- Capabilities
- Getting started
- Architecture center
- Platform updates
Set up a streaming sync
A sync is a task that reads specific data from a source and ingests it into Foundry. For example, if you have a relational database source that contains multiple tables, you might configure a sync to ingest a specific table into Foundry.
A streaming sync is similar to a non-streaming (i.e. batch or incremental) sync but with some differences. The primary difference is that a batch or incremental sync runs periodically while a streaming sync runs consistently to pull data into Foundry with as little latency as possible.
Below, we will discuss the steps required to create a sync :
- Define the data to sync from the source.
- Define a location in Foundry to send the data.
- Configure the streaming sync.
- Run the streaming sync.
For this tutorial, we will use a Kafka source to set up the sync.
Part 1. Define data
First, decide which data you would like to sync into Foundry. Select your streaming source in Data Connection, then select the available action in the top right corner:
- Explore and create syncs: This option appears if your source type supports source exploration, allowing you to explore your data source while creating a sync.
- Create sync: This option appears if your source type does not support source exploration.

Explore and create syncs
If your source type supports source exploration, you will land on the Explore source page in Data Connection that shows data available to sync. The exploration view interface depends on the source type you are using. For example, a Kafka source exploration allows you to see the topics ↗ present on the Kafka broker and preview the data contained in those topics.
From the Kafka exploration view, you can view existing topics in the list to the left of the page.
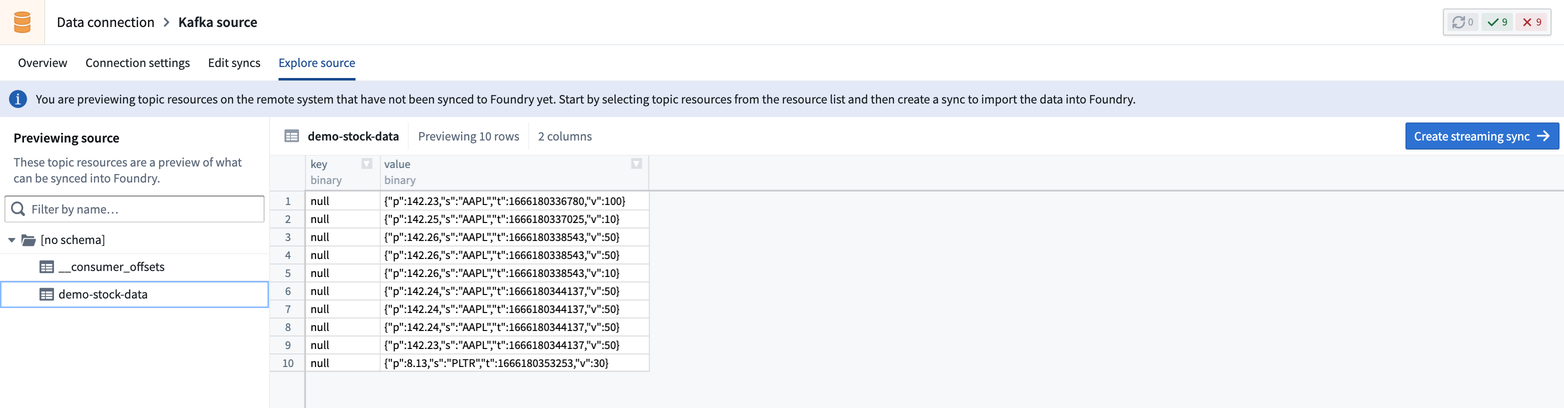
Selecting a topic will let you preview a sample of data from that topic.
