- Capabilities
- Getting started
- Architecture center
- Platform updates
Incremental updates
Incremental syncs are stateful syncs which enable append-style transactions from the same table. The following types of incremental syncs are offered:
- Single field: Import rows when a single field in the target table/object is greater than or equal to the largest value already imported.
- Multiple fields: Similar to Single field but supports combining multiple fields with an OR operator; can be used, for example, when both "created" and "last updated" timestamp fields exist in a table.
- Concatenate fields: Similar to Multiple fields but instead of combining fields with an OR operator, fields are concatenated together; can be used, for example, when there are separate "last updated date" and "last updated time fields" in a table.
- Use change document table: Import new rows based on updates in SAP's change document table.
- Use twin or twinjoin table: Import new rows from the target table when a field in a "twin" table is greater than or equal to the largest value already imported. A Twinjoin table allows setting the target table to be a join of multiple tables.
The table below indicates which incremental types are supported by which SAP object types.
| Object Type | Single field | Multiple fields | Concatenate fields | Use change document table | Use twin table | SAP built-in | Replication | Request Based | Combo |
|---|---|---|---|---|---|---|---|---|---|
| Table | X | X | X | X | X | X | |||
| Remote Table | X | X | X | X | X | X | |||
| InfoProvider | X | X | X | ||||||
| Remote InfoProvider | X | X | X | ||||||
| SLT | X | ||||||||
| Extractor | X |
The Incremental Field property in a sync definition is used to manage incremental updates. After an initial bulk extract, only rows which have changed are extracted for each incremental update. When using the Multiple fields type, the list of fields should be separated with a comma.
To enable incremental update functionality, set Transaction type to APPEND.
Ideally, the incremental field provided should be a monotonically increasing value; however, it is not always possible to find such a field. The best option may be a date field (with no time component). For this reason, the system uses a "greater than or equal to" comparison (as opposed to just "greater than") so that no data is omitted if the previous sync was run midway through a given date.
As a result of the "greater than or equal to" comparison, it is possible that duplicate values may appear in the resultant dataset in Foundry. These duplicate values should be removed as a first step in the data transformation pipeline in Foundry (for example, by checking for duplicate rows by primary key).
Incremental updates are not supported for BEx Queries or Functions; all syncs will be a full extract.
For more details on incremental updates for SLT, refer to the documentation on configuring SLT.
Use change document table
