注: 以下の翻訳の正確性は検証されていません。AIPを利用して英語版の原文から機械的に翻訳されたものです。
概要
Data Connection は Foundry から外部システムへのデータセットやストリームのエクスポートをサポートしています。これは、さまざまな目的に役立ちます:
- データパイプラインを使用して Foundry でクリーンアップおよびトランスフォームされたデータを、データウェアハウスやデータレイクなどのシステムに同期できます。このパターンについては、「How Palantir Foundry Fuels Your Data Platform」で詳しく説明しています。
- バッチデプロイメントを使用して作成された機械学習モデルの推論結果を他のシステムにエクスポートして、組織全体でMLプロジェクトを運用化できます。
- オントロジーから取得されたエンドユーザーの操作データを、Foundry 外のシステムで分析するために書き出すことができます。
Data Connection のエクスポートは、すべてのソースタイプに対応しているわけではありません。ソースタイプの概要ドキュメントに記載されている個々のソースページを確認して、利用可能かどうかを確認してください。各ソースページには、エクスポート機能が利用可能な場合、ファイルエクスポート、ストリーミングエクスポート、テーブルエクスポート、またはレガシーエクスポートタスクサポートのいずれかが記載されます。たとえば、Amazon S3のソースタイプはファイルエクスポートをサポートしており、BigQueryのソースはエクスポートタスクを必要とします。
ファイル、ストリーミング、テーブルエクスポート機能に対応していないソースの中には、レガシーエクスポートタスクの設定をサポートしている場合があります。レガシーエクスポートタスクは、更新されたエクスポート機能を実装しているソースタイプには推奨されません。
ソースのエクスポートを有効にする
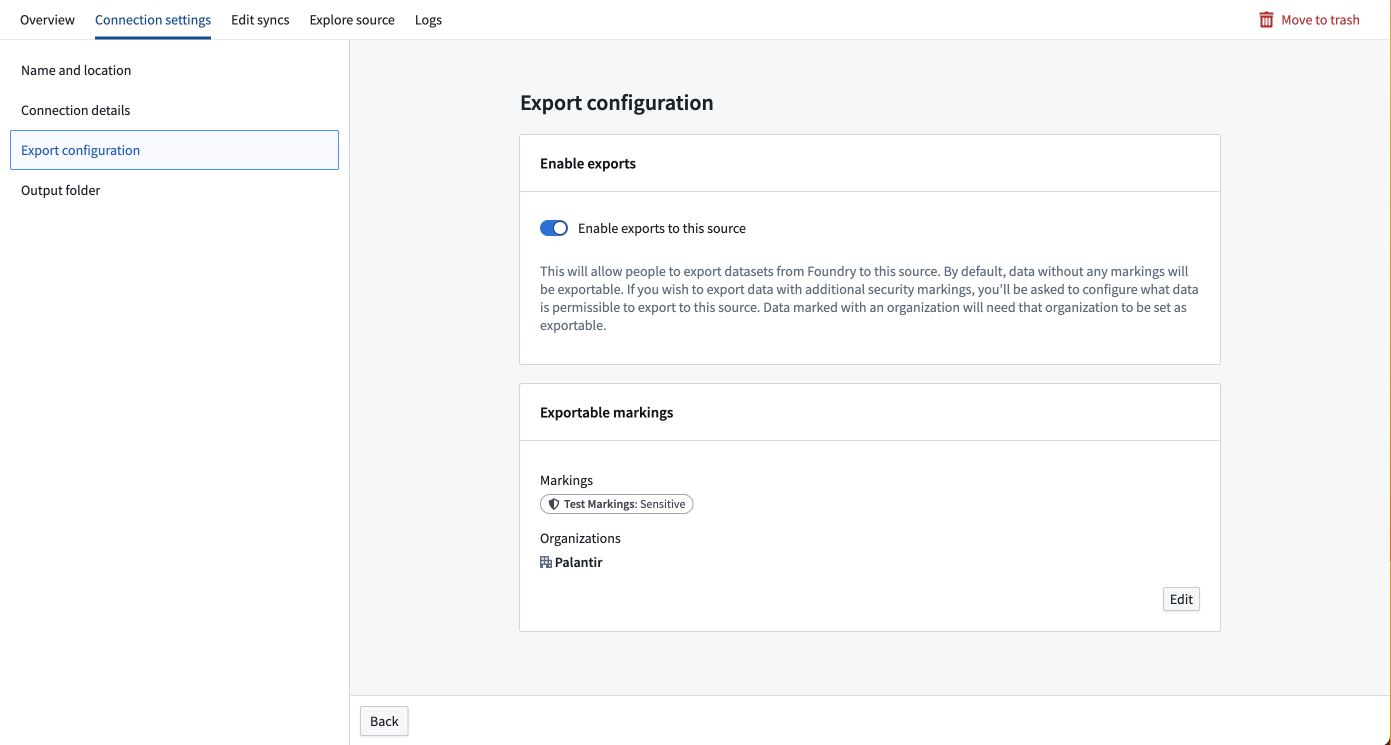
データをエクスポートするには、エクスポート先のソースの接続設定セクションでエクスポートを有効にする必要があります。エクスポートをサポートするソースタイプは、画面の左側にエクスポート設定タブを表示します。Foundry の情報セキュリティ責任者ロールを持つユーザーは、このタブに移動して、このソースへのエクスポートを有効にするオプションをオンにします。
情報セキュリティ責任者は Foundry のデフォルトロールです。Control Panelのエンロールメント権限でユーザーに情報セキュリティ責任者ロールを付与できます。
エクスポートを有効にした後、このソースにエクスポート可能なマーキングのセットを提供する必要があります。エクスポート設定にマーキングや組織が追加されていない場合、それらのマーキングや組織を含むデータはこのソースにエクスポートできません。エクスポート可能なマーキングを追加するには、ユーザーが情報セキュリティ責任者であり、エクスポートしたいマーキングや組織の解除権限を持っている必要があります。
たとえば、Palantir組織にSensitiveマーキングが付いたデータセットがある場合、このデータセットをエクスポートするには、SensitiveマーキングとPalantir組織の両方をこのソースのエクスポート可能なマーキングセットに追加する必要があります。
