してください。
ピボットされたデータ全体と対話するためには、ボード上の **Switch to pivoted data** オプションを使用してください。これにより、ピボットテーブルボードの下にあるすべてのボードで完全に計算されたピボットデータへの Contour 分析が切り替わります。あるいは、ピボットテーブルの上流でデータをさらにフィルター処理して、セルの制限を回避することも試みることができます。
### 設定
:::callout{theme=success title="Tip"}
列集計を指定する際、列内の値はケースインセンシティブにユニークである必要があります。たとえば、列 "Borough" に "Brooklyn" と "brooklyn" の値が含まれている場合、"Borough" を列集計として指定すると、ピボットテーブルの計算は失敗します。この問題を回避するために、すべての値を一貫したケースにキャストすることを検討してください。
:::
* **列**
* 集計を実行する列を1つ以上選択します。元のデータセットの選択した列の値の組み合わせがピボットテーブルの列を形成します。
* **行**
* 元のデータセットから行を定義する列を1つ以上選択します。元のデータセットの選択した列の値の組み合わせがピボットテーブルの行を形成します。
* **集計**
* 利用可能な集計メトリックは以下の通りです: **Count** (レコード数), **Unique Count**, **Min**, **Max**, **Sum**, **Mean**, **Approx. Median**, **Standard Deviation**, および **Variance**。
* **Count** 以外では、どの列に集計を適用するかを指定する必要があります。**Unique Count** では任意の列を選択できます。
* **Min**, **Max**, **Sum**, **Mean**, **Approx. Median**, **Standard Deviation**, および **Variance** は数値列にのみ適用されます。
