注: 以下の翻訳の正確性は検証されていません。AIPを利用して英語版の原文から機械的に翻訳されたものです。
概要
Pipeline Builder は、Foundry でデータをトランスフォームするための柔軟で強力かつ使いやすいインターフェースを提供します。既存のツール(たとえば Spark や SQL など)でデータトランスフォームを記述することは、コーダーでない人や経験豊富なソフトウェア開発者にとっても困難でエラーが発生しやすいです。さらに、既存のツールは特定の実行エンジンに結び付けられており、データトランスフォームを表現するためにコードライブラリを使用する必要があります。
Pipeline Builder はデータトランスフォームを記述するための一般的なモデルを使用します。このバックエンドは、トランスフォームの記述に使用されるツールとその実行の間の中間層として機能します。
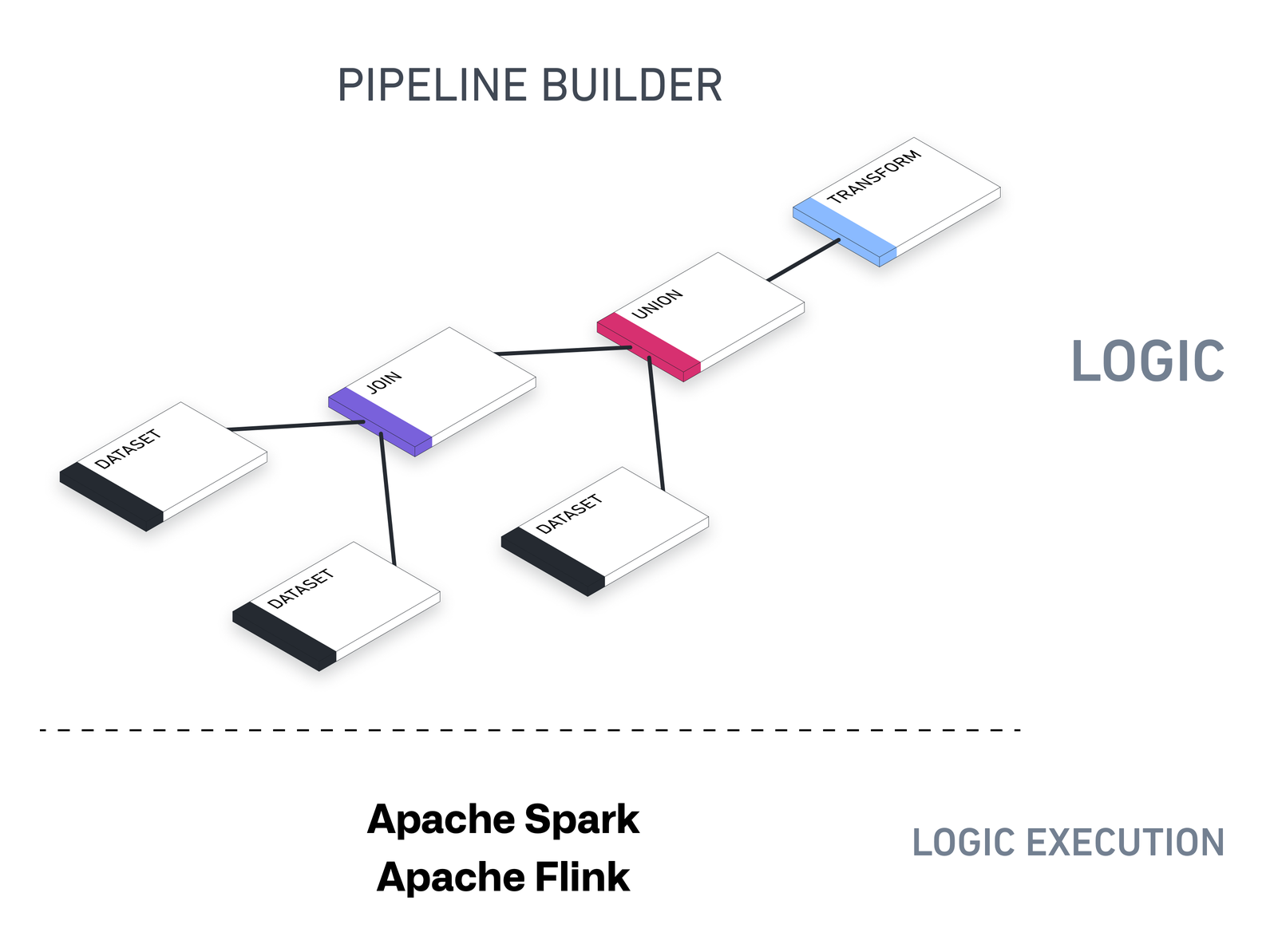
Pipeline Builder の基盤アーキテクチャは、データセット、オントロジーオブジェクト、ストリーム、時系列、および外部システムへのエクスポートなど、すべての種類の出力をサポートするように設計されています。データセット、オブジェクトタイプ、リンクタイプに対応するバッチパイプラインや、ストリーミングデータセットに対応するストリーミングパイプラインを実行できます。
Pipeline Builder でのトランスフォームの使用
Pipeline Builder では、2 種類のデータトランスフォームを使用できます: 式とトランスフォーム。式はテーブルの列を入力として受け取り、単一の列を出力します(たとえば Split string)。一方、トランスフォームはテーブル全体を入力として受け取り、テーブル全体を返します(たとえば、Pivot や Filter)。
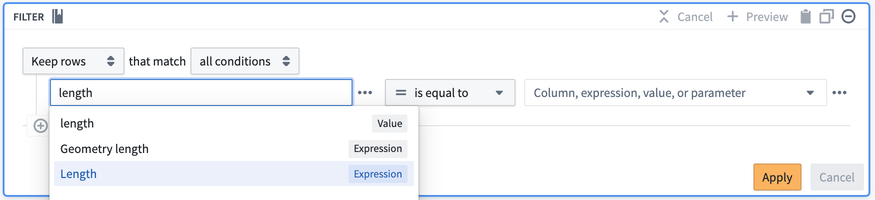
