注: 以下の翻訳の正確性は検証されていません。AIPを利用して英語版の原文から機械的に翻訳されたものです。
はじめに
データセットの設定
このチュートリアルでは、Titanic の乗客に関する情報を含む公開データセット(titanic_dataset.csv をダウンロード)を使用します。
このデータセットには、Titanic の乗客の名前、年齢、性別などの識別情報が含まれています。Foundry に移動し、ユーザーのパーソナルプロジェクトを開きます。Code Workbook Tutorial という名前のフォルダーを作成し、そこに Titanic のデータセットをアップロードして titanic_dataset と命名します。
Code Workbook の設定
プロジェクトで 新規 ボタンをクリックし、Code Workbook を選択して新しい Workbook を作成します。
データセットのインポート
データセットをインポート をクリックして開始します。表示されるダイアログで titanic_dataset を検索します。セットアッププロセス中に作成したファイルを選択し、そのファイルは /user/Code Workbook Tutorial/titanic_dataset にあるはずです。
目的のデータセットを特定したら、ファイルをクリックし、選択をクリックしてデータセットをグラフに追加します。
Python を使用したデータの変換
titanic_dataset がワークブックにインポートされたので、コードと再利用可能なロジックの断片を使用して変換できます。titanic_dataset にマウスカーソルを合わせて + サインをクリックし、下流の変換を追加します。これにより、さまざまな変換オプションを示すドロップダウンが表示されます。Python を選択します。
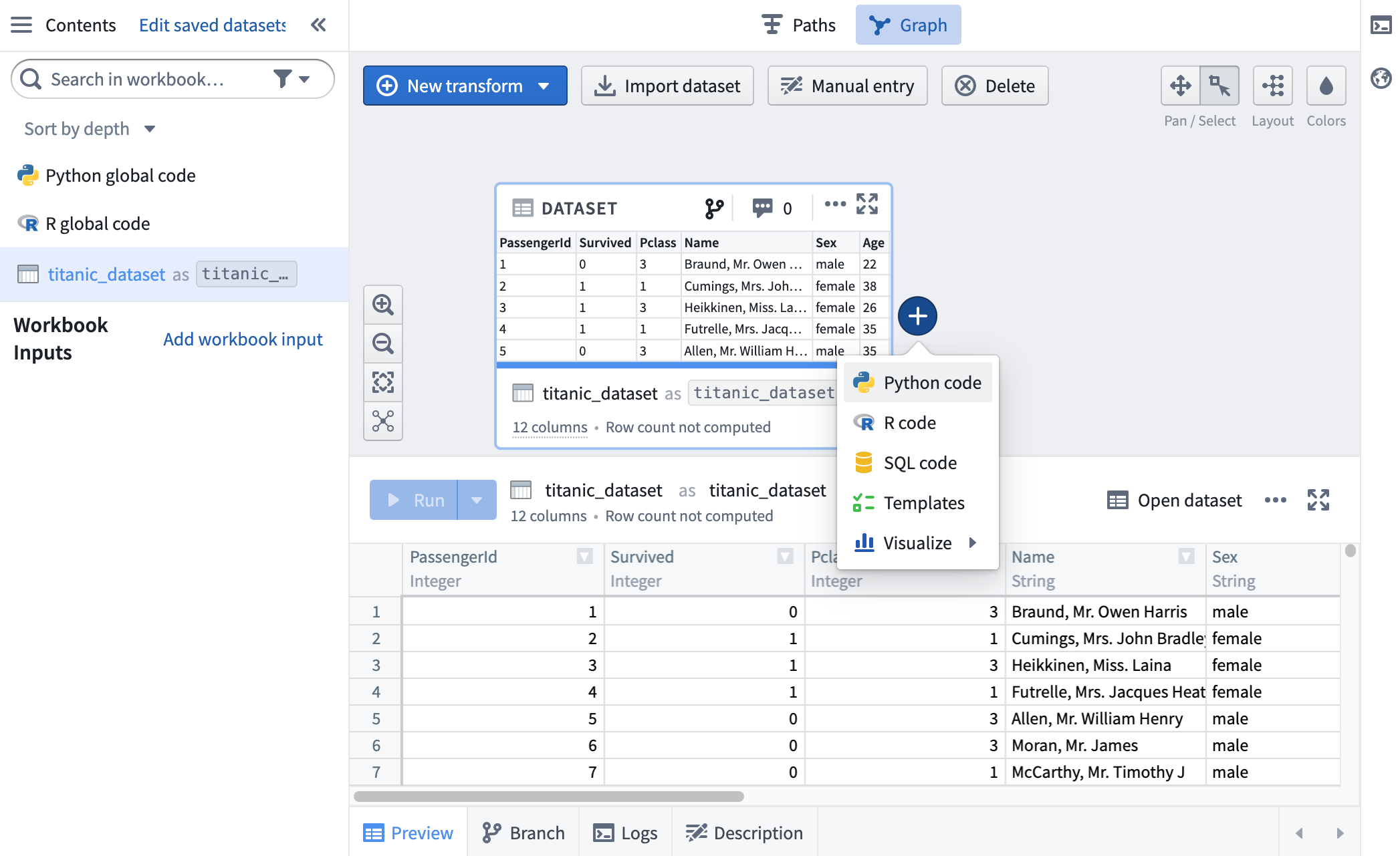
Python のコードノードがグラフに表示され、接続線が titanic_dataset の子であることを示しています。ロジックタブの上部のテキストボックスにクリックして、この変換に titanic_filtered というエイリアスを付けます。
デフォルトでは、新しく作成された変換は Foundry のデータセットとして保存されません。データセットとして保存 のトグルをクリックすることで、変換の結果をデータセットとして保存することを選択できます。変換をデータセットとして保存について詳しく学ぶ 変換がデータセットとして保存されると、エイリアスと Foundry データセットの名前の 2 つの名前があります。
Pandas データフレームの使用
Pandas の構文に慣れている場合は、Python ノードで Pandas を使用できます。Pandas を使用して titanic_filtered を更新しましょう。
