注: 以下の翻訳の正確性は検証されていません。AIPを利用して英語版の原文から機械的に翻訳されたものです。
データセット出力を追加する
Pipeline Builder にデータセット出力を追加して、パイプライン統合をクリーンでトランスフォームされたデータに向けてガイドすることを選択できます。異なる出力タイプについて詳しく学びましょう。
データセット出力を作成する
まず、グラフの右側の出力パネルにあるデータセットタイプの隣にある Add をクリックします。
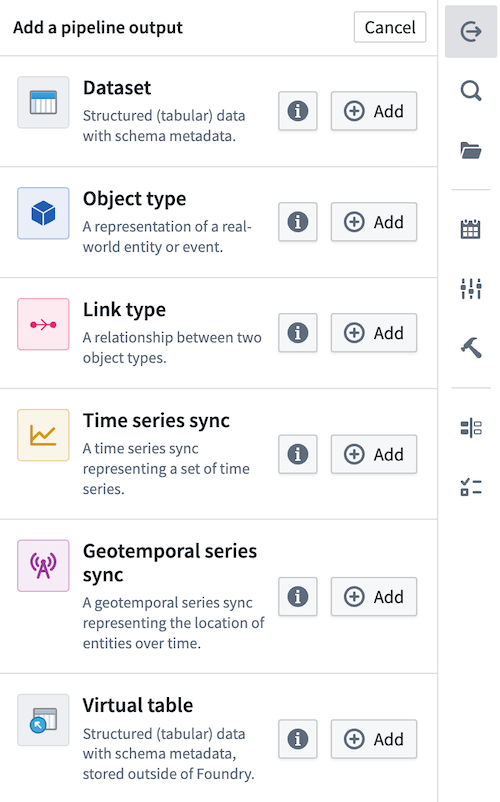
これで新しい出力データセットが作成されました。パイプラインの最初のビルド後、データセット出力はパイプラインと同じフォルダーに作成されます。例えば、デモパイプラインの Vendor データセット出力は次のファイルパスを持つでしょう:/Palantir/Pipeline Builder/Demo Pipeline/Vendor。
出力データセットの名前を変更するには、名前フィールドをクリックします。Add column を選択して手動で列を出力スキーマに追加するか、トランスフォームノードを接続して Use updated schema でその出力スキーマを使用します。
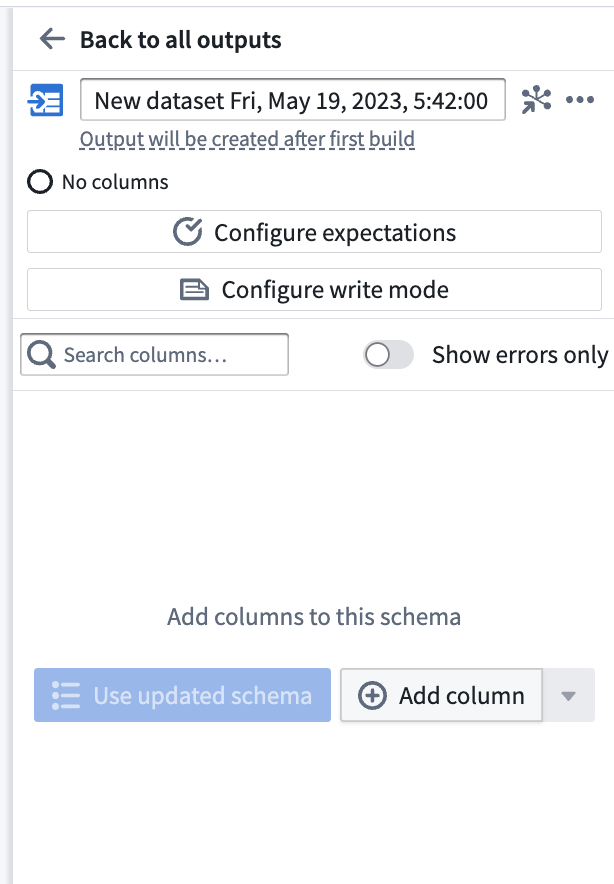
出力スキーマを追加したら、Search columns... フィールドを使用してデータセット内の列を素早く見つけます。出力スキーマのエラーのみを表示するには、Show errors only ボタンを切り替えます。
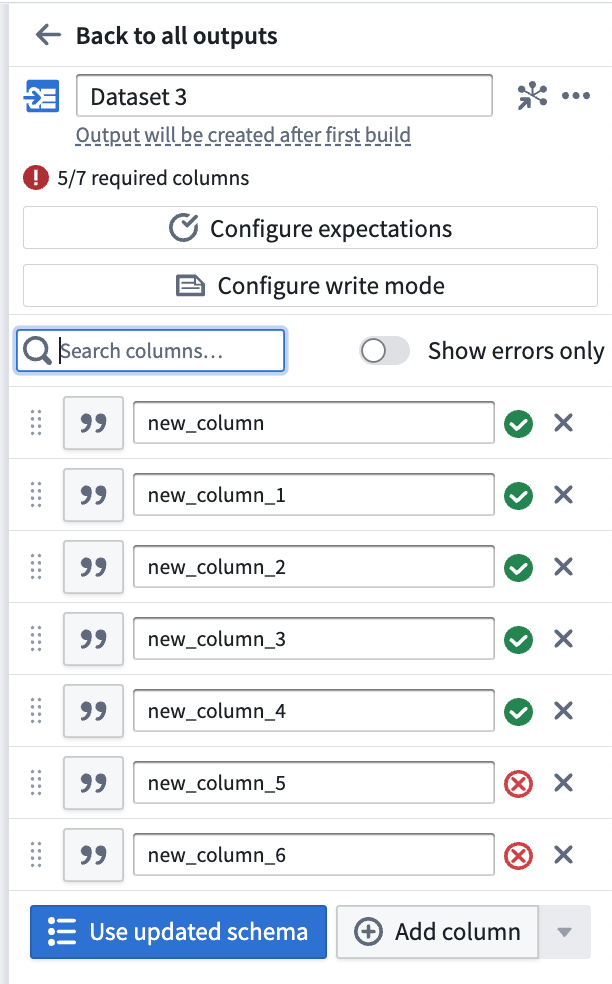
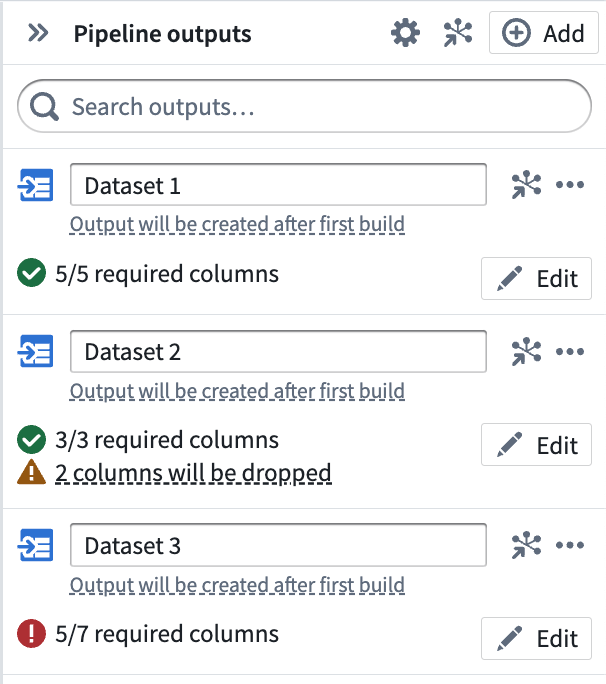
出力データセットを追加したら、Back to all outputs をクリックしてパイプライン内のすべての出力のリストを表示します。各出力のステータスを一目で理解し、出力スキーマが入力トランスフォームノードスキーマと一致するかどうかを含めます。以下の3つの出力は、出力スキーマが持つことができる異なるステータスを表しています:
