- Capabilities
- Getting started
- Architecture center
- Platform updates
Build settings
This page describes build settings in Pipeline Builder that can be used to adjust the performance of your batch and streaming pipelines.
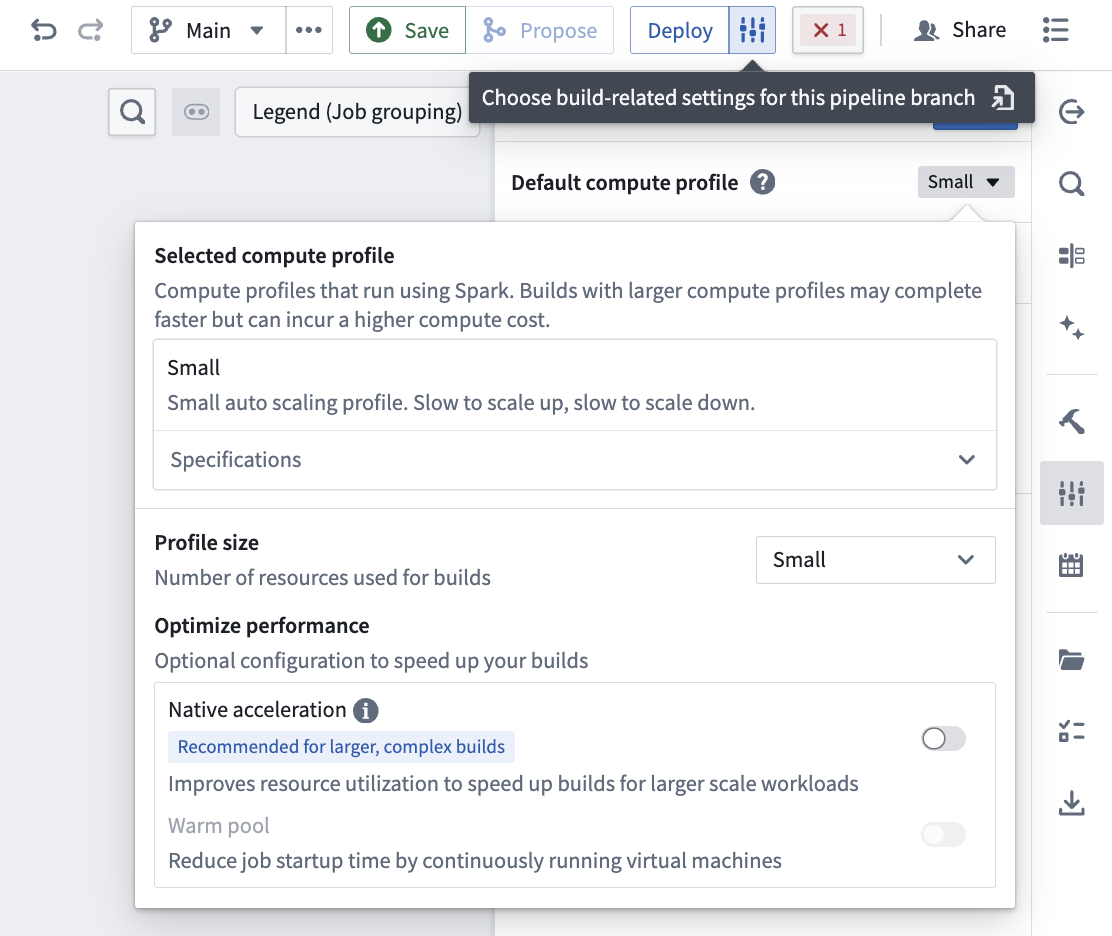
You can edit the Build settings of your pipeline by selecting the settings icon next to Deploy in the top right of your screen.
Batch pipeline
Batch compute profiles
The following batch compute profiles are available to select in Build settings:
| Profile | Driver cores | Driver memory | Dynamic min executors | Dynamic max executors | Executor cores | Executor memory | Executor off-heap memory |
|---|---|---|---|---|---|---|---|
| Extra Small | 1 | 4GB | N/A | N/A | N/A | N/A | N/A |
| Small | 1 | 2GB | 1 | 2 | 1 | 3GB | N/A |
| Medium | 1 | 6GB | 2 | 16 | 2 | 6GB | N/A |
| Large | 1 | 13GB | 2 | 32 | 2 | 6GB | N/A |
| Extra Large | 1 | 27GB | 2 | 128 | 2 | 6GB | N/A |
| Warm Pool Extra Small | 3 | 13GB | N/A | N/A | N/A | N/A | N/A |
| Natively Accelerated Small | 1 | 2GB | 1 | 2 | 1 | 600MB | 2400MB |
| Natively Accelerated Medium | 1 | 6GB | 2 | 16 | 2 | 1200MB | 4800MB |
| Natively Accelerated Large | 1 | 13GB | 2 | 32 | 2 | 1200MB | 4800MB |
| Natively Accelerated Extra Large | 1 | 27GB | 2 | 128 | 2 | 1200MB | 4800MB |
You can also view these specifications in the Specifications dropdown under the selected compute profile.
