注: 以下の翻訳の正確性は検証されていません。AIPを利用して英語版の原文から機械的に翻訳されたものです。
グローバルコード
グローバルコードペインは、ワークブックインターフェースの右側でアクセスでき、その言語のワークブック全体で利用できる変数や関数を定義することができます。たとえば、複数の変換で使用される定数を定義するためにグローバルコードを使用したり、繰り返し使用したいヘルパー関数を定義することができます。
例
この例では、titanic_dataset を元に、乗客の年齢を入力として、年齢層を返す簡単な関数を作成します。
まず、ページ右側にある Python グローバルコードパネルを開きます。表示は次のようになります。
グローバルコードパネルが開いたら、以下のコードをパネルにコピー&ペーストします:
Copied!1 2 3 4 5 6 7 8 9 10 11 12def return_age_bracket(age): if age is None: return 'Not specified' # 年齢が指定されていない場合 elif (age <= 12): return '12 and under' # 12歳以下の場合 elif (age >= 13 and age < 19): return 'Between 13 and 19' # 13歳から19歳未満の場合 elif (age >= 19 and age < 65): return 'Between 19 and 65' # 19歳から65歳未満の場合 elif (age >= 65): return '65 and over' # 65歳以上の場合 else: return 'N/A' # それ以外の場合(適用外)
このグローバル関数を使用するには、新しい titanic_dataset から派生したPythonトランスフォームを作成し、以下のコードをトランスフォームに貼り付けます:
Copied!1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17def passengers_by_age_bracket_udf(titanic_dataset): from pyspark.sql.functions import udf # 入力データフレームとしてタイタニックのデータセットを使用 input_df = titanic_dataset # return_age_bracket関数を用いてUDFを作成 age_bracket_udf = udf(return_age_bracket) # 新しい列 "age_bracket" を追加し、その値をage_bracket_udfにより生成 output_df = input_df.withColumn("age_bracket", age_bracket_udf(input_df.Age)) # 出力データフレームは "Name" と "age_bracket" のみを選択 output_df = output_df.select(output_df.Name, output_df.age_bracket) # 結果を返す return output_df
次に、コードを実行します。すると、次の出力が表示されます:
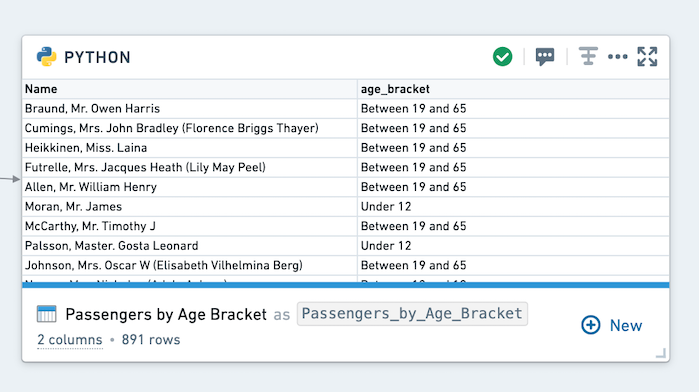
このコードは、ユーザー定義関数(UDFs)、特にループを含むものは、効率が悪いことが多いため、実行に時間がかかるかもしれません。グローバルに定義された関数を使用することが常にベストプラクティスとは限りません。この例では、pyspark.functions がよりシンプルな方法を提供しています:when((condition), result).otherwise(result)。
UDFを使用せずに、上記と同じ結果を得るために試してみましょう:
Copied!1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16def passengers_by_age_bracket(titanic_dataset): from pyspark.sql import functions as F # 入力としてtitanic_datasetを利用します input_df = titanic_dataset # 年齢範囲のカテゴリを作成します。条件に一致しない場合は'N/A'と表示されます output_df = input_df.withColumn("age_bracket", F.when(input_df.Age.isNull(), 'Not specified')\ .when( input_df.Age <= 12, '12 and under')\ .when(( (input_df.Age >= 13) & (input_df.Age < 19)), 'Between 13 and 19')\ .when(( (input_df.Age >= 19) & (input_df.Age < 65)), 'Between 19 and 65')\ .when(input_df.Age >= 65, '65 and over').otherwise('N/A')) # 'Name'と'age_bracket'のみを選択します output_df = output_df.select('Name','age_bracket') # 結果のデータフレームを返します return output_df
ほとんどの状況下で、上記の変換は、UDFを使用した場合の数分に比べて、数秒で実行されるはずです。
再現性に関する注意
結果が再現性を確保するために、グローバルコード内の変数や関数を変更しても、他のトランスフォームには伝播しないことに注意してください。たとえば、Pythonでグローバルコード内にリストを定義する場合は、以下のようになります。
Copied!1 2# リストを作成する my_list = [1, 2, 3, 4]
そして、ユーザーのトランスフォームにリストを更新してください:
Copied!1 2 3 4 5def my_transform(input_df): # my_listという名前のリストに5を追加します my_list.append(5) # my_listの中身を出力します print(my_list)
my_transformを実行すると[1,2,3,4,5]が表示されますが、他のトランスフォームは依然として[1,2,3,4]の値を受け取ります。