- Capabilities
- Getting started
- Architecture center
- Platform updates
Foundry SAP sync
A new sync configuration should be created for each SAP object (such as a table, a view, and so on) to be extracted to Foundry.
The Data Connection documentation contains step-by-step instructions for how to create a new sync.
To configure a sync for the Palantir Foundry Connector 2.0 for SAP Applications ("Connector"):
-
Configure the standard settings as you would for any other sync (name, target dataset and schedule).
-
Set Transaction type to APPEND for incremental updates or SNAPSHOT for a full load. For further details about incremental updates, review Incremental Updates.
-
Select an SAP Object Type from the following options:
- ERP Table – for a standard SAP ERP table
- BW InfoProvider – for a BW InfoProvider (which covers InfoCubes, DataStore objects, InfoObjects)
- BW BEx Query – for a BW BEx query
- SLT – to extract data from an SAP Landscape Transformation Replication Server
- BW Content Extractor – for an ERP Business Content extractor
- Function – to run a BAPI function
- ERP Table Data Model – for details of the relationships between tables
- Remote ERP Table – for a standard SAP table in a remote system
- Remote BW InfoProvider – for a BW InfoProvider in a remote system
- Remote BW BEx Query – for a BW BEx query in a remote system
- Remote Function – to run a BAPI function in a remote system
Further details are available in SAP Object Types.
-
If you are using SLT or connecting to a remote system, you will also be asked to select a Context. For more details on contexts, see Install a Remote Agent.
-
Next, enter the Object Name – once you start typing in this field, you will be presented with a list of suggestions based on the SAP Object Type (and Context if used).
-
If you are configuring an incremental update, you will need to provide an Incremental Field. Review the section on this setting below for more details.
-
Optionally, you may specify additional parameters (see full details below) by clicking on the Extras tab.
For full details on configuring a sync with SLT, see Configure SAP SLT.
Incremental type
Learn more about incremental updates.
Filter
The filter setting is used to filter the data being extracted from SAP.
The following operators are supported in the filter syntax:
- Comma (
,) means "or" - Semicolon (
;) means "and" - Colon (
:) means "between" - Equals (
