注: 以下の翻訳の正確性は検証されていません。AIPを利用して英語版の原文から機械的に翻訳されたものです。
高度な設定
タイムシリーズパイプラインの設定には、Pipeline Builder を使用して タイムシリーズの設定ページに説明されているように行うことをお勧めします。これにより、以下で説明されるトランスフォームの最適化が自動的に適用されます。
高度な設定構成を進める前に、Palantir の担当者に相談してください。
低レベルのトランスフォーム制御や Pipeline Builder ではまだ提供されていない高度な機能が必要な場合、このページでは、データ変換に使用される Code Repositories と共にタイムシリーズパイプラインを手動で設定する方法を説明します。
Code Repositories を使用してタイムシリーズを設定するには、以下の手順を完了する必要があります。
- タイムシリーズデータセットを作成する。
- タイムシリーズデータセットを最適化する。
- タイムシリーズ同期を手動で設定する。
- タイムシリーズオブジェクトタイプの元データセットを作成する。
- タイムシリーズオブジェクトタイプを設定する。
1. タイムシリーズデータセットを作成する
Pipeline Builder のタイムシリーズ出力を使用してタイムシリーズ同期を作成すると、タイムシリーズデータセットが自動的に生成され、タイムシリーズデータセットと同期が正しく設定されます。パイプラインを手動で設定する場合、フォーマットされたタイムシリーズデータを含むタイムシリーズデータセットを明示的に生成し、タイムシリーズ同期の作成に必要となるデータセットを作成する必要があります。データセットには、用語集で指定されているように、Series ID、Value、および Timestamp 列が含まれている必要があります。
シリーズIDのすべての値は、同じデータセットに含まれている必要があります。値はシリーズIDで取得されるため、1つのタイムシリーズデータセットには複数のシリーズIDのすべての値が含まれていても問題ありません。例:
+------------------------+---------------------+---------+
| series_id | timestamp | value |
+------------------------+---------------------+---------+
| Machine123_temperature | 01/01/2023 12:00:00 | 100 | # Machine123の温度データ、2023年1月1日の12時00分の値は100
| Machine123_temperature | 01/01/2023 12:01:00 | 99 | # Machine123の温度データ、2023年1月1日の12時01分の値は99
| Machine123_temperature | 01/01/2023 12:02:00 | 101 | # Machine123の温度データ、2023年1月1日の12時02分の値は101
| Machine463_temperature | 01/01/2023 12:00:00 | 105 | # Machine463の温度データ、2023年1月1日の12時00分の値は105
| Machine123_pressure | 01/01/2023 12:00:00 | 3 | # Machine123の圧力データ、2023年1月1日の12時00分の値は3
| ... | ... | ... | # 他のデータ...
+------------------------+---------------------+---------+
時系列データセットは、ライブデータがある場合には通常、インクリメンタルに構築されるように設定されています。インクリメンタルビルドにより、コンピューティングコストを節約し、生のデータが取り込まれるときから最新のデータが読み取れるまでの待ち時間を大幅に短縮することができます。
インクリメンタルな時系列ビルドの利点については、FAQ ドキュメントを参照してください。
2. 時系列データセットの最適化
コードで時系列データセットを生成する際には、書き込む前に以下のようにデータセットをフォーマットしてください。
Python
Copied!1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20# transforms.apiから必要な関数をインポートします from transforms.api import transform, Input, Output # transformデコレータを使用して、入力と出力データセットを指定します @transform( output_dataset=Output("/path/to/output/dataset"), # 出力データセットのパスを指定します input_dataset=Input("/path/to/input/dataset") # 入力データセットのパスを指定します ) # my_compute_functionという関数を定義します def my_compute_function(output_dataset, input_dataset): # 入力データセットをデータフレームに変換し、'seriesId'によって再パーティションを行い、それぞれのパーティション内で'seriesId'と'timestamp'によってソートします output_dataframe = ( input_dataset .dataframe() .repartitionByRange('seriesId') .sortWithinPartitions('seriesId', 'timestamp') ) # 出力データセットにデータフレームを書き込み、出力形式を'soho'に指定します output_dataset.write_dataframe(output_dataframe, output_format='soho')
Java