Data Connection のソース設定に入力された資格情報は、外部システムのテーブルに書き込みアクセス権を持っている必要があります。たとえば、S3には "s3:PutObject" 権限が必要です。他のファイルエクスポートでは、ターゲットパスが既に存在しない場合にディレクトリを作成するための特定の権限が必要な場合があります。テーブルエクスポートでは、切り捨てを行うエクスポートモードを使用する場合に追加の権限が必要な場合があります。
ソース固有の考慮事項については、ソースタイプの概要ドキュメントに記載されている個々のソースページを確認してください。
新しいエクスポートを作成する
エクスポートを作成するには、まずエクスポート先のソースの概要ページに移動します。
指定されたソースの最初のエクスポートを設定する場合、空のテーブルとエクスポートを作成するためのボタンが表示されます。

エクスポートを作成を選択し、エクスポートするデータセットまたはストリームと、ソース固有のエクスポート設定オプションを選択します。これらのオプションはソースコネクタごとに異なり、ドキュメント内の対応するソースタイプページで説明されています。エクスポートされたデータセットに複数のブランチが存在する場合、マスターブランチのデータのみがエクスポートされます。
以下の例は、S3コネクタのエクスポート設定インターフェースを示しています:
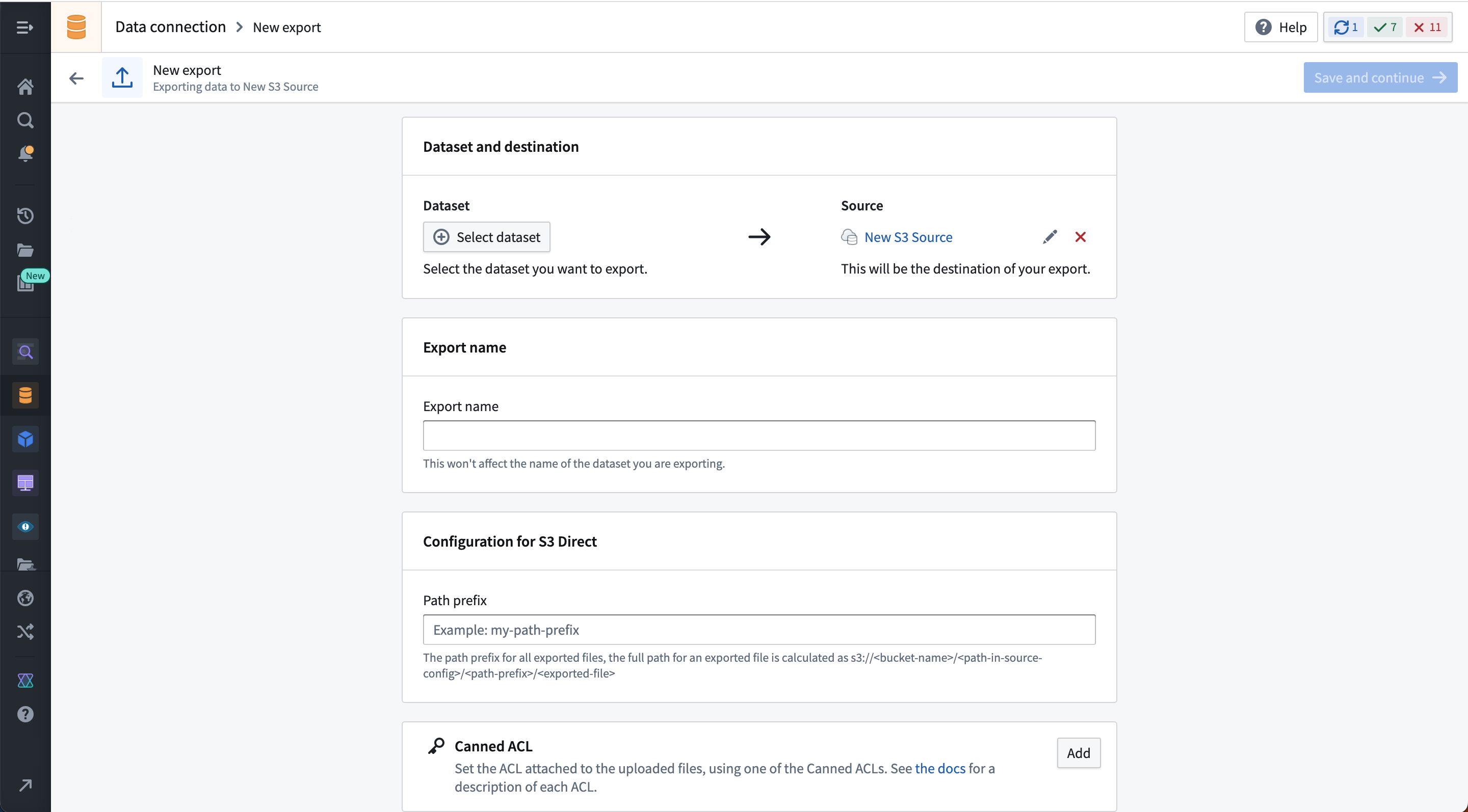
エクスポートを保存すると、次の操作が可能なエクスポート管理ページに移動します:
- エクスポートを手動で実行する。
- エクスポートのスケジュールを設定する。
- エクスポート履歴を表示する。
- 設定オプションを変更する。
ストリーミングエクスポートは、実行ボタンの代わりに開始/停止ボタンを使用します。ストリーミングエクスポートにスケジュールが設定されている場合、他のストリームのスケジュールと同様に動作します。スケジュールがトリガーされたときにストリームが停止している場合、自動的に再起動されます。スケジュールがトリガーされたときにストリームが停止していない場合、引き続き実行されます。
初期設定後に一部のソースエクスポートオプションは編集できない場合があります。変更する必要がある不変のオプションがある場合、エクスポートを削除して再作成する必要があります。
エクスポートタイプ
エクスポートの動作は、エクスポート先のシステムが受け入れるデータのタイプによって異なります。
| エクスポートタイプ | 概要 |
|---|---|
| ファイルエクスポート | スキーマのないシステムにエクスポートするために使用されます。データセットからの生ファイルがスケジュールに従ってコピーされ、ターゲットシステムに書き込まれます。 |
| ストリーミングエクスポート | イベントストリーミングをサポートするシステムに継続的にエクスポートするために使用されます。Foundry のストリームからのレコードが継続的にターゲットシステムにプッシュされます。 |
| テーブルエクスポート | スキーマを持つシステムにエクスポートするために使用されます。データセットの行がスケジュールに従ってターゲットシステムに挿入され、選択したエクスポートモードに従います。 |
ファイルエクスポート
ファイルエクスポートをサポートするシステムの例として、S3があります。
ファイルエクスポートは、選択した Foundry データセットから構成された宛先にファイルを書き込みます。デフォルトでは、上流のデータセットで最後に正常にエクスポートされたトランザクション以降に変更されたファイルのみが書き込まれます。つまり、特定のトランザクションでファイルが更新されなかった場合、次回のスケジュールされた実行または手動実行時には再エクスポートされません。
