- Capabilities
- Getting started
- Architecture center
- Platform updates
Analyze the impact of changes
Code edits may result in unexpected changes to dataset content, permissions, and structure. We recommend protecting production branches and requiring a review of proposed changes before merging; these options can be found in the branch settings. The pull request page will then offer various ways to analyze the impact of code changes on the affected datasets.
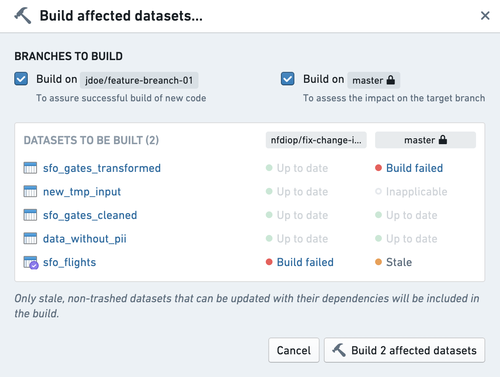
Stale datasets
Evaluating the impact of changes requires the affected datasets to be built with the most recent code changes. This build is required on both the head branch (development) and the base branch (target):
- Build on head branch (development) to validate that the code builds properly, the outputs appear as expected, and that all Data Expectations are met.
- Build on base branch (target) to compare the outputs to the latest version of the target.
The pull request page will warn you when affected datasets are stale. Clicking on Configure and build will allow you to review the stale datasets and build them on head and base branches.
The pull request page's staleness warning only covers affected datasets within a specific code repository. The pull request page does not warn about stale parent datasets outside of the repository or about uncommitted changes.
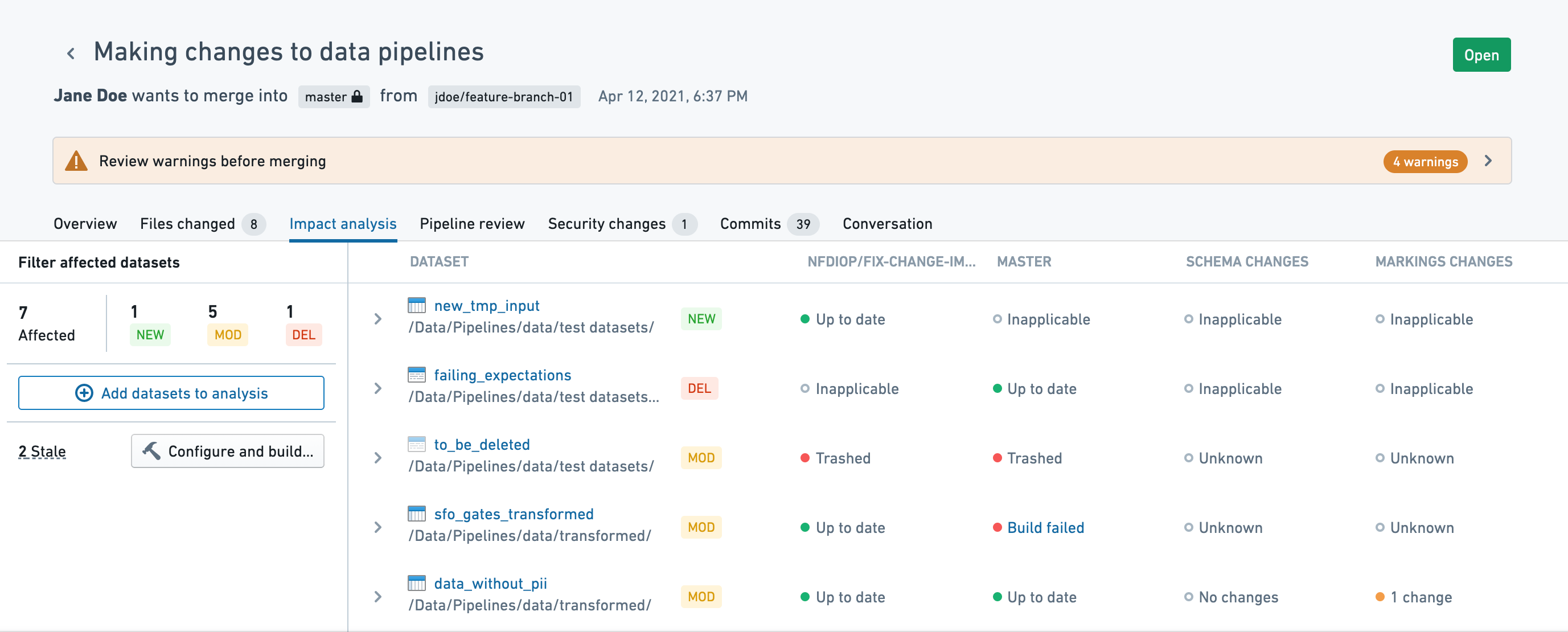
Impact analysis
The Impact analysis tab provides information on datasets affected by the pull request. By default, it will only show directly affected datasets, excluding derived datasets that may be impacted. You can inspect the impact on additional tables by clicking on Add datasets to analysis.