まず、titanic_dataset の入力タイプを変更する必要があります。ロジックパネルの Inputs タブにクリックして移動し、サイドバーを展開します。入力タイプが Spark データフレームと設定されていることがわかります。ドロップダウンをクリックして Pandas データフレームを選択し、titanic_dataset の入力タイプを Pandas データフレームに変更します。
次に、Pandas データフレームで動作するようにコードを更新しましょう。同じフィルター処理を行います。
Copied!1 2 3 4 5 6# Titanicデータセットの関数をフィルタリングします def titanic_filtered(titanic_dataset): # 'Survived'の値が1で、かつ'Sex'が'female'の行だけを取り出します output_df = titanic_dataset[(titanic_dataset['Survived'] == 1) & (titanic_dataset['Sex'] == 'female')] # フィルタリングされたデータフレームを返します return output_df
このコードは、タイタニック号の女性生存者を含む Pandas データフレームを出力します。
コンソールの使用
コンソールは、Code Workbook 用の REPL(Read-Evaluate-Print Loop)を提供し、グラフ上の任意のトランスフォームや入力データセットを迅速に、アドホックに分析できます。ワークブックで有効になっている言語ごとにコンソールがあるため、好みの言語で素早く反復できます。
コンソールを開き、ページの右側にあります。Python コンソールを選択します。
Python のコマンドを実行して、データを素早く試すことができます。また、トランスフォームからコンソールで実行するコードを送信するには、コードをハイライトしてキーボードショートカット Cmd+Shift+Enter(macOS)またはCtrl+Shift+Enter(Windows)を使用します。
まず、Python コンソールで以下の PySpark SQL 関数をインポートする必要があります。
Copied!1 2# pyspark.sql.functionsをFという名前でインポートします import pyspark.sql.functions as F
次に、タイタニック号の女性生存者の最高年齢を決定します:
Copied!1 2# タイタニックデータセットから、最大の年齢を選択し表示します titanic_filtered.select(F.max('Age')).show()
SQL コンソールを使用して同じ統計量を計算することもできます:
Copied!1 2-- titanic_filteredテーブルから最大の年齢(Age)を選択し、それをmax_ageとして表示します。 SELECT max(Age) AS max_age FROM titanic_filtered