- Capabilities
- Getting started
- Architecture center
- Platform updates
Optimize JDBC syncs
This guide provides tips to improve the speed and reliability of JDBC syncs.
If your sync is already working reliably, there is no need to take the actions described below. If you are setting up a new sync or your sync takes too long to complete or does not complete reliably, we recommend following this guide.
There are two primary methods for speeding up JDBC syncs. We recommend starting by making your sync incremental and only moving on to parallelizing the SQL query if the incremental sync is insufficient:
Incremental syncs
By default, batch syncs will sync all matching rows from the target table. Incremental syncs, by contrast, maintain state about the most recent sync and thus can be used to ingest only new matching rows from the target. This can improve sync performance dramatically for tables with a large number of rows. Incremental syncs work by adding data as an APPEND transaction to the synced dataset.
Below is an example configuration for an incremental batch sync:
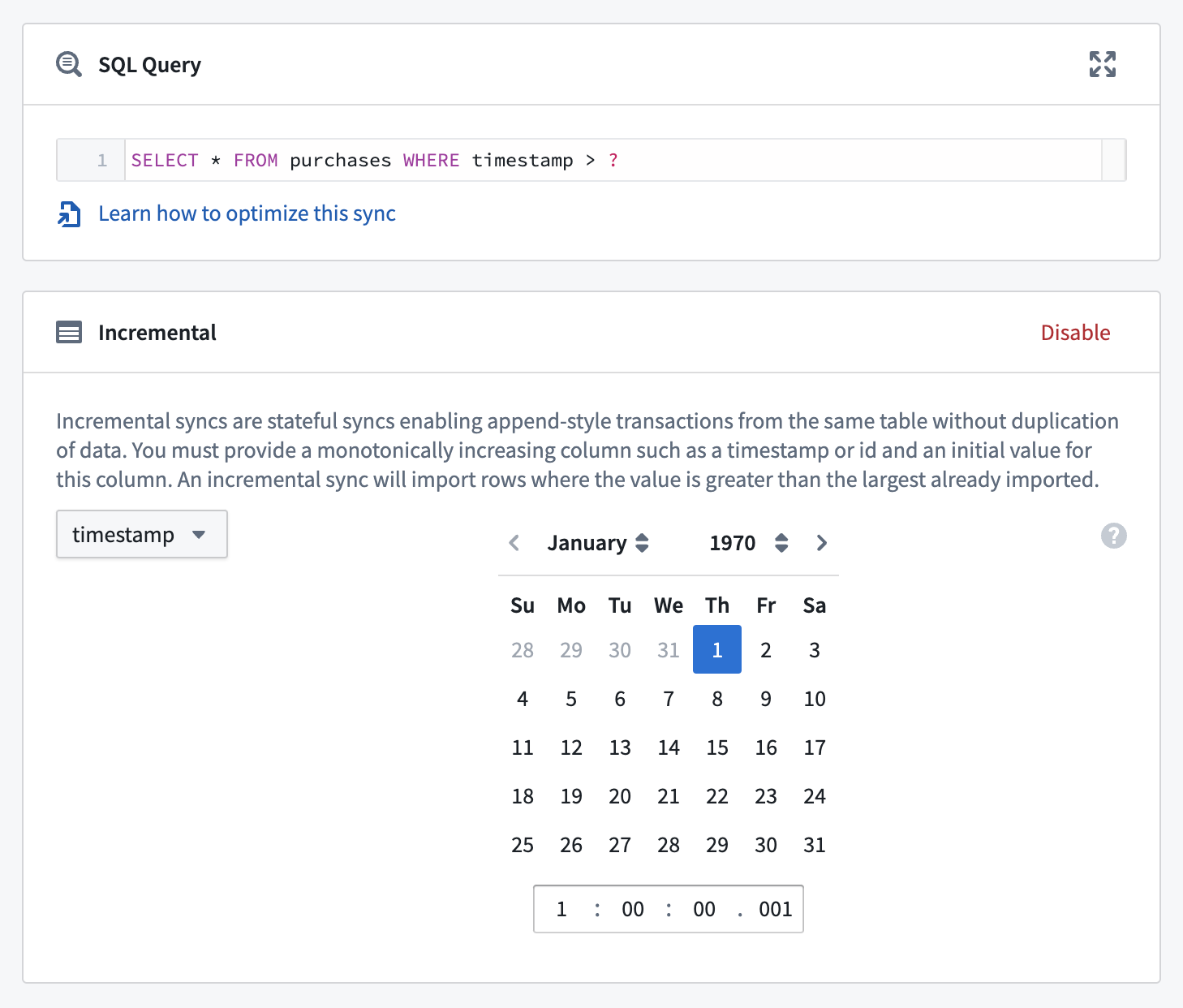
Perform the following steps to set up an incremental batch sync:
-
Navigate to the configuration page for the sync you want to convert, and ensure that the preview is working.
