- Capabilities
- Getting started
- Architecture center
- Platform updates
Create a simple preparation
Preparation has been superseded by Pipeline Builder and is therefore no longer the recommended approach for cleaning and preparing data. Pipeline Builder makes it easy to clean and prepare your data for pipelines, while also offering Marketplace support.
The following tutorial will walk you through how to use Preparation to transform a spreadsheet of raw data to a cleaned and prepared dataset ready for analysis.
This tutorial uses data from The Meteoritical Society via the NASA Data Portal ↗. You can follow along on your own Preparation instance with this sample dataset:
Download meteorite_landings_raw
This dataset contains raw data about meteorites that have been found on Earth.
The dataset includes name, mass, classification, and other identifying information for each meteorite, along with the year it was discovered and coordinates of where it was found.
We recommend opening the CSV to review the data before uploading into Foundry.
1. Create a preparation
We will get started by creating a new preparation.
-
First, upload the
meteorite_landings_raw.csvfile into Foundry. -
Then, navigate to the
meteorite_landings_rawdataset, right-click, and choose Clean in Preparation.
This creates a new preparation. You should save your preparation with a meaningful name to make it easier to find again in your files.
- Finally, click Save and choose a name and save location for the preparation.
Preparations that you create and do not explicitly save are stored by default in Files > .auto-save.
2. Clean data
Now, review the dataset and identify and fix any data quality issues you find.
Trim whitespace
- First, click on the name column in the table:
The panels below will show some information about the data in the column: statistics, charts, etc:
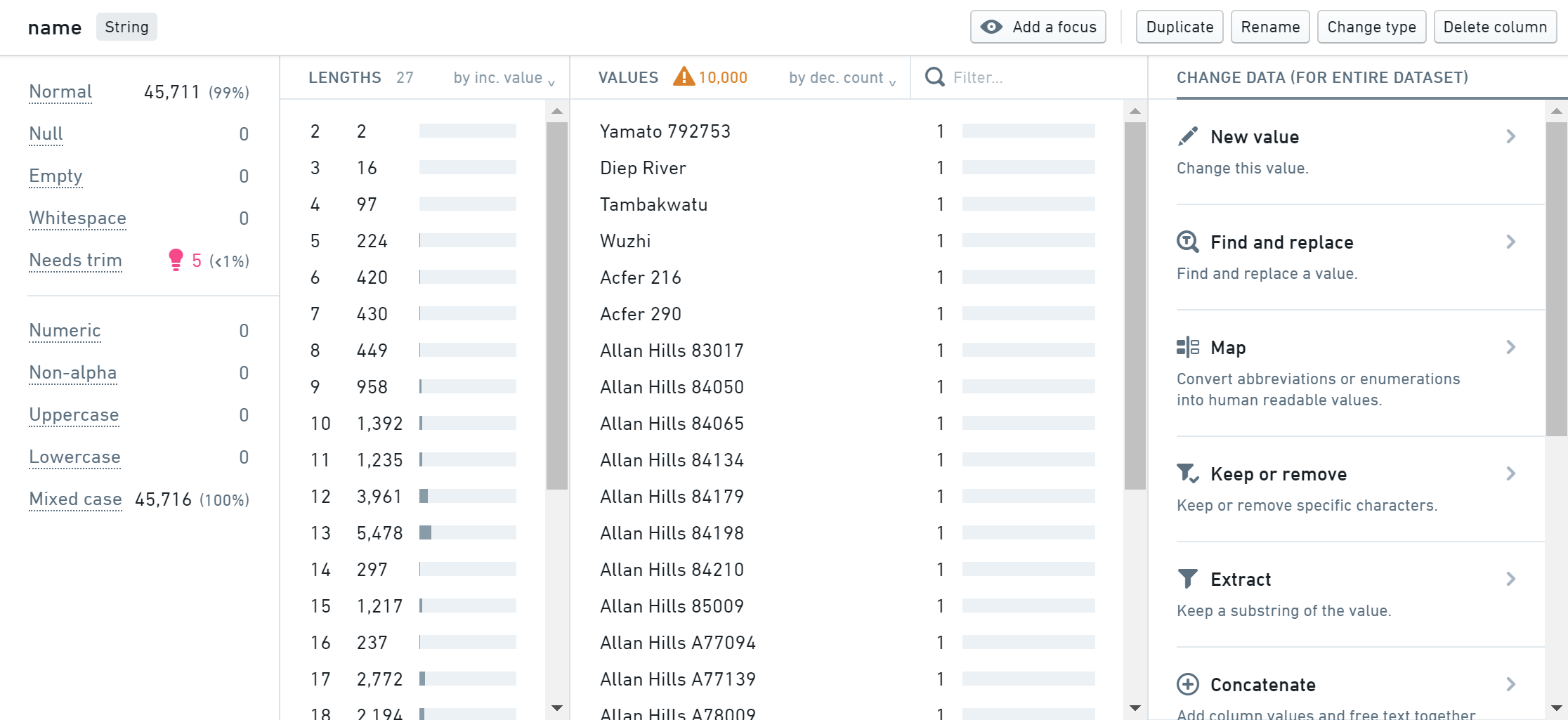
You can see from the statistics panel that some of the values have been flagged as Needs trim, which means that there is extraneous whitespace at the beginning or end of the value.
