- Capabilities
- Getting started
- Architecture center
- Platform updates
Change data capture (CDC)
Change data capture ↗ (CDC) is an enterprise data integration pattern often used to stream real-time updates from a relational database to other consumers.
Foundry supports syncing, processing, and storing data from systems that produce change data capture feeds. Components throughout the platform, including data connectors, streams, pipelines, and the Foundry Ontology can all work natively with this changelog data using the metadata configured on the schema of the underlying data.
Change data capture support in Foundry
Foundry offers the following support for change data capture updates:
| Application | CDC support |
|---|---|
| Data Connection | CDC support available for syncs (source-system dependent) |
| Ontology | CDC indexing for batch- and stream-backed objects |
| Pipeline Builder | Full CDC stream processing and partial CDC streams with backfill |
| Streams | Full CDC support for live and archive views |
| Transforms | Append-only incremental for datasets, full changelog incremental available for Iceberg tables |
| Workshop | Auto-refresh available for frequently updating objects |
Changelog metadata
Changelog metadata requires the following attributes on the data:
- One or more primary key columns
- Changelog data will contain many entries with identical primary key columns, as changelogs are meant to convey every individual change that occurred on the record with that primary key. Change data capture is particularly useful for data that is being edited, rather than immutable or append-only data feeds.
- One or more ordering columns
- The ordering column(s) must be numeric and are used to determine the relative order of changes for records with a given set of primary keys. Ordering columns are frequently timestamps represented as longs, however this is not always the case. The largest value is understood to be the most recent, even if the order columns are not timestamps.
- A deletion column
- The deletion column is used to determine if a given update deleted the record with the given set of primary keys. This must be a boolean that is true if the record was deleted, else it should be false.
This changelog metadata is used to specify a resolution strategy to resolve the changelog down to a current view of the data in the source system. The resolution strategy for change data capture works as follows:
- Group the data based on the primary key column(s).
- Find the entry with the largest value in the ordering column(s).
- If this entry has the value
truein the deletion column, remove it.
After these steps, the changelog should now be collapsed down to the same view as you would see in the upstream source system generating the changelog. The changelog metadata and resolution strategy is used in different ways by various Palantir components, as described below.
Change data capture in Data Connection
Sources available in Data Connection may support syncing data from systems as a stream with changelog metadata applied. The ability for a source to implement the capability to sync changelog data is dependent on the ability of the source system to produce log data with the required attributes (primary key column(s), ordering column(s), and a deletion column).
Many commonly used databases including MySQL, PostgreSQL, Oracle, Db2, and SQL Server can produce CDC changelog data. Data connectors in Foundry for these systems may or may not support directly syncing these changelogs. Even if a connector does not currently support CDC syncs, you can still sync data via Kafka or other streaming middleware and use as a changelog once the data arrives in Foundry.
The following source types in Data Connection currently support CDC syncs:
- Db2
- Microsoft SQL Server
- Oracle
- PostgreSQL
If you have changelog-shaped data available from other sources, such as Kafka, Kinesis, Amazon SQS, or push-based integration with streams, read how to manually configure changelog metadata using the key-by board in Pipeline Builder.
Enable change data capture on an external database
To sync changelog feeds from a supported source type, you must have the correct settings enabled for the relevant tables and, in some cases, for the entire database.
For example, to enable change data capture for Microsoft SQL Server, you must run a command to enable CDC on the database:
USE <database>
GO
EXEC sys.sp_cdc_enable_db
GO
Then, run another command on each table that should be recording changelogs:
EXEC sys.sp_cdc_enable_table
@source_schema = N'<schema>'
, @source_name = N'<table_name>'
, @role_name = NULL
, @capture_instance = NULL
, @supports_net_changes = 0
, @filegroup_name = N'PRIMARY';
GO
The above examples provide a high level explanation of what may be required to enable a source system to produce changelog data. Specific information on how to enable change data capture logs for a given system can be found in documentation provided by that system.
