- Capabilities
- Getting started
- Architecture center
- Platform updates
HyperAuto V1 [Sunset]
HyperAuto V1 is in the sunset phase of development and will be deprecated at a future date. Full support remains available. The creation of new V1 pipelines is discouraged, and users should migrate from HyperAuto V1 to V2 as detailed in the migration documentation.
HyperAuto V1 (also known as SDDI or Bellhop), is the first version of Palantir's source-to-value automation suite. HyperAuto V2 has been released for SAP and is strongly recommended for that data source, but HyperAuto V1 is still currently supported for several source types, including:
- Salesforce
- Oracle NetSuite
- SAP (V1 not recommended; use V2 instead)
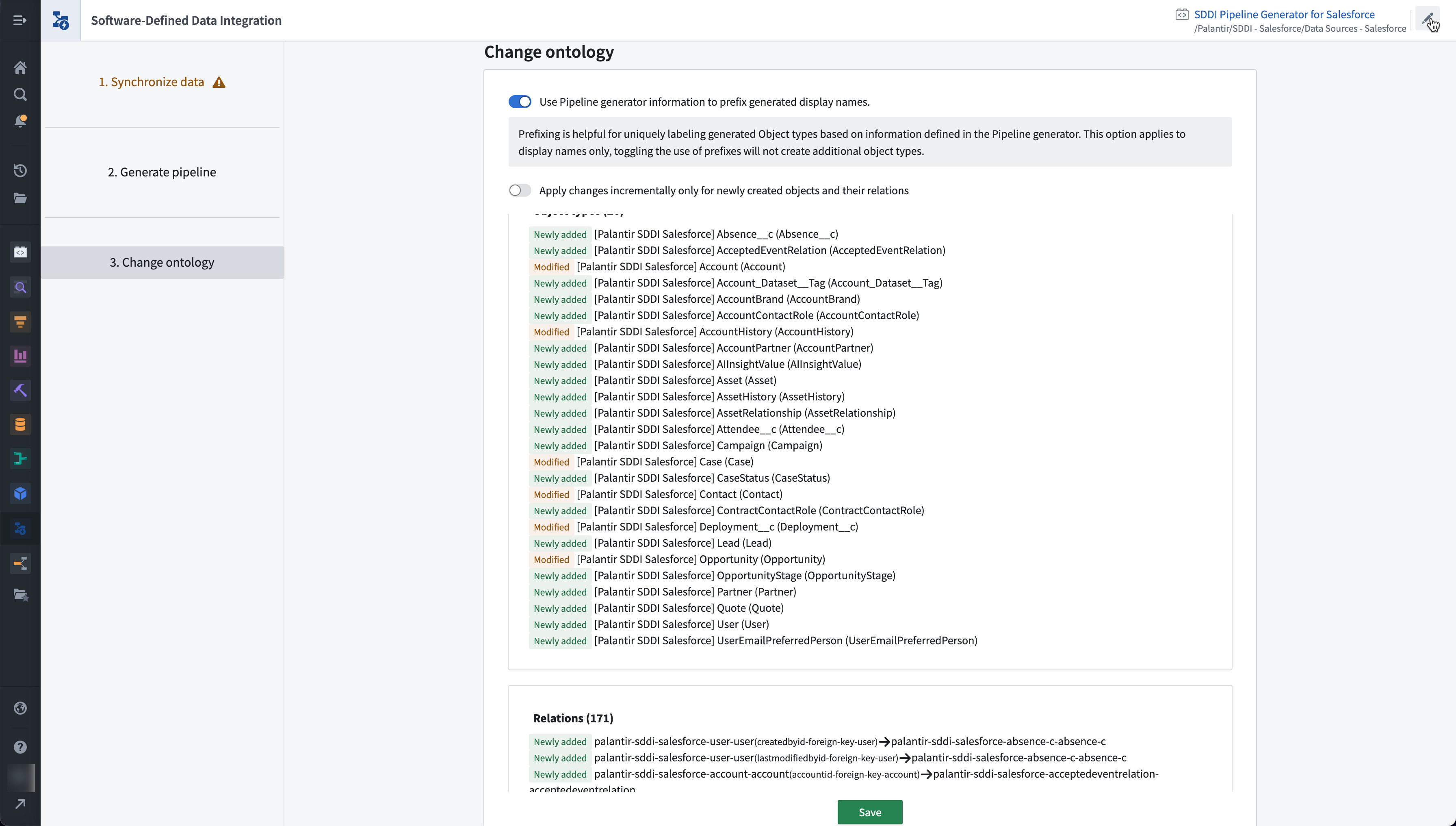
Detailed documentation for HyperAuto V1 is available in-platform. From there, view Software-Defined Data Integration to see the range of configuration options.
