注: 以下の翻訳の正確性は検証されていません。AIPを利用して英語版の原文から機械的に翻訳されたものです。
仮想テーブル
仮想テーブルを使用すると、Foundryのデータセットにデータを最初に保存することなく、サポートされているデータプラットフォームのテーブルにクエリを実行できます。
仮想テーブルは、Foundry外のソースシステムのテーブルへのポインターとして機能します。仮想テーブルは、基盤となるソースシステムやストレージフォーマットを抽象化し、異なるソースシステムからのデータをシームレスに組み合わせたワークフローを構築できるようにします。仮想テーブルは、Foundryに保存されたデータセットと組み合わせることもでき、データを1か所に統合する必要のない柔軟なアーキテクチャの一部として機能します。
仮想テーブルは以下によって定義されます:
- ソースストレージシステムへの接続(たとえば、ソースのURLや資格情報)。この接続は、Foundryのデータ接続アプリケーションでソースを設定することで確立されます。
- ソースシステム内のテーブルを識別するロケーター(たとえば、データベース、スキーマ、テーブル名)。
Foundryの他のリソースと同様に、仮想テーブルはFoundryのセキュリティおよび権限モデルによって管理され、さまざまなFoundryアプリケーションで開いたり使用したりできます。
サポートされているソース
以下のソースは仮想テーブルをサポートしています。接続の設定方法およびサポートされている機能の詳細については、ソースのドキュメントを参照してください。
| ソース | ステータス | サポートされているフォーマット | 手動登録 | 自動登録 |
|---|---|---|---|---|
| Amazon S3 | 🟢 一般的に利用可能 | Avro ↗、Delta ↗、Iceberg ↗、Parquet ↗ | ✔️ | |
| Azure Data Lake Storage Gen2 (Azure Blob Storage) | 🟢 一般的に利用可能 | Avro ↗、Delta ↗、Iceberg ↗、Parquet ↗ | ✔️ | |
