- Capabilities
- Getting started
- Architecture center
- Platform updates
Job groups
In Pipeline Builder, each successful deployment initiates a single build. By default, each batch pipeline output is built as its own job, and those jobs will succeed or fail independently. In streaming pipelines, all outputs are bundled into a single job running on a single Flink cluster, so all output streams will either succeed or fail together.
Job grouping in Pipeline Builder allows you to bundle outputs into one job in a batch pipeline, or split each output into its own job in a streaming pipeline. You can also specify compute profiles for each job grouping, providing granular control over how your outputs are built. The compute resources are shared across all outputs in the job group.
Grouping outputs into a single job is useful when you want output logic to update in parallel. In batch pipelines, outputs must be placed into the same job group to efficiently compute shared logic through checkpoints. Learn more about checkpoints in Pipeline Builder.
Dividing outputs into smaller groups or single-output jobs is helpful when you want the output to run independently of other outputs. Remember that each job group in a streaming pipeline will require its own Flink cluster, which will increase computation costs.
Moving outputs between job groups in streaming or incremental pipelines is considered a breaking change and will trigger mandatory replays. Learn more about breaking changes in Pipeline Builder.
Assign job groups
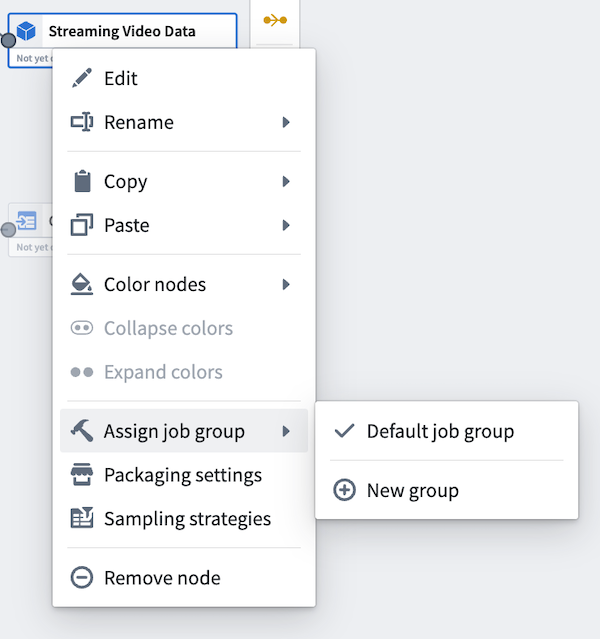
To assign job groups, right-click on any output node in your Pipeline Builder graph to open the context menu. Then, hover over Assign job group. In batch pipelines, outputs will default to single jobs. In streaming pipelines, outputs will default to a single job group.
Batch view | Streaming view
-------- |------------------
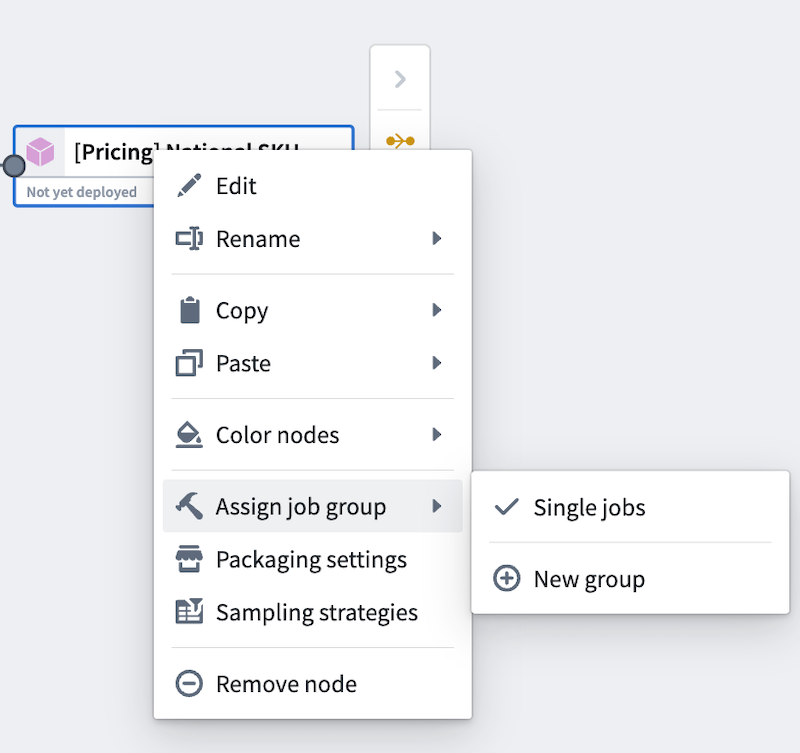 |
| 
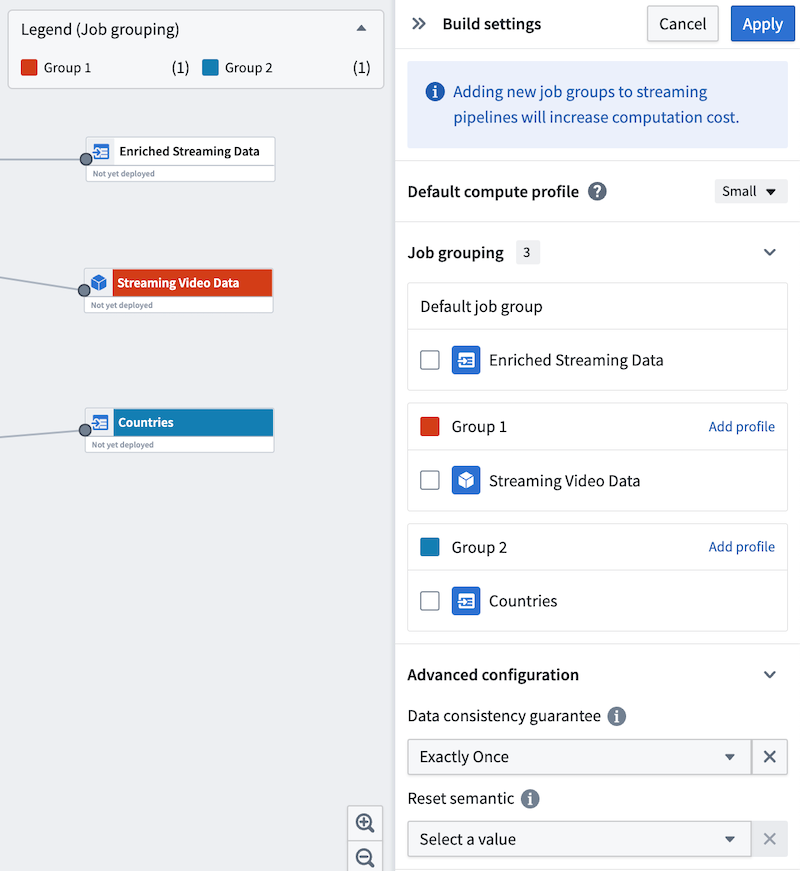
Select New group to assign the output to a new job group. A Build settings panel will open to the right side and automatically assign a color to the job group for easy identification on the graph.
