注: 以下の翻訳の正確性は検証されていません。AIPを利用して英語版の原文から機械的に翻訳されたものです。
オプションでデータを永続化する
ワークブック内の各変換について、ユーザーは結果をデータセットとして保存するかどうかを選択できます。
データセットとして保存するかどうかを選択する
デフォルトでは、新しい変換はデータセットとして保存されません。保存するには、ロジックペインのトグルを使用します。
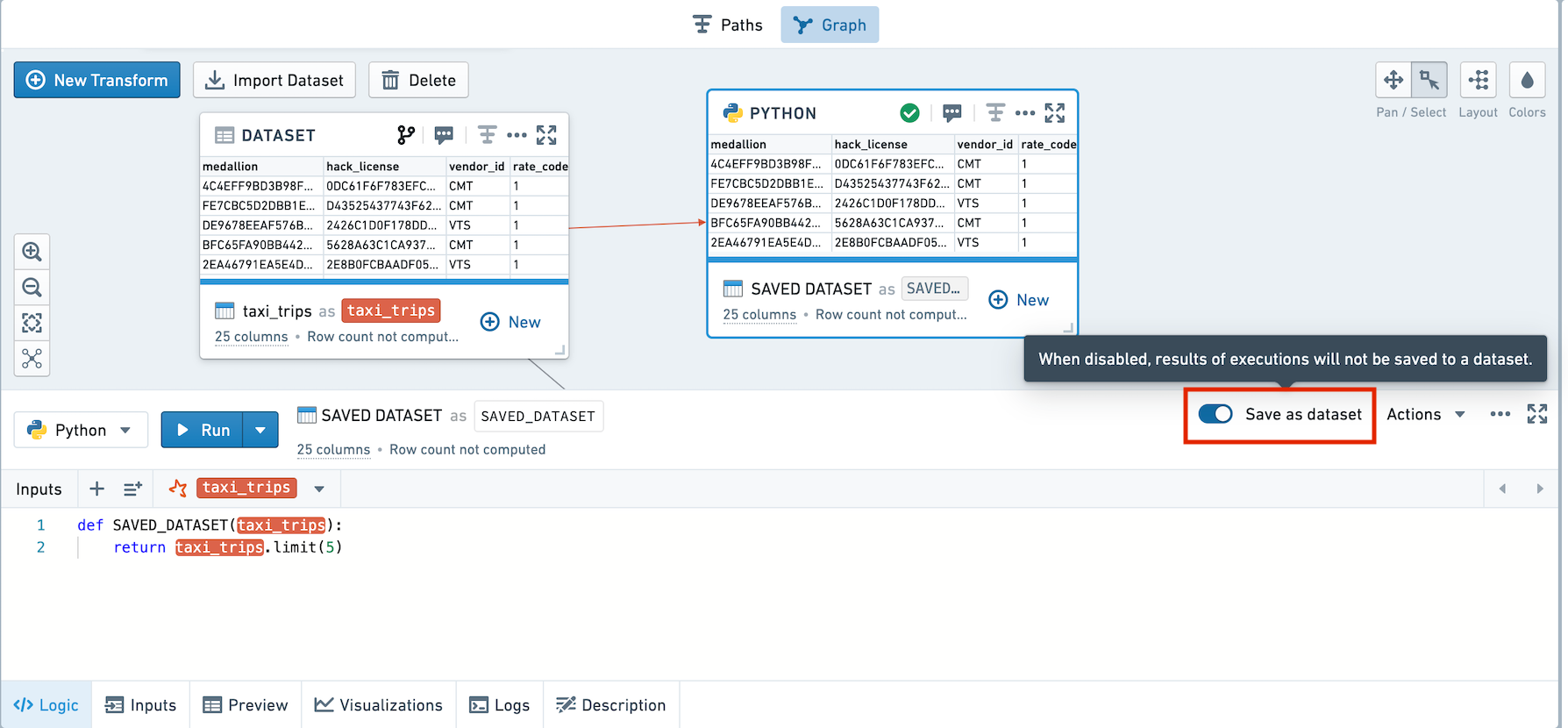
これらのスクリーンショットは、NYC Taxi & Limousine Commission ↗ からのオープンソースデータを使用しています。
複数の変換の永続性を一度に変更するには、左側のバルクエディタを使用します。
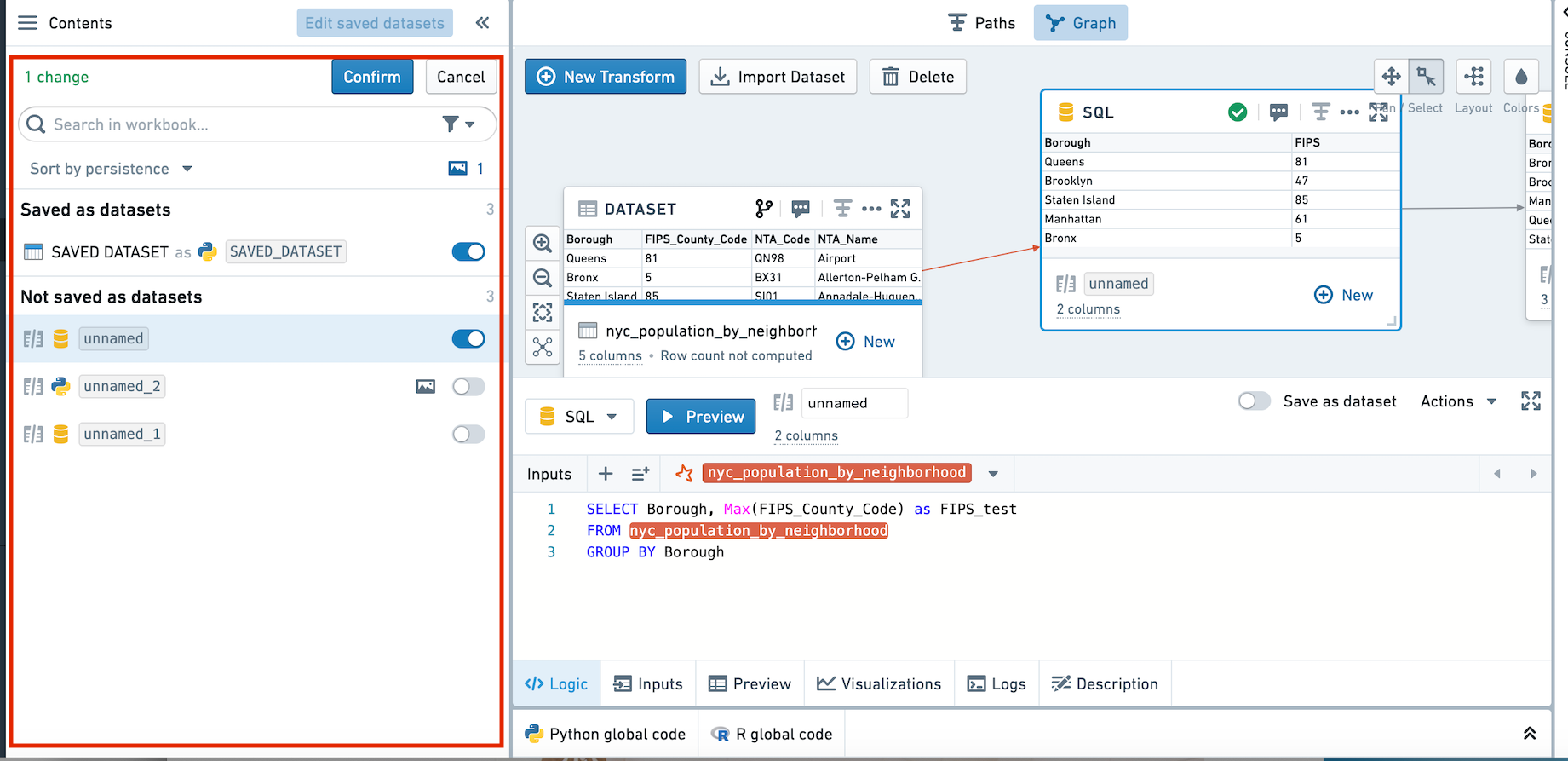
保存されていない変換を保存される変換に変更する場合、以前の保存されたデータセットに再リンクします。以前の保存されたデータセットが存在しない場合、新しいデータセットが作成されます。
保存された変換は、水平な青いバーで示されます。
実行モデル