=) means "equals" - Exclamation mark and equals (
!=) means “not equals” - Greater than (
>), greater than or equal to (>=), less than (<) or Less than or equal to (<=) are supported.
All field names should be the same as in the data dictionary.
Examples:
-
by price between 500 and 650
PRICE=500:650 -
by CUSTOMER A,B or C
CUSTOMER=A,B,C -
by price between 500 and 650 and CUSTOMER A,B or C
PRICE=500:650;CUSTOMER=A,B,C -
by a material starting with
PAL,DISandSAP, use the following filter with wildcardsMATERIAL=PAL*,DIS*,SAP* -
by a date column which is greater than or equal to 09.08.2019
DATE>=20190809
Note that date format in SAP's DB is YYYYMMDD.
Drop columns
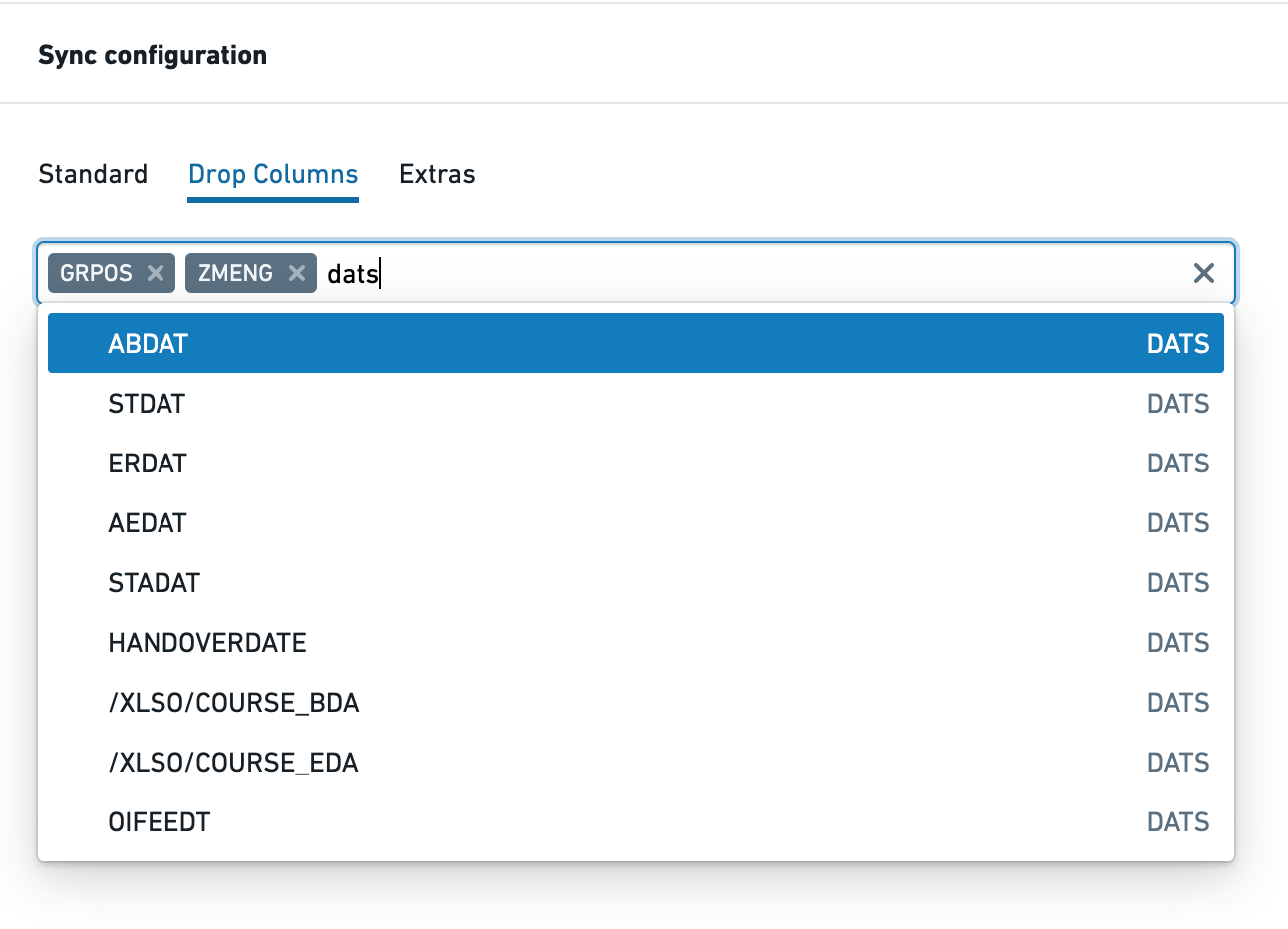
Drop Columns is only supported for the Table and Remote Table object types, and allows you to drop columns before data is extracted from SAP. All fields in the schema for the given table are listed in a multi-select box. You can search on either the field name or type (as shown in this example with "dats").
This feature can be used if you have fields containing sensitive data in SAP or to avoid importing data that is not required in Foundry. Performance will be considerably better than using the column masking / hashing / encryption functionality.
Timestamp
When Timestamp is set to On, the data will include a timestamp showing when the data was fetched and a row order number. This information can be used to deduplicate data from SAP later in the pipeline if required.
- The maximum value of
/PALANTIR/ROWNOfor the maximum value of/PALANTIR/TIMESTAMPfor any given primary key is guaranteed to be the latest version of that record in SAP - The
/PALANTIR/TIMESTAMPcolumn indicates the time at which the data sync ran (not the time at which the update happened in the SAP system) - The
/PALANTIR/ROWNOcolumn tracks the order in which records within a given data sync are returned from SAP- This value is only relevant when using either the SLT Replication Server for trigger-based change data capture (CDC) or when using the CDPOS or CDHDR incremental mode
- In those cases, a single data sync will contain all the changes to a record that have taken place since the last data sync; the higher the value of
/PALANTIR/ROWNO, the more recent the change
Param name
A function can return multiple tables. This parameter is used to determine which table to select and write to the Foundry dataset.