| BigQuery | 🟢 一般的に利用可能 | Table、View、Materialized View | ✔️ | ✔️ |
| Google Cloud Storage | 🟢 一般的に利用可能 | Avro ↗、Delta ↗、Iceberg ↗、Parquet ↗ | ✔️ | |
| Snowflake | 🟢 一般的に利用可能 | Table、View、Materialized View | ✔️ | ✔️ |
Iceberg カタログ
Apache Icebergテーブルを利用した仮想テーブルをロードするには、Icebergカタログが必要です。Icebergカタログの詳細については、Apache Icebergのドキュメント ↗を参照してください。仮想テーブルは、使用されるソースに応じて異なるカタログオプションをサポートしています。以下の表は、サポートされているカタログを示しています。各カタログの設定方法の詳細については、ソースのドキュメントを参照してください。
| ソース | AWS Glue | Object Storage | Unity Catalog |
|---|---|---|---|
| Amazon S3 | 🟢 一般的に利用可能 | 🟢 一般的に利用可能 | 🟢 一般的に利用可能 |
| Azure Data Lake Storage Gen2 (Azure Blob Storage) | 🔴 利用不可 | 🟢 一般的に利用可能 | 🟢 一般的に利用可能 |
| Google Cloud Storage | 🔴 利用不可 | 🟢 一般的に利用可能 | 🔴 利用不可 |
サポートされているFoundryワークフロー
仮想テーブルは以下のアプリケーションおよびワークフローで入力としてサポートされています:
| サポートされているアプリケーション | サポートされているワークフロー | サポートされていないもの |
|---|---|---|