Batch view | Streaming view
------ |------------------
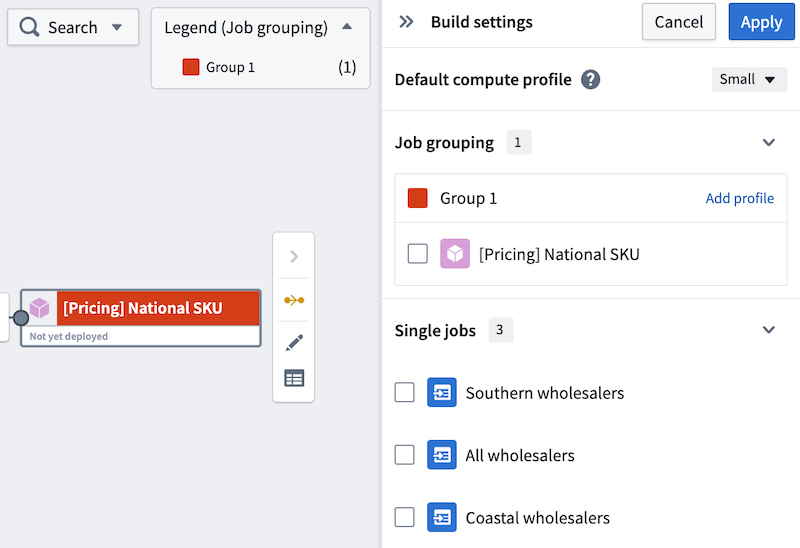 |
| 
Continue to edit other outputs to add them to existing or new job groups. Alternatively, use the side panel to move outputs to new groups.
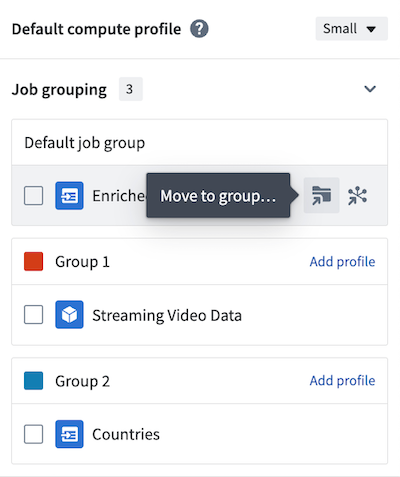
The default compute profile is shown at the top of the panel. To add custom profiles for each job group, select Add profile in the header of each group. In the example below, the default compute profile is Small, but Group 1 is configured with a Medium compute profile.
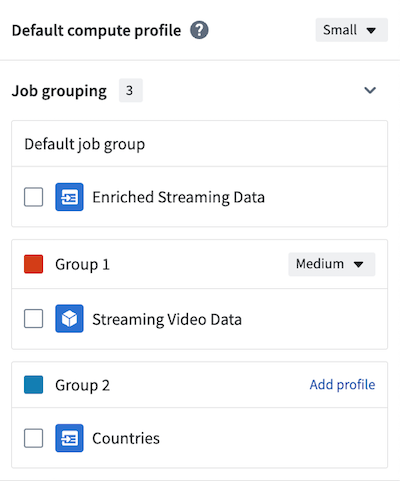
Once you have created your job groups, select Apply in the upper right of the panel to save your changes.

You are now ready to deploy your pipeline.
Job groupings and Markings
In a job group, Markings from all inputs will be inherited by all outputs within the same job group, even if the outputs are not directly connected to the marked inputs. Learn more about Markings inheritance.
In the following example, Input_A has Markings and Input_B has no Markings. Output_X and Output_Y are in the same job group. Although Output_Y is not directly connected to Input_A, it will inherit all Markings from Input_A upon deployment.
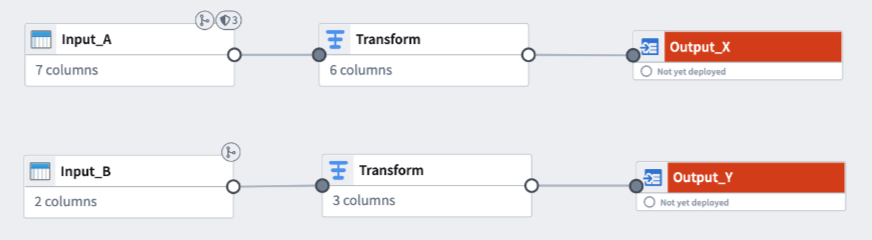
You can preemptively remove Markings inherited from job groupings if you do not want the markings on Output_Y.