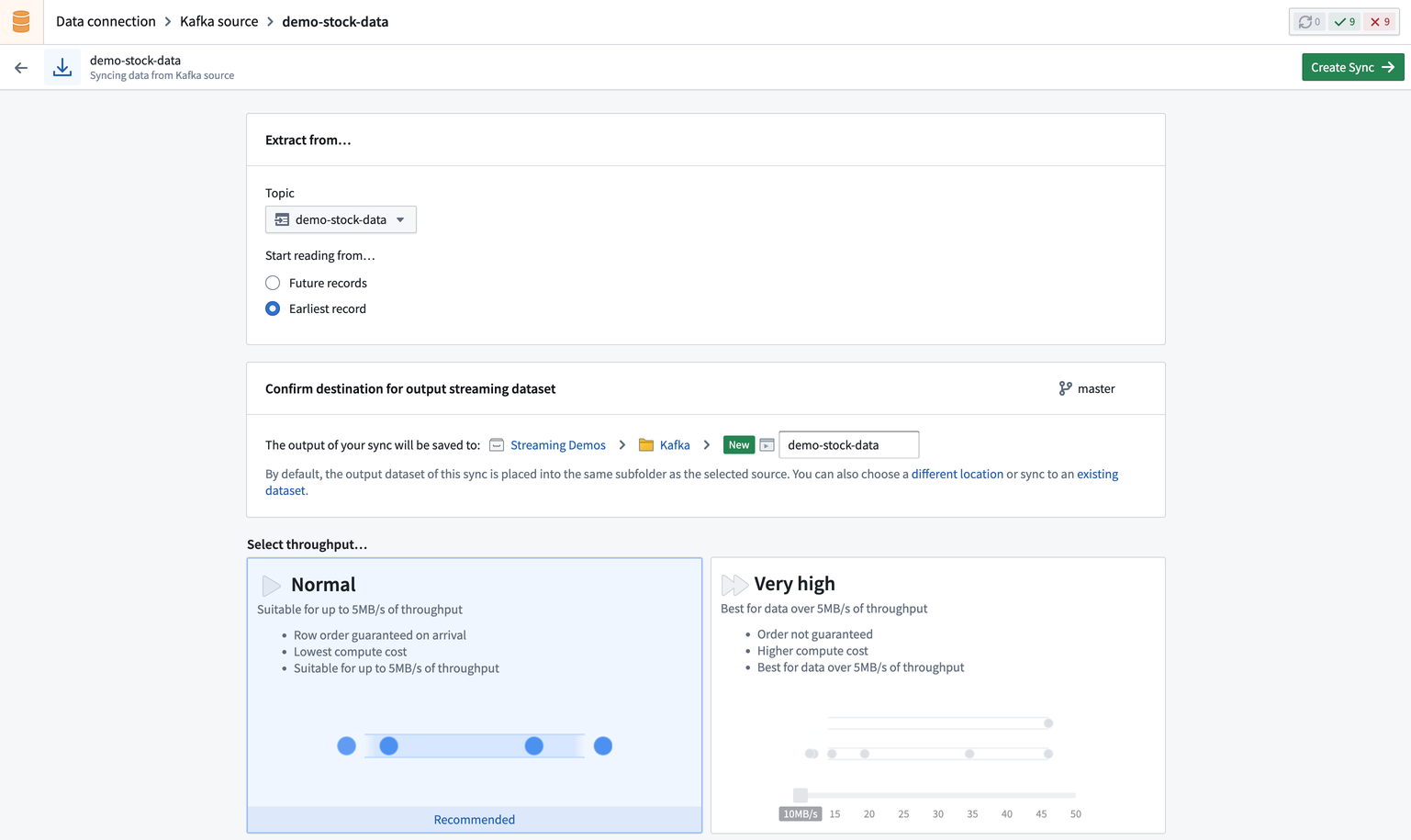
Part 2. Define the sync location
Next, you need to decide where to save your synced dataset in Foundry. The location of your dataset will determine who has permission to access the resulting dataset, based on Project-level permissions.
We recommend saving a synced dataset next to its source in a Project, allowing them to have the same permissions; matching dataset and source permissions are helpful when creating data pipelines. Learn more about the recommended Project structure for data pipelines.
Once you choose your sync location, click Create streaming sync in the upper right corner.
Part 3. Configure the streaming sync
Now, you will land on the Sync creation page in Data Connection where you can define source-specific and core streaming configurations for your sync.