- Dataset 1 は5/5 の必須列を持っていて、これは入力トランスフォームノードのすべての列が出力データセットにビルドされることを意味します。
- Dataset 2 は3/3 の必須列を持ち、2つが削除されています。これは、入力トランスフォームノードに5つの列があるが、出力データセットには3つしかビルドされないことを意味します。これは、入力トランスフォームノードに不必要な列がある場合に望ましいです。
- Dataset 3 は5/7 の必須列を持っていますが、これはエラー状態です。2つの欠落した列が入力トランスフォームノードの列にマッピングされるまで、パイプラインをデプロイすることはできません。
出力スキーマをいつでも更新するには、Edit をクリックします。
データセットスキーマについて詳しくは、データ統合をご覧ください。
出力設定を設定する
スキーマの設定に加えて、各個別の出力にはカスタマイズ可能なデフォルト設定がいくつかあります。
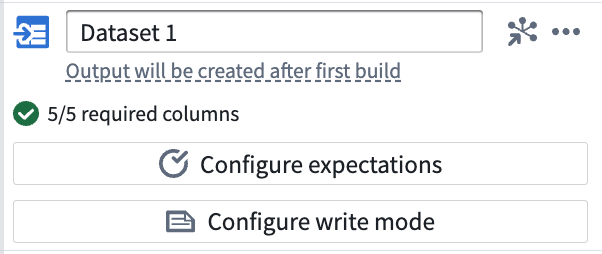
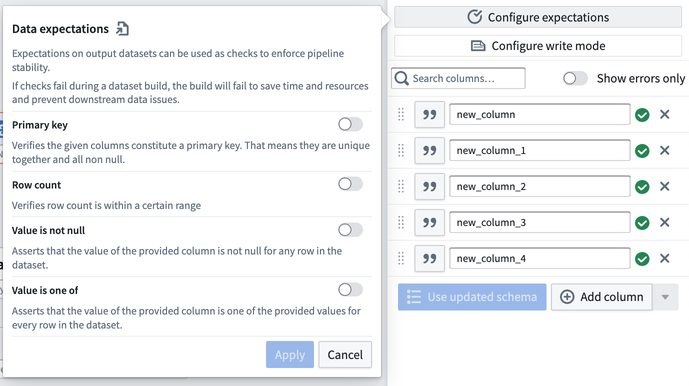
期待値を設定する
パイプラインの安定性を強制するために、出力データセットに期待値を追加します。パイプラインビルド中にチェックが1つでも失敗すると、ビルドが失敗します。
書き込みモードを設定する
データが将来のデプロイメントでデータセット出力に追加される方法を定義します。
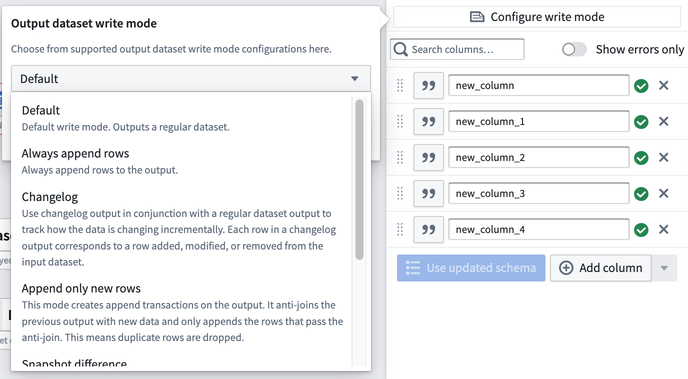
Default: これは、ほとんどのバッチパイプライン、スナップショットとインクリメンタルの両方に推奨されます。デフォルトの書き込みモードは、少なくとも1つの入力がインクリメンタルとしてマークされていて、すべてのインクリメンタルとしてマークされた入力が前のビルド以降に APPEND または追加的な UPDATE トランザクションしか持っていない場合、結果を APPEND トランザクションとして出力します。それ以外の場合、デフォルトの書き込みモードは結果を SNAPSHOT トランザクションとして出力します。トランザクションタイプについて詳しく学びましょう。
