注: 以下の翻訳の正確性は検証されていません。AIPを利用して英語版の原文から機械的に翻訳されたものです。
推奨されるプロジェクトとチームの構造
このページでは、Projectsを使用してFoundryでdata pipelineを構築する際の推奨される構造を概説します。これにより、以下が可能になります。
- パイプライン全体で整理された権限
- 役割間での効果的な共同作業
- 読みやすく保守性の高いパイプライン構造
また、プロダクション環境での成功したパイプライン管理に必要な役割と責任の範囲についてもカバーしています。
これは、各パイプラインステージとその目的についての概念的な概観を提供します。Foundryでこの構造を設定する方法についてのステップバイステップのガイドについては、Platform Security documentationのSecuring a data foundationを参照してください。
パイプラインステージ
これらのステージは、整然としたパイプラインを構成するプロジェクトの論理的な分離を定義します。以下でそれぞれについて詳しく説明します。
- Data Connection: ソースシステムからの生のデータを
Datasource Projectに同期します。 - Datasource Project: 論理的なデータソースごとに1つの
Datasource Projectが定義され、各生データセットの基本的なクリーンアップステップが適用され、一貫したスキーマが適用されます。 - Transform Project: データセットは1つまたは複数の
Datasource Projectsからインポートされ、変換されて正規化された、再利用可能なデータセットが生成されます。 - Ontology Project: データセットは1つまたは複数の
Transform Projectsからインポートされ、変換されて正規化されたテーブルが生成され、それぞれが離散的な運用オブジェクトを表します。単一のオントロジープロジェクトは、管理を容易にするために、特定の運用ドメインに関連するオブジェクトのセットをしばしばグループ化します。 - Workflow Project: Workflow ProjectsはOntology Projectsからデータをインポートして特定の結果を追求します。これは頻繁に運用ワークフロー、データサイエンスの調査、ビジネスインテリジェンスの分析とレポート、またはアプリケーション開発プロジェクトであることが多いです。
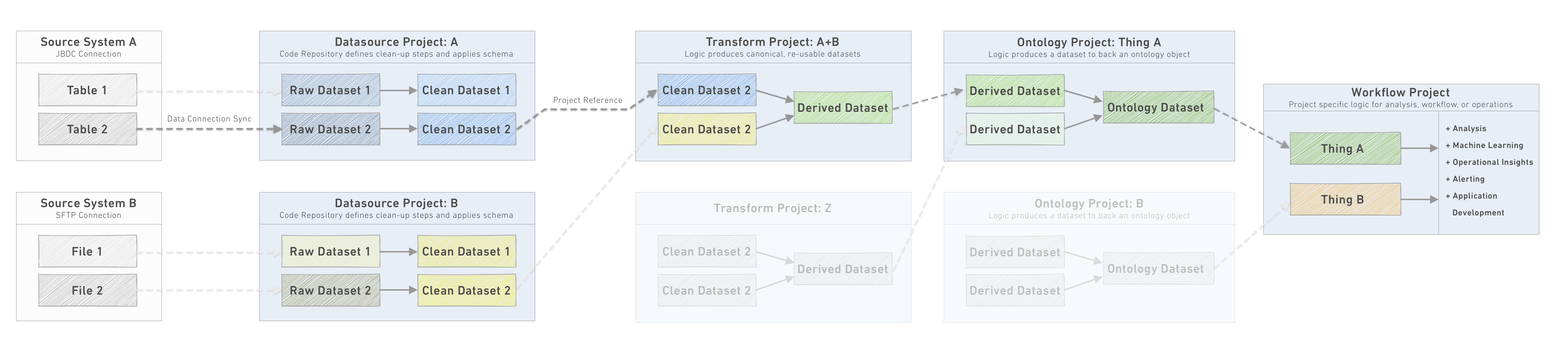
各パイプラインステージは独立したユニットであり、その出力は、他のユースケース、パイプライン開発、分析などに使用するために、下流のプロジェクトがインポートして使用できるデータセットです。各プロジェクト内では、変換ステップの実装に加えて、責任を持つチームは、出力の安定性と整合性を管理する必要があります。これには、ビルドスケジュールの管理、データヘルスチェックの設定と監視、関連する場合はunit testsまたは追加のデータ整合性テストの作成が含まれます。
以下のセクションでは、パイプラインを通じてデータのフローを追うために、各下流のプロジェクトタイプについて詳しく説明します。パイプラインを設計する過程で、オントロジーレイヤから逆算して必要なソースシステムを接続し、実装するパイプライン変換を決定します。
Projectsは、Foundry内のデータとコードを整理する手段を提供します。これらは、特定の作業範囲を中心に共同作業を行う個人やチームのアクセスと権限を管理する主要なユニットです。また、Projectsは、プロジェクト活動のイベントログ、プロジェクトのドキュメンテーション用のスペース、プロジェクトのリソース消費と計算メトリクスなど、メタデータをキャプチャし共有する機能を公開します。