This feature works by referencing two SAP change document tables: CDHDR and CDPOS. This approach could be useful if the table you are ingesting lacks any obvious updated timestamp fields or otherwise monotonically increasing values, such as a unique row ID.
Note that for some SAP objects, changes to rows are included in the change document tables but inserts may not be present. Thus, we recommend proceeding with caution and testing this feature thoroughly to achieve the expected results for your specific use case.
Use twin table
This feature allows you to specify a field / multiple fields for incremental updates in a different table than the one that you are importing to Foundry. This could be helpful if, for example, the primary table you are importing is an item table that lacks a suitable updated timestamp field but has a header table in which such a field does exist (and that field is updated when changes occur in the item table).
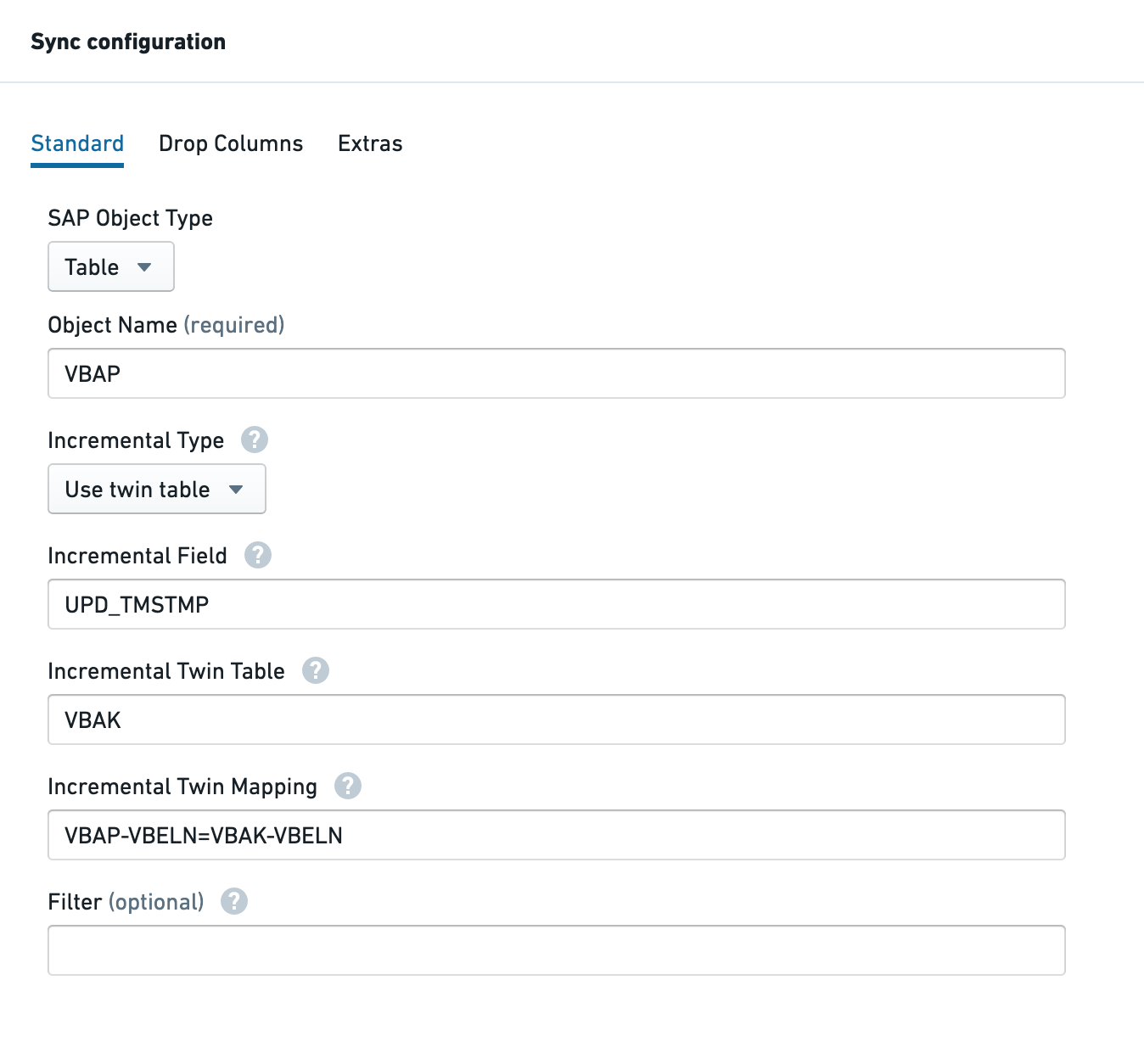
In this example, after a successful initial load, subsequent requests will only extract rows of data from VBAP where the UPD_TMSTMP field in VBAK (the header table) is greater than or equal to the highest UPD_TMSTMP value from the last successful sync.
The Incremental Twin Table setting is used to indicate the twin table to use.
The Incremental Twin Mapping setting is used to define the join conditions between the primary table and the twin table. Syntax is as follows:
{PRIMARY_TABLE_NAME}-{FIELD_NAME}={TWIN_TABLE_NAME}-{FIELD_NAME}
Multiple join conditions can be applied using a semicolon (which represents the AND operator).
Request-based incremental for InfoProviders
In SAP BW, DSOs and InfoCubes are loaded by using Data Transfer Processes (DTPs). Each DTP creates a loading request and the Palantir Foundry Connector 2.0 for SAP Applications now uses these requests to capture the changed data.
This feature is only supported for non-compressed requests. If the data is transferred to Foundry, then the requests can be compressed. If the request is compressed before loading to Foundry, the data sync will fail and initial loading must be repeated.
A sample configuration for request-based incremental ingestion (note that you will need to toggle from the Basic view of the Sync configuration to Advanced):
Copied!1 2 3 4type: magritte-sap-source-adapter sapType: infoprovider obj: <technical-name-of-infoprovider> incrementalType: REQUEST
Reset incremental state
To re-initialize incremental ingests by forcing an initial load, follow these steps:
- Switch to the Advanced tab in the sync config.
- Add
resetIncrementalState: trueto the YAML config. - Toggle the transaction type to
SNAPSHOT(ensure that anyincremental*parameters remain set). - Run the sync; this will perform a full snapshot of the data from SAP, replacing all files in the dataset.
- Remove
resetIncrementalState: truein the YAML config. - Toggle back transaction type to
APPEND.
When the next syncs run, incremental appends will occur as normal.