Reviewing affected datasets requires access to the data. Inaccessible datasets will be indicated in the UI as inaccessible.
The way a repository determines the list of affected datasets can differ depending on the language you use. Python repositories use Transforms Level Logic Versioning (TLLV) to generate the list. In Java transforms, datasets are considered directly affected if their source file is changed by the pull request.
The impact analysis tab shows the following information:
- Code - View changes to the source file (it will not include other files that may be referenced or used).
- Schema - View changes to dataset columns.
- Security - View changes to markings applied to the output dataset.
- Expectations - View the data expectations on the head branch.
- Trashed datasets - Trashed datasets that are updated by the PR will appear faded.
View impact on derived datasets
Clicking on Add datasets to analysis will analyze the pull request's impact on derived datasets. All intermediate datasets between the selected dataset and the affected datasets will be added as well.
The added datasets must not be stale in order to show impact information. Click on Configure and build to view an updated list of stale datasets and trigger a build.
Pipeline review
The pipeline review tab offers a lineage view of the datasets affected by the pull request.
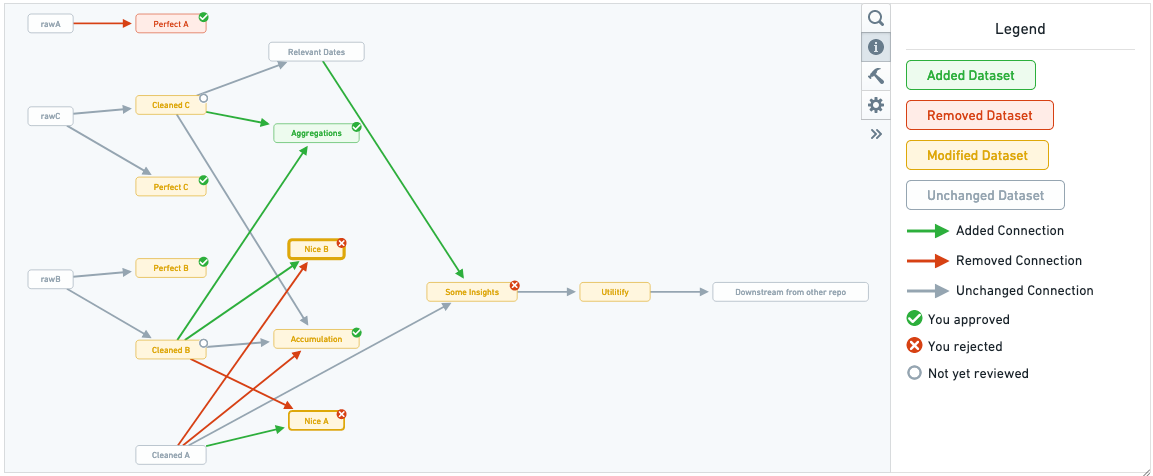
When one of the dataset nodes is selected, the changes to the transforms code file that generates this dataset is displayed along with the schema changes for each dataset generated by that code file. Navigating through the affected datasets in the order of data flow can help you understand how changes to different files and datasets correspond.
To keep track of your progress while reviewing the changes in a pull request, you can approve or reject each file individually. For transform source files, this review status is shown in the pipeline graph as an indicator on the corresponding output dataset nodes.