:::callout{theme=neutral title="Approximate median"}
**Approx. Median** 集計は近似値です。Contour は [percentile_approx ↗](https://spark.apache.org/docs/2.3.0/api/sql/index.html#percentile_approx) 関数をパーセンテージ値 0.5 とデフォルトの精度で呼び出します。
:::
列、行、集計の間でドラッグアンドドロップが可能です。
単一のピボットテーブルで複数の集計を指定できます。選択した行と列の各組み合わせに対してそれぞれの集計が計算されます。
総計も計算できます。総計はデータセット全体に対して集計を実行することで計算されます(つまり、**Unique Count** の総計はデータセット全体のユニークカウントの総数であり、**Mean** の総計はデータセット全体の平均です)。
### ピボット(集計データに切り替え)
**Pivot**(集計データに切り替え)をクリックすると、ヒストグラムの後に追加されるボードは、元のデータセットではなく、テーブルで計算された集計データを使用します。
新しいデータセットには、元のヒストグラム設定でY軸に選択した列と集計列が含まれます。例えば:

---
## 列エディタ
列エディタボードを使用すると、データセットから列を簡単に削除したり、新しい列を派生させたりできます。後続のボードは、ユーザーが保持することを選択した列のセットを利用します。
### 新しい列を追加
データセット内の既存の列に対して二元操作を行い、新しい派生列を作成したり、文字列の列を数値または日付形式の列に解析したりできます。
**SQL Equivalent**
派生列は、SQL または Spark でオペレーターを使用することと同等です。例えば、以下は **Income per person** の列を派生させます。