良いプロジェクトが何であるかを考える際には、良いマイクロサービスが何であるかという類推を考えてみてください:明確に定義された目的、下流の依存関係が使用する明確な出力データセット/API、プロジェクト管理のための自身の基準を設定し、効果的に連携できる十分に小さな人々の集団による所有権。
新しいプロジェクトを作成するか、既存のものにビルドするかを決定する際には、次の点を考慮してください:
- プロジェクトはCode Repositoriesと1:1であるべきです。広範なスコープはより深い協力を可能にしますが、摩擦のないバージョン管理を確保するためには、より高度な運用要件が発生します。
- プロジェクトは、関連リソースすべてに対するファイル構造と権限を課すレベルであるべきです。単一の概念的な "プロジェクト" が個々の権限を必要とするサブコンポーネントを持っている場合は、Foundry内で複数のプロジェクトを作成することを検討してください。
1. データ接続
Foundry内のパイプラインを通過するデータは通常、外部のソースシステムから来るものです。Data Connectionサービスは、ソースシステムが登録される管理インターフェースを提供します。各ソースシステムに対して、1つ以上の個別の同期が設定され、データがDatasource Projectのrawデータセットに陸揚げされます。
ソースシステムや同期を初めて設定するためには、通常、Agent AdministratorがData Connection Agentを設定する必要があります。各エージェントは、Agent Administratorsのみがアクセス可能な専用のプロジェクトに保存するべきです。
新しいデータソースの新しい接続の管理は、Datasource Owner、Agent Administrator、およびDatasource Developerの共同作業を必要とする多分野の努力であり、しばしばCompliance/Legal Officerがソースシステムからのデータの移動を新しい環境に承認する必要があります。
ただし、ソースシステムが設定されていれば、Datasource Developerは個々の同期を自己完結的に設定することができます。これにより、チーム間のやり取りが大幅に減少し、新しいシステムの接続が一度限りの労力となります。
各接続において重要な考慮事項は、SNAPSHOT、つまり各同期で現在のデータを置き換えるか、APPEND、つまり各同期で既存のデータに累積的に追加するかを選択することです。これらの概念をより完全に理解し、効率的でパフォーマンスの高いパイプラインを作成するための影響を理解するには、Incremental pipelinesセクションを参照してください。
さらなる読み物
データソースと同期の原理、アーキテクチャ、設定についての詳細は、Data Connection documentationをご覧ください。
接続を監視し、パイプラインに流れるデータが正確で期待通りであることを確保するための考え方については、Maintaining pipelinesセクションをご覧ください。
2. データソースプロジェクト
各ソースシステムは、プラットフォーム内の対応するプロジェクトにデータを陸揚げするべきです。通常のパターンでは、各同期のデータを可能な限り 'raw' の形式で陸揚げします。 "clean" データセットへの変換ステップは、プロジェクトの_Code Repository_で定義されます。
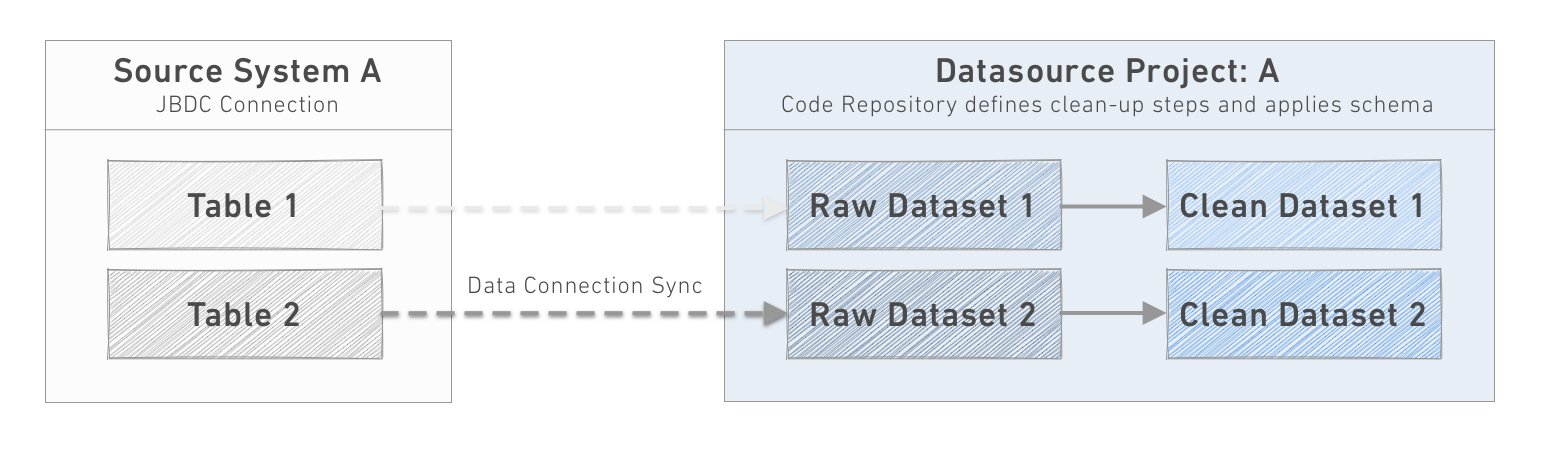
このデータソースごとのプロジェクトモデルを確立することには、多くの便利な利点があります:
- 新しいデータソースの探索を一貫した場所で奨励します。
- データソースへのアクセスコントロールを指定する単一の場所を提供します。
- 同じデータを異なるチームが同期するという労力の重複を最小限に抑えます。