Always append rows: 結果を APPEND トランザクションとして出力します。
Append only new rows: 結果を APPEND トランザクションとして出力し、新しく見つけた主キーとして定義された新しい行のみが出力に追加されます。現在のトランザクション内に重複した行が存在する場合、ランダムに1つが削除されます。以前の出力に存在する主キーを持つ行は削除されます。
Changelog: Object Storage v1 でのみ使用します。 すべてのレコードの変更履歴を含む一連の APPEND トランザクションを出力します。Changelog データセットについて詳しく学びましょう。
Snapshot difference: 結果を SNAPSHOT トランザクションとして出力し、新しく見つけた主キーを持つ行のみが出力に保持されます。現在のトランザクション内に重複した行が存在する場合、それらは保持されます。他のすべての行は削除されます。
Snapshot replace: 結果を SNAPSHOT トランザクションとして出力し、新しいデータが前の出力と結合されます。以前の出力に存在する主キーは新しい行に取って代わられて削除されます。現在のトランザクション内に重複した行が存在する場合、ランダムに1つだけが削除されますので、出力は主キーごとに1行だけになります。
Snapshot replace and remove: これは、Snapshot replace に続いて、古いデータから行を選択的に削除するための後フィルタリングステージが続くものと同等です。 結果を SNAPSHOT トランザクションとして出力し、新しいデータが前の出力と結合され、その後に提供されたブール型の post_filtering_column に基づいて、前のトランザクションからの行を削除する後フィルタリングステージが続きます。