```sql
SELECT
[Household Members], -- 世帯人数
[Marital Status], -- 婚姻状況
[Income Column] / [Household Members] AS [Income per person] -- 一人当たりの収入
FROM [Table Name]
### 既存の列
列を削除するには、**Show existing columns** を選択し、削除したい列の名前を選択します。削除した列を再度追加するには、もう一度選択します。多くの列を削除したい場合は、**Remove All** を選択してから、保持したい列を選択することもできます。
### 重複する行を削除する
列エディタボードで **Remove duplicate rows** オプションを使用して、重複する行を削除できます。

**SQL に相当する操作**
列エディタボードを使用して列を削除する操作は、SQLで列名を選択する操作に相当します。例えば、5つの列(A-E)があるテーブルで、以下のように列DとEを削除します:
```sql
SELECT A, B, C FROM table_name;
Copied!1 2SELECT columnA, columnB, columnC FROM <tableName> -- <tableName>にはテーブルの名前を入力してください
マルチ列エディター
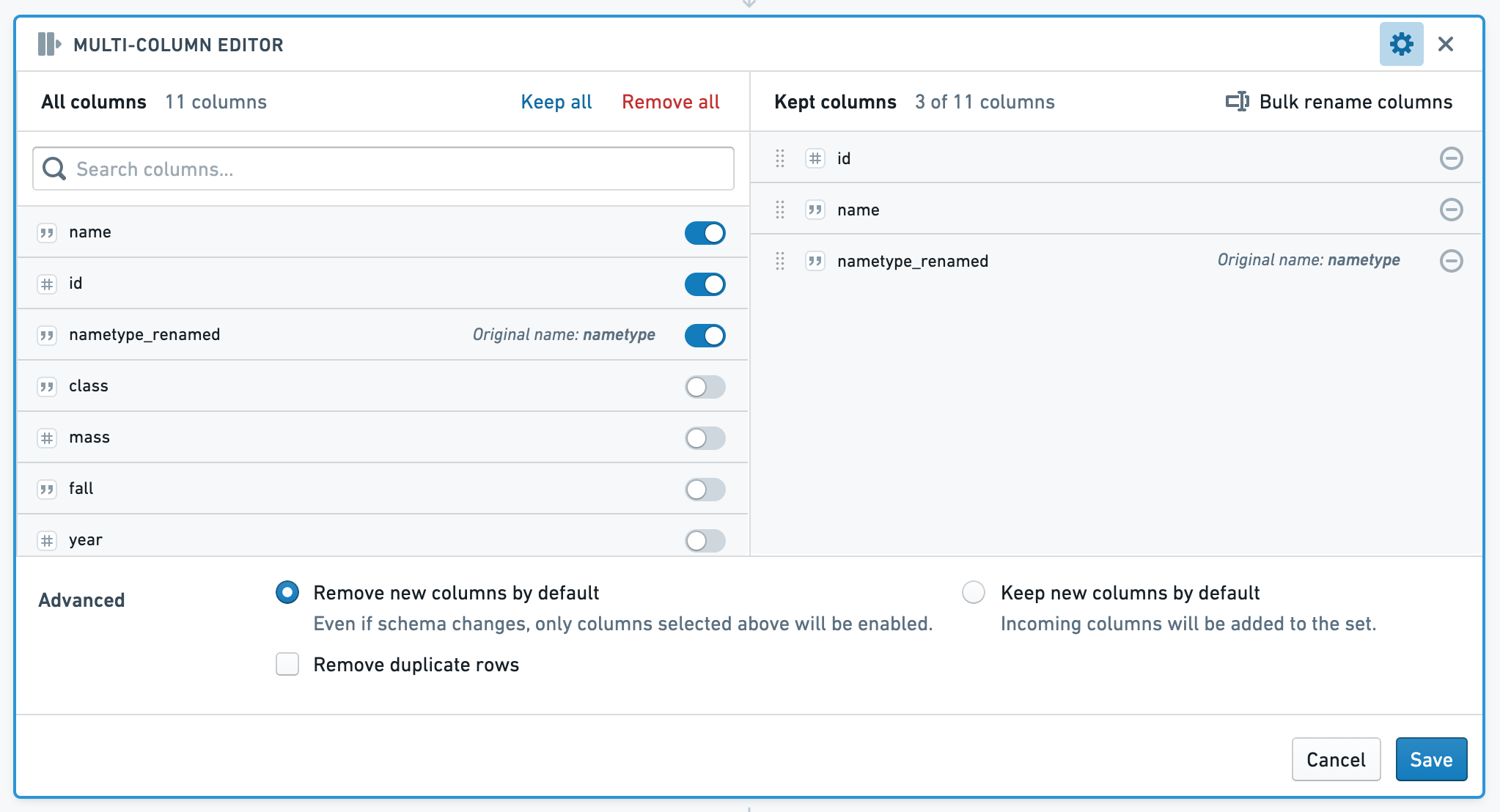
マルチ列エディターボードでは、データから列を並べ替え、名前を変更し、削除することや、重複する行を削除することができます。次のボードは、ユーザーが保持することを選択した列のセットを使用します。
ボードの左側にはすべての列が表示され、右側には保持する列が表示されます。保持する列セクションでは、保持する列の名前を変更したり、順序を変更したり、一括名前変更機能を使用することができます。
SQL 相当