| Data Connection | ソースの設定 仮想テーブルの登録 | エージェントベースの接続 |
| Contour | Contourでの分析 | データセットとして保存 |
| Ontology | Pipeline Builder経由のオブジェクト作成 | Ontology Manager経由のオブジェクト作成 |
| Data Lineage | Foundryデータフローの表示 | |
| Pipeline Builder | パイプラインへの入力 オブジェクトおよびデータセットの出力 スナップショットビルド インクリメンタルビルド(追加のみ) | ストリーミングビルド |
| Code Repositories | Pythonトランスフォーム スナップショットビルド インクリメンタルビルド(追加のみ) | Javaトランスフォーム SQLトランスフォーム |
一部のソースタイプはこれらのすべての機能をサポートしていない場合があります。詳細については、ソース固有のドキュメントを参照してください。仮想テーブルをCode Repositoriesで使用する方法についてはこちらをご覧ください。
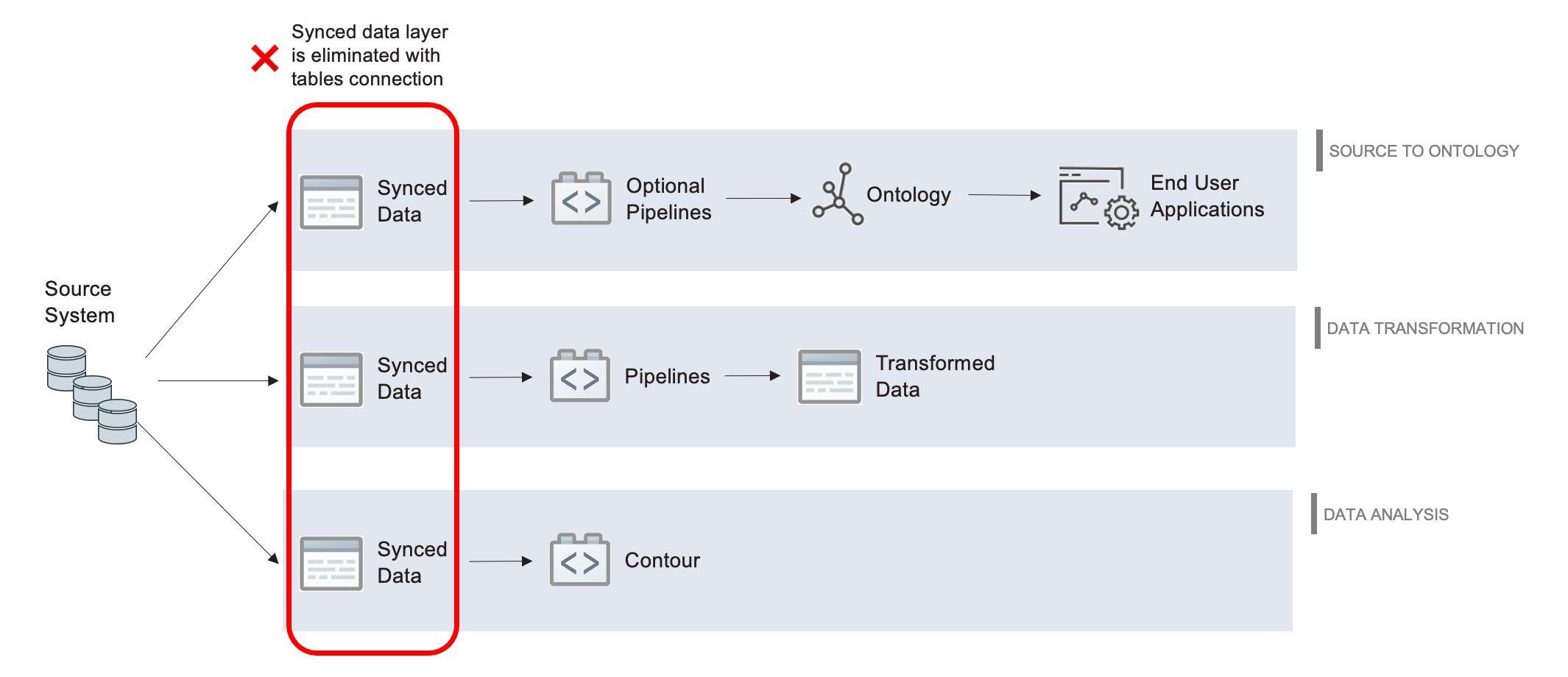
一般的には、仮想テーブルは以下のいずれかの方法で大部分のFoundryワークフローをサポートするために使用できます:
- 上記のように仮想テーブルと直接やり取りする、または
- 仮想テーブルを利用した変換パイプラインを作成し、Foundryデータセットやオブジェクトを出力します。これらの出力はプラットフォーム内で通常通り使用できます。
仮想テーブルの接続設定
仮想テーブルをサポートするソースは、Data Connectionアプリケーションで設定されます。使用するソースを選択し、ソース設定の仮想テーブルタブに移動します。ソースのドキュメントおよび仮想テーブルの使用に関する要件を参照してください。
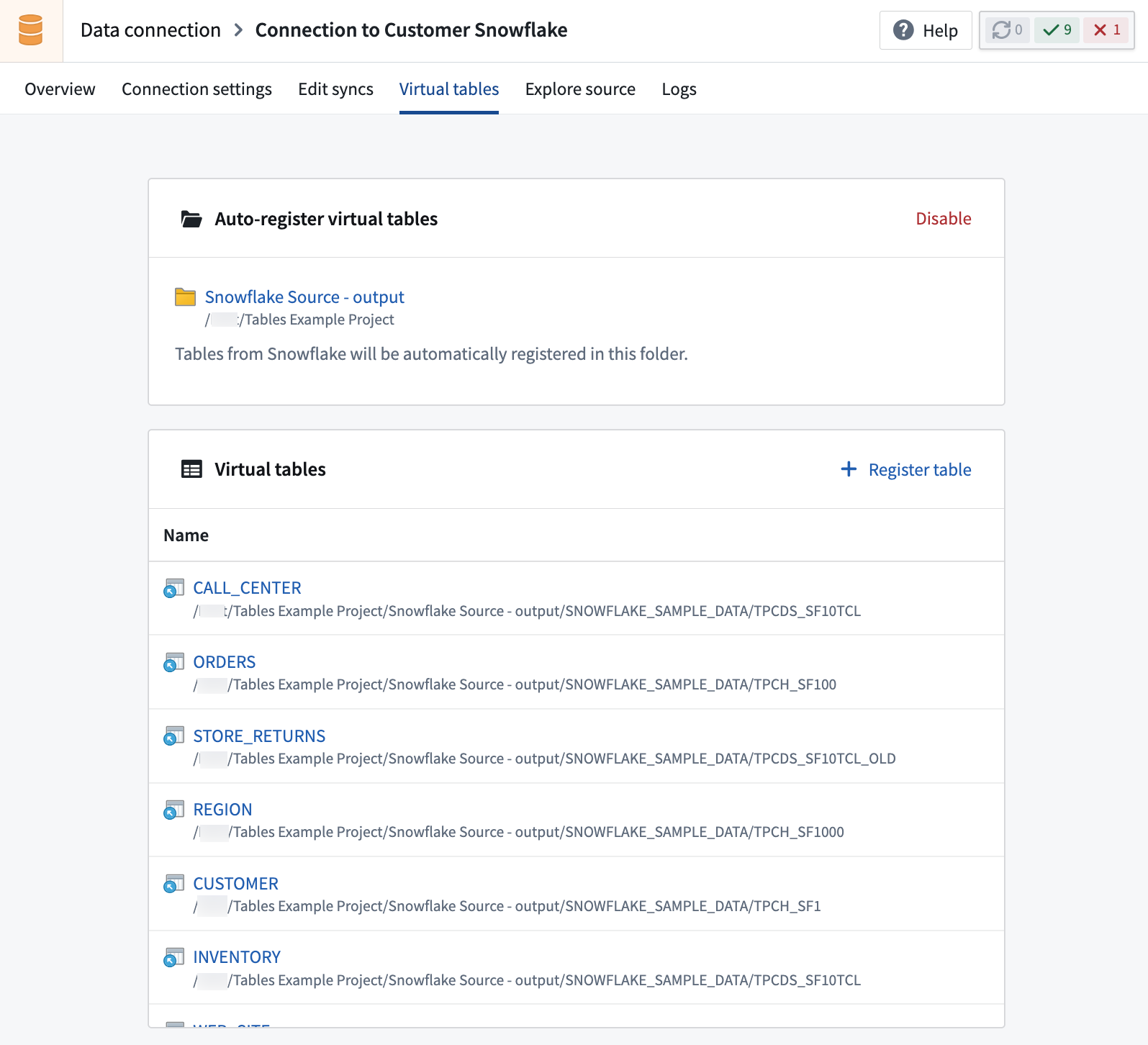