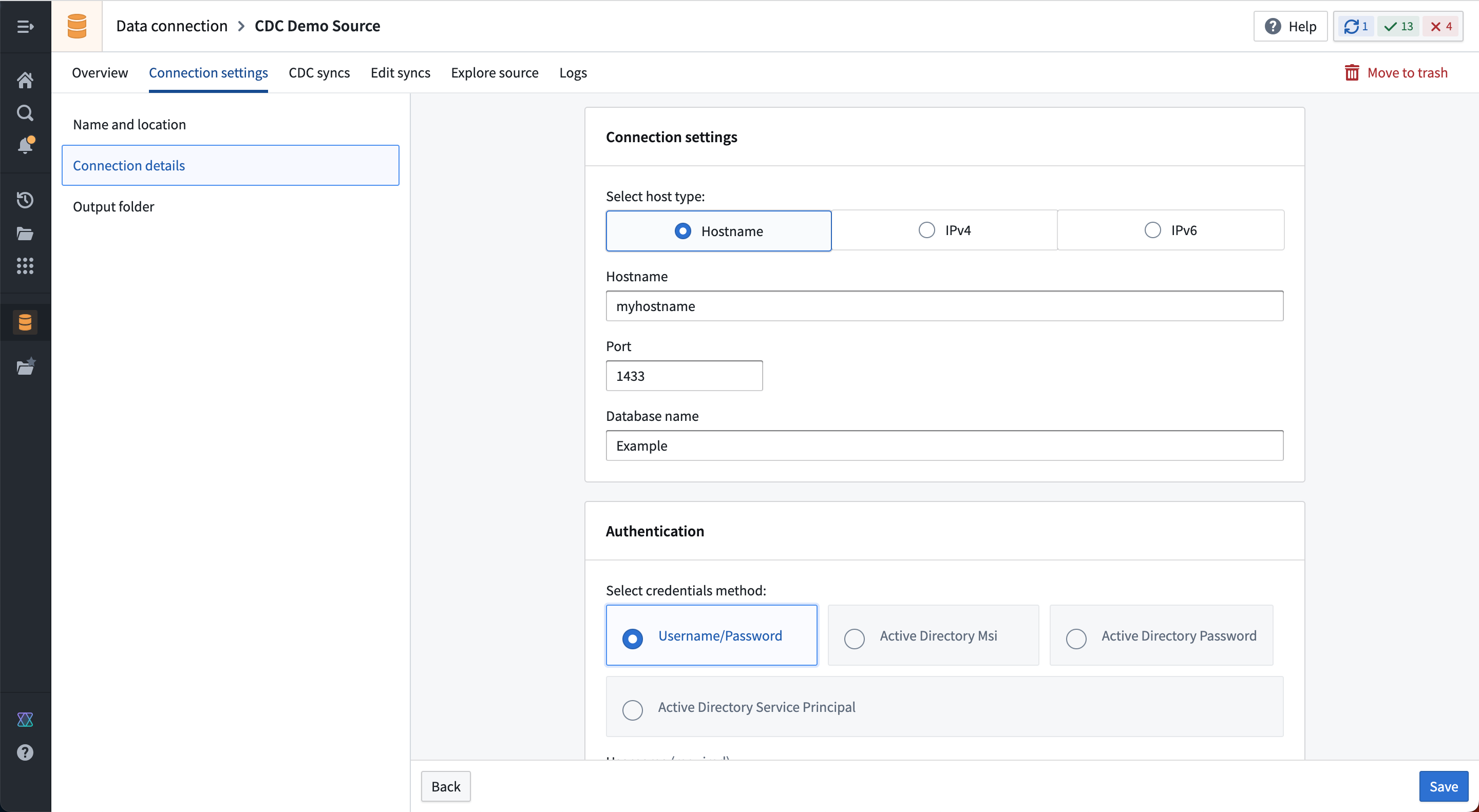
Set up a source connection for change data capture
Now, you can configure a source in Data Connection that connects to the system from which you want to capture changelogs. Continuing with our example, set up a connection using the Microsoft SQL Server connector, as shown below:
Create a change data capture sync
On the source overview page, you will find an empty table of CDC Syncs.