-
Set the transaction type to
APPEND. This is necessary to avoid overwriting rows from previous syncs. -
Select Enable in the Incremental box. Ensure that the preview has successfully run on this sync. With a working preview, the Incremental box will expand to allow you to configure the initial incremental state for the sync.
-
Configure the sync's incremental state. This state consists of an incremental column and an initial value, which can be configured in the user interface. Keep the following important considerations in mind when setting these values:
- The incremental column must be strictly increasing between syncs. If your rows are immutable (i.e., existing rows cannot be updated in place), any consistently incrementing column (e.g., an auto-incrementing ID, or a timestamp indicating when the row was added) will be sufficient. If your rows are mutable (i.e., your table allows existing rows to be updated, as opposed to only allowing new rows to be inserted), you'll need a column that increases with every mutation of the data (e.g. an
update_timecolumn). - To avoid ingesting rows more than once, the initial value of the incremental column must be greater than that of all rows synced in previous runs. For example, if the most recent
SNAPSHOTsync brought in rows with values of an integeridcolumn ranging up to1999, you could set the initial value to2000.
- The incremental column must be strictly increasing between syncs. If your rows are immutable (i.e., existing rows cannot be updated in place), any consistently incrementing column (e.g., an auto-incrementing ID, or a timestamp indicating when the row was added) will be sufficient. If your rows are mutable (i.e., your table allows existing rows to be updated, as opposed to only allowing new rows to be inserted), you'll need a column that increases with every mutation of the data (e.g. an
When you ingest an updated version of an existing row, the Foundry dataset will still include previous versions of the row (remember, we're using the APPEND transaction type). If you want only the latest version of each row, you will need to use another tool in Foundry, such as Transforms, to clean the data. Refer to the guidance on incremental pipelines to learn more.
- Finally, update the query to use the wildcard symbol
?. Exactly how you include the wildcard in the query depends on your query logic; see below for a simple example, and note the following:- In the first incremental run, this wildcard will be replaced by the initial value we specified in the previous step.
- In any subsequent run, the wildcard will be replaced with the maximum synced value of the incremental column from the previous run.
As mentioned above, the incremental state interface only works if a preview of the sync has run successfully. This means that if you are creating an incremental sync from scratch or duplicating an existing incremental sync, you will need to run a preview without the wildcard ? operator in your query.
Example
Suppose you are ingesting a table called employees, with transaction type set to SNAPSHOT and the following simple SQL query:
Copied!1 2 3 4SELECT * FROM employees
At time T1, the table looks as follows:
| id | name | surname | update_time | insert_time |
|---|---|---|---|---|
1 | Jane | Smith | 1478862205 | 1478862205 |
2 | Erika | Mustermann | 1478862246 | 1478862246 |
And suppose this table is mutable, so that at a later time, T2, it looks like this:
| id | name | surname | update_time | insert_time |
|---|---|---|---|---|
1 | Jane | Doe | 1478862452 | 1478862205 |
2 | Erika | Mustermann | 1478862246 | 1478862246 |
3 | Juan | Perez | 1478862438 | 1478862438 |
We want to convert this sync to be incremental, so we update the transaction type to APPEND.
What should we use as the incremental column? It's important to note that neither the id nor insert_time columns are appropriate to use as the incremental column because they will miss updates, like the change in the surname column of the Jane row. Instead, we should use update_time as the incremental column.
What we choose for the initial value depends on whether or not we've previously synced rows from this table. Supposing that we ran a SNAPSHOT sync at time T1 and have already synced rows with values of update_time as high as 1478862246; we should use 1478862247 as our initial value to avoid duplicates. If we never synced any rows from this table, we could use 0 (or 01/01/1970 if setting a date) as the initial value.
Finally, we change the SQL query to
Copied!1 2 3 4 5 6SELECT * FROM employees WHERE update_time > ?