仮想テーブルの手動登録と自動登録
すべてのソースは手動登録をサポートしており、ソースシステムからFoundryに個々のテーブルを登録できます。一部のソースは自動登録もサポートしており、構成された資格情報でアクセス可能なすべてのテーブルが指定されたプロジェクトに定期的に登録されます。
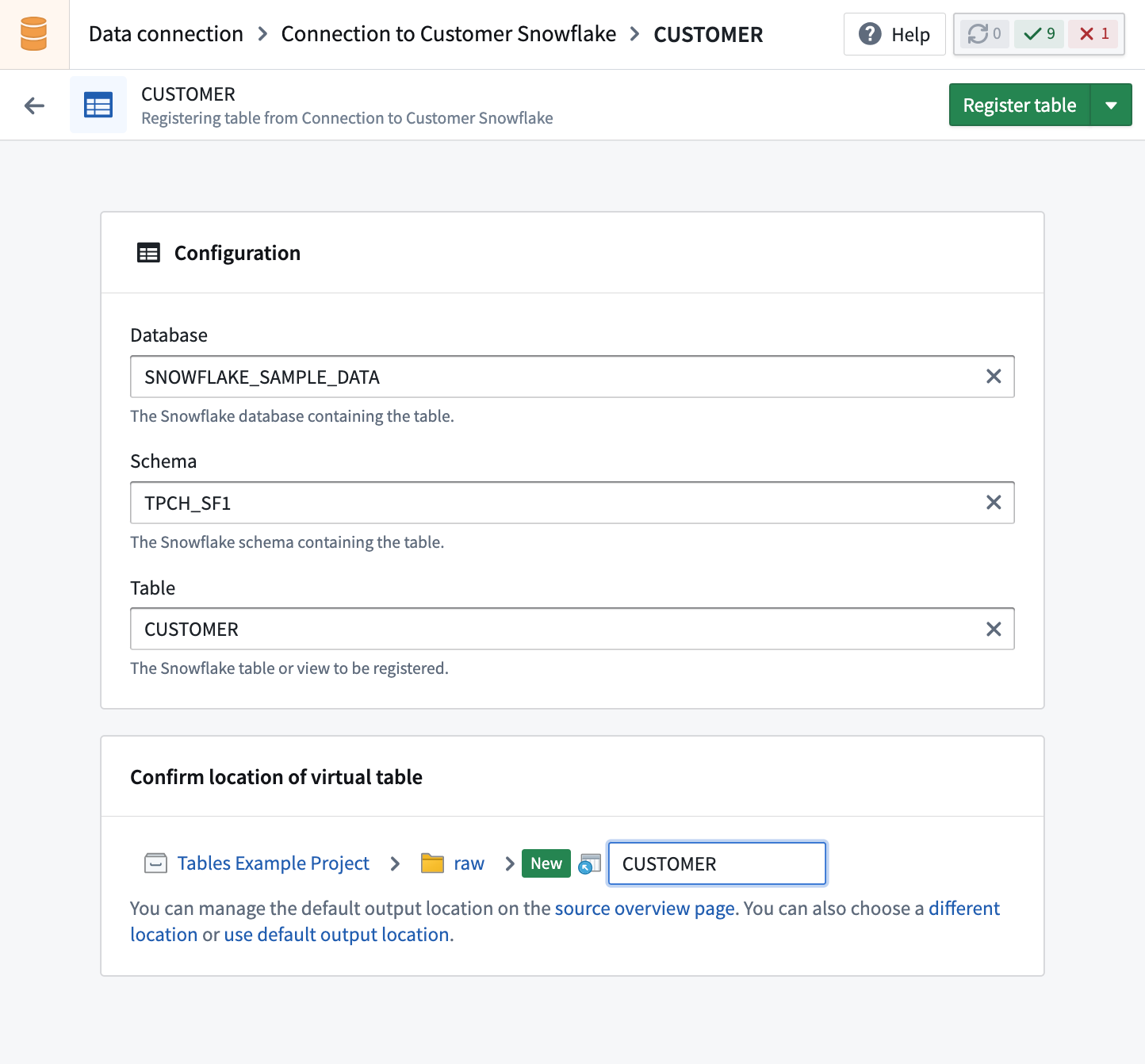
手動登録を使用する場合、仮想テーブルの作成を選択し、ソースシステム内の利用可能なテーブルを参照し、登録する個々のテーブルを選択できます。異なる場所を選択しない限り、これらはソースの接続設定で構成されたFoundryの場所に登録されます。
自動登録を有効にすると、仮想テーブルが自動的に作成される新しいFoundryプロジェクトを作成します。このプロジェクトのフォルダーヒエラルキーはソースシステムの構造を反映し、新しいテーブルがソースに作成されるたびに定期的に更新されます。ソーステーブルが削除されると、関連する仮想テーブルはプロジェクト内で自動的に削除されませんが、アクセスしてもデータは読み込まれません。
自動登録を有効にするには、Foundryでプロジェクト作成権限が必要です。
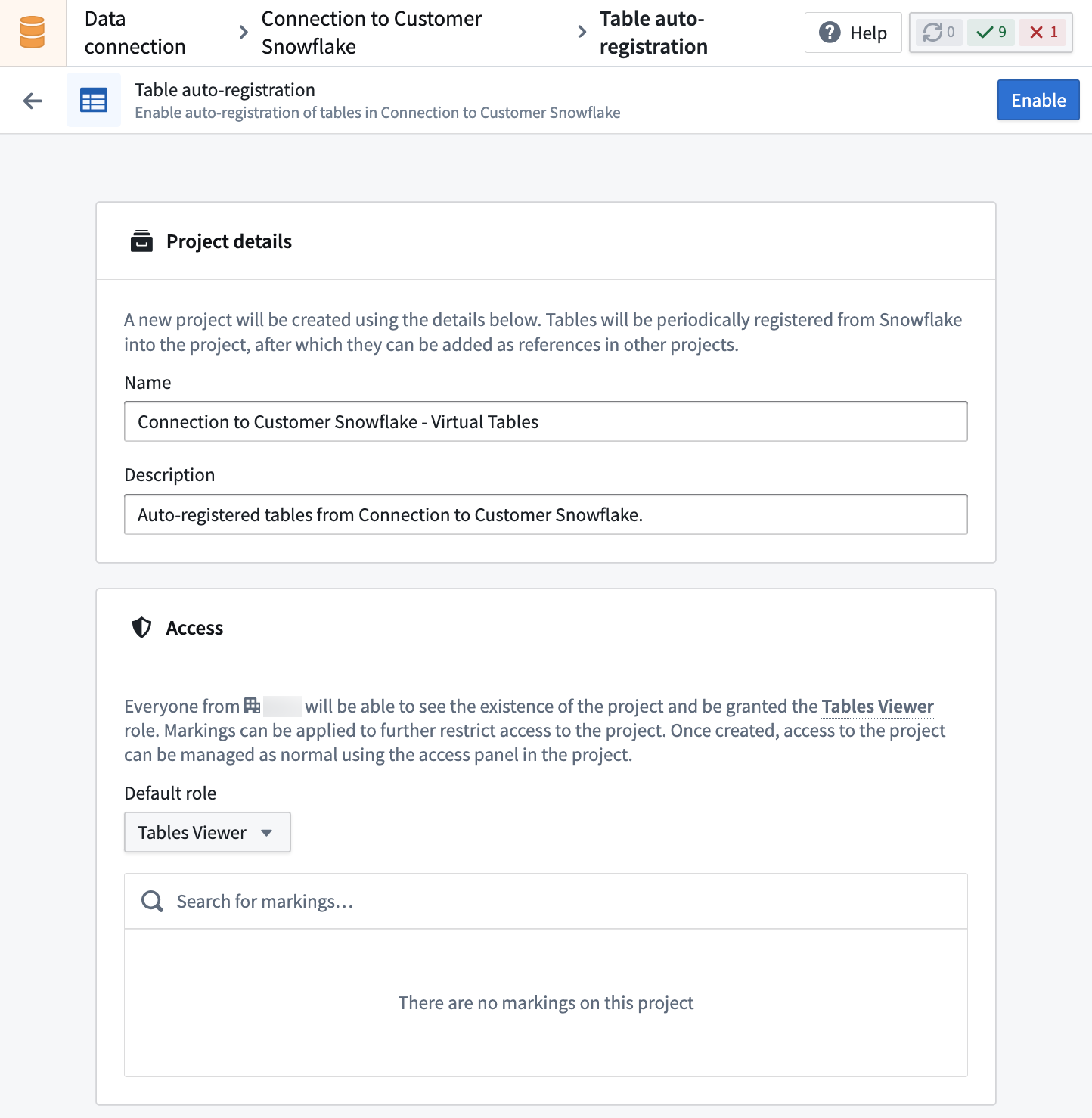
プロジェクトはFoundryによって管理され、ユーザーは手動でリソースを作成または更新できません。このプロジェクトに登録された仮想テーブルは、ワークフロー開発に使用するために他のプロジェクトにインポートできます。
自動登録を有効にすると、プロジェクトへのアクセス権限とアクセスを設定でき、その後プロジェクト所有者がアクセスサイドバーを使用して管理できます。
Code Repositoriesでの仮想テーブル
仮想テーブルがCode Repositoriesで使用される場合、それを消費するトランスフォームは、ソースで構成されたエグレスポリシーに基づいてネットワークエグレスを自動的に取得します。ソースで構成された資格情報は、ソースへの接続に利用可能となります。これは外部トランスフォームと同様の動作です。
