- Capabilities
- Getting started
- Architecture center
- Platform updates
Streams
Similar to a dataset, a stream is a representation of data from when it lands in Foundry through when it is processed by a downstream system. A stream is a wrapper around a collection of rows which are stored by both a persistent “hot buffer” and “cold storage” backed by a file system. The benefit of using Foundry streams is they provide the same primitives as a Foundry dataset (branching, version control, permission management, schema management, etc) while also providing a low latency view of the data.
Streams are inherently tabular and, therefore, inherently structured. They are stored in open source formats such as Avro ↗, along with metadata about the columns themselves. This metadata is stored alongside the stream as a schema.
Stream storage
Hot buffer
As records flow into a Foundry stream, they are stored in a hot buffer that is available in low latency for all downstream applications that support reading streams. This hot buffer is critical for enabling low latency transforms and availability. It provides at-least-once semantics for data ingestion and optional exactly-once semantics for data processing in platform.
Cold buffer
All data from within a Foundry stream is transferred from the hot buffer to the cold storage every few minutes. We call this process "archiving", and it makes the data available as a standard Foundry dataset. This means that any Foundry application can operate on streaming data, even if it doesn’t process data in real-time from the hot buffer. The dataset view of a Foundry stream behaves exactly as a standard Foundry dataset in the platform.
Stream processing
Read data from a stream
Foundry products with low latency enabled are able to read a hybrid view of the data. By reading data from both the hot and cold storage layers, products can provide a complete view of the data. This view gives products access to the low latency records still in hot storage and older data that has been transferred to cold storage. In this way, a Foundry stream can have the benefits of both the low latency of hot storage and the lower storage costs of cold storage.
Transactions
Unlike standard Foundry datasets, streams do not have transaction boundaries inherent in the stream themselves. Instead, each row is treated as its own transaction, and state is tracked on a per row basis. This allows a stream to be read at a granular level so Foundry can support push-based transformations without requiring batching or polling.
Stream types
You can configure stream types for each of your streams based on its throughput needs. These stream type settings apply to how streams write data to the hot buffer storage mentioned above. You should only need to modify the stream type settings if stream metrics indicate the stream is being bottlenecked when writing to the hot buffer storage. Latency and throughput are tradeoffs, so only set high throughput/compressed stream types after inspecting stream metrics. We support the following stream configurations:
- High Throughput: This is best for streams that send large amounts of data every second. Enabling this stream type might introduce some non-zero latency at the expense of a higher throughput. Therefore, before you enable it you should inspect stream metrics. If the average batch size is equal to the max batch size or if the job fails because of Kafka producer batches expiring, you might need to enable the high throughput setting.
- Compressed: Enabling this configuration compresses message batches when producing data to the hot storage buffer. Compression helps reduce the size of the data being sent, resulting in lower network usage and storage, at the cost of some additional CPU usage for compression and decompression. We only recommend enabling this stream type if your stream contains a high volume of repetitive strings and is experiencing poor network bandwidth symptoms like non-zero lag, lower than expected throughput, or dropped records.
You can set stream types when creating a new stream on the Define page. You can also update stream types in stream settings for an existing stream. For this, navigate to your streaming dataset in Foundry and select Details in the toolbar. Then, go to Stream Settings. You can change the stream type and enable/disable compression here.
Partitions
To maintain high throughput, Foundry breaks the input stream into multiple partitions for parallel processing. When creating a stream, you can control the number of partitions we create through the throughput slider. Note that although the data is partitioned, all reads and writes to the stream operate as if there is a single partition. This behavior provides design transparency to consumers and producers of Foundry streams.
Each additional partition for a given stream increases the max throughput the stream can process. A good heuristic is that each partition increases the throughput by approximately 5mb/s.
Supported field types
Foundry streams support the same data types as a Foundry dataset, including:
BOOLEANBYTESHORTINTEGERLONGFLOATDOUBLEDECIMALSTRINGMAPARRAYSTRUCTBINARYDATETIMESTAMP
Streaming Jobs
All streaming jobs are represented internally as job graphs, which provide a visual representation of your streaming pipeline. As data is processed, it flows through the job graph according to the directed edges until reaching a data sink.
Checkpointing
Foundry streaming provides fault tolerance while processing data by storing both the active state and current processing location in a checkpoint.
Checkpoints are periodically produced by data sources and flow through the job graph alongside the data from the source. Once a checkpoint has reached all data sinks at the end of the job graph, all rows emitted before that checkpoint by the source must have also reached the sink.
