- Capabilities
- Getting started
- Architecture center
- Platform updates
Views
A View behaves similarly to a Foundry dataset view, but it does not hold any files containing data. Instead, it is composed of the union of other datasets (known as backing datasets) when it is read. Views can be thought of as "pointing" to their backing datasets.
Views can also automatically perform deduplication of data with the addition of a primary key. If any of a View's backing datasets have new data, a build will be automatically triggered to ensure that the latest data is available after deduplication. Views build like regular datasets but complete almost instantly since no data is actually read or written as part of the build.
Generally, you can use Views like regular datasets. However, Views cannot be specified as valid transform outputs; instead, they can be specified as valid transform inputs.
Additionally, Views can only be used with datasets that have a schema, since Views operates with rows.
Views built over incremental datasets should not be used as incremental inputs in downstream transforms. When Views are read incrementally, the deduplication is done within the incrementally read transaction range and not across the entire View.
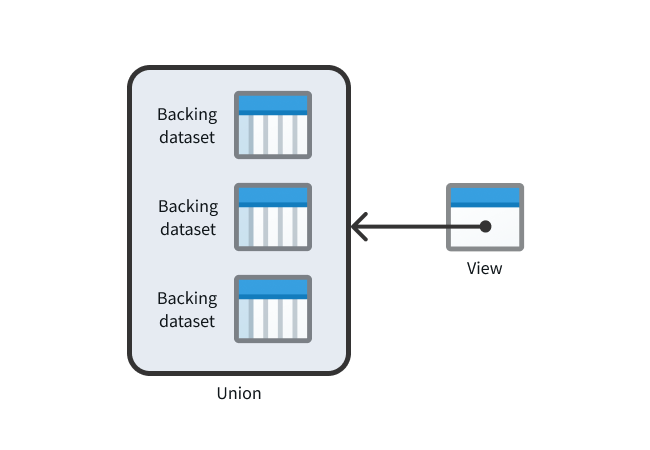
Some primary use cases for views include the following:
- Automatic updates: Create a union dataset that is always up-to-date without having to perform a transform.
- Folder organization: Replicate a dataset in a different location without incurring additional compute and storage costs.
- Data uniqueness: Automatically guarantee data with primary key deduplication without transforms.
Create a View
To create a new View, open Files from the left workspace navigation panel, then find your desired Project or folder. Once there, select New > View in the top right to create a new View within the current Project or folder:
Choose a name and location for the View, then proceed with configuration. When the View is created, a build schedule will be automatically created in the background that will rebuild the View any time the backing datasets update. If you want to immediately read the View after creating or modifying it, you must build the View manually.
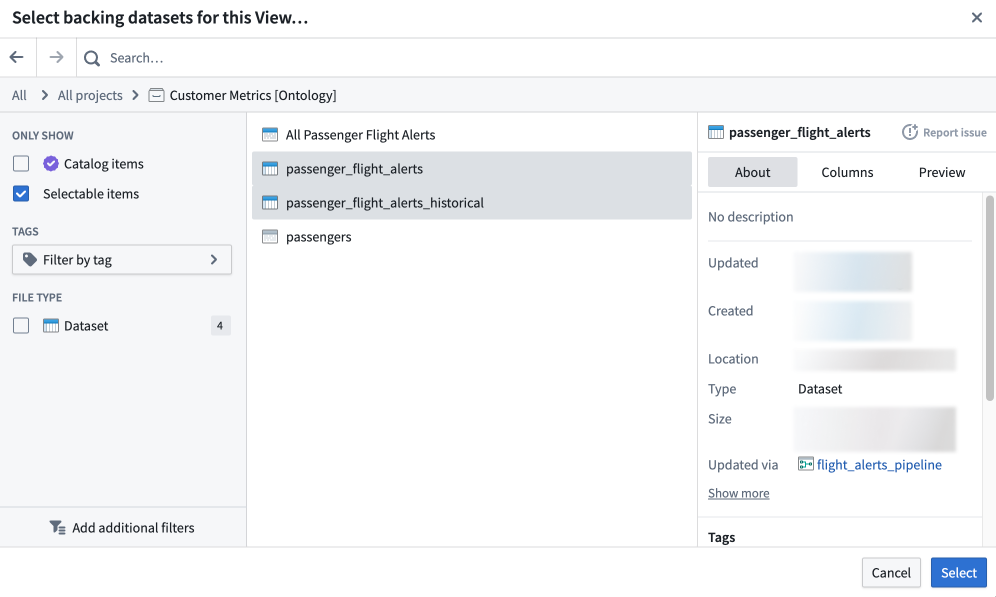
Select backing datasets
Because a View is composed of the union of its backing datasets, every backing dataset for a given View must possess the same set of column names and types (though the column order can be different).