- Hover over the pink lightbulb, and click the Trim whitespace button to fix this issue.

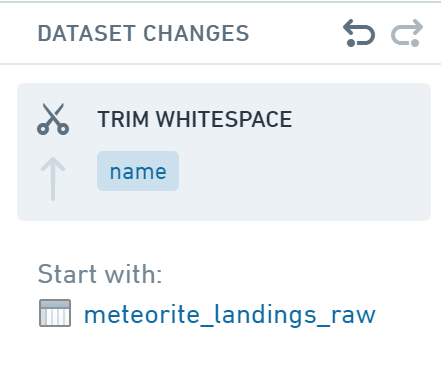
After the column statistics refresh, you should now see that the Needs trim count is now zero, and the column has been cleaned successfully. You will also see the Trim whitespace change added to the Dataset Changes list on the right side of the screen:
Transform year column to a date
Now, let's move on to the year column. You can see in the table that the data type of the column is Timestamp. However, we want it to just be a Date.
-
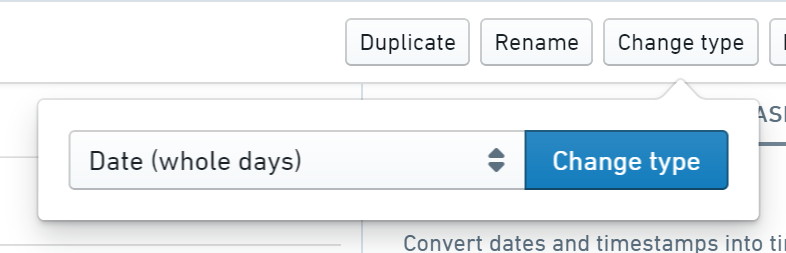
First, click the Change type button and choose Date (whole days) from the dropdown list.
-
Click the Change type button.
Set geolocation values to null
Finally, let's look at the GeoLocation column. You will see in the histogram that a large number of rows have a value of (0.000000,0.000000), which is not a valid geolocation.
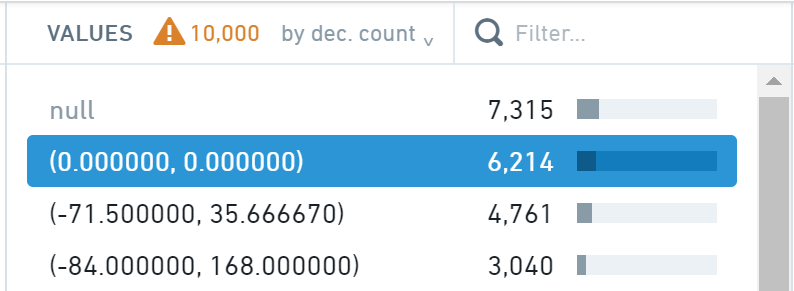
Let's fix these values by setting them to null.
- First, select the (0.000000, 0.000000) value in the histogram.
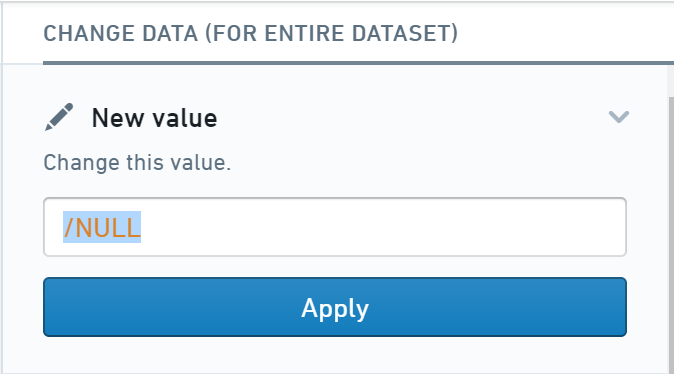
- Next, click the New value action under Change data (for selected rows).
- Finally, enter
/NULLin the text box, and click Apply to set these values tonull.
3. Save a cleaned version of a dataset
Now that we have cleaned up data quality issues, we can save a new, cleaned version of this dataset.
- First, click the Save as dataset button at the top of the screen.
- Then, choose a name and location for the new cleaned dataset. A pop-up will appear indicating that the new dataset is being built.

There will be a link to the new dataset indicated by Output:. As you make changes to the preparation, you can update the output dataset using the Update button.
To try out the results of your cleaning in Contour without having to save a new dataset, click the Analyze button at the top of the screen.