- Source-specific: Located at the top of the configuration page, these options depend on your source type and configures the parameters passed to the specific source to which you are connecting.
- Core streaming: Located below the source-specific configuration, these options are common to all streaming syncs. Core configurations include the throughput, schema, and sync destination.
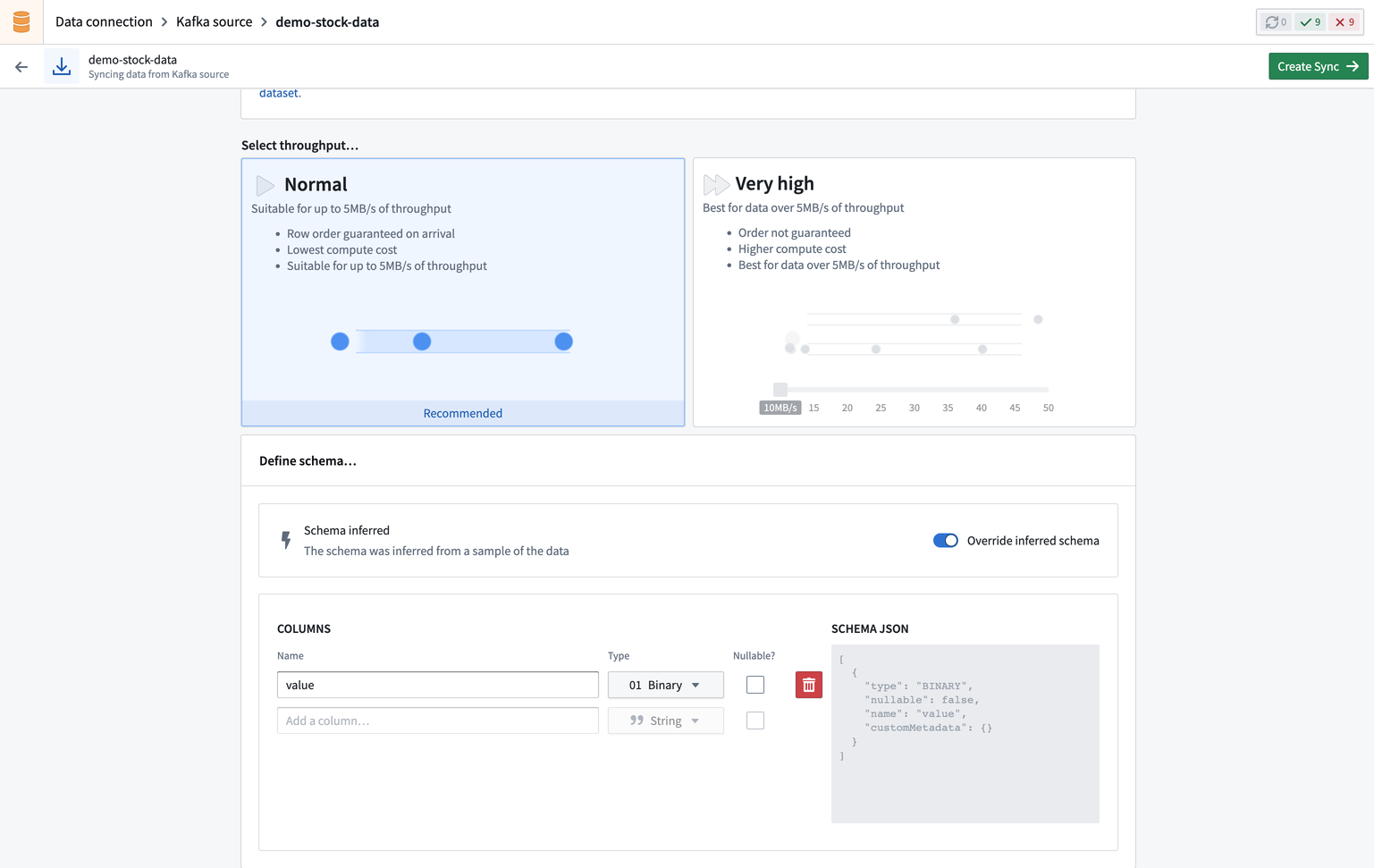
Next, select the throughput for your stream. The throughput determines the number of partitions that will be created. Selecting a larger number of partitions allows for higher throughput. Selecting a Normal throughput will allow up to 5 MB/s for that stream.