Copied!1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36package myproject.datasets; import com.palantir.transforms.lang.java.api.Compute; import com.palantir.transforms.lang.java.api.FoundryInput; import com.palantir.transforms.lang.java.api.FoundryOutput; import com.palantir.transforms.lang.java.api.Input; import com.palantir.transforms.lang.java.api.Output; import com.palantir.foundry.spark.api.DatasetFormatSettings; import org.apache.spark.sql.Dataset; import org.apache.spark.sql.Row; import java.util.Collections; public final class TimeSeriesWriter { @Compute // パーティションに書き込むメソッド public void writePartitioned( @Input("/path/to/input/dataset") FoundryInput inputDataset, // 入力データセットへのパス @Output("/path/to/output/dataset") FoundryOutput outputDataset) { // 出力データセットへのパス // 入力データフレームを読み込む Dataset<Row> inputDataframe = inputDataset.asDataFrame().read(); // データフレームを'reseriesId'に基づいて再分割し、各パーティション内で'seriesId'と'timestamp'に基づいてソートする Dataset<Row> outputDataframe = inputDataframe .repartitionByRange(inputDataframe.col('seriesId')) .sortWithinPartitions('seriesId', 'timestamp'); // データフレームを出力する // フォーマットは'soho'を使用 outputDataset.getDataFrameWriter(outputDataframe) .setFormatSettings(DatasetFormatSettings.builder() .format('soho') .build()) .write(); } }
この再パーティションとソートを実行すると、データセットが時系列としてのパフォーマンスに最適化されます。最低限、データセットは_Soho_(表示されているように)でフォーマットされている必要があり、新しいデータがまだ投影されていない場合に時系列データベースにインデックスされます。また、repartitionByRange() ↗によって書き込まれるパーティションの数を、以下のガイダンスに基づいてパイプラインに適した数に設定する必要があります:
- 可能な限り少ないパーティションを書き込む。
- パーティションは128MBより大きいべきである。
- 一般的に、パーティションは50億行未満であるべきである。
書き込むことができるパーティションの最低数の上限は、executorに収まる十分に小さなパーティションを書き込むこと、しかし十分に多くのパーティションを書き込むことで、ユーザーが求めるパイプラインの遅延に対して十分に並列化されることによって決定されます。より多くのパーティションを書き込むと、パーティションは小さくなり、ジョブは速くなりますが、大きなパーティションほど最適とは言えません。
3. 手動で時系列同期を設定する
新しい時系列同期を作成するには、直接 https://<domain>/workspace/time-series-catalog-app/new に移動します。同期を保存する場所を選択するよう求められますが、これはユーザーの時系列データセットを含むか、それをリファレンスとしてインポートするProject内でなければなりません。

入力としてユーザーの時系列データセットを選択し、データセットの列を時系列同期のSeries ID、Value、Timestampにマッピングを完了します。Timestamp列がLongタイプの場合、それがSECONDS、MILLISECONDS、MICROSECONDS、NANOSECONDSのいずれの単位であるかを指定します。
時系列同期がビルドされると、時系列データセットからメタデータが同期され、Foundryがユーザーの時系列データを要求に応じて時系列データベースにインデックス化できるようになります。
制限付きビューによってバックアップされたオブジェクトタイプの操作
制限付きビューは、データセットへのアクセスをユーザーが閲覧する権限を持つ行のみに制限します。制限付きビューにバックアップされたオブジェクトタイプを操作する場合、ユーザーは時系列同期を設定してマーキングの継承を停止する必要があります。
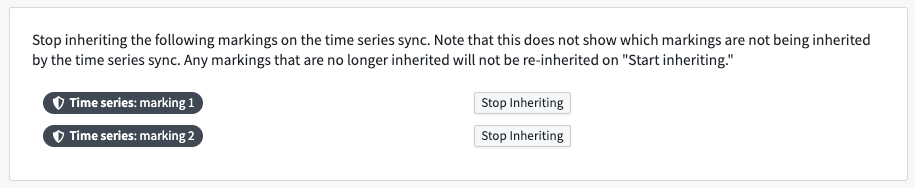
時系列データセットの各マーキングを選択して継承停止を選択することで、マーキングの継承を停止します。
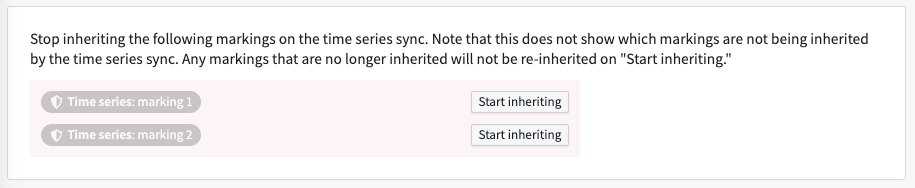
終了したら、ページの上部で保存を選択します。
高度な時系列同期設定
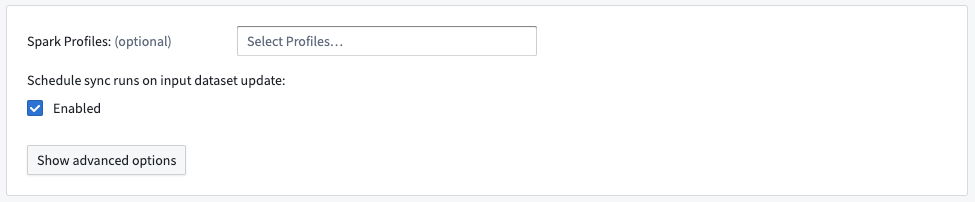
時系列同期ビルドのSparkプロファイルを設定することは可能ですが、これは非常にまれです。
デフォルトでは、同期は入力時系列データセットが更新されたときに実行されるようにスケジュールされます。ユーザーの時系列データが最新の状態に保たれるように、この設定を推奨します。
もし、ユーザーが他の時系列同期で交差するシリーズIDを書き込み、その同期を新しいものに置き換えたい場合は、詳細オプションを表示 > 他のデータセットによってバックアップされた他の同期からのシリーズを上書きの下で古い同期を指定できます。これを行うと、古い同期は失敗し、それはゴミ箱に入れられるべきです。
4. 時系列オブジェクトタイプ元データセットの作成
ユーザーは好みの方法で時系列オブジェクトタイプの元データセットを生成でき、それは用語集で指定されたスキーマに準拠するべきです。
自動的に時系列オブジェクトタイプの元データセットを生成するために、ユーザーはそれをユーザーの時系列データセットと同じトランスフォームで生成できます。ここでは、シリーズIDの一意のセットを取得し、それらから/それらにメタデータを抽出/マッピングできます。インクリメンタルなパイプラインでは、これを達成するためにマージと追加のパターンを使用できます。
5. 時系列オブジェクトタイプの設定
時系列オブジェクトタイプの元データセットにオブジェクトタイプを作成するための標準的なプロセスに従います。また、データセットプレビューで全てのアクション > オブジェクトタイプを作成を選択することで、データセットから直接オブジェクトタイプを生成することも可能です。オブジェクトタイプを作成する際には、どのプロパティを時系列プロパティとして指定するべきかを指定して、それを時系列用に設定します。