データセット全体を再エクスポートする必要がある場合、同じソースで新しいエクスポートを設定するか、上流のトランスフォームがエクスポートする必要のあるすべてのファイルを上書きするようにしてください。
デフォルトでは、宛先に既にファイルが存在する場合、エクスポートジョブはそのファイルをエクスポートされたデータで上書きします。この動作はソースタイプによって異なる場合があります。宛先システムに保存されたデータを誤って上書きしないようにするため、Foundry からエクスポートされたデータを配置する専用のサブフォルダーを作成することをお勧めします。
ストリーミングエクスポート
ストリーミングエクスポートをサポートする宛先の例として、Kafkaがあります。
ストリーミング宛先へのエクスポートは、Foundry でエクスポートジョブが実行されている限りレコードを宛先にストリームします。ジョブが停止され再起動された場合、以前の位置からレコードのストリームを再開します。
ストリーミングエクスポートのリプレイ動作
ストリーミング宛先へのエクスポートを設定する際、Foundry でストリームがリプレイされたときの望ましい動作を指定する必要があります。通常、ストリームは処理ロジックに大きな変更を加えた後にリプレイされます。この場合、以前に処理されたレコードを新しいロジックを使用して再処理する必要があります。以下のいずれかの方法で行います:
-
リプレイされたレコードをエクスポート: ストリームがリプレイされたときにすべてのレコードを再エクスポートします。以前にエクスポートされたレコードが再度エクスポートされるため、外部システムが重複を処理するように構成されている必要があります。
-
リプレイされたレコードをエクスポートしない: リプレイされたオフセットがエクスポートジョブの最新のオフセットと一致するまでエクスポートを一時停止します。リプレイされたストリーム間でオフセットが一致する保証はないため、このオプションはエクスポートされないままのレコードが発生することがよくあります。
ストリーミング宛先へのエクスポートは、直接接続ランタイムを使用している場合にはサポートされていません。エージェントプロキシまたはエージェントワーカランタイムを使用してストリーミングエクスポートを実行する必要があります。
テーブルエクスポート
2024年6月時点で、テーブルエクスポートは一般的に利用可能ですが、すべてのソースタイプで利用できるわけではありません。テーブルエクスポートがサポートされているかどうかを確認するには、Data Connection で新しいソースページにアクセスし、テーブルエクスポートタグを探すか、関連するソースタイプのドキュメントページを参照してください。
テーブルエクスポートは、既知のスキーマを持つ表形式のデータを含むシステムへのエクスポートを可能にします。外部ターゲットスキーマがエクスポートしたい Foundry データセットのスキーマと一致する場合、テーブルエクスポートは選択したテーブルエクスポートモードに従って、システム固有のINSERTステートメントまたは同等のAPI呼び出しを実行してターゲットテーブルに行を書き込みます。
テーブルエクスポートモード
選択されたエクスポートモードは、テーブルエクスポート中にデータがどのようにエクスポートされるかを指定します。すべてのテーブルエクスポートで利用可能なエクスポートモードは以下の通りで、Data Connection のエクスポート設定ページでも説明されています。
| テーブルエクスポートモード | 説明 |
|---|---|