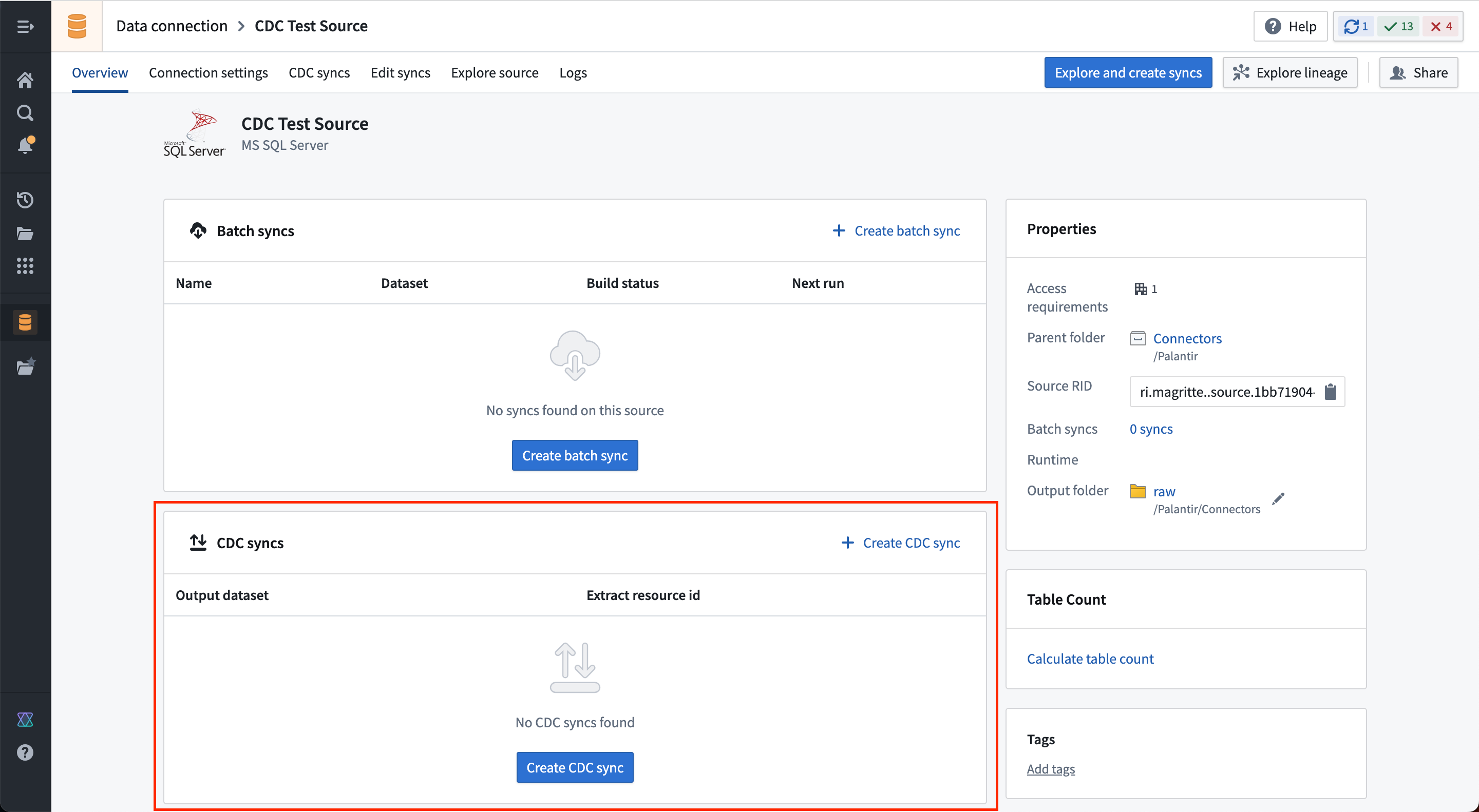
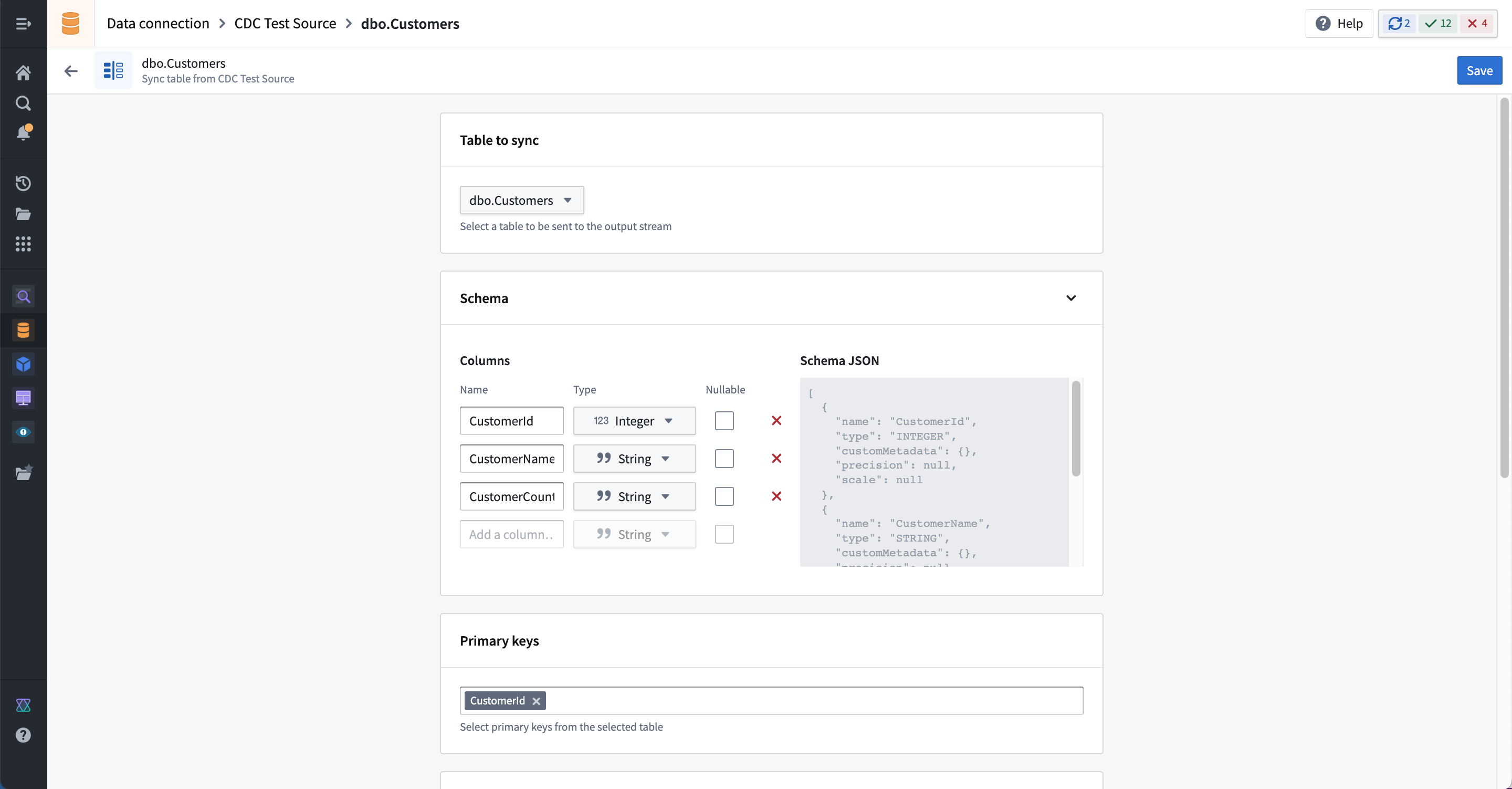
Select Create CDC sync to add a new change data capture sync. Specify the table you wish to sync, and the following information will be automatically derived by the connector:
- The schema for the output streaming dataset.
- Changelog metadata, including primary key columns, ordering columns, and a deletion column.
As with other streams, you must specify the expected throughput at creation. The throughput cannot be changed after sync creation; ensure that your stream is configured to support the expected volume of changelog data. The default volume is 5MB/s, which is typically more than required for most change data capture workflows. Since changes in relational databases are often produced at “human scale”, the volume and frequency of changes is much smaller than what is possible with “machine scale” sensor or equipment data.
Save the sync configuration to create a new stream in the specified output location.
Currently, the CDC job must be manually (re)started after any changes. All CDC syncs run as a single multi-output extract job, meaning that any existing CDC streams from the same source must be briefly stopped whenever a feed is added or removed. The streams will gracefully catch up with any data that was changed while the streaming sync job was stopped.
After starting the output stream, changelog data should begin flowing and appear in the live view of the output streaming dataset.
Configure custom CDC settings per source
Foundry's CDC implementation leverages the open-source platform Debezium ↗ to read data source logs. You can configure the Debezium connection and engine properties for an individual source directly from the Data Connection interface. First, navigate to the created source that you want to configure. Then select CDC syncs from the top right. Select the CDC settings section to expand the configuration options.

Foundry’s default CDC configuration is designed to provide a frictionless setup and minimize disruptions on your source systems. However, we strongly recommend reviewing the specific default behaviors for your connector, particularly its snapshot mode, to ensure these defaults align with your data requirements.
Each data source type has recommended configurable settings. For example, the image above shows a Transaction isolation level for the Microsoft SQL Server connector. However, you can also configure arbitrary Debezium properties using the Advanced Debezium configuration option. This flexibility allows you to customize settings to the specific needs of each data source.
