- Capabilities
- Getting started
- Architecture center
- Platform updates
Pipeline Builder
Pipeline Builder is Foundry's primary application for data integration. You can use Pipeline Builder to build data integration pipelines that transform raw data sources into clean outputs ready for further analysis.
With Pipeline Builder and a robust backend model, users who code and users who do not code can collaborate jointly on a pipeline workflow. Pipeline Builder leverages both Spark and Flink as part of its architecture while incorporating a variety of advanced features supported by Palantir-developed custom libraries and services. Instead of writing code that requires lengthy health checks, Pipeline Builder integrates various programming languages beneath a streamlined builder point-and-click interface through which users apply data transforms without the need for specialized programming language knowledge.
Pipeline Builder uses a next-generation data transformation backend specifically designed to act as an intermediary between logic creation and execution. As users describe the pipeline they want to build, the backend writes transform code and performs checks on pipeline integrity, identifying refactoring errors and offering solutions to ensure a healthy build. With the backend acting as a middle layer between logic creation and execution, builders can solve schema problems before a pipeline is built and save time previously spent on computation and code checks.
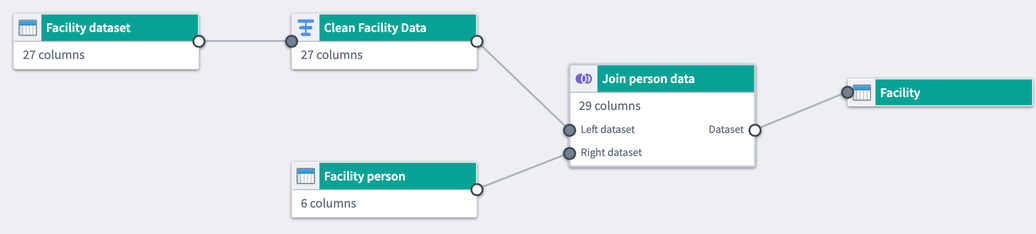
Features
Pipeline Builder includes features focusing on comprehensive pipeline creation, maintenance, and control.
- Intuitive user interface: Users write pipelines using graph and form-based interfaces that provide feedback, including join keys and column casting suggestions.
- Type-safe functions: Functions are strongly typed and can flag errors immediately instead of at build time.
- Strict output checks: If the expected output checks are not met, builds are prevented to avoid unintentional downstream breaks.
- Automatic build path pruning: Pipeline Builder will prune transform paths that are not connected to outputs to avoid unnecessary computation in builds.
- Abstract implementation details: Users focus on describing their end-to-end pipeline and desired outputs. Builds, syncs, and other orchestrations are handled automatically by the Pipeline Builder backend.
- Independent pipeline logic: Pipeline Builder can connect to different logic execution engines, including Spark, Flink, Azure instances, and more.
- Reusability: Pipeline logic can be easily extracted and reused for different pipelines.
- Full version control: Users can draft a pipeline separately, collaborate on one pipeline, or revert to previous versions.
- Media processing transformations: Users can pass media sets as transform inputs within their pipeline.
- Large Language Models (LLMs): Leverage the power of LLMs and AIP to transform your data.
- Geospatial transformations: Use Pipeline Builder to load, transform, and yield different forms of geospatial data.
- Streaming capability: Pipeline Builder offers the ability to write pipelines that execute with real-time latencies. This feature is not available on all Foundry environments. Contact your Palantir representative if your workflow requires the availability of streaming pipelines.
Workflow
Pipeline Builder follows a workflow comprising the following steps from importing data to delivering a healthy build.
- Inputs: Add a new data source or add additional datasets.
- Transform: Transform, join, or union data towards the desired output.
- Preview: After applying transformations, preview the output.
- Deliver: Once the pipeline is complete, build the pipeline outputs.
- Outputs: Add an object type, link type, or dataset output for your pipeline.