| データセットを外部テーブルに効率的にミラーリング (推奨) | 外部テーブルは常に Foundry データセットの表示と一致します。 これは、現在のデータセットビューからエクスポートされていないトランザクションを常にインクリメンタルにエクスポートし、エクスポートされている Foundry データセットに SNAPSHOT トランザクションがある場合に外部テーブルを切り捨てることで実現されます。 このモードは、エクスポートされるデータセット内の UPDATEおよびDELETEトランザクションをサポートしていません。 |
| 切り捨てなしでデータセット全体 | 外部テーブルを最初に切り捨てずに、Foundry データセットの全ビューのスナップショットを常にエクスポートします。 注: このオプションはほとんどの場合、外部テーブルに重複が発生します。このオプションは、外部システムが各実行後に行を消費して削除する場合や、既にエクスポートされた行を再エクスポートしたい場合に有用です。 |
| 切り捨てありでデータセット全体 | このオプションはターゲットテーブルを切り捨て(削除)し、その後に現在のデータセットビューの全スナップショットをエクスポートします。 このオプションは、Foundry データセットを常にミラーリングしますが、インクリメンタルオプションよりも効率が悪いです。 このオプションは、エクスポート間に外部テーブルに編集が行われ、それを常に上書きしたい場合に有用です。 |
| インクリメンタルにエクスポート | 現在のビューからエクスポートされていないトランザクションのみをターゲットテーブルを切り捨てずにエクスポートします。 このモードは、エクスポートされるデータセット内の UPDATEおよびDELETEトランザクションをサポートしていません。このオプションは、同じデータを再エクスポートしないようにするために、APPENDトランザクションのみを含むデータセットをミラーリングします。このモードは、上流データセットにSNAPSHOTトランザクションがある場合、ターゲットテーブルに重複レコードを生成する可能性があります。 |
-- target_tableというテーブルにデータを挿入するSQL文
-- column1, column2, column3というカラムにそれぞれ'value1', 'value2', 'value3'という値を追加
INSERT INTO target_table (column1, column2, column3) VALUES ('value1', 'value2', 'value3');
ソースの種類に応じて、挿入ステートメントが 1 行または複数行のデータに対して適用されます。たとえば、Snowflake は batch inserts をサポートしているため、複数の行を一度に書き込むことができます。
-- データをtarget_tableに挿入するSQL文
-- 3つのレコードを一度に挿入します
INSERT INTO target_table (column1, column2, column3) VALUES ('value1', 'value2', 'value3'), ('value4', 'value5', 'value6'), ('value7', 'value8', 'value9');
対照的に、Apache Hive のようなソースは batch inserts を限定的にサポートしており、その後の 3 つの insert ステートメントを通じてエクスポートが行われます。
-- target_tableにデータを挿入するSQL文
-- それぞれのINSERT文は異なる行を挿入します