Customized CDC settings for data connectors can be useful for a variety of situations, including the following examples:
- High transaction volume: For data connectors experiencing rapid transaction bursts, the default
max.batch.sizesetting may lead to excessive small batch processing, increasing overhead and delaying data propagation. By raising themax.batch.size, you can consolidate changes into larger batches, enhancing efficiency and data flow. - Network instability: For data connectors prone to transient network issues or temporary errors, increasing
error.max.retriesprovides the connector with more opportunities to recover autonomously, reducing the risk of missed data. - Real-time updates: In high-transaction environments where near-real-time updates are crucial, lowering
offset.flush.interval.msensures more frequent offset flushing, minimizing recovery windows and improving change propagation timeliness.
Review Debezium’s documentation ↗ to learn which properties can be configured for each data connector type.
When configuring arbitrary Debezium properties, it is your responsibility to ensure compatibility and functionality. Improper configurations may lead to unexpected behavior or data loss. Proceed with caution and consult the Debezium documentation for guidance.
Change data capture in streams
Streams with changelog metadata will display two views into the data:
- A live view showing the fully expanded list of changelog entries.
- An archive view where the data is resolved according to the resolution strategy and collapsed down to the current latest view of the data.
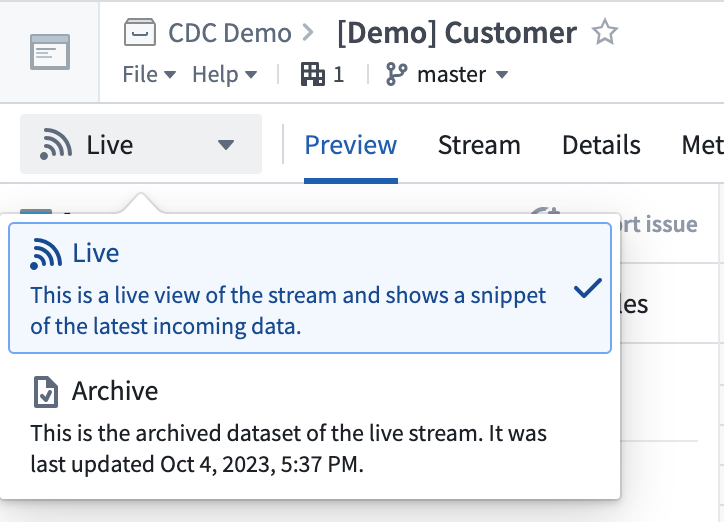
The schema will display changelog metadata as a primary key resolution strategy in the details view.
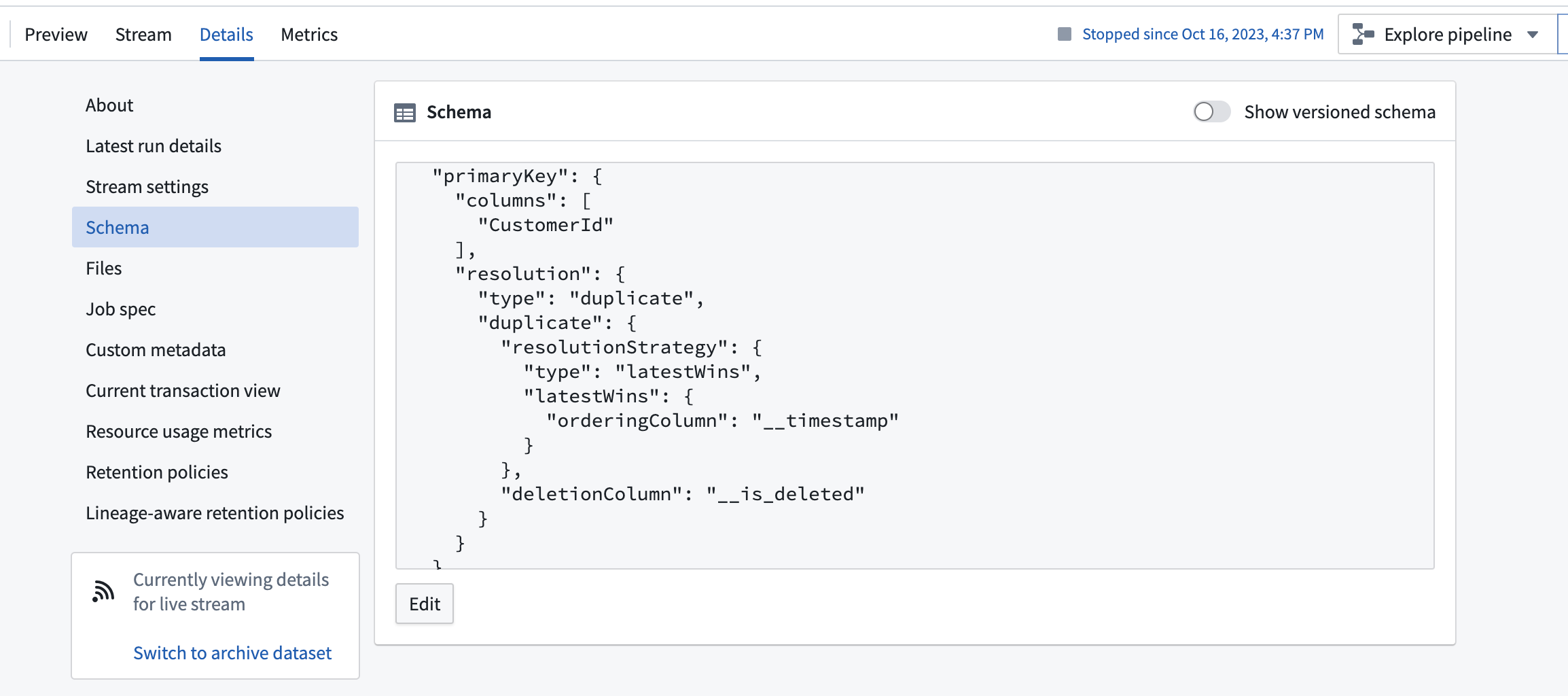
Streams currently use the ordering column to perform resolution. This means that data will be resolved in the archive according to the provided ordering column, even if the data was received out of order. This behavior differs from the behavior of changelog data in the Foundry Ontology, which indexes data based on the order of arrival in the stream used to back the object type.