以前の出力に存在する主キーは、post_filtering_column = TRUE の新しい行に取って代わられて削除されます。ただし、現在のトランザクションで post_filtering_column = FALSE である主キーを持つ行が存在する場合、古いデータから対応する行がフィルタリングされます(ただし、これは post_filtering_column = TRUE を持つ新しい行が保存されることを上書きしません)。現在のトランザクション内に post_filtering_column = TRUE を持つ重複した行が存在する場合、ランダムに1つだけが削除されますので、出力は主キーごとに1行だけになります。
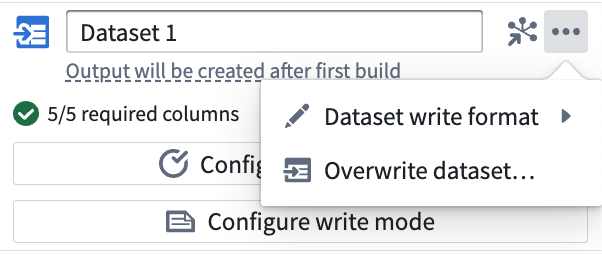
データセットの書き込み形式
データセットの出力ファイル形式は初回デプロイメント後に変更でき、次回のパイプラインのデプロイメント時に有効になります。ファイル形式について詳しく学びましょう。
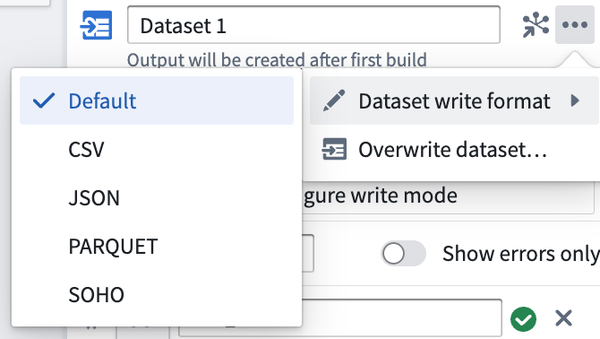
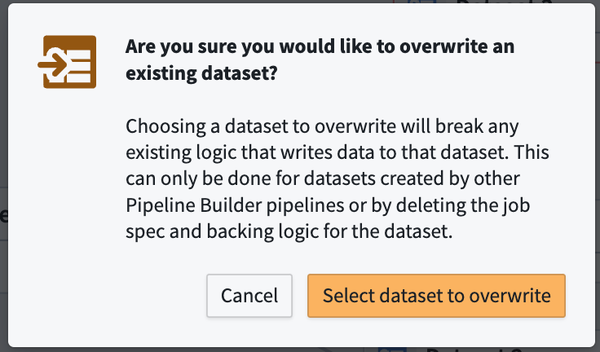
データセットを上書きする
既存のデータセットの所有権を Pipeline Builder の新しい出力に与える一回限りのアクションです。このアクションは、Pipeline Builder の外部で追加のアクションを必要とする場合があります。
データセット出力をビルドする
データセット出力をパイプラインに追加した後、変更を保存することを忘れないでください。データのトランスフォームが完了し、パイプラインワークフローの定義が完了したら、パイプラインをデプロイし、データセット出力をビルドする準備が整いました。パイプラインをデプロイした後、最終的なデータセット出力をOntology Managerでのオントロジー構築の基礎として使用します。
パイプラインをデプロイする方法を学びましょう。