- Code Repositoriesは小さく、ソースシステムのデータのタイプと形式を処理するために特別に設計されています。
- パイプラインレイヤーにアクセスする前にデータの匿名化、クリーンアップ、標準化を可能にします。
データソースプロジェクトの目標
各データソースプロジェクト内では、同期したデータを組織全体の多様なユーザー、ユースケース、パイプラインで消費するために準備することが目標です。
出力データセットとそのスキーマは、APIと考えるべきです。つまり、それらが論理的に整理され、時間の経過と共に安定していることが目標となるでしょう。なぜなら、データソースプロジェクトからの出力データセットは、すべての下流の作業の基盤であるからです。出力はソーステーブルまたはファイルと1:1で対応するべきであり、データセットの各行はソースシステムの直接一致する行を持つべきです。
このため、raw → clean 変換の一般的な目標には以下のようなものがあります:
- 一貫した列命名スキーマを適用します。
- 適切なタイプが列に適用されていることを確認します。
- 不足している、形式が間違っている、または誤った型の値を処理します。
- 主要なData Healthチェックを確立します。
- PII(Personally Identifiable Information)や一般的な利用に不適切な他の機密データを削除します。
ソースシステムが列のデータ型情報を提供している場合でも、値をSTRING型として取り込むことが必要なことがあります。特にDATE、DATETIME、およびTIMESTAMP型に注意を払ってください。これらはソースシステムで非標準の形式で表現されることがよくあり、数値型も時折問題を引き起こします。これらの型がソースシステムからの形式が不安定であることがわかった場合、STRING型としてインポートすることで、より堅牢なパースを実装し、形式が間違っている値の処理ロジックを定義するか、使用できないまたは重複した行を削除するオプションを提供します。
これらのプログラムステップに加えて、クリーンなデータセットは厳密に文書化されるべきです。データセットの定性的な説明、ソースシステムの出自、適切な連絡先と管理プロトコル、および関連する場合は、データの特性を説明する列ごとのメタデータなどが、将来の開発者がデータを適切に使用することを確保します。
データソースプロジェクトの実装
- システム管理者が目標のデータソースの新しいプロジェクトを作成し、適切なDatasource Developersを新しいuser groupに追加してプロジェクトを管理します。
- 特定のデータソースのデータソース開発者グループのメンバーだけが、プロジェクト内でデータセットをビルドする権限を持つべきです。
- Datasource OwnerとAgent Administratorが協力して、ソースシステムにData Connection Agentをデプロイし、UIでデータソース接続を設定します。
- データソース開発者がソースシステム内のテーブルとファイルをプレビューできるように、適切な権限が設定されていることを確認します。
- Datasource Developersは、プロジェクト内で1つ以上の生のデータセットのための同期を設定します。これには、適切な同期間隔と同期タイプの選択、および各生のデータセットに対する適切なData Healthチェックの追加が含まれます。
- Datasource Developersは、他のプロジェクトで使用する準備ができた "clean" データセットを生成するためのクリーンアップ変換を実装します。
- 下流の開発者は、ソースシステムからの新しいデータセットのリクエスト、クリーンデータセットの強化、またはデータ品質の問題を報告するために、プロジェクトまたは特定のクリーンデータセットに対してIssueを提出します。