Change data capture in Pipeline Builder
Pipeline Builder offers powerful capabilities for processing and configuring change data capture (CDC) streams. This section covers two scenarios: working with full CDC streams and handling partial CDC streams that require backfilling.
Process full CDC streams
When working with streaming transformations in Pipeline Builder, you can process changelog data while preserving its metadata. As long as the metadata columns (primary key, ordering, and deletion) remain unmodified during transformations, the changelog metadata will automatically propagate to any outputs.
Configure partial CDC streams with a backfill dataset
In some cases, a CDC stream may not contain all historical data. Instead, it could only contain changes from a specific point in time. To create a complete dataset, you must combine a backfill dataset with the ongoing CDC stream. Use the steps below to achieve this:
-
Prepare the backfill dataset:
- Ingest a snapshot of the data using the same Data Connection source used for the CDC stream.
- Ensure the backfill dataset includes a timestamp column. If not present in the source data, generate one using an SQL function (
CURRENT_TIMESTAMP(), for example).
-
Combine the datasets in Pipeline Builder:
- Use a Union transform to combine the backfill dataset with the ongoing CDC stream.
-
Configure CDC metadata:
- Use the Key By transform board to prepare the combined data for syncing into the Ontology.
- Set the primary key column(s) to match those in your source system.
- Choose the timestamp column as the ordering column.
- If applicable, specify the deletion column.
-
Handle deletions and ordering:
- Ensure the Key By board is configured to order the data by the timestamp column.
- If the source data does not include explicit deletion information, you may need to implement logic to infer deletions (for example, by comparing consecutive snapshots).