INSERT INTO target_table (column1, column2, column3) VALUES ('value1', 'value2', 'value3');
INSERT INTO target_table (column1, column2, column3) VALUES ('value4', 'value5', 'value6');
INSERT INTO target_table (column1, column2, column3) VALUES ('value7', 'value8', 'value9');
TRUNCATE TABLE ステートメントの例
Full dataset with truncation のようなエクスポートオプションは、まず外部ソースの対象テーブルを切り詰めてから、挿入ステートメントを実行します。これを実現するための実際のコードは、以下の例のようになります。
-- テーブルの全データを削除する
TRUNCATE TABLE table_name;
-- target_tableに新しいデータを挿入する
INSERT INTO target_table (column1, column2, column3) VALUES ('value1', 'value2', 'value3');
次のステップ
より具体的なダイアレクトが必要な場合は、Foundry のコードベースの接続オプションの 1 つをお勧めします。たとえば、外部トランスフォームなどです。
テーブルエクスポートの特別な考慮事項
- Foundry からエクスポートするデータセットは、外部ソースと 1:1 で一致している必要があり、列名(大文字小文字を区別)およびデータ型も正確である必要があります。たとえば、
COLUMN_ABCタイプLONGをタイプSTRINGのCOLUMN_ABCにエクスポートすると、実行時に失敗します。 - テーブルエクスポートを設定する際、ソースで必要な場合は
DATABASE、SCHEMA、TABLEフィールドが入力されていることを確認してください。これらのフィールドが欠けていると、実行時にエクスポートが失敗します。同様に、不必要なフィールドを含めると失敗することがあります。信頼性を高めるために、ソース内の宛先を選択する際に、ソースを探索して自動入力を使用してください。 - テーブルエクスポートでエージェント実行環境を使用する場合、エージェントは Linux ホストで実行されている必要があります。Windows エージェントはテーブルエクスポートの実行をサポートしていません。
- 表形式の宛先にエクスポートされるデータセットの基礎となるファイルは、Parquet 形式である必要があります。CSV およびスキーマをサポートする他のファイルタイプはエクスポートに失敗します。
- 宛先テーブルはソースシステムに既に存在している必要があります。Foundry によって自動的に作成されることはありません。
- 切り捨てを行うエクスポートモードを使用する場合、Foundry ソース設定に入力された資格情報には外部システムでテーブルを切り捨てる権限が必要です。
Array、Map、およびStructタイプはエクスポートに対応していません。エクスポートするデータセットにArray、Map、またはStructタイプの列が含まれている場合、エクスポートは失敗します。
エクスポートのスケジューリング
エクスポートは定期的に実行されるようにスケジュールし、最近のデータを外部宛先にエクスポートする必要があります。ストリーミングエクスポートは、単に開始または停止されるべきであり、スケジュールする必要はありません。