すべてのデータソースはある程度独自のものとなるでしょうが、ソースシステムのクリーニングと準備のステップは、生の文字列値を特定の型に解析し、エラーを処理するなど、共有のステップを持つことがよくあります。データソースに類似のクリーンアップ変換が多数ある場合、Pythonでライブラリを定義して、一貫したツールセットを提供し、重複したコードを減らすのがベストプラクティスです。
推奨されるフォルダー構造
/raw:データ接続同期からのデータセット用。/processed(オプション):非表形式のファイルから表形式のデータを作成するためのファイルレベルの変換。/clean:/rawのデータセットと1:1のデータセット用ですが、クリーニングステップが適用されています。/analysis:クリーンアップ変換のテストまたはドキュメント化を行うために作成されたリソースと、データの形状を表示します。/scratchpad:クリーンアップ変換の構築またはテストの過程で作成された一時的なリソース。/documentation:クリーンアップのためのパイプラインステップを示すData Lineageグラフと、Foundry Notepadで書かれた追加のドキュメンテーション(プロジェクトの最上位レベルのREADMEを超えて)。
3. Transform プロジェクト
Transform プロジェクトの目標は、データの意味的に意味のあるグループをカプセル化し、オントロジー層にフィードするための標準的なビューを生成することです。
これらのプロジェクトは、1つ以上のデータソースプロジェクトからクリーニングされたデータセットをインポートし、値を拡張するためにルックアップデータセットと結合し、オブジェクト中心または時間中心のデータセットを作成するために関係を正規化または非正規化し、または標準的な共有メトリクスを作成するためにデータを集約します。
推奨されるフォルダー構造
/data/transformed(オプション):これらのデータセットは、変換プロジェクトの中間ステップの出力です。/output:これらのデータセットは、変換プロジェクトの「出力」であり、下流のオントロジープロジェクトで依存すべき唯一のデータセットです。
/analysis:クリーンアップ変換のテストまたはドキュメント化を行うために作成されたリソースと、データの形状を表示します。/scratchpad:クリーンアップ変換の構築またはテストの過程で作成された一時的なリソース。/documentation:クリーンアップのためのパイプラインステップを示すData Lineageグラフと、Notepadで書かれた追加のドキュメンテーション(プロジェクトの最上位レベルのREADMEを超えて)。
4. オントロジープロジェクト
オントロジーは、Foundry全体で共有のコミュニケーションレイヤー - しばしば「セマンティックレイヤー」と呼ばれます - を強制し、クリーンで整理された安定したオントロジーの作成は、多様な価値のあるプロジェクトが同時に進行しつつ共通の運用画像を豊かにするための最上位の目標です。オントロジーの設計と管理の概念と実践については、オントロジーの概念ドキュメンテーションを参照してください。
オントロジープロジェクトは、任意のパイプラインの中心点であり、オントロジーで定義された単一または関連グループのオブジェクトの定義に準拠したデータセットを生成するために必要な最終変換を表します。これらのプロジェクトはまた(別個に)オブジェクトエクスプローラビューをバックアップするために同期されたデータセットを生成します。
オントロジーデータセットは、それらが表現する運用オブジェクトについての正規の真実を表すため、すべての「消費」プロジェクトの出発点となります。上流のクリーニングとパイプラインステップの出自と変換ロジックは可視化されていますが、概念的にはこれらのステップと中間データセットは、オントロジープロジェクトからのみデータを消費するプロジェクト開発者、アナリスト、データサイエンティスト、運用ユーザーにとってはブラックボックスになる可能性があります。この意味で、オントロジーレイヤーは運用オブジェクトのAPIとして機能します。