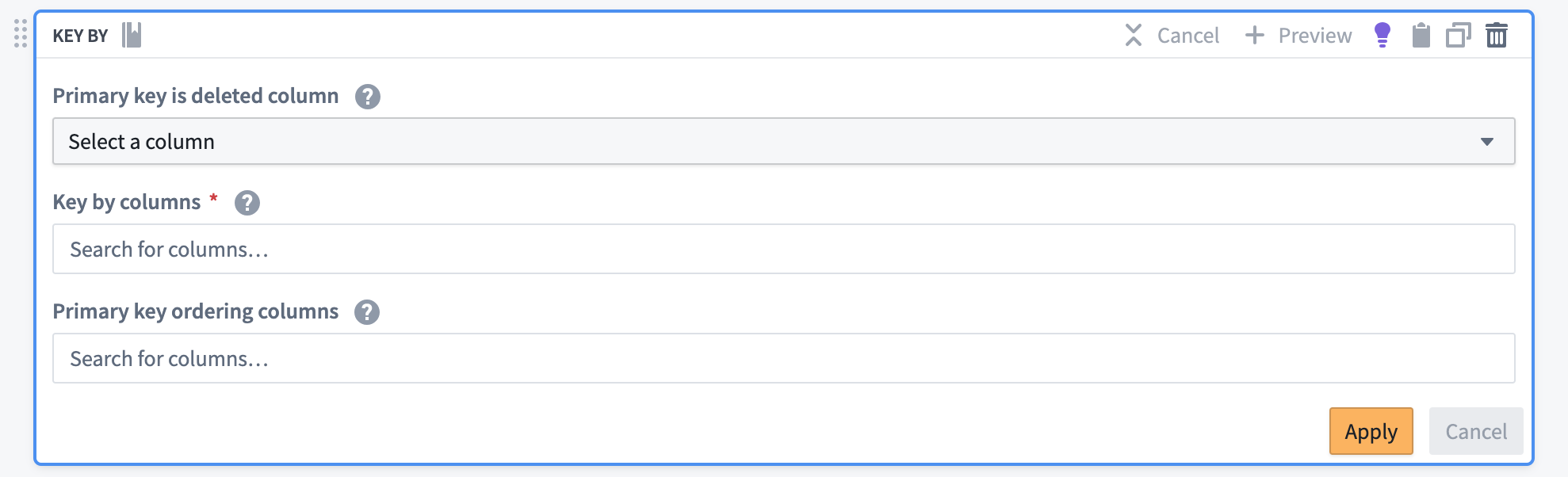
The Key By transform board will append the necessary CDC metadata to the stream, including the following:
- A primary key resolution strategy
- Ordering column(s)
- A deletion column
This configuration prepares the data for proper resolution when synced to the Ontology, ensuring that the most recent state of each record is maintained based on the timestamp ordering.
Apply CDC metadata to non-CDC data
If your input stream lacks changelog metadata or if the metadata columns were modified during transformations, you can still use the Key By board to apply changelog metadata to your output(s). This allows you to treat any dataset as a CDC stream, enabling powerful data integration and real-time update capabilities.
Change data capture in the Ontology
The Ontology uses changelog metadata to index data into object types in Object Storage V2 that are backed by a streaming data source. The data arriving in the stream is resolved and indexed into a latest current view that is available when querying the Ontology (to display in a Workshop module, for example).
If retention is configured on a data source with changelog metadata, any records that do not receive updates within the retention window time will disappear from the Ontology.
The Ontology currently ignores the ordering column(s) specified in the changelog metadata. Instead, Object Storage V2 indexes data based on the order it arrives in the backing data source. Concretely, this means that for a given primary key, if a log entry with an ordering value of 2 arrives at t1 and data_column=foo, followed by another log entry with an ordering value of 1 that arrives at t2 with data_column=bar, the record will appear with data_column=bar even though in the source system the most recent value is data_column=foo. This can cause the Ontology to incorrectly reflect the data in the source system if data arrives out of order.
Since connectors used with Palantir are guaranteed to deliver data in order, and Foundry streams maintain ordering, this Ontology behavior will likely only affect custom setups or older streaming changelogs that are manually backfilled and not re-ordered before syncing. If you encounter this situation, we recommend applying a transformation to reorder the data in Pipeline Builder before syncing to the Ontology.
Change data capture in Workshop
Workshop supports auto-refresh to display the frequently updating data as soon as it is available in the Ontology. Auto-refresh is compatible with CDC and may be used to ensure that any data streamed in with change data capture is promptly available in Workshop applications.
Auto-refresh is available for any data that is expected to update frequently while the Workshop module is open. Data is not required to have changelog metadata on the backing data source to use auto-refresh.
Considerations when using change data capture
We recommending reviewing the following information on backfills, outages, and other known limitations before using CDC workflows.
Backfill
All changelog syncs are handled on an exclusively "going forward" basis; no automatic backfill is performed.
Often, a full backfill of changelogs is not possible, since most systems do not enable CDC by default. Even if changelogs are enabled, most systems include a retention period, after which changlogs are permanently deleted and no longer recoverable.
If a full backfill is required, we recommend the following:
- Set up a CDC stream on a "going forward" basis.
- Perform a batch sync to extract the desired historical data.
- Convert the historical batch data into a stream of “create” records for each primary key, then merge that stream into the CDC stream.
Backfills may result in data that is out of order, and you may need to manually reorder or replay streams to properly prepare data for syncing to the Ontology.
