- Capabilities
- Getting started
- Architecture center
- Platform updates
Data expectations
Data expectations are requirements that can be applied to dataset outputs. These requirements (known as "expectations") can be used to create checks that improve data pipeline stability.
Data expectations can be set on each pipeline output to define an expectation on the resulting output. Pipeline Builder currently supports two data expectations: primary key and row count.
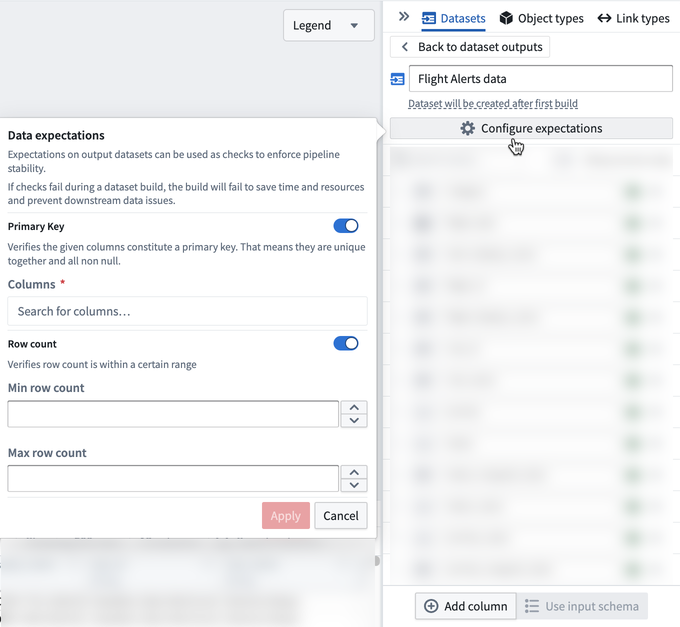
If any expectations fail, the build will fail. The job expectations pane will show which data expectations passed and failed.
Primary key data expectations
Primary key expectations are provided with one or more column names and verify:
- Each column has no null values.
- The combination of columns is unique.
If you have an incremental build, and your primary key check is taking a long time, try adding a projection to your primary key column.
Example of a primary key data expectation
In the specific column selected, we check that every entry underneath is unique.
If two columns are selected, we check that the combination of both columns are unique.
In our example, we'll use id and time as two columns existing in our dataset.
Example dataset:
| id | time |
|---|---|
| 1 | 8pm |
| 1 | 9pm |
| 2 | 8pm |
| 3 | 8pm |
The above example would pass the check. This is because even though 1 and 8pm are repeated individually, the combination of id and time remains unique.
Conversely, the following would fail:
| id | time |
|---|---|
| 1 | 8pm |
| 2 | 9pm |
| 1 | 8pm |
This table would fail the check because the 1 and 8pm combination is repeated.
Row count data expectations
Row count expectations are provided with a minimum and/or maximum row count.
If a minimum row count is provided, the expectation will verify that there are at least the specified amount of rows.
If a maximum row count is provided, the expectation will verify that there are at most this many rows.