Depth
When SAP Type is Data Model, this setting is used to define how many links to follow when finding table relationships. Set to 1 for only first-order relationships, 2 for second-order, etc.
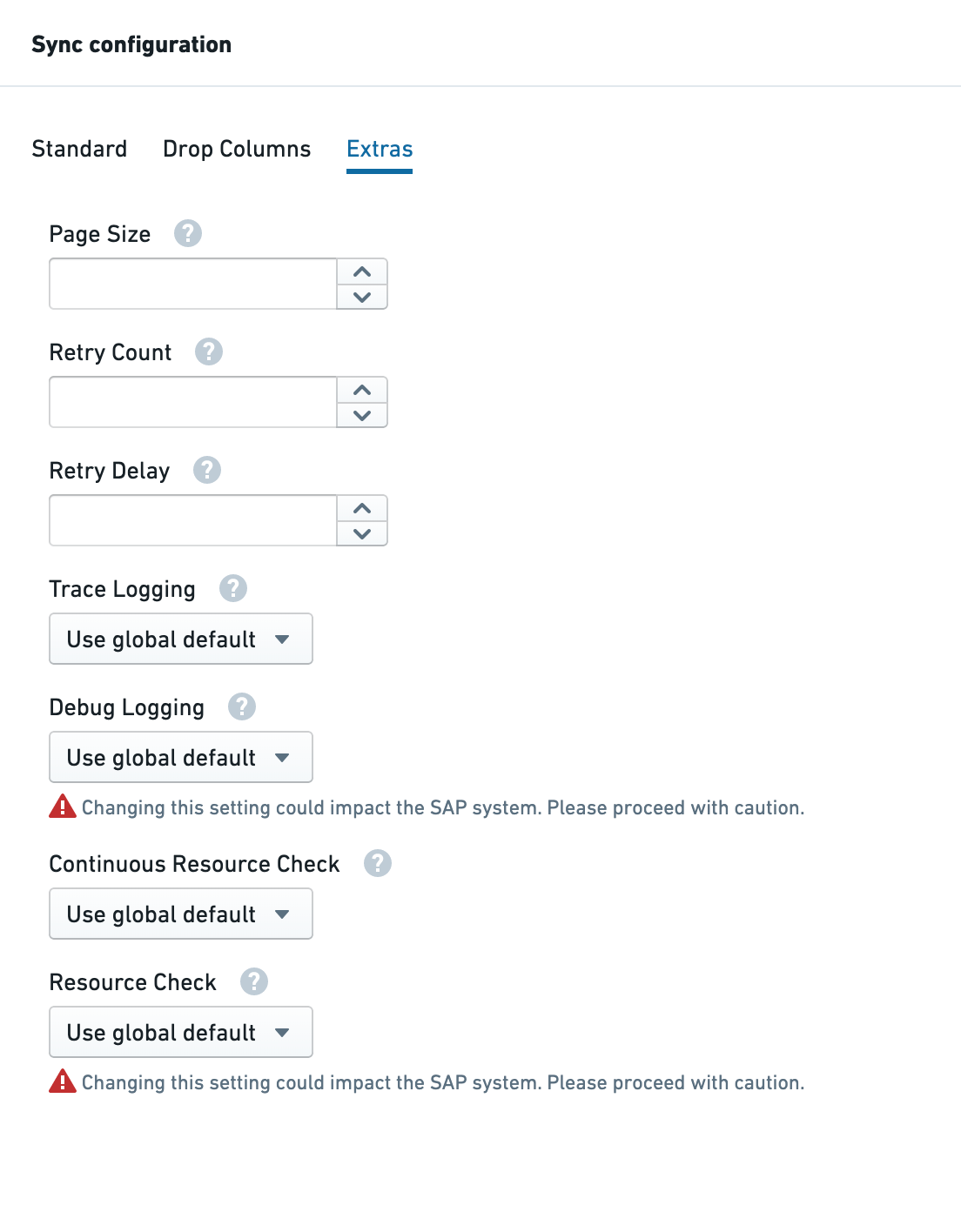
Page size
Sets the number of rows to return per page when retrieving data from the SAP system. Note that the system default for this setting is 50,000 rows and changes made here will only be applied if they are above that value. If you wish to set a lower system default, you will need to make a system call to do so.