ソースで次の設定が有効になっている必要があります:
- コードインポート: これにより、ソースがコードリポジトリにインポートされて使用できるようになります。この設定の詳細および有効化方法についてはこちらをご覧ください。
- 輸出規制: これにより、仮想テーブルを使用するPythonトランスフォームの入力に許可されるセキュリティマーキングおよび組織が制御されます。この設定の詳細および有効化方法についてはこちらをご覧ください。
ソースが設定されてコードリポジトリにインポートされると、仮想テーブルはデータセットと同様にPythonトランスフォームの入力として使用できます。transforms.api.Inputを使用します。インクリメンタル計算にはデータセットと一貫したAPIがあり、一部のソースでサポートされています。詳細についてはソース固有のドキュメントを参照してください。
仮想テーブルを使用する vs. データセットへの同期
仮想テーブルを使用するか、Foundryデータセットに同期するかの決定は、アーキテクチャの目標およびサポートされるターゲットワークフローに依存します。ワークフローごとに適切な統合パターンを検討することをお勧めします。この2つのアプローチは、互いに補完するために併用できます。
以下に、仮想テーブルを使用する場合とデータセットへの同期に関する利点、欠点、および制限についての考慮事項を示します。
仮想テーブルを使用する利点
仮想テーブルは、以下のような多くの利点を提供します:
- Foundryにソースデータを保存しないことによる重複ストレージの削減。Foundryは、パイプラインの出力として生成されたデータセットやオブジェクトなどの下流リソースのデータを引き続き保存します。
- クエリをソースシステムにプッシュダウンして、データ転送の総量を制限できます。プッシュダウン計算の可用性はソースシステムおよびクエリタイプによって異なります。
- 仮想テーブルは、重複ストレージコストが重要になる非常に大きなテーブルに特に有益です。