The conversion is now complete. Note that after running the sync incrementally, we will have multiple Jane rows in our dataset (one for each update). As mentioned previously, we'll have to handle these duplicates in our downstream logic—in Contour or Transforms, for example.
If you run into issues with incremental JDBC syncs, this section of the troubleshooting guide may be helpful.
Parallelize the SQL query
Because the parallel feature runs separate queries against the target database, carefully consider the case of live-updating tables being treated differently by slightly differently-timed queries.
The parallel feature allows you to easily split the SQL query into multiple smaller queries that will be executed in parallel by the agent.
In order to achieve this behavior you need to change your SQL statement to this structure:
Copied!1 2 3 4 5 6 7 8 9SELECT /* FORCED_PARALLELISM_COLUMN({{column}}), FORCED_PARALLELISM_SIZE({{size}}) */ column1, column2 FROM {{table_name}} WHERE {{condition}} /* ALREADY_HAS_WHERE_CLAUSE(TRUE) */
The key parts of the query are:
FORCED_PARALLELISM_COLUMN({{column}})- This specifies the column on which the table will be divided.
- It should be a numeric column (or a column expression that yields a numeric column) with a distribution as even as possible.
FORCED_PARALLELISM_SIZE({{size}})- Specifies the degree of parallelism, e.g.
4would result in five simultaneous queries: four which split up the values for the specified parallelism column, plus a query for NULL values in the parallelism column.
- Specifies the degree of parallelism, e.g.
ALREADY_HAS_WHERE_CLAUSE(TRUE)- This specifies if there is already a
WHEREclause or if one needs to be generated. If this isFALSE,WHERE column%size = Xwill be added to each of the generated queries. If this isTRUE, this condition will instead be appended with anAND.
- This specifies if there is already a
Example
Suppose you are syncing a table called employees that contains the following data:
| id | name | surname |
|---|---|---|
1 | Jane | Smith |
2 | Erika | Mustermann |
3 | Juan | Perez |
NULL | Mary | Watts |
The basic query will look like this:
Copied!1 2 3 4SELECT id, name, surname FROM employees
This will execute a single query in the database and attempt to retrieve all records from the table.
To leverage the parallel mechanism the query can be changed to the following:
Copied!1 2 3 4 5 6SELECT /* FORCED_PARALLELISM_COLUMN(id), FORCED_PARALLELISM_SIZE(2) */ id, name, surname FROM employees /* ALREADY_HAS_WHERE_CLAUSE(FALSE) */
This will execute the following three queries in parallel:
Copied!1 2 3 4 5 6SELECT id, name, surname FROM employees WHERE id % 2 = 1
Extracting:
| id | name | surname |
|---|---|---|
1 | Jane | Smith |
3 | Juan | Perez |
and
Copied!1 2 3 4 5 6SELECT id, name, surname FROM employees WHERE id % 2 = 0
Extracting:
| id | name | surname |
|---|---|---|
2 | Erika | Mustermann |
and
Copied!1 2 3 4 5 6SELECT id, name, surname FROM employees WHERE id % 2 IS NULL
Extracting:
| id | name | surname |
|---|---|---|
NULL | Mary | Watts |
Parallelisms with a WHERE clause that contains an OR condition
When using parallelism with a WHERE clause that contains an OR condition, you should wrap conditions in parentheses to indicate how the conditions should be evaluated. For instance, examine the sync provided below:
Copied!1 2 3 4 5 6 7SELECT /* FORCED_PARALLELISM_COLUMN(col1), FORCED_PARALLELISM_SIZE(32) */ col1, col2 FROM tbl WHERE condition1 = TRUE OR condition2 = TRUE /* ALREADY_HAS_WHERE_CLAUSE(TRUE) */
This example sync will be transformed to the following:
Copied!1condition1 = TRUE OR condition2 = TRUE AND col1 % X = 0
However, that statement may be logically interpreted as condition1 = TRUE OR (condition2 = TRUE AND col1 % X = 0), rather than the desired (condition1 = TRUE OR condition2 = TRUE) AND col1 % X = 0. You can ensure the intended interpretation by wrapping the entire WHERE clause in parentheses. For the example above, this would mean:
Copied!1 2 3 4 5 6 7SELECT /* FORCED_PARALLELISM_COLUMN(col1), FORCED_PARALLELISM_SIZE(32) */ col1, col2 FROM tbl WHERE (condition1 = TRUE OR condition2 = TRUE) /* ALREADY_HAS_WHERE_CLAUSE(TRUE) */