Then specify the schema of the input data, by default this is inferred from source, but it can be overwritten if necessary.
Once you configure your sync, select Create Sync on the top right.
Now that your sync is created, you will be taken to the Overview tab.
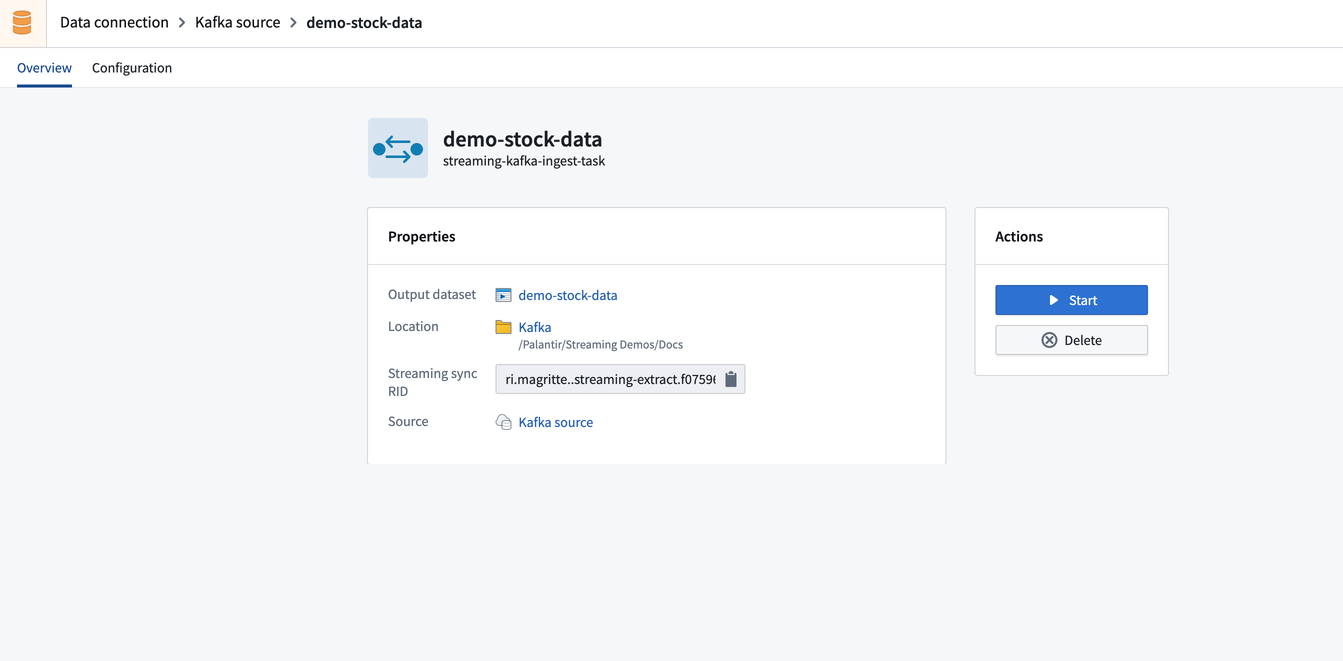
Part 4. Run the sync
Now, you are ready to run the sync. Select the Overview tab to view a summary of your new sync, including the output dataset, location, and available actions.
Click Start to begin running the sync of data from the external stream into Foundry.
