- Capabilities
- Getting started
- Architecture center
- Platform updates
Transforms
Pipeline Builder provides a flexible, powerful, and easy-to-use interface for transforming your data in Foundry. Writing data transformations in existing tooling (for example, in Spark or SQL) can be challenging and error-prone, both for non-coders and experienced software developers. In addition, existing tooling is often coupled to one specific execution engine and requires using a code library to express data transformations.
Pipeline Builder uses a general model for describing data transformations. This backend is an intermediate layer between the tools used to write transformations and the execution of said transformations.
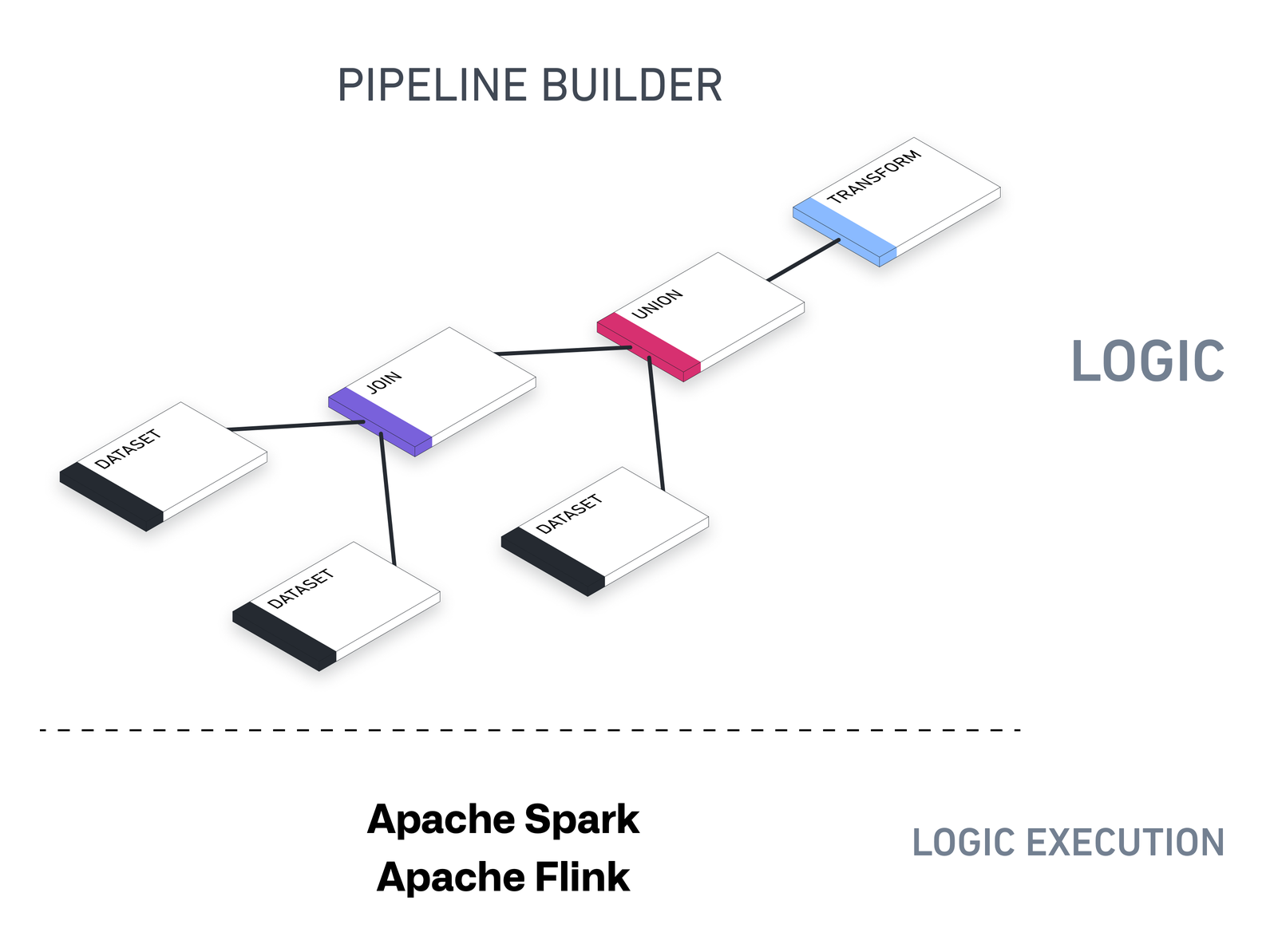
Pipeline Builder's underlying architecture is designed to support all kinds of outputs - datasets, ontological objects, streams, time-series, and exports to external systems. You can run batch pipelines for datasets, object types, link types, or streaming pipelines that correspond to streaming datasets.
Using transforms in Pipeline Builder
In Pipeline Builder, you can use two types of data transformations: expressions and transforms. Expressions take columns from a table as input and output a single column (for example Split string), while transforms take an entire table as input and return an entire table (for example, Pivot or Filter).
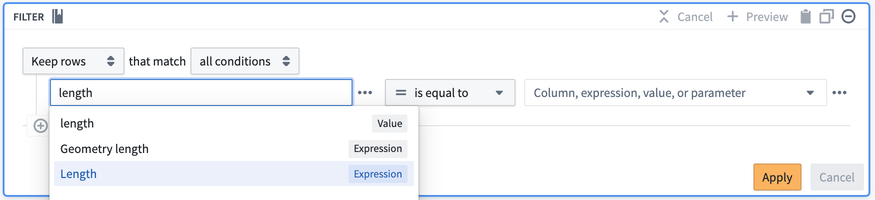
We group expressions and transforms together in the same configuration interface. For example, you can find the Drop columns transform alongside expressions like Cast and Concatenate strings. This allows you to use expressions and transforms together in the same path, and embed expressions within transforms in one configuration form, as shown by inserting the Length expression into the Filter transform below.
Other data structuring transforms, namely Join and Union, have their own configuration panes and are marked with unique icons in the Pipeline Builder interface.
For simplicity, we typically refer to all types of data transformations as transforms.
Join
A join combines two datasets that have at least one matching column. Depending on the type of join you configure, your join output can combine matching rows and exclude non-matching rows.
Union
A union combines two datasets to include all rows.
The union transform requires all inputs have the same schema. If input schemas do not all match, the union will display an error message with a list of missing columns.
User-defined functions
If you cannot manipulate your data with existing transformation options, or have complex logic that you want to reuse across pipelines, you can create a user-defined function (UDF). User-defined functions let you run custom code in Pipeline Builder that can be versioned and upgraded.
Note: We recommend using Python functions for the best experience. If you need access to specific Java libraries, Java UDFs are also available.
User-defined functions should only be used when necessary. We recommend using the optimized transform boards within Pipeline Builder when possible.
Next steps
Learn how to add a transform to your pipeline workflow.