- Capabilities
- Getting started
- Architecture center
- Platform updates
Preview pipeline
The preview panel allows you to preview logic and column statistics for a single selected node in your pipeline. Select a node and click Preview to run the pipeline. This will open the preview panel and run the logic from raw datasets up until the selected node.
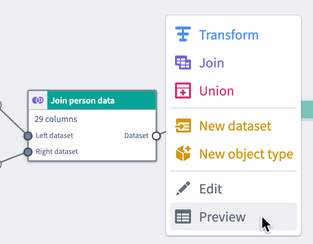
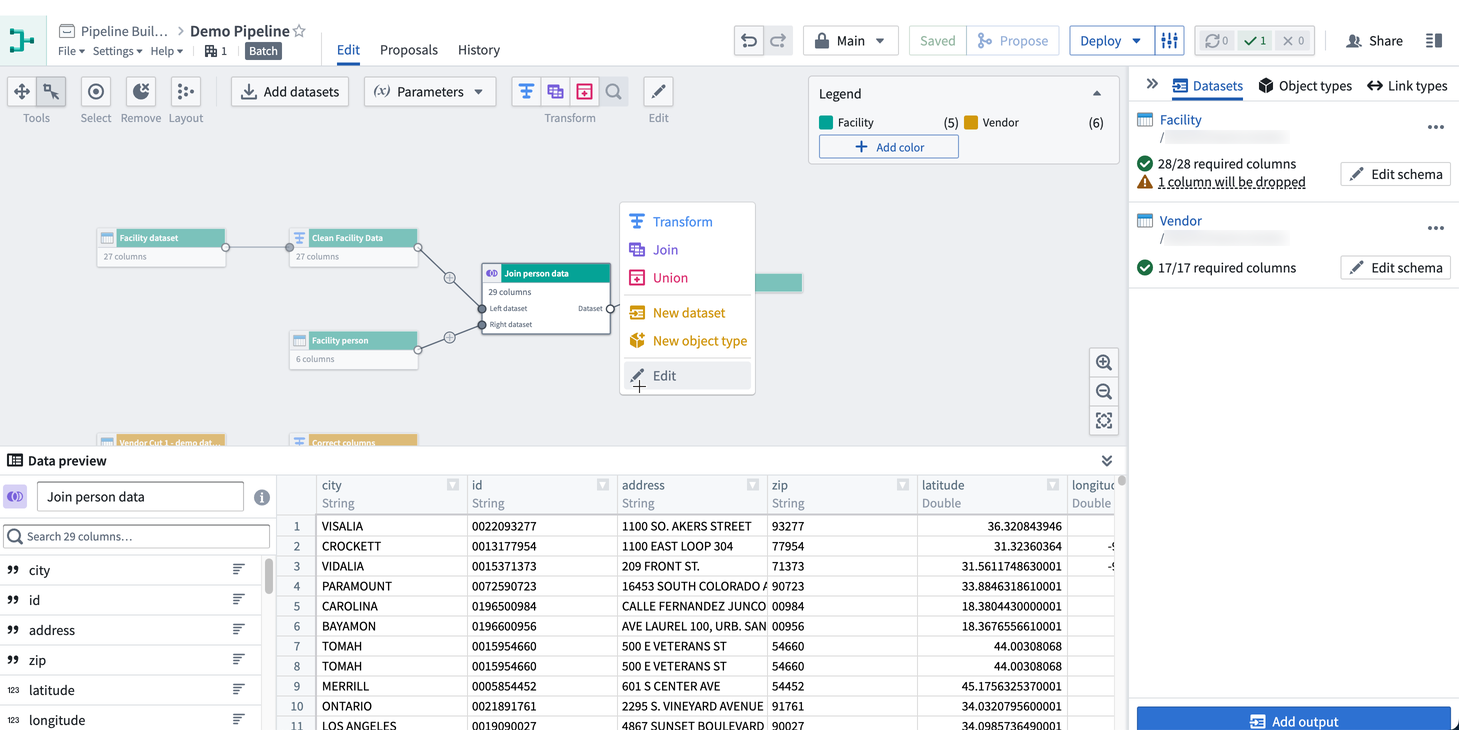
You can also expand the preview panel by clicking on the icon in the bottom right of the graph. Then, click on a node to preview data.
To view statistics, right-click on a column and click View stats.
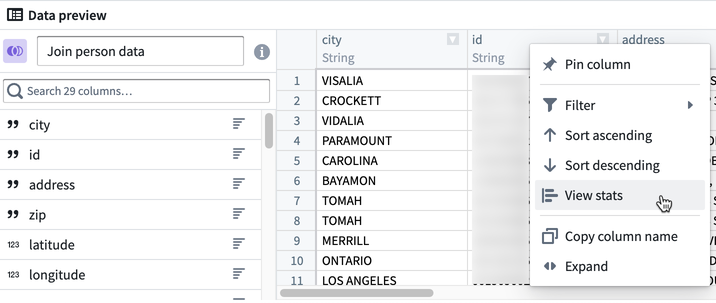
For string columns, the statistics view includes histograms of values and value lengths and counts of string casing, whitespace, and null instances. For numeric columns, a distribution of values is displayed along with basic statistics such as min, max, mean, standard deviation, and number of distinct values.
To view the row count, select Calculate row count in the bottom right of the preview panel.
Preview row counts
By default, Pipeline Builder will process up to 500 rows in the preview table. This implementation may only require 500 input rows in the dataset, but many operations such as Filter, Joins and Drop Duplicates can require additional rows to produce a preview of 500 rows.
To speed up previews, add an input sampling strategy to limit the number of input rows available for computing previews. Input sampling strategies only affect previews and have no effect on builds.
Row count and statistic calculations are run across the sampled input. This means that if the full dataset is used, the row count and stats will match a full build; however, if a sample strategy is set to only use part of the input dataset, the row counts and stats will only be computed across this sample.
As an example, suppose we have an input dataset with 600 rows:
| id | value |
|---|---|
| 1 | row_1 |
| 2 | row_2 |
| ... | ... |
| 600 | row_600 |
Our preview will be limited to 500 rows. Note that these might not necessarily be the first 500 rows of the input.
| id | value |
|---|---|
| 1 | row_1 |
| 2 | row_2 |
| ... | ... |
| 500 | row_500 |
After setting an input strategy of a small percentage, the input will be limited to a small sample that can speed up preview compute. Suppose we are left with just six rows in our preview:
| id | value |
|---|---|
| 1 | row_1 |
| 12 | row_12 |
| 33 | row_33 |
| 62 | row_62 |
| 126 | row_126 |
| 527 | row_527 |
If we then use a transform to add a constant column hello with value world, the preview will show the transform computed for our six sampled rows:
| id | value | hello |
|---|---|---|
| 1 | row_1 | world |
| 12 | row_12 | world |
| 33 | row_33 | world |
| 62 | row_62 | world |
| 126 | row_126 | world |
| 527 | row_527 | world |
Computing the row count will return six rows, and any stats will be computed across only these six rows.
When we finally build our pipeline, the sampling strategy will have no affect, and our transform will be computed across the full 600 input rows.