列の並べ替え、名前変更、削除は、SQLで列名を選択することと同等です。例えば、5つの列 A-E を持つテーブルがある場合、以下のコードは列 D と E を削除し、A を A_1 に名前変更します:
```sql
SELECT columnA as columnA_1, columnB, columnC
FROM <tableName>
Copied!1 2-- 列 columnA を columnA_1 として選択し、columnB と columnC を含めています。 -- <tableName> を実際のテーブル名に置き換えて使用します。
Enrich
Enrich ボードでは、現在作業中のデータセットを他のデータセットと結合し、一致する結果をユーザーのデータにマージできます。
Link
Link ボードでは、別のデータセットと結合し、そのデータセットの一致するレコードを返します。これは、セット数学の keep only 操作とは異なり、リンクされた (右側の) テーブルからのみ列を返します。
Set math
Set math ボードでは、ユーザーの現在のデータセットを他のセットに基づいて変更できます。他のデータセットに存在するデータのみを保持するようにデータセットをフィルター処理する (keep only)、別のデータセットからデータを追加する (add)、または別のデータセットの結果に基づいてデータを削除する (remove) ことができます。
Join
Join ボードでは、ユーザーの Palantir 管理者によってキュレーションされた推奨結合テンプレートが提示されます。推奨結合を追加または変更したい場合は、管理者に連絡してください。
Export
Export ボードでは、ユーザーの分析セットを CSV または XLS ファイルとしてダウンロードできます。
ドロップダウンから csv または xls を選択し、Export をクリックします。サーバーでの操作が完了した後、ファイル名をカスタマイズするオプションが表示されます。その後、Download <#> records をクリックしてファイルをダウンロードします。