One or more backing datasets are required to construct a View. After initial configuration, a View's backing datasets can be modified by navigating to Details > Dataset view settings.
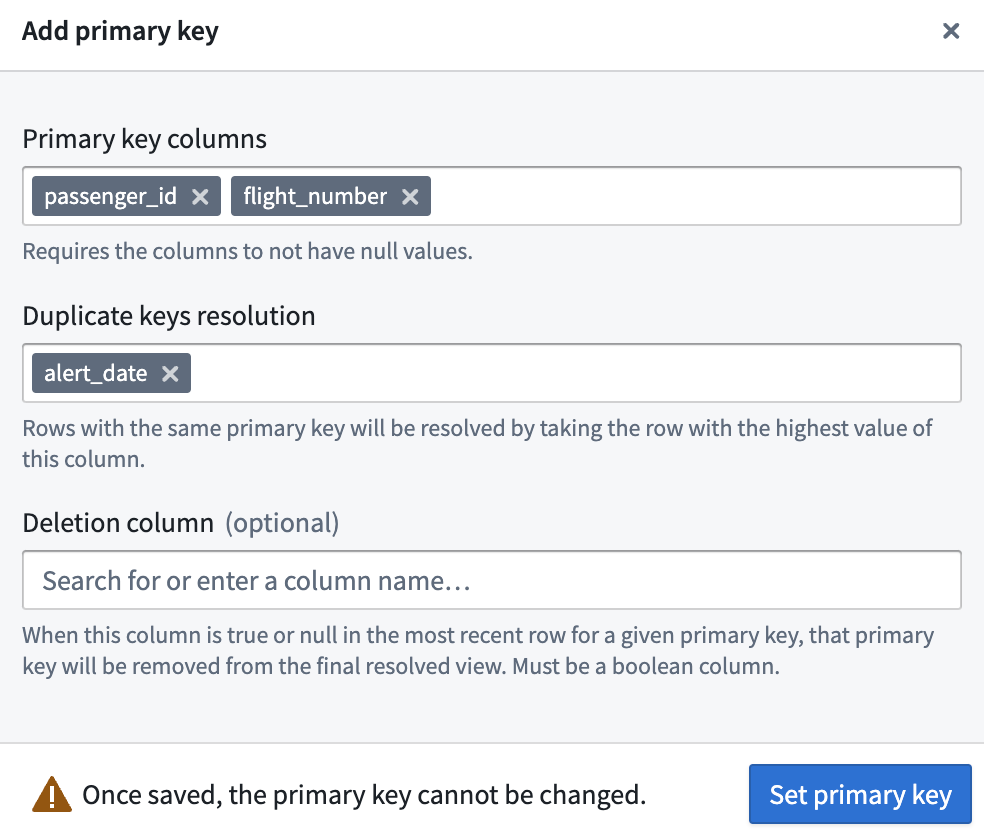
Add a primary key
Data deduplication is a key feature of Views that you can enable by adding a primary key. Once the primary key is configured, the View is guaranteed to have primary key uniqueness; each primary key present in the View appears in only one row. Add a primary key to ensure that only the most up-to-date data for each primary key is returned when the View is read. This automatic deduplication can be especially useful in cases when the View's backing dataset(s) may contain unwanted duplicate rows.
Once the primary key is set, it cannot be modified without creating a new View.
To add a primary key, select one or more columns which, when combined, will form the primary key. The column(s) must not contain null values.
If you do not add a primary key during initial configuration, you can do so later by navigating to Details > Dataset view settings.
Resolve duplicate keys
To add a primary key, you must also specify a column (or combination of columns) for resolving duplicate primary keys. Deduplication of rows with the same primary key is performed by keeping the row with the highest values of these columns in order and discarding the others. This ensures that every primary key appearing in the View is unique.
Select a deletion column
You can also optionally specify a deletion column, which must contain Boolean values. After deduplication, if the final remaining row for a given primary key has true in the deletion column, that row will be excluded from the View.
