- Capabilities
- Getting started
- Architecture center
- Platform updates
Joins in streaming Pipeline Builder pipelines
With Pipeline Builder for streaming, you can join your streams against both batch datasets and other streams. Given the low latency nature of streaming, the way joins are implemented differs from how they work in standard batch pipelines. This page explains how joins work and how best to leverage them in your pipelines.
Join streams with batch datasets
Foundry allows you to combine low latency streams with batch datasets in a manner similar to how you can join two batch datasets in a batch Pipeline Builder pipeline.
Complete the following steps to join a stream with a batch dataset in Pipeline Builder:
-
Add the stream and the batch dataset to your Pipeline Builder graph.
-
Under the batch dataset, select the dropdown menu and change the type to Snapshot.
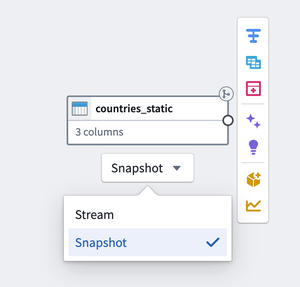
-
Select the stream against which you want to join.
-
Select Join, and select batch dataset for the right side of the join.
-
Under Join Type, select Left Lookup Join.
-
Enter the match conditions.
Architecture
Streaming joins against batch datasets work by initially downloading the batch dataset and indexing it in the streaming cluster to allow for low latency lookups. To make the join low-latency, transforms on the batch dataset are not permitted in the same Pipeline Builder pipeline before the join with the stream.
The batch dataset is updated when new transactions are written to the dataset. When a new transaction is added to the batch dataset, a background process will download the new view of the data and convert it into a queryable format. Once that process is complete, the stream will start joining against that new view of the batch dataset.
Limitations
You cannot transform the batch dataset before joining it against a stream. If you need to transform the batch dataset, you can do so in an upstream Pipeline Builder pipeline.
Consider the following limitations for streaming joins:
- The left side of the join must be either a stream or a batch dataset with "Stream" read mode when joining against a batch dataset.
- Performance may degrade if you join against batch datasets with more than 8-10GB of data.
- The batch dataset will update at most once every five minutes if a new append transaction is detected.
- Joining against large static datasets can slow down cluster startup time.
Join streams with other streams
Foundry allows you to combine multiple low latency streams, similar to how you can join multiple batch datasets in a batch Pipeline Builder pipeline.
Complete the following steps to join two streams in Pipeline Builder:
- Add the two streams to your Pipeline Builder graph.
- Select Join, and select the two streams.
- Under Join Type, select Outer Caching Join.
- Enter the match conditions.
- Specify the cache time values and units. The cache time values and units control how long data is stored in the cache we use to join the two streams.
If you want a left or right join instead of an outer join, you can filter out records that have null values downstream of the join. For a right join, filter where the right side values are null; for a left join, filter where the right side values are null.
Architecture
Since streams run indefinitely and new records are constantly flowing into both sides of the join, joins between two streams operate on caches of data from each side of the join instead of joining against the entire stream.
Joins between multiple streams are limited to operate on a cache of data to prevent unbounded state growth, which would cause the streaming cluster to eventually run out of memory and crash. By setting expiration times for the caches on the left and right side of the join, the state required to store the records for the join is bounded; this prevents the streaming cluster from running out of memory.
Data is stored on a per-key basis and distributed across task managers to allow for larger joins. This means that to join against larger streams, you can increase the memory per task manager or increase the number of task managers the cluster is running with.
Records from the left side of the stream will always be joined against the most recent record of the right side, based on the key column specified in the join. Only the most recent record for a particular key will be joined.
Limitations
Consider the following limitations when joining streams with other streams:
- A cache expiration time is required for both the left and right side of the joins to prevent unbounded state growth.
- Only the most recent value per join key is stored for each side of the join. This means the join behaves like an "outer" join.
- If a record arrives in either the left or right stream before the other side of the join has a match, a record will be emitted with null values for the other side of the join.