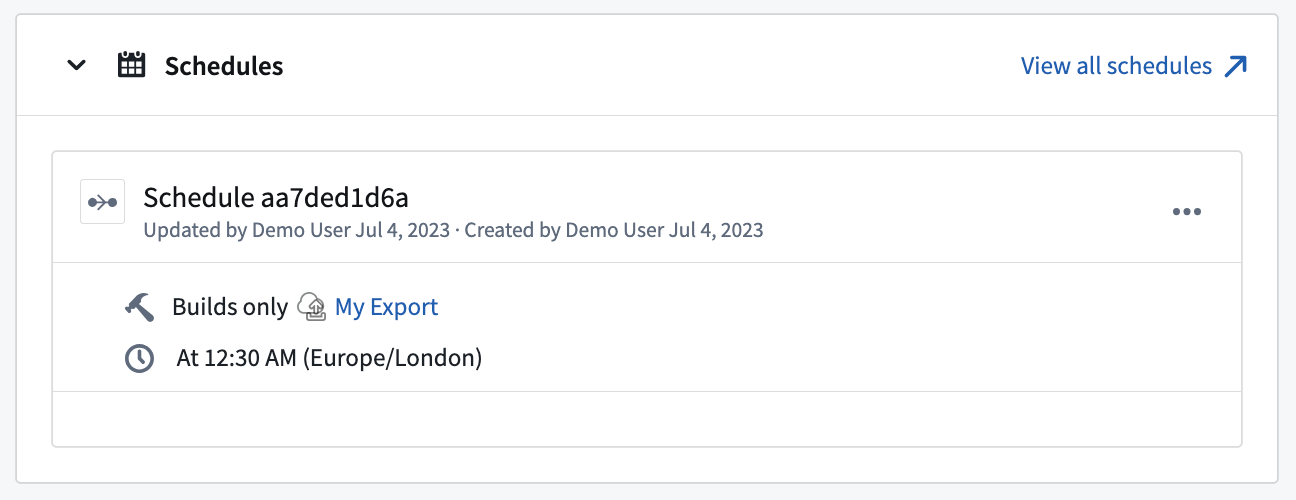
エクスポートをスケジュールするには、エクスポートの 概要 ページに移動します。次に、スケジュールの追加 を選択してエクスポートを Data Lineage で開きます。そこから、画面右側の 新しいスケジュールを作成 を選択し、他のジョブと同様に設定します。利用可能なスケジュールオプションについてさらに学びます。
特定のエクスポートをトリガーするスケジュールは、以下に示すように、エクスポートの 概要 ページで表示できます。
エクスポート履歴
同期と同様に、エクスポートは Foundry のビルドシステムを使用してジョブとして実行されます。エクスポートの 履歴 ビューには、それに関連するジョブの履歴が表示されます。各ジョブは、ジョブの詳細 セクションの右上にある ビルドレポートを表示 を選択することで開いて表示できます。
ストリーミングエクスポートの場合、エクスポート履歴にはストリーミングエクスポートジョブが現在実行中か停止中かも表示されます。
エクスポートデータのトランスフォーム
一般的に、エクスポートジョブの一部として実行されるデータトランスフォームはエクスポートではサポートされていません。つまり、エクスポートするデータセットまたはストリームは、フィルター処理、名前変更、再パーティションされたファイル、およびその他のデータのトランスフォームを含めて、既に望ましい形式である必要があります。
Pipeline Builder および Code Repositories はデータトランスフォームパイプラインを構築するための Foundry のツールであり、ジョブのスケーラビリティ、監視、バージョン管理、および必要に応じて任意のロジックを書く柔軟性を含む、データをエクスポートのために準備するために必要な完全なツールを提供します。
Kafka へのエクスポート時にストリームレコードの Base64 デコードを許可することが可能です。Kafka エクスポートの詳細については、完全な Kafka コネクタドキュメントを参照してください。
エクスポートとエクスポートタスクの違い
テーブルエクスポートは、公開された製品ライフサイクルに従って最終的に廃止される予定の エクスポートタスク を完全に置き換えることを目的としています。エクスポートタスクによって提供される機能の多くは新しいエクスポートオプションで利用できますが、機能や設定にいくつかの違いがあります。
エクスポートタスクからテーブルエクスポートへの移行
エクスポートタスクから新しいエクスポートオプションへの移行は手動で行う必要があります。以下に記載されているオプションを使用してエクスポートを設定し、新しいエクスポートプロセスが期待通りに動作することを確認したら、以前使用していたエクスポートタスクを手動で削除します。
エクスポートタスクで利用可能な機能が新しいエクスポートで同等のオプションを持たない場合、推奨される移行方法は 外部トランスフォーム を使用することです。外部トランスフォームは、外部システムと対話するカスタムロジックを実行するための柔軟な代替手段を提供し、UI 設定オプションが必要な機能をカバーしていない場合に使用されることを意図しています。
エクスポートとエクスポートタスクの機能比較
| エクスポートタスクオプション | 新しいエクスポートでサポートされているか? | 詳細 |
|---|---|---|
parallelize: <boolean> | ソースタイプによる | これはソースごとに関連する場合があり、サポートがある場合はソース固有のエクスポート設定で文書化されます |