Reorder columns
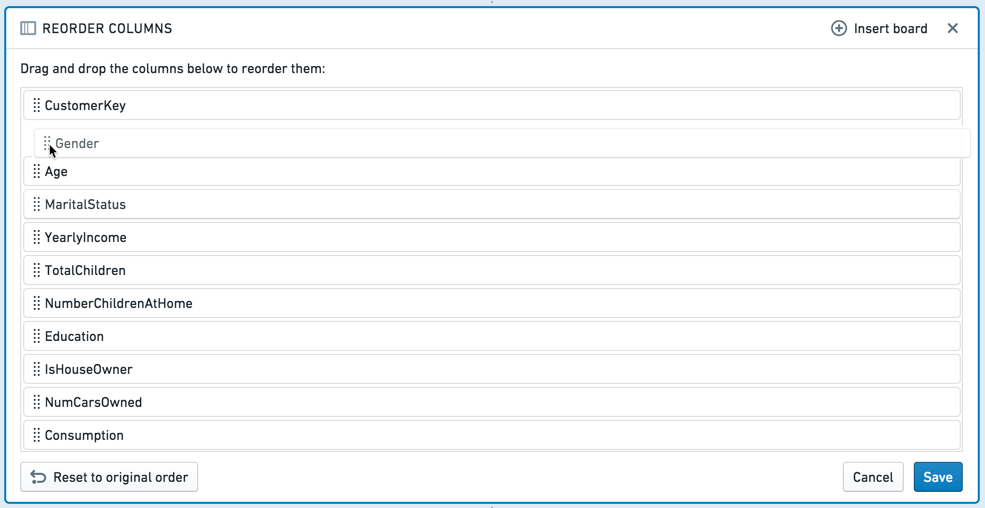
Reorder columns ボードでは、テーブル内の列をドラッグアンドドロップして順番を変更できます。
Macro
Macro ボードでは、以前に作成したマクロをユーザーのパスに適用できます。
Sort
Sort ボードでは、データセット内のすべてのデータをソートできます。このソートは分析に限定され、保存されたデータセットには反映されないことに注意してください。ソートは、下流の集約 (例: 結合や重複行の削除) によって失われる可能性があるため、これらの集約をソート前に行うことをお勧めします。
Calculation
Calculation ボードでは、ユーザーのデータに対して複数の集計計算をカードやリストの形式で表示できます。利用可能な集計メトリクスは次のとおりです: Unique Count, Min, Max, Sum, Mean, Median, Standard Deviation, および Variance。
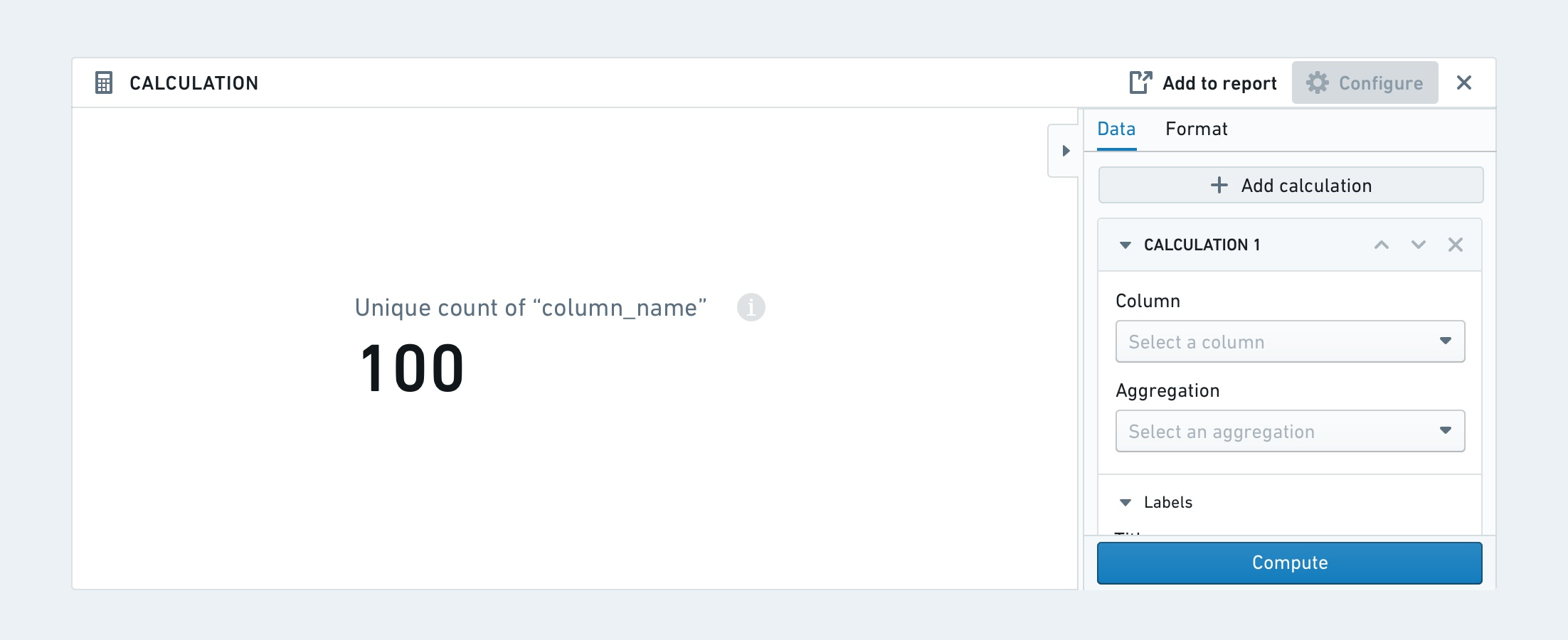
Calculation ボードは、カード または リスト としてフォーマットできます。
カード形式には、水平または垂直の方向 や メトリクスのサイズ の追加フォーマットオプションがあります。
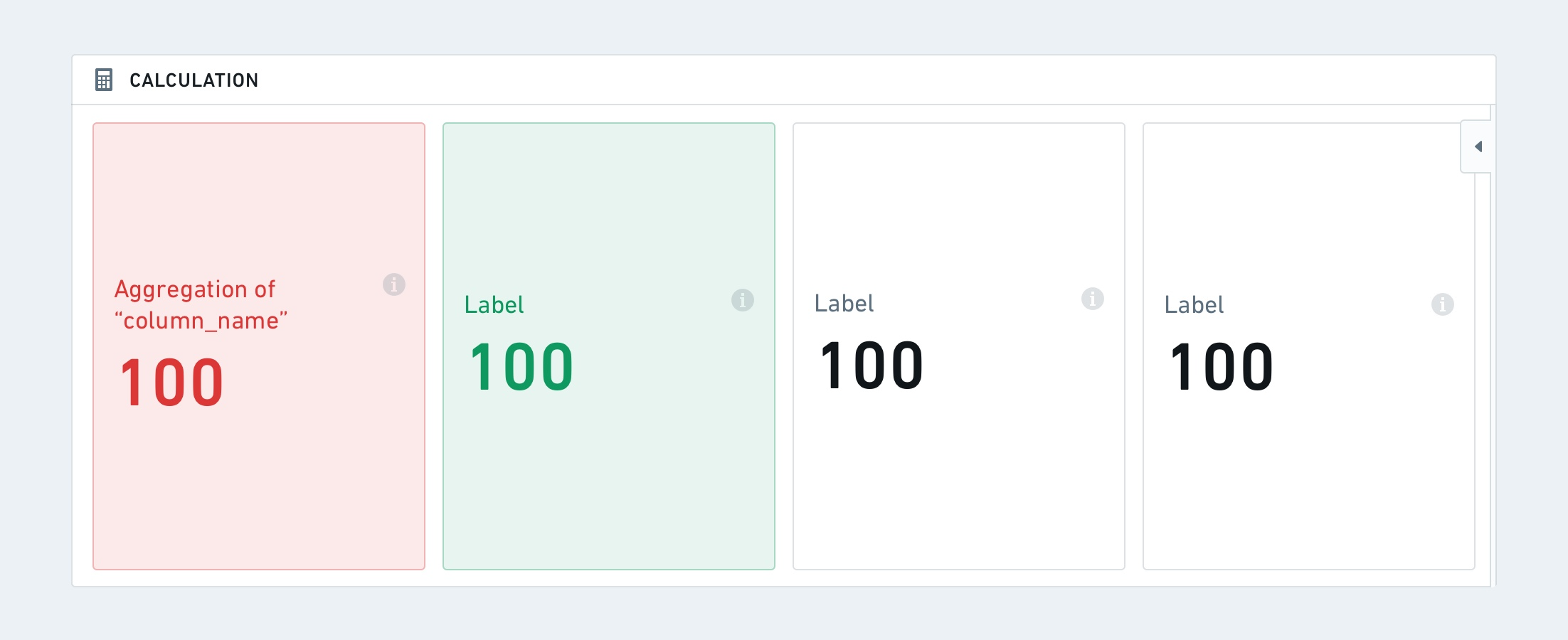
最後に、各計算には指定されたルール (条件) に基づく条件付きフォーマットを設定できます。これは、条件が満たされたかどうかに応じてフォントの色や背景色が変わることを意味します。
Unpivot
Unpivot ボードでは、いくつかの列を行に変換することでデータを再構成できます。選択した列は、2つの新しい列に再フォーマットされます。ヘッダー列 (元の列名を含む) と値列 (元のデータ値を含む) です。