Checkpoints allow a streaming job to be restarted from the point of the latest checkpoint, rather than reprocessing already-seen data. Checkpoints store the state of each operator in your job graph, plus the last-processed data point in the stream. On your streaming job's Job Details page, you can see the status, size, and duration of your stream's last few checkpoints in real-time.
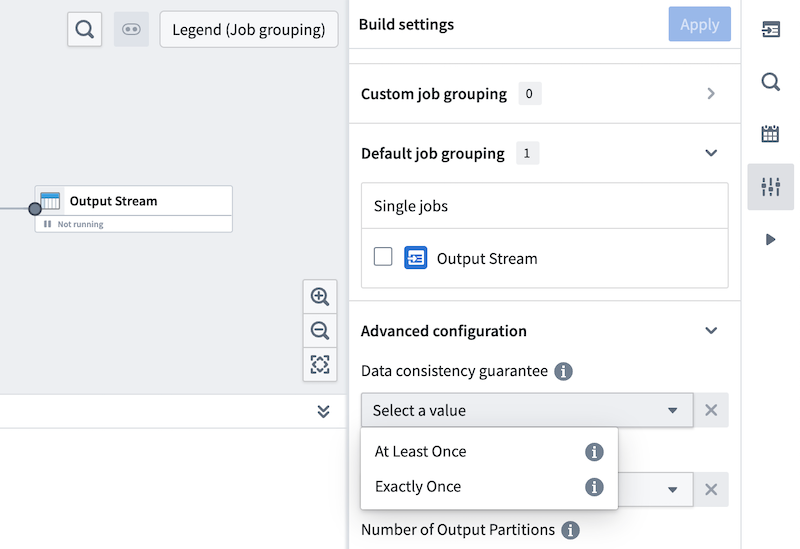
Streaming consistency guarantees
Streaming in Foundry operates with two consistency guarantees: AT_LEAST_ONCE and EXACTLY_ONCE.
AT_LEAST_ONCE semantics
AT_LEAST_ONCE semantics guarantee that a message will be delivered downstream at least once, but a message may be delivered multiple times in case of checkpointing failures or retries. This means that duplicates may occur, and the consuming application should be designed to handle or tolerate duplicate messages.
Benefits of AT_LEAST_ONCE semantics
- Ensures that no messages are lost, providing a high level of message durability.
- Generally offers lower latency compared to
EXACTLY_ONCEsemantics, as messages can be delivered without blocking on the bookkeeping of records.
Drawbacks of AT_LEAST_ONCE semantics
- Requires the downstream consuming application to be able to handle duplicate messages.
EXACTLY_ONCE semantics
EXACTLY_ONCE semantics guarantee that each message will be delivered and processed exactly once, ensuring that there are no duplicates or missing messages. This is the strongest level of message delivery guarantee and can greatly simplify the design of the consuming application.
Benefits of EXACTLY_ONCE semantics
- Ensures that no messages are lost, providing a high level of message durability.
- Eliminates the need for the consuming application to handle duplicate messages or implement idempotent processing.
- Ensures consistency in processing results, as each message is processed exactly once.
Drawbacks of EXACTLY_ONCE semantics
- Typically introduces higher latency compared to
AT_LEAST_ONCEsemantics, due to the additional coordination and tracking required to ensure that messages are not duplicated. Foundry streaming solves this problem through checkpointing.
Latency trade-offs
Choosing between AT_LEAST_ONCE and EXACTLY_ONCE semantics often involves a trade-off between latency and processing complexity. AT_LEAST_ONCE semantics generally provide lower latency because they do not require complex coordination or tracking mechanisms, but they place more responsibility on the consuming application to handle duplicates and maintain consistency. When EXACTLY_ONCE is enabled, records are only visible downstream after each checkpoint has completed (default is two seconds). Notably, the records are still being processed at streaming speeds but only show up downstream when "finalized".
On the other hand, EXACTLY_ONCE semantics provide stronger guarantees and can simplify the design of the consuming application by ensuring that each message is processed exactly once. However, this guarantee comes at the cost of higher latency due to the additional overhead required.
Streaming sources in Foundry currently only support AT_LEAST_ONCE semantics for extracts and exports. Streaming pipelines do support both AT_LEAST_ONCE and EXACTLY_ONCE semantics, and this is configurable under the Build settings section of Pipeline Builder.