Architecture
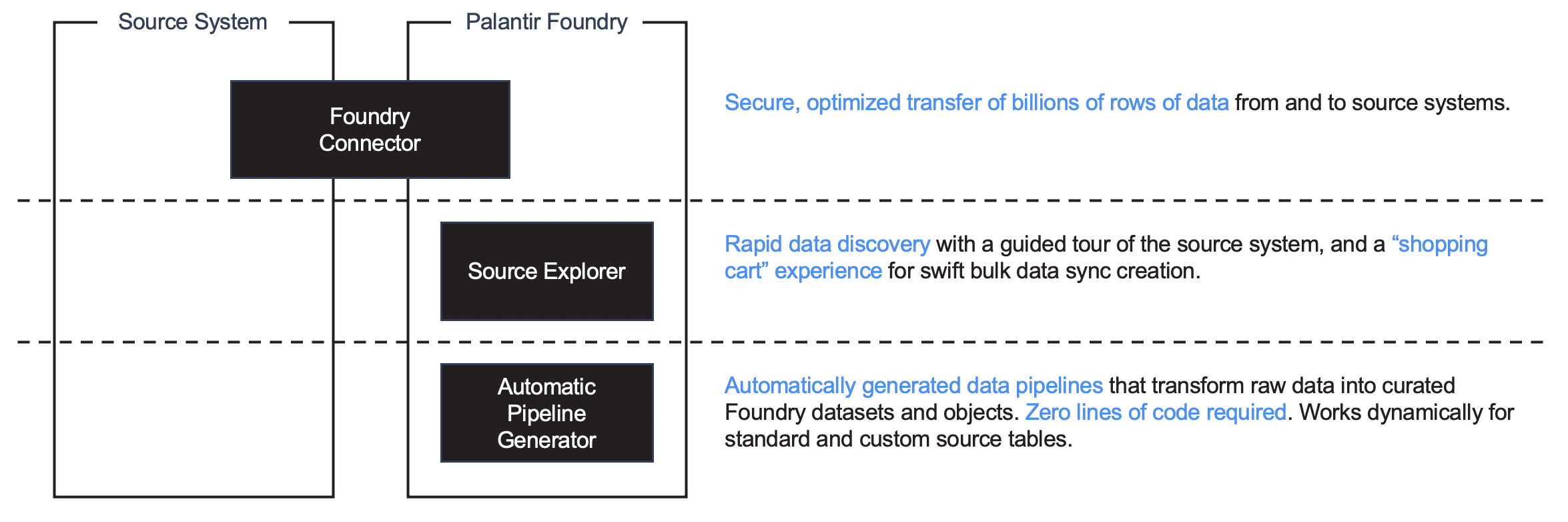
HyperAuto V1 consists of three components designed to integrate data from raw sources to ontology with minimal effort:
- Connectors enable transfer of large-scale data in a secure and optimized way from and to source systems.
- Source exploration allows rapid data discovery in a guided manner, and a "shopping cart" experience for rapid bulk data sync creation and configuration.
- Automatic pipeline generation transforms raw data into curated Foundry datasets and object types in the Ontology using automatically generated data pipelines.
Pipeline generation
Automatic pipeline generation creates out-of-the-box data pipelines for integrating common source systems. The pipelines prepare the data so that it can be used by ontologies and workflows. Because pipeline generation ships with embedded knowledge about each source system, using this feature increases efficiency and removes the need to fully understand the intricacies of each underlying source system.
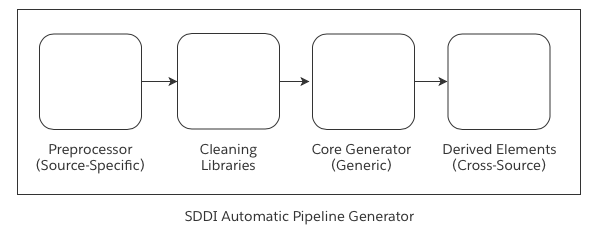
Generated pipelines include four major steps:
- Source-specific preprocessing generates a set of metadata datasets with a pre-defined schema. These metadata contain the necessary information to understand data from the source system.
- Cleaning libraries apply standardized data cleaning steps to all datasets, ensuring that best practices are followed for every piece of data flowing into the system.