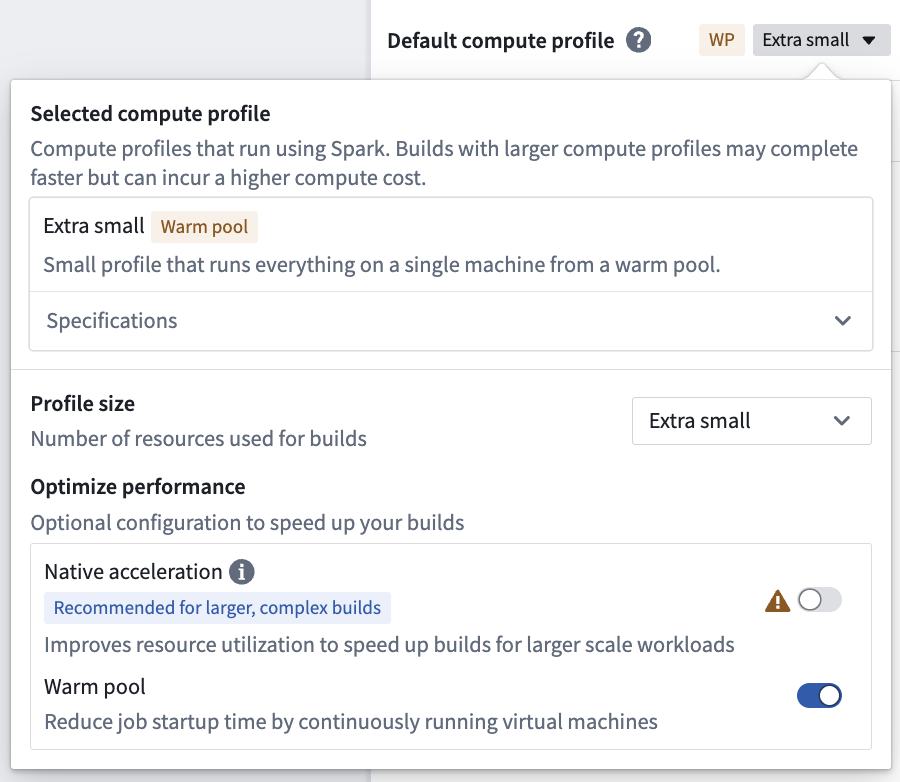
Warm pool
The warm pool compute profile option, available only on Rubix and OpenShift enrollments, is a powerful new type of compute profile designed to speed up your builds in Pipeline Builder. Warm pool speeds up your builds by using an auto-scaling pool of continuously running virtual machines to minimize job startup latency. A maximum of three jobs will run concurrently on a single virtual machine, each of which will consume a share of the total resources available on the virtual Machine.
By leveraging warm pool, jobs can begin processing immediately, speeding up overall build times. It is recommended for smaller scale builds, for example, a job that would take up to 30 minutes on an extra small profile.
Enable warm pool
To enable warm pool, toggle on Warm pool in the compute profile dialog. Larger profiles are currently not support for warm pool.
Native acceleration
You can improve performance by enabling native acceleration of batch pipelines in Pipeline Builder with Velox ↗.
Read more about native acceleration in Foundry.
Enable native acceleration
You can edit the build settings of your pipeline by selecting the settings icon next to Deploy. The settings for native acceleration contain preconfigured profiles for small, medium, and large compute sizes. These align with the default small, medium, and large sizes based on the total memory footprint (there is no local mode). These preconfigured profiles are recommended if you are trying to run a pipeline with native acceleration for the first time.