Deduplication and deletion in practice
Duplicate primary keys are resolved before the deletion column is used to exclude rows. Therefore, only the value of the deletion column in the “latest” row for a given primary key matters.
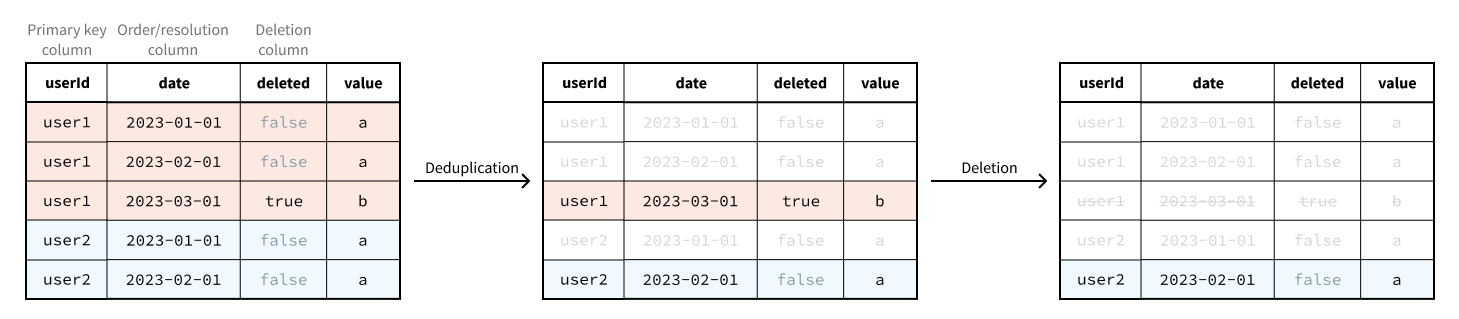
Deduplication and deletion is performed across all of the backing datasets:
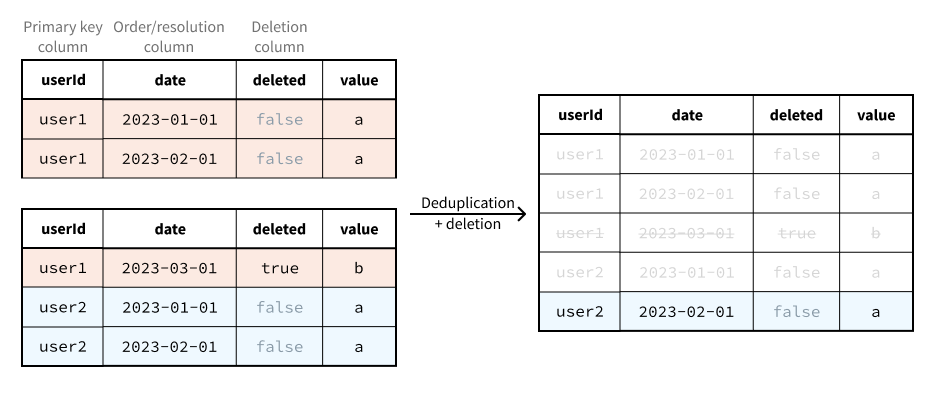
Deduplication and deletion is implemented with a combination of the following:
- An appropriately configured, automatically created projection on the View.
- Window function-based filter logic that is evaluated on every read.
Although the filter logic is evaluated on every read, the evaluation of this logic has a negligible impact on runtime and compute cost provided the projection is up to date and the backing datasets of the View have only had APPEND or UPDATE transactions since the last projection build.
Considering this architecture, we recommend only creating a View with primary key configuration in the following cases.
- All of the backing datasets are updated with
APPENDor strictly additiveUPDATEtransactions. - Some of the backing datasets are updated with
APPENDor strictly additiveUPDATEtransactions and some are updated withSNAPSHOTtransactions, but the ones that are updated withSNAPSHOTtransactions are built infrequently.
If updates to the backing datasets require a full rebuild of the projection, considerable compute costs will be incurred since readers (Contour, transform jobs, and so on) must apply the filter logic without the benefit of the projection until the projection rebuild is complete.