式とトランスフォームは同じ設定インターフェースでまとめられています。たとえば、Drop columns トランスフォームは、Cast や Concatenate strings のような式と並んで見つけることができます。これにより、同じパスで式とトランスフォームを一緒に使用でき、1 つの設定フォーム内でトランスフォームに式を埋め込むことができます。以下の例では、Filter トランスフォームに Length 式を挿入しています。
他のデータ構造化トランスフォーム、具体的には Join および Union は、それぞれ独自の設定パネルを持ち、Pipeline Builder インターフェースでユニークなアイコンで表示されます。
シンプルさを保つために、通常はすべての種類のデータトランスフォームをトランスフォームと呼びます。
Join
Join は、少なくとも 1 つの一致する列を持つ 2 つのデータセットを結合します。設定する Join のタイプによって、一致する行を結合し、一致しない行を除外することができます。
Union
Union は 2 つのデータセットを結合してすべての行を含めます。
Union トランスフォームは、すべての入力が同じスキーマを持つ必要があります。入力スキーマが一致しない場合、Union は欠落している列のリストを含むエラーメッセージを表示します。
ユーザー定義関数
既存のトランスフォームオプションでデータを操作できない場合や、パイプライン全体で再利用したい複雑なロジックがある場合は、ユーザー定義関数 (UDF) を作成できます。ユーザー定義関数を使用すると、バージョン管理およびアップグレード可能なカスタムコードを Pipeline Builder で実行できます。
注意: 最良の体験を得るために Python 関数 の使用をお勧めします。特定の Java ライブラリにアクセスする必要がある場合は、Java UDF も利用可能です。
ユーザー定義関数は必要な場合にのみ使用してください。Pipeline Builder 内の最適化された transform boards を可能な限り使用することをお勧めします。
次のステップ
パイプラインワークフローに トランスフォームを追加 する方法を学びましょう。