- 仮想テーブルを使用すると、データを同期したり、データの古さを考慮する必要なく、利用時に直接クエリが実行されます。
- 仮想テーブルは、Foundryの実装をターゲットアーキテクチャパターンに合わせるためのオプションを提供します。
仮想テーブルを使用する欠点
仮想テーブルがすべての状況で最適な選択であるとは限りません。以下のような考慮事項があります:
- インタラクティブなパフォーマンスは、Foundryデータセットに保存されたデータを操作する場合よりも遅くなる可能性があります。
- クエリの種類によっては、コンピューティング使用量が増加する可能性があります。たとえば、スケジュールされたパイプラインの入力として使用されるテーブルは、Contour分析でインタラクティブに頻繁にアクセスされるテーブルと比較して、限られたコンピューティングを生成する可能性があります。
- 仮想テーブルは、データセットのバージョン管理やブランチングなどのFoundryデータセット機能の恩恵を受けることができません。
仮想テーブルを使用する制限
仮想テーブルの制限には以下が含まれます:
- すべてのソースで仮想テーブルが利用できるわけではありません。
- 仮想テーブルには、ソースへの直接接続が必要です。エージェントを使用する接続はサポートされていません。
- すべてのFoundryアプリケーションおよび機能が仮想テーブルを入力としてサポートしているわけではありません。ただし、パイプラインの出力として生成されたデータセットやオブジェクトなど、仮想テーブルから生成された素材リソースは、通常通りFoundryエコシステム全体で完全にサポートされます。
仮想テーブルに対するクエリのためのコンピュート
仮想テーブルに対して直接実行されるクエリの場合、コンピュートはFoundryとソースシステムの間で分割されることがあります。具体的な動作は、クエリおよびソースシステムによってサポートされるプッシュダウン計算の度合いに依存します。詳細についてはソース固有のドキュメントを参照してください。