Outages
You may encounter the following outages when using a CDC workflow:
- Network connectivity between the source database and the Foundry agent
- Network connectivity between the Foundry agent host and Foundry
- Foundry outage
- Database outage
- Agent outage
Outages are handled gracefully if the retention window on replication logs and changelogs in the database are configured to be longer than the maximum expected outage.
For example, if the connection to Foundry goes down for several hours, and the log retention window on Microsoft SQL Server is set to one day, the database will continue recording changelog entries. Foundry will gracefully catch up once it is back online and reconnected to Microsoft SQL Server. Since no new data will flow until the queue of changelog entries is cleared, there may be some lag before changes are again flowing at near real time into Palantir.
Use changelog-shaped data from non-changelog sources
Data does not need to be ingested as a changelog to use CDC workflows. Any streaming data in Palantir may be “keyed” with changelog metadata and then used as CDC data in workflows after syncing to the Ontology.
This means, for example, that push-based ingestion using stream proxy may be used to manually push changelog-shaped records into a stream.
Similarly, if changelog data is available in a Kafka topic, it may be ingested using a standard (non-CDC) sync. Then, it can be “keyed’ using Pipeline Builder and used in the Ontology and beyond.
Remove changelog metadata
Sometimes, it may be useful to remove changelog metadata. For example, you might want to remove metadata to analyze the process flow captured by the changelog. To remove changelog metadata, use one of the following methods:
- Perform any transformation on the metadata columns
- Manually remove the resolution strategy from the schema of the streaming dataset
Enabling access to your CDC tables
When connecting to your source system, you must provide user credentials within Connection Details. These credentials are tied to permissions set at the source. For basic data ingestion, this user will need SELECT permissions for the datasets you plan to ingest. However, CDC connections may require the user to have both SELECT and EXECUTE permissions on the table you wish to ingest from as well as its schema.
Default CDC behavior
Below are some universal default settings for CDC connections:
| Property | Default Value | Notes |
|---|---|---|
tombstones.on.delete | false | Tombstone records are not produced when rows are deleted. |
decimal.handling.mode | string | Decimal columns are converted to string. |
include.schema.changes | false | DDL events (schema changes) are not forwarded into output topics. |
offset.flush.interval.ms | 60000 (1 minute) | Debezium attempts to flush offsets every minute. |
error.max.retries | 5 | The engine will attempt to recover from transient errors five times before failing. |
Connector-specific defaults
Most database connectors also have default settings for snapshot mode and other parameters. The tables below contain summaries of the most important settings. You can override these configurations from the CDC syncs page. Select Edit in the CDC settings dropdown section, then select Add property under Advanced Debezium configuration.
Oracle
| Property | Default value |
|---|---|
snapshot.mode | schema_only |
schema.history.internal.store.only.captured.tables.ddl | true |
internal.log.mining.log.query.max.retries | 10 |
log.mining.strategy | online_catalog |
log.mining.query.filter.mode | in |
log.mining.batch.size.default | 50000 |
database.connection.adapter | logminer |
PostgreSQL
| Property | Default value |
|---|---|
snapshot.mode | never |
plugin.name | pgoutput |
Db2
| Property | Default value |
|---|---|
snapshot.mode | no_data |
snapshot.isolation.mode | none |
Microsoft SQL Server
| Property | Default value |
|---|---|
snapshot.mode | schema_only |
offset.flush.interval.ms | 1000 |
Snapshot mode considerations
By default, Foundry configures snapshot.mode to schema_only (Oracle, SQL Server), no_data (Db2), or never (PostgreSQL) to avoid impacting the database’s availability; these configurations avoid locking the tables during the snapshot process, ensuring minimal disruption to ongoing database operations. Although these modes avoid table locking, they still pose a data loss risk if archived logs are purged before Debezium can process them. For example, Oracle may delete older redo logs over time; if Debezium tries to read a deleted log, it cannot recover the missing data without a full snapshot.
Alternative configurations
If you want to protect against log purging or ensure a base dataset, consider a more complete snapshot configuration instead:
-
recovery- Behavior: Recovers a connector that is already capturing changes if the schema history topic is lost or corrupted; resets and rebuilds the database schema history on restart if no schema changes happened since the last shutdown.
- Limitation: Requires infinite retention on the schema history topic.
-
always- Behavior: Takes a complete snapshot each time the connector restarts, guaranteeing a fully up-to-date copy of the data.
- Limitation: May induce table locking and added overhead on every start.
when_needed- Behavior: Snapshots only if Debezium cannot detect valid offsets; for example, if the offset does not exist or is expired.
- Limitation: Still may lock tables when a snapshot is triggered.