- Core generation performs data enrichment, column renaming, de-duplication, and data unioning to produce usable data that can be used for analysis, reporting, and workflows in the Ontology.
- Derived elements provide pre-defined support for advanced workflows, including generating join tables, time series datasets, and enriched columns that provide rich derived information that also feeds into the Ontology.
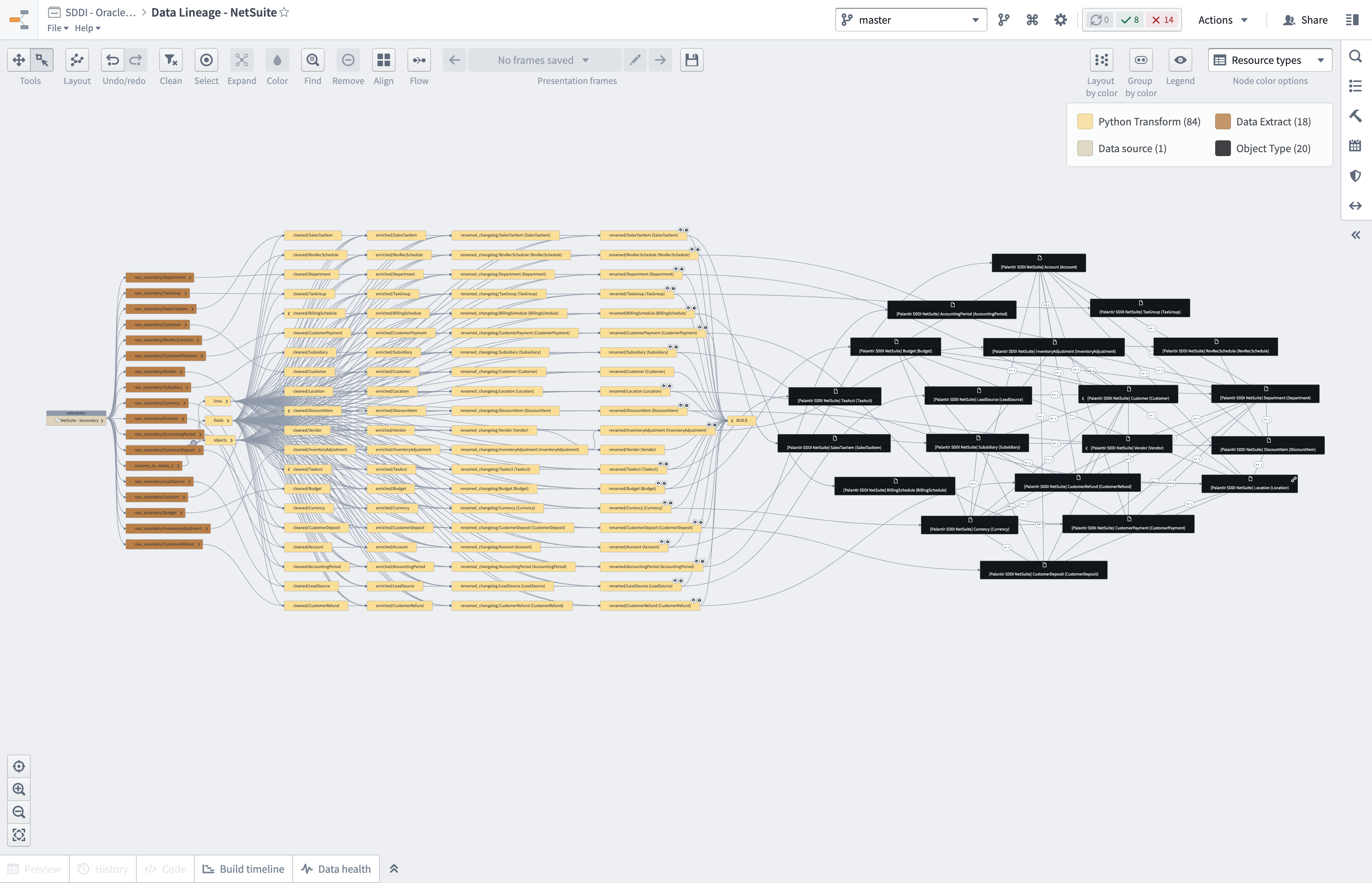
Ontology creation
After pipelines are automatically generated, HyperAuto V1 additionally supports generating an Ontology automatically. This completes the data integration process, allowing you to immediately begin searching for, analyzing, and even building applications on top of data thanks to the broad set of Ontology-aware applications in Foundry.