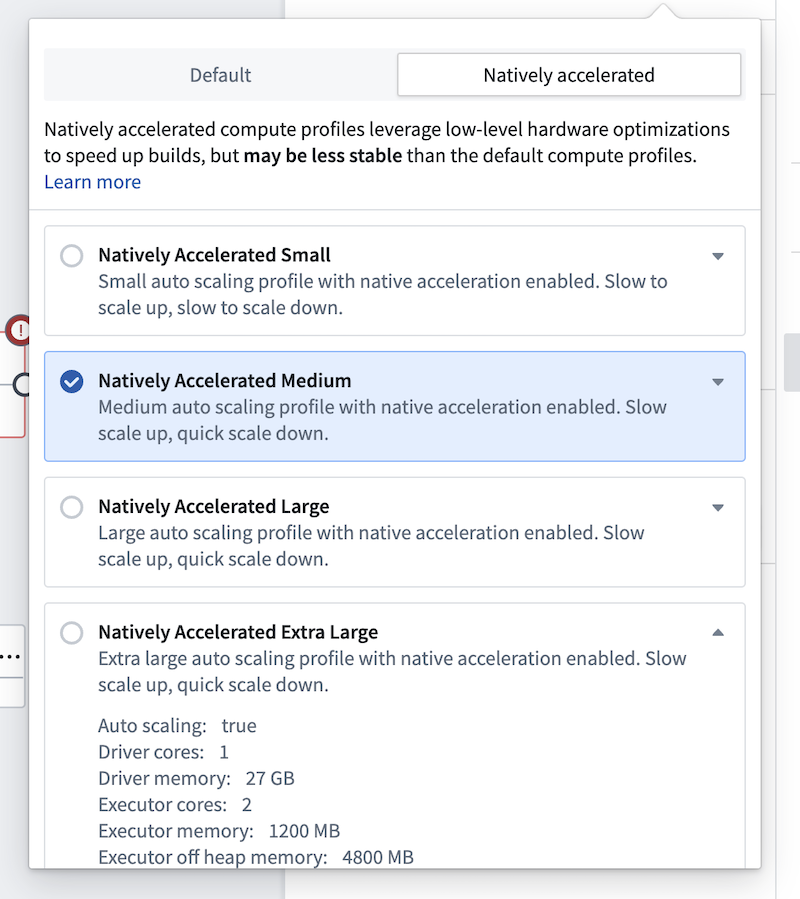
There is also a natively accelerated profile with advanced configuration, allowing you to fully specify the on-heap and off-heap memory ratios, as well as all other resource and compute affecting configurations for the build.
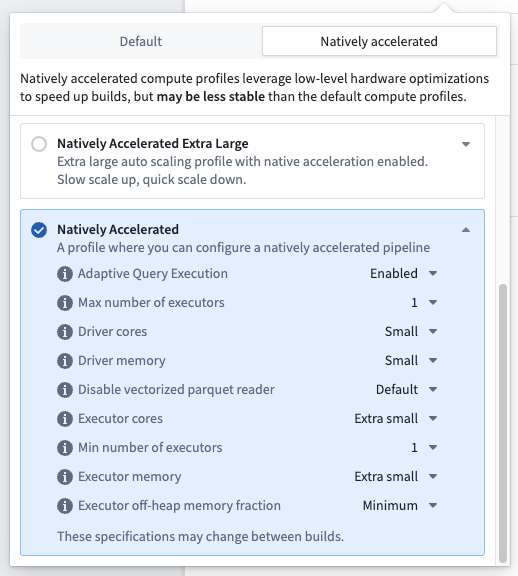
Most of the time, selecting a preconfigured native acceleration profile should be enough to speed up your pipelines. If you encounter OOMs or performance regressions that do not occur in the non-natively accelerated build, the memory configuration is likely suboptimal. Often, adopting the advanced profile and reducing the percentage of memory allocated to off-heap can resolve the issue. If problems persist, it is likely that the pipeline is not well-suited for native acceleration and you should continue using the default run profiles.
Memory configuration considerations for native acceleration
After enabling native acceleration, monitor your builds for any failures. If failures occur, try selecting a custom profile and changing the percentage of memory allocated to off-heap compute. More information is provided below.
Running Spark with native acceleration in Foundry requires a slightly different configuration from normal batch pipelines. Spark supports performing some operations with off-heap memory ↗. Off-heap memory is memory that is not managed by the JVM, cutting out GC overhead and leading to better performance.
By default, we do not enable off-heap memory in Foundry, as doing so can introduce additional maintenance costs for pipelines. Enabling off-heap memory is necessary for native acceleration since DataFrames modified by Velox must be off-heap to be accessible by the native process.
Foundry still requires sufficient on-heap memory for everything except Velox data transformations (for instance, orchestration, scheduling, and build management code still run in the JVM), but ideally most work will now be performed off-heap. Configuring a pipeline to use native acceleration introduces additional maintenance costs in balancing on-heap and off-heap memory. Pipeline Builder will offer managed profiles to assist with this, but custom configuration may still be necessary.
Streaming pipeline
Streaming compute profiles
The following compute profiles are available to select in Build settings:
| Profile | Job Manager memory | Parallelism | Task Manager memory |
|---|---|---|---|
| Extra Extra Small | 1GB | 1 | 1GB |
| Extra Small | 1GB | 1 | 1GB |
| Small | 1GB | 2 | 4GB |
| Medium | 1GB | 3 | 6GB |
| Large | 2GB | 4 | 8GB |
| XLarge | 2GB | 8 | 12GB |