オントロジープロジェクトの実装
データソースプロジェクトと同様に、オントロジープロジェクトを維持するための重要な要素は以下の通りです。
- 頑健なドキュメンテーション
- 意味のある健康チェック
- 定期的なスケジュール
- Data Catalogでのキュレーションと適切なタグ
これらについては、パイプラインの維持と、以下のプロジェクトのドキュメンテーションについてのコールアウトで詳しく説明されています。
さらに、オントロジーがより頑健になり、より多くのチームがオントロジーレイヤーに貢献するにつれて、データセット「API」の整合性を維持することがますます重要になります。このため、提案された変更が出力データセットスキーマの整合性を保つことを確認するために追加のチェックを実装することを検討してください。これについては、近日公開予定の追加のドキュメンテーションで詳しく説明します。
推奨されるフォルダー構造
/data/transformed(オプション):これらのデータセットは、オントロジープロジェクトの中間ステップからの出力です。/ontology:これらのデータセットは、オントロジープロジェクトの「出力」であり、ユーザーケースまたはワークフロープロジェクトの下流で依存すべき唯一のデータセットです。
/analysis:クリーンアップ変換のテストまたはドキュメント化を行うために作成されたリソースと、データの形状を表示します。/scratchpad:クリーンアップ変換の構築またはテストの過程で作成された一時的なリソース。/documentation:クリーンアップのためのパイプラインステップを示すData Lineageグラフと、レポートで書かれた追加のドキュメンテーション(プロジェクトの最上位レベルのREADMEを超えて)。
5. ワークフロープロジェクト
ワークフロープロジェクト、別名 ユーザーケースプロジェクトは、手元の状況に対して柔軟に設計されるべきですが、通常は単一のプロジェクトまたはチームを効果的な協力の単位として周りに構築し、責任とアクセスの境界を明確にします。
一般的に、ワークフロープロジェクトはオントロジープロジェクトからデータを参照するべきです。これにより、運用ワークフロー、ビジネスインテリジェンス分析、およびアプリケーションプロジェクトすべてが世界の共通のビューを共有します。ワークフロープロジェクトを開発する過程で、オントロジー層で利用可能なデータソースがソースとして十分でないことが示された場合、オントロジーを豊かにし、拡張する必要があります。パイプラインのより早い(または遅い)段階からデータを参照することは避けてください。これは特定のタイプのデータの真実の源を分断する可能性があります。
各プロジェクトは、開発プロセス全体で徹底的にドキュメント化されるべきです。ここにいくつかの一般的なパターンとベストプラクティスを示します:
- 最も重要なデータセットとパイプラインの関係を捉えるために、各プロジェクトのルートに1つ以上のData Lineageグラフリソースを保存します。異なるグラフは、データの再読み込みの定期性、関連するデータセットのグループ化、またはデータセットの特性(例えば、サイズ)など、関連する特徴を強調するために異なる色のスキームを使用することができます。
- プロジェクトに短い説明を追加します - プロジェクトタイトルの直下で利用可能です。これは全てのプロジェクトのリストビューで使用されます。それについてあまり詳しくないユーザーに対してプロジェクトを文脈に置くことに焦点を当てます。