Use Views
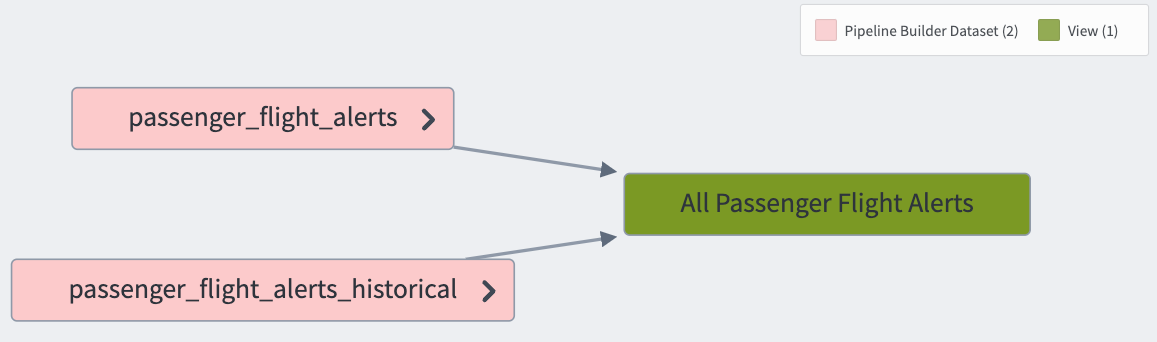
Views are visible in Foundry like regular Foundry datasets and can be used anywhere that regular datasets can be used. The only exception to this is that Views are not valid transform outputs (though they are valid transform inputs). An example use case for Views is to create a union of multiple datasets efficiently, using a primary key to ensure the resulting View has data uniqueness.
Remove Markings with Views
Views do not support the removal of Organizations from datasets, only mandatory control Markings.
Removing Markings with Views may not be enabled on your Foundry enrollment. Contact Palantir Support to enable this feature.
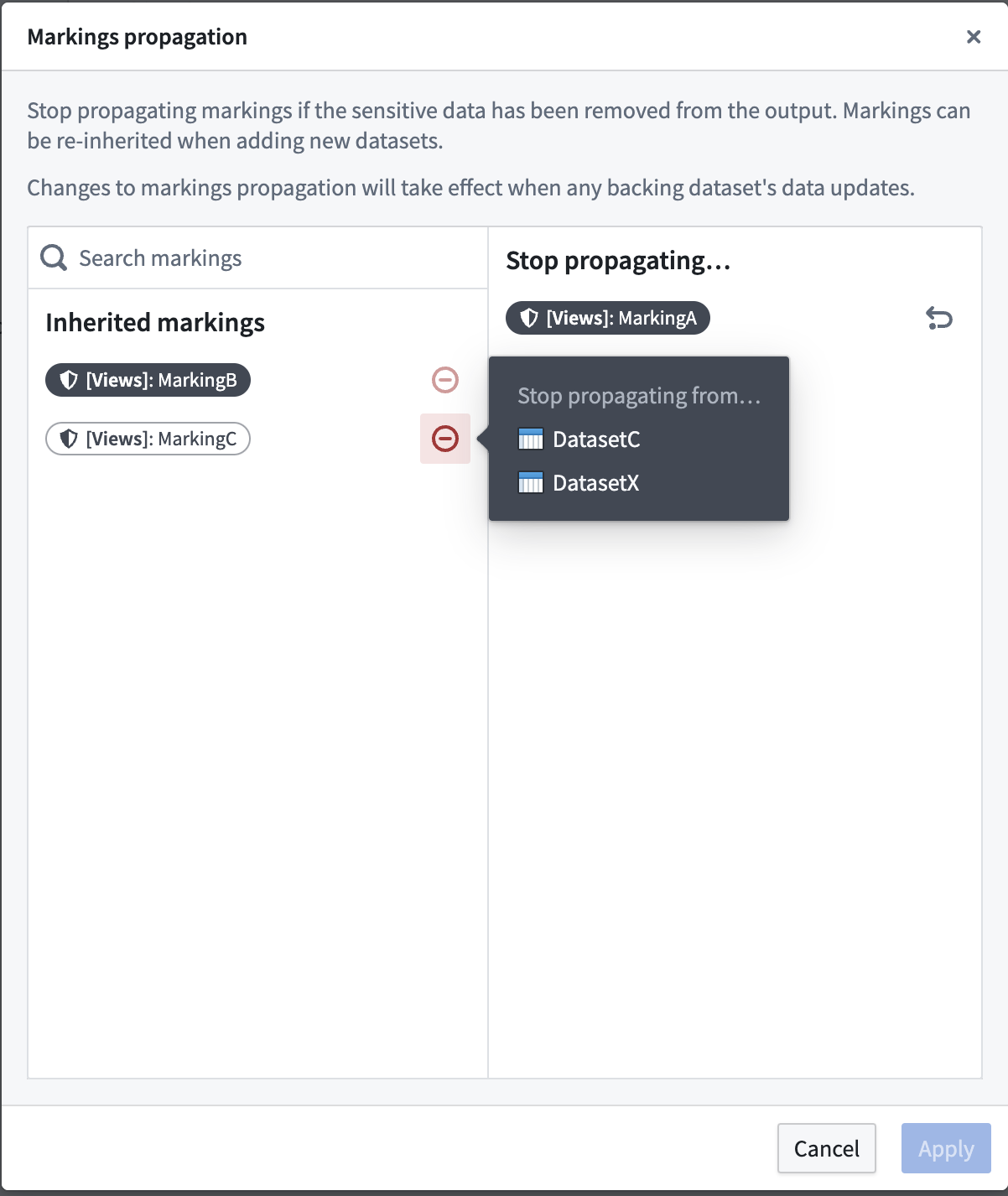
You can use Views to stop propagating Markings on datasets backing the View. You can do this by navigating to Dataset view settings in the Details tab of the View, then selecting Edit > Manage marking propagation.