ノードを実行すると、そのノードの上流にあるすべての未永続化ノードのロジックも実行されます。以下の図では、保存された変換Cを実行すると、未保存の変換Aのロジックも実行されます。
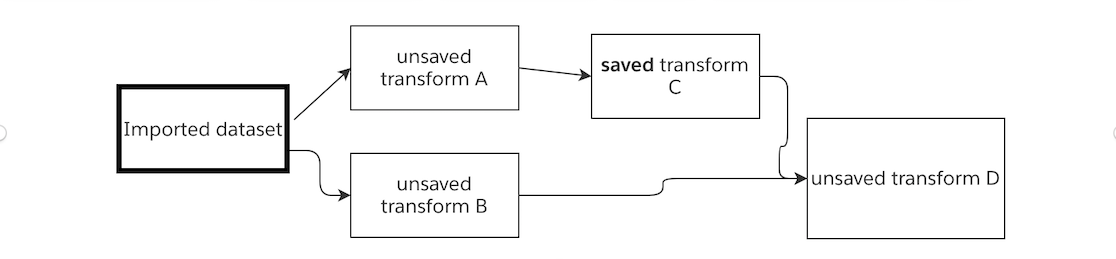
未保存の変換Aのコードを変更して実行しないで、保存された変換Cを実行すると、保存された変換Cの結果はロジックの変更を反映します。
未保存の変換Dを実行すると、保存された変換Cが Foundry データセットから読み込まれ、未保存の変換Bのロジックが実行されます。
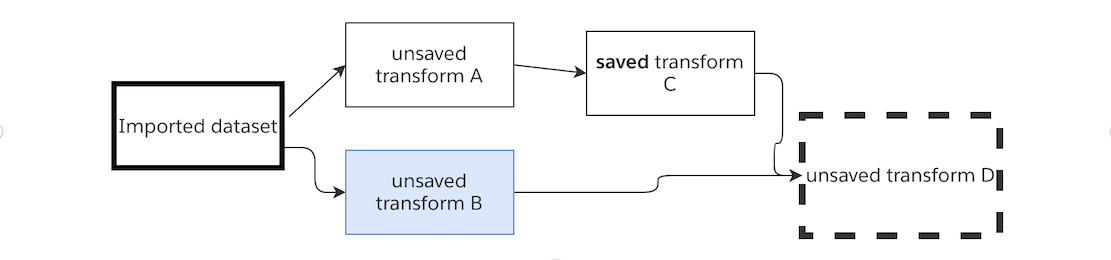
保存された変換Cのトグルをオフにしてデータセットとして保存されなくなると、未保存の変換Dを実行すると、上流の3つの変換すべてのロジックが実行されます。
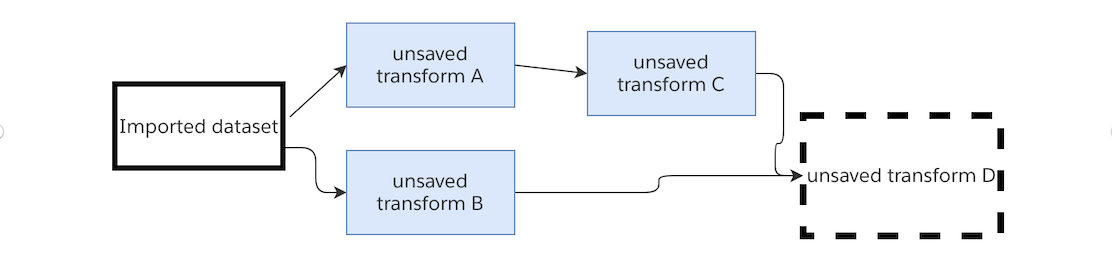
この場合、この一連の変換を実行する場合 - 最終的に未保存の変換Dの結果を表示することが目的であれば、上流の3つの未保存の変換をプレビューする必要はありません。未保存の変換Dを実行することで、4つの変換すべての最新のロジックとインポートされたデータセットの最新のトランザクションが使用されます。
よくある質問
いつ変換をデータセットとして保存すべきですか?
変換が非常に計算量が多く、他の多くの変換の上流で使用される場合、パフォーマンスが低下しないように、データセットとして保存することを検討してください。
ワークブックの外で変換の結果を使用したい場合(例えば、別の Code Workbook や Contour 解析で使用する場合)、変換の結果をデータセットとして保存する必要があります。
変換が関数を非決定的に計算する場合(例えば、row_number関数や現在の時刻を呼び出す関数を使用する場合)、データセットを Foundry に永続化する必要があります。これにより、下流の変換がデータセットに書き込まれた正確な結果を使用することが保証されます。
ワークブックに永続化されていないノードの長いチェーンが含まれている場合、中間ノードを永続化することで定期的にワークブックのチェックポイントを作成することをお勧めします。
いつノードをプレビューすべきですか?
一般的に、プレビュー機能は変換のシリーズを作成する際に、その正確性を検証し、結果をプレビューするために使用する必要があります。変換の一連の処理がコード化されると、プレビュー機能を使用する理由は減少します。
なぜ未保存の変換が Data Lineage に表示されないのですか?