- トップレベルのプロジェクトフォルダーの右サイドバーの ドキュメンテーションを追加 ボタンを使用して、Markdown の構文を書きます。これはプロジェクトの目的、主要な出力、プロジェクトの消費者にとって他の関連情報を説明する最適な場所です。
- さらにグローバルなプロジェクトのドキュメンテーションを、ローカルで作成されたMarkdown(.md)ファイルに配置し、ドキュメンテーション フォルダーにアップロードするか、Notepadに配置し、これらをトップレベルのドキュメンテーションからリンクします。
- プロジェクトのコードリポジトリにREADME.mdファイルを追加し、各変換ファイルに説明と追加のインラインコードコメントがあることを確認します。
推奨されるフォルダー構造
ワークフロープロジェクトの構造は他のプロジェクトタイプよりも多様であり、主要なリソースがすぐにアクセス可能でよくドキュメント化されていることに焦点を当てるべきです。
/data/transformed(オプション):これらのデータセットは、ワークフロープロジェクトの中間ステップからの出力です。/analysis(オプション):これらのデータセットは、分析ワークフローからの出力です。/model_output(オプション):これらのデータセットは、モデルワークフローからの出力であり、モデルの適合性を判断するために分析することができます。/user_data(オプション):ワークフローがユーザーが自分自身の「スライス」のデータを作成することを可能にする場合、ユーザー固有のフォルダーにそれらを保存します。
/analysis:意思決定とフィードバックループを推進するために作成されたリソースとレポート。/models:作成されたすべてのモデルはここに保存されるべきです。/templates:プロジェクト固有の使用のために共有されるCode Workbookのテンプレートはここに保存されるべきです。
/applications:追加のワークフローアプリケーションやサブアプリケーションはここに保存されます。主要なアプリケーションは、目立つアクセスのためにプロジェクトのルートに保存する必要があります。/develop:開発中のアプリケーション、新しい機能、テンプレートはここに保存されます。
/scratchpad:クリーンアップ変換の構築またはテストの過程で作成された一時的なリソース。/documentation:クリーンアップのためのパイプラインステップを示すData Lineageグラフと、レポートで書かれた追加のドキュメンテーション(プロジェクトの最上位レベルのREADMEを超えて)。
パイプライン管理の役割
以下の役割は、Foundryでのパイプラインの範囲設定、設計、実装、および管理に一般的に関与するプロフィールの例です。すべての役割がすべての状況で必要というわけではなく、特にプラットフォーム開発の初期段階では、個々の人が一度に複数の役割を果たすこともあります。しかし、一般的にこれらの役割の説明とそれらがどのように相互作用するかを考慮することで、順序立てられた効果的なチームを作成するのに役立ちます。
以下の図は、主要な役割を最も一般的に活動するパイプラインのセグメントに関連付けています。

主要な役割
- エージェント管理者:エージェント管理者は、データ接続の エージェント の作成と設定、およびそれを関連する データソース所有者 と共有する責任があります。これにより、エージェントのインストールと設定の制御が集中化され、セキュリティとコントロールが向上します。
- データソース開発者:データソース開発者は、データレイクに関連する各データソースのソーシングプロセスを所有するエンジニアです。これは単一のチームで行うことも、ソースシステムごとに分割することもできます。
- 各データソース開発者は、(1) データソースとデータソースの技術的な接続を持つData Connectionデータソースと、(2) 同期されたデータがソースとされるFoundryプロジェクトを所有します。