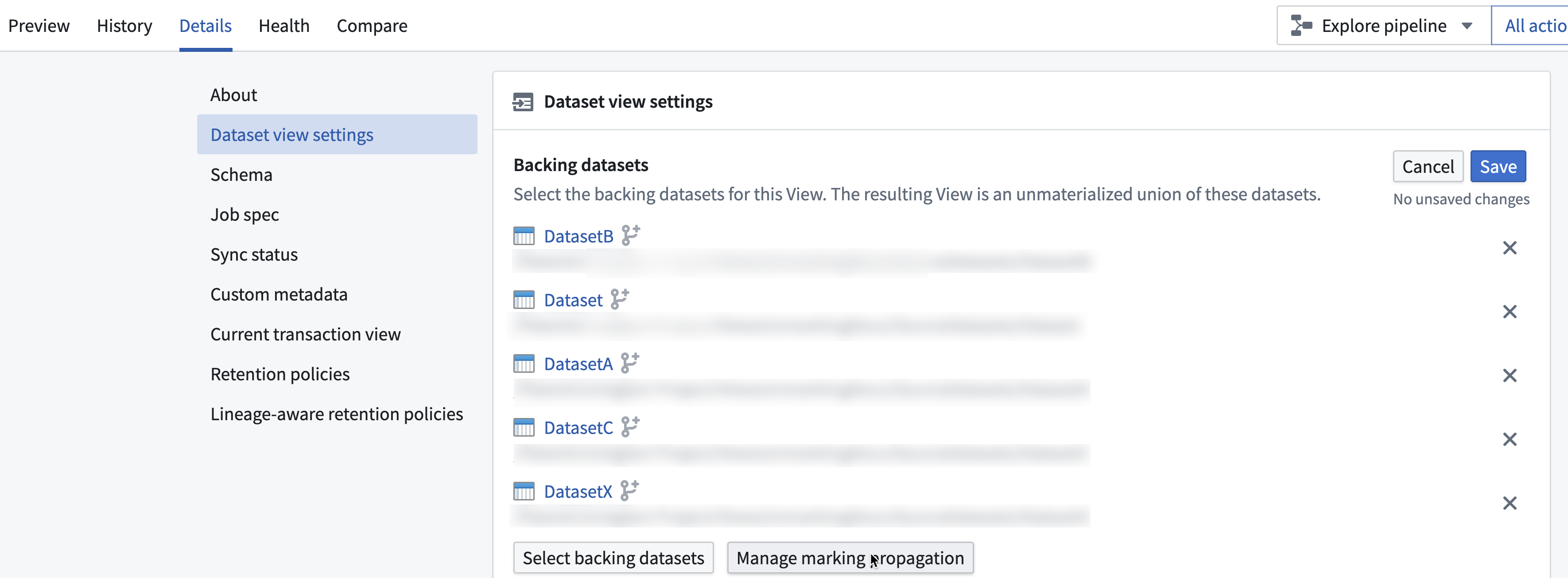
Only users with Remove Marking permissions will be able to stop propagation of the Marking. Changes to Marking propagation will take effect when any updates to the backing dataset occurs.
Review our guidance on removing Markings for more information.