preSql: <sql statements> | サポートされていない | この機能が必要な場合は、外部トランスフォームを使用してください。 |
stagingSql: <sql statements> | サポートされていない | この機能が必要な場合は、外部トランスフォームを使用してください。 |
afterSql: <sql statements> | サポートされていない | この機能が必要な場合は、外部トランスフォームを使用してください。 |
manualTransactionManagement: <boolean> | サポートされていない | この機能が必要な場合は、外部トランスフォームを使用してください。 |
transactionIsolation: READ_COMMITTED | 設定不可 | これはソース設定オプションとして利用可能であり、エクスポートを実行する際に適用されます。設定オプションが利用可能かどうかを確認するには、ソース固有のドキュメントを確認してください。 |
datasetRid: <dataset rid> | サポートされている | エクスポートするデータセットまたはストリーム |
branchId: <branch-id> | 設定不可 | データは常に master ブランチからエクスポートされます。 |
table:database: mydb # Optionalschema: public # Optionaltable: mytable | サポートされている | これらのオプションは、JDBC ソースのテーブルエクスポートに特有のものです。 |
writeDirectly: <boolean> | 設定不可 | 新しいエクスポートは常に writeDirectly: true と同等のオプションを使用します。 |
copyMode: <insert|directCopy> | 設定不可 | 新しいエクスポートは常に copyMode: insert と同等のオプションを使用します。 |
batchSize: <integer> | ソースタイプによる | バッチサイズは JDBC ソースのエクスポートでサポートされていますが、他のソースタイプではサポートされていない場合があります。 |
writeMode: <ErrorIfExists|Append|Overwrite|AppendIfPossible>incrementalType: <snapshot|incremental> | サポートされている | これらのオプションは、上記で文書化されたテーブルエクスポートモードに類似しています。すべての組み合わせがエクスポートタスクに対して有効であるわけではなく、組み合わせはテーブルエクスポートに提供される 6 つのモードに正規化されています。 |
exporterThreads: <integer> | サポートされていない | エクスポータースレッドを細かく制御する必要がある場合は、外部トランスフォームを使用してください。 |
quoteIdentifiers: <boolean> | サポートされていない | このオプションはターゲットシステムにテーブルを作成する際にのみ関連しますが、新しいエクスポートではサポートされていません。テーブルはエクスポートを設定する前に存在している必要があります。 |
exportTransactionIsolation: READ_UNCOMMITTED | 設定不可 | transactionIsolation: READ_COMMITTED と同様に、トランザクション分離はソース設定から取得され、設定されている場合に適用されます。 |