- データソースプロジェクトの出力は、1つ以上の下流のユーザーケースプロジェクトによる消費の準備が整った、クリーニングと準備が行われたデータセットです。データソース開発者はまた、自分が所有する各データソースの再読み込み頻度を定義し、リリースマネージャーまたはオペレーションマネージャーと共に パイプラインビルドポリシー をスケジュールします。
- データパイプライン開発者:データパイプライン開発者は、すべてのユーザーケースに使用するデータアセットを提供する共通のオントロジーレイヤーを構築する責任を持つデータエンジニアです。データパイプライン開発者はこのセマンティックレイヤーを定義し、ソース構造からオントロジー構造への変換を構築する責任があります。
- リリースマネージャー:リリースマネージャーは、製品パイプラインを所有し、リリースプロセスを管理し、製品パイプラインが組織の標準に従い、確実に実行されることを確認します。
- パイプラインへのコード変更については、これは通常、マスターにプルリクエストを承認するプロセスと、マスターでパイプラインビルドを実行するための承認を通じて行われます。継続的な信頼性については、リリースマネージャーは、パイプラインとデータソース開発者と協力して定義したキーデータセットの Health Checks を監視します。
- コンプライアンスオフィサー / リーガルオフィサー:コンプライアンスオフィサーは、ユーザーケースが開発される前にそれらを承認する責任があります。そのような承認は、次のことを考慮に入れるべきです:(1) 使用する必要があるデータ、(2) プロジェクトの目的、および (3) 彼らの管轄地域のデータ保護体制と組織自体のポリシーを考慮した場合の、データへのアクセスを持つユーザー。
- ユーザーケース開発者:ユーザーケース開発者は、ユーザーケースの開発を所有するエンジニア - ソフトウェア開発者および/またはデータサイエンティスト - です。彼らはオントロジーレイヤーからソースとされ、コンプライアンスオフィサーによって彼らに承認されたデータを使用します。
その他の役割
- オペレーションマネージャー:この役割は、製品パイプラインの健全な実行の監視を所有しています。彼らは異なるソースのデータ再読み込み、異なるパイプラインのビルドの実行、サポートリクエストのトリアージを監視します。この役割は、リリースマネージャーをサポートします。
- パーミッションオーナー / アイデンティティマネージャー:ほとんどのケースでは、ユーザーをグループに割り当てるプロセスは、顧客のアイデンティティ管理システムで管理され、その情報はSAMLインテグレーションを通じてFoundryに渡されます。そのようなケースでは、パーミッションマネージャーがそのプロセスを所有します。
- データオフィサー:セマンティックレイヤーをユーザー中心の世界観にモデリングし、データ品質を所有し、統合すべき新しいデータソースを探し出す責任があります。データオフィサーはまた、ユーザーケースで行われる補完を監視し、それらをセマンティックレイヤーに一般化して再利用性を向上させる責任があります。
- プロジェクトマネージャー:プロジェクトマネージャーは、プロジェクトに貢献するエンジニアと協力して、技術的な目標とビジネスの目標の整合性、プラットフォームでの開発のためのベストプラクティスの標準の遵守、および他のプロジェクトチームとの調整を確保します。プロジェクトマネージャーはまた、プロジェクトのドキュメンテーションを担当します。
- データソース所有者:これは特定のソースシステムの主要な連絡先です。新しいデータ接続の設定中に エージェント管理者 と密接に協力する必要があり、その後、「上流」の問題 - サーバーまたはファイルシステム上のエージェントサービスの実行またはデータ自体の整合性 - に対してある程度の責任を引き受ける必要があります。