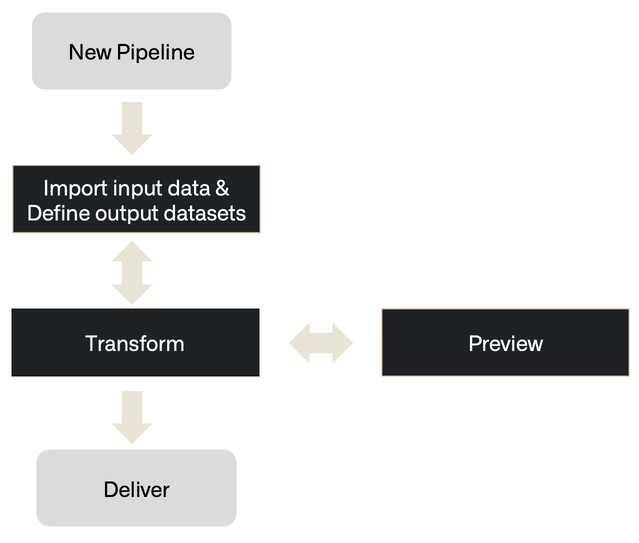
When visualized on a Pipeline Builder graph, this is how the steps might be demonstrated:
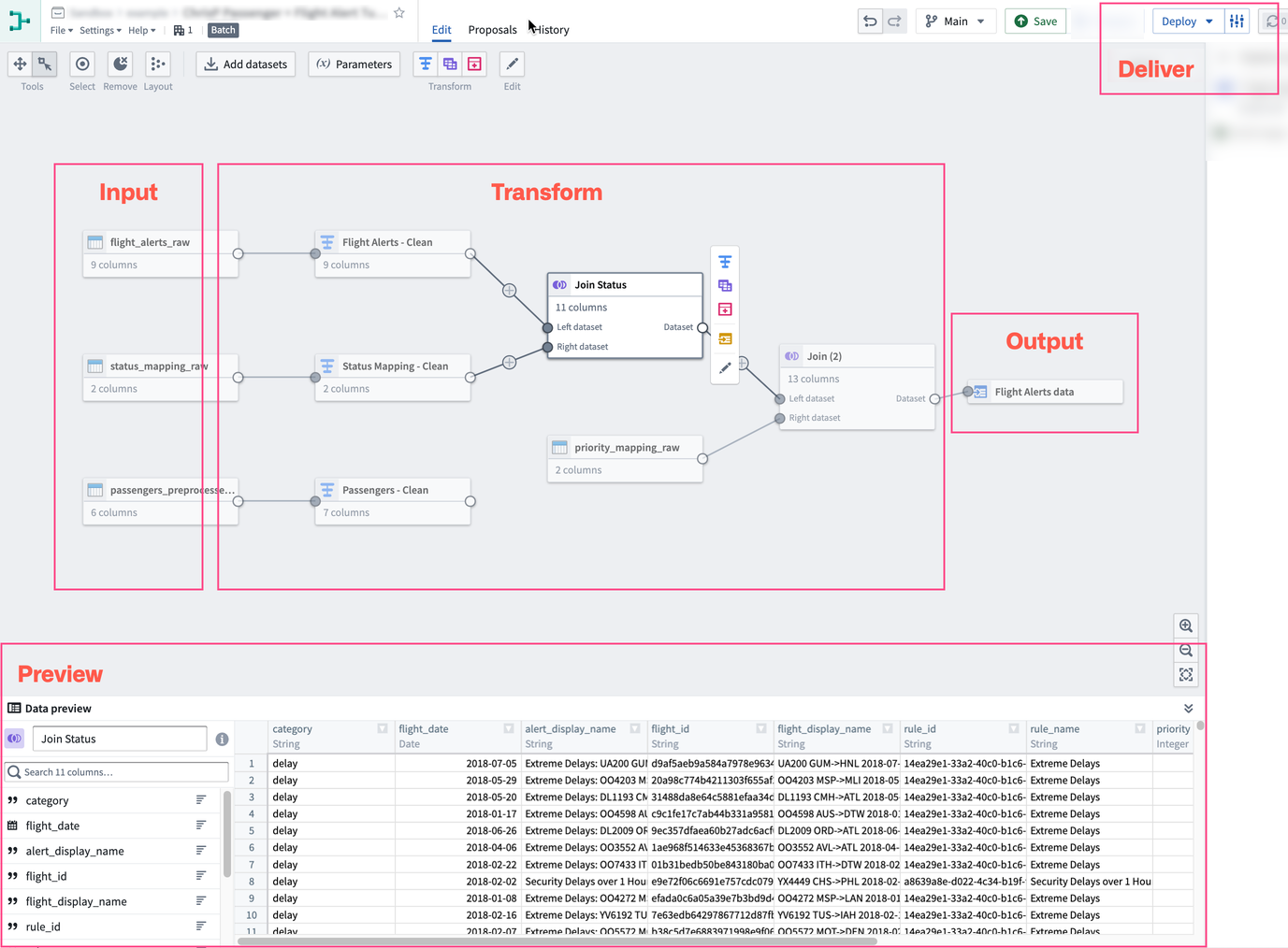
Learn how to create a simple batch pipeline, or learn more about the core concepts of building and managing pipelines in Pipeline Builder.
Try to build out your first pipeline in a course on learn.palantir.com ↗.