Code Workbook の未保存の変換は、プロジェクト内のリソースではなく、論理ブロックです。データラインを調べると、データセットは実行するすべてのコードを表示します。これには、保存された変換の上流にある未保存の変換のコードが含まれます。
例えば、このワークブックには未保存の変換と保存された変換が1つずつ含まれています。
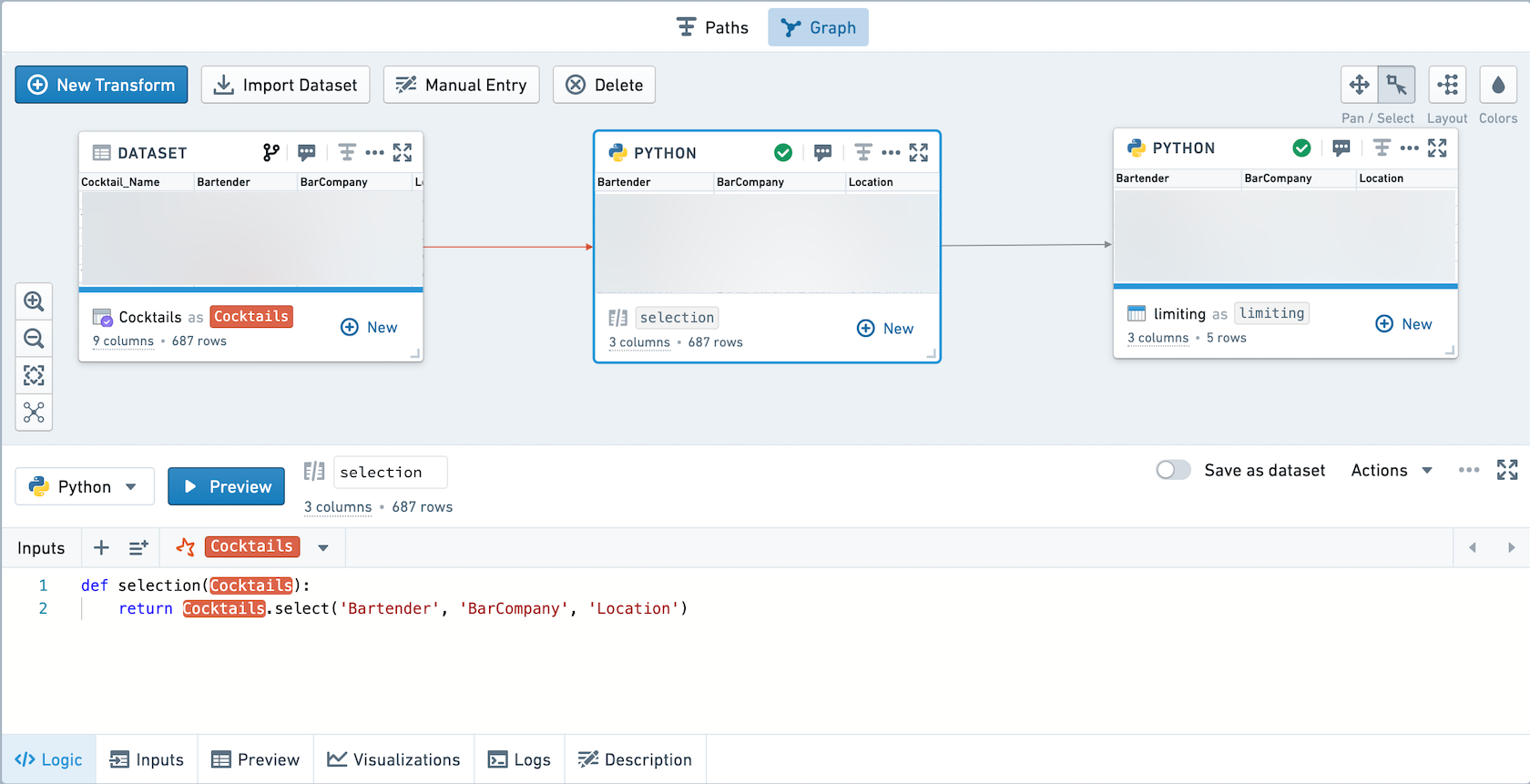
データラインの調査をクリックすると、以下のように表示されます。selection変換のコードが limiting変換のコードの前に追加されていることに注意してください。
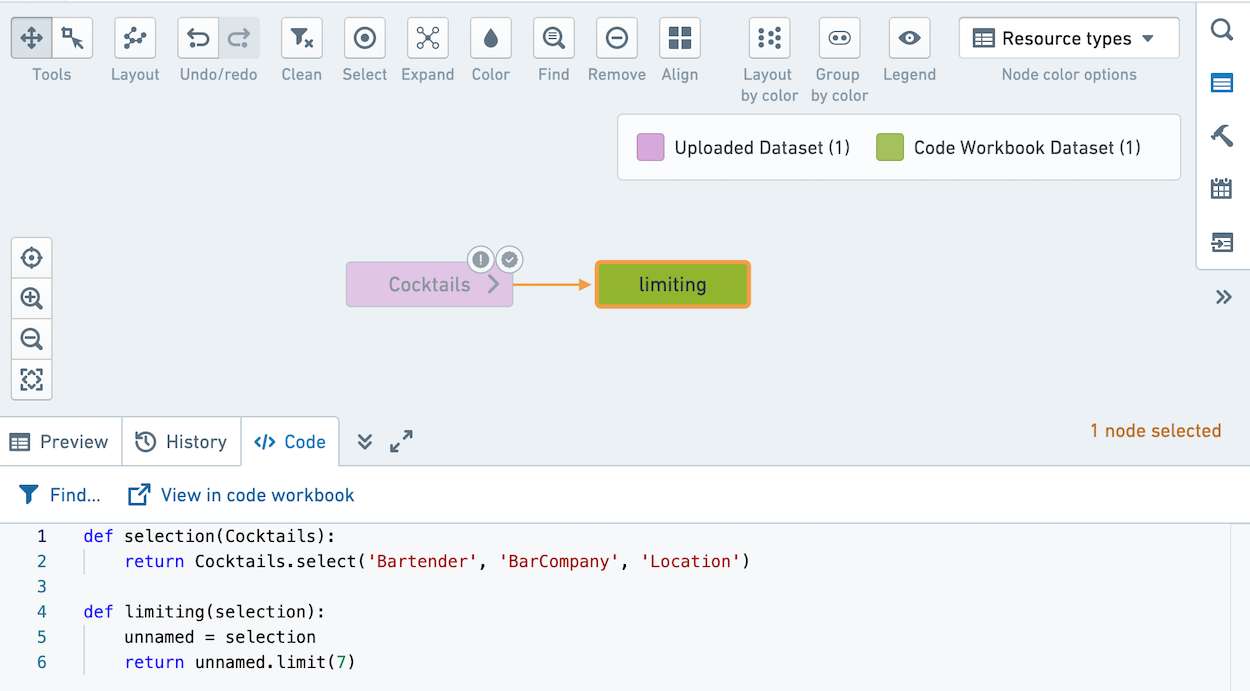
オプションのデータ永続化がパフォーマンスとリソース使用に与える影響は何ですか?
Code Workbook は最初、各変換が Foundry データセットとして保存される実行モデルを使用していました。現在の実行モデルでは、ユーザーが変換をデータセットとして保存するかどうかを選択でき、パフォーマンスとリソース使用に影響があります。
スケジュールされたビルド
以前の実行モデルでスケジュールされたビルドが実行されていたと想像してみてください。新しい実行モデルでは、すべての変換が永続化されたままであれば、パフォーマンスは以前と同じままです。
中間の変換の一部が Foundry データセットとして保存する必要がないと判断し、それらを永続化しない選択をした場合、パイプラインの速度に厳密なパフォーマンス向上があります。これは、これらのノードの中間結果が Foundry に書き込まれなくなり、場合によっては Spark クエリプランナが下流の計算をさらに最適化するのに役立つからです。
対話型の使用
対話型のケースでは、古い実行モデルではプレビュー結果と書き込み結果の両方が計算されました。オプションの永続化では、永続化されていないノードはプレビューのみを計算し、永続化されたノードは書き込みのみを計算します。したがって、重複する作業は行われず、同一のワークブックを実行すると、新しい実行モデルでは以前の実行モデルよりもリソースが少なくなります。
対話型のケースでオプションの永続化がパフォーマンスに与える影響は、より微妙です。非常に計算量が多い変換(例えば、大規模な結合)を持つワークフローでは、下流の変換を実行するたびに大規模な結合を再計算するのを避けるために、結合を永続化することを検討してください。
すべてのケースで、変換の永続化を解除することを決定すると、Foundry に書き込まないことでストレージスペースが節約されます。