Retry count
Number of retries to attempt when request fails due to a resource shortage.
Retry delay
Delay (in seconds) between two retry attempts.
Trace logging
Set to On to turn on trace logging for this sync.
Debug logging
Turning on debug logging starts a background process in the SAP system that will run for the duration of the sync, to be used for live-debugging complex issues. This process could drain resources and impact users of the system so proceed with caution.
Set to On to turn on debug logging for this sync.
Continuous resource check
When On, all paging requests are subject to a resource check (memory, CPU, etc); when Off, only the initial page request is subject to a resource check. See performance parameters for more details.
Resource check
Turning off the resource check setting causes the sync to run irrespective of whether the available memory, CPU and processes meet the configured thresholds. This could mean that the sync puts excess load on the SAP system, impacting users and other processes. Proceed with caution.
Set to Off to turn off all resource checks (memory, CPU, processes) for this sync. See performance parameters for more details.
Fetch Option (SLT Only)
When Fetch Option is set to XML, the connector will fetch data from SLT using zipped data fetch. When it is Direct, it will fetch data from SLT as a string. The XML data fetch option is faster than the Direct method. You should use the XML option unless you encounter an error relating to data content while fetching data.
maxRowsPerSync (SLT Only)
When set, the connector will return approximately maxRowsPerSync (could be slightly above or below) rows for each sync run from Foundry. This allows you to divide the initial sync of a very large table (or indeed subsequent deltas if those also contain many rows) into a series of smaller syncs. Useful if intermittent issues are killing long syncs because you can recover from the last successful sync without having to re-ingest the whole table.
To enable this setting, you will need to toggle from the Basic view of the Sync configuration to Advanced.
Copied!1maxRowsPerSync: 500000
BEx Settings (BEx Only)
As of the Connector version SP22 and Magritte Plugin 0.11.0, the following BEx Query parameters enable BEx paging support.
bexPaging: Turns on paging for BEx queries (supported via filters). The SAP add-on automatically generates separate filters for each page. This means large BEx queries can be run without having to split the sync manually. The default value (defined in the SAP add-on) if this is not set is false.
bexMemberLimit: The Connector uses a threshold to prevent unnecessary dimensions being used as filter candidates. If the posted value for an InfoObject is more than bexMemberLimit, it is considered too fine-grained and discarded for filter generation. The default value (defined in the SAP add-on) if this is not set is 200. The value cannot be lower than 2.
To enable this setting, you will need to toggle from the Basic view of the Sync configuration to Advanced.
Copied!1 2 3bexSettings: bexPaging: true bexMemberLimit: 10
Ignore unexpected values
You may encounter an error of the following form when running a sync:
Unexpected value encountered in SAP data Failed to parse value XXX in field YYY
This can occur if a date or number value is malformed and cannot be parsed. Ideally, this should be resolved by correcting the problem in the source system; if this resolution is not an option and you would still like to run the sync, you can ignore unexpected values.
To enable this setting, you will need to toggle from the Basic view of the Sync configuration to Advanced. (Note that once you have added this setting, you will not be able to return to the Basic view.) In the Advanced view, add the following line to the sync YAML definition:
Copied!1ignoreUnexpectedValues: true
This will ignore date and number parsing exceptions. Values that fail to be parsed will be set to null and a warning will be logged at the end of the sync with a summary of the parse exceptions found.
Configure the maximum size of each Parquet file
The maximum file size of each Parquet file in Foundry datasets can be defined on the Source, for all syncs, and on the Sync, for the specific sync.
If you would like to change the maximum size of each Parquet file for a specific sync use the outputSettingsOverride parameter.
Copied!1 2 3 4 5outputSettingsOverride: maxFileSize: type: rows rows: max: 10000
Copied!1 2 3 4 5outputSettingsOverride: maxFileSize: type: bytes bytes: approximateMax: 400MB
- Specifying the maximum size in bytes is only approximate. The resulting file sizes might be slightly smaller or larger.
- If specifying a maximum size in bytes, the number of bytes needs to be at least twice as large as the in-memory buffer size of the Parquet writer (which defaults to 128 MB).