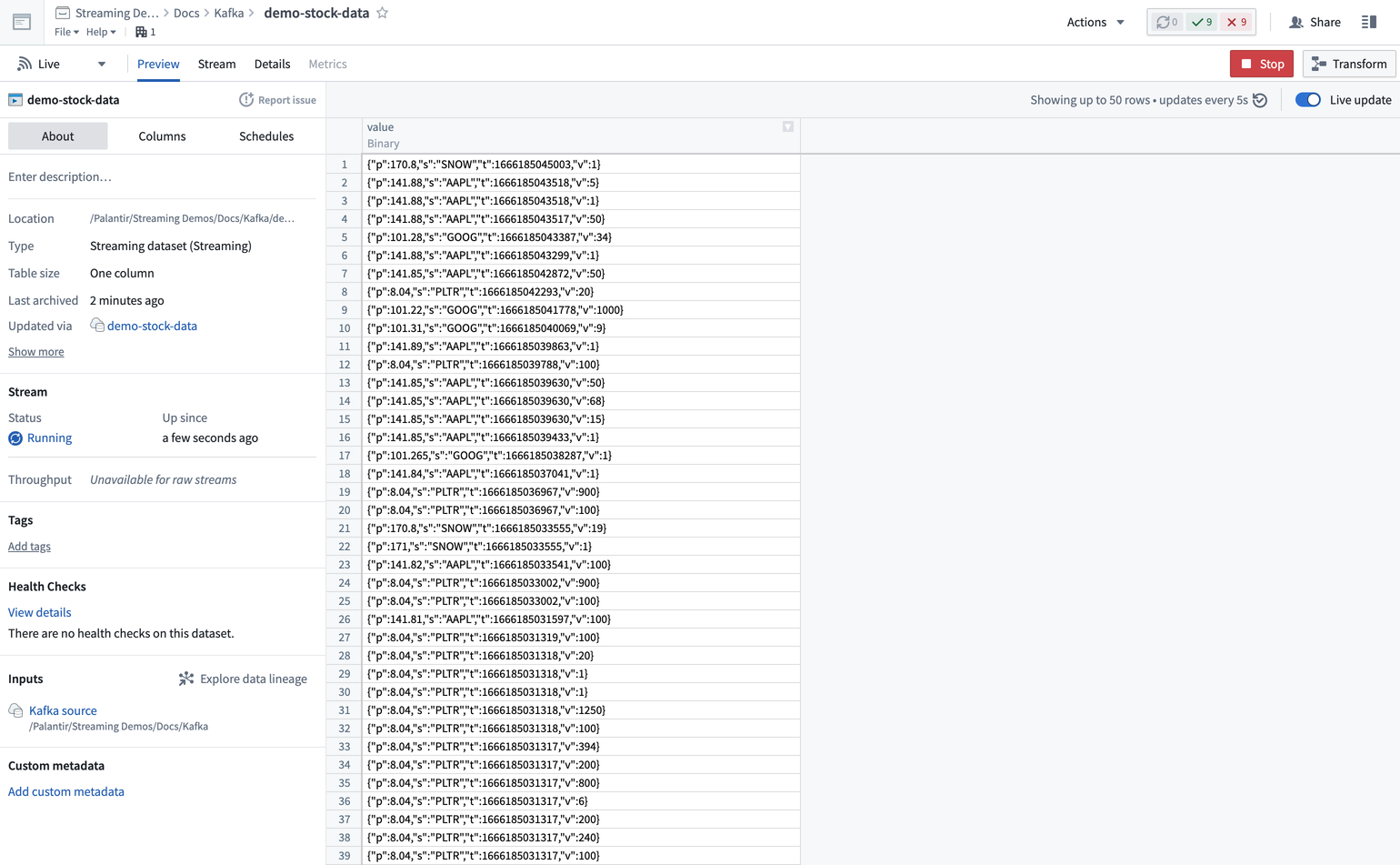
To view the stream data, navigate to the stream you configured while creating the sync to view the stream preview page. You should see records flowing from the Kafka topic in the stream.
Next steps
Now that you have successfully run a sync, learn how to debug a failing stream, push data into a stream with push-based ingestions, or integrate your stream with the Ontology.