注: 以下の翻訳の正確性は検証されていません。AIPを利用して英語版の原文から機械的に翻訳されたものです。
Copied!1 2# transforms.external.systemsからexternal_systems, Sourceをインポートします from transforms.external.systems import external_systems, Source
ユーザーは external_systems デコレータを使用して、トランスフォームに含めるべきソースを指定する必要があります:
Copied!1 2 3 4 5 6# 外部システムとの連携を行うためのデコレータ @external_systems( # pokeSourceは、外部システムとの通信に使用する情報源を指定します # ここでは、"ri.magritte..source.e301d738-b532-431a-8bda-fa211228bba6"という情報源を指定しています pokeSource=Source("ri.magritte..source.e301d738-b532-431a-8bda-fa211228bba6") )
Copied!1 2# pokeSourceからHTTPS接続を取得し、そのURLをpokeUrlに設定します。 pokeUrl = pokeSource.get_https_connection().url
Copied!1 2 3 4 5 6pokeUrl = pokeSource.get_https_connection().url pokeClient = pokeSource.get_https_connection().get_client() # pokeClientはPythonの `requests` ライブラリから事前設定されたSessionオブジェクトです。 # GETリクエストの例: response = pokeClient.get(pokeUrl + "/api/v2/pokemon/" + name, timeout=10)
エージェントプロキシを使用してオンプレミスシステムに接続する場合、必要なエージェントプロキシの設定が自動的に行われるため、ビルトインクライアントを 必ず 使用しなければなりません。
エージェントプロキシはベータ機能であり、ユーザーのエンロールメントによっては利用できない場合があります。
例:PokeAPIからデータをインポートする
以下の例は、APIが返すすべてのポケモンを一度に100ずつ取得し、すべてのポケモンの名前をデータセットに出力する完全なトランスフォームを示しています。
Copied!1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38from transforms.api import transform_df, Output from transforms.external.systems import external_systems, Source from pyspark.sql import Row import json import logging logger = logging.getLogger(__name__) # 外部システムとの連携を設定 @external_systems( # リポジトリにインポートされたソースを指定 pokeSource=Source("ri.magritte..source.e301d738-b532-431a-8bda-fa211228bba6") ) @transform_df( # この変換では入力を使用せず、出力データセットのみを指定 Output("/path/to/output/dataset") ) def compute(pokeSource, ctx): poke = pokeSource.get_https_connection().get_client() pokeUrl = pokeSource.get_https_connection().url data = [] startUrl = pokeUrl + "/api/v2/pokemon?limit=100&offset=0" while startUrl is not None: # これ以上ページがないまでループする logger.info("PokeAPIからデータを取得しました:" + startUrl) # PokeAPIソースの組み込みHTTPSクライアントを使用して、ページごとに最大100のポケモンを取得 response = poke.get(startUrl) responseJson = json.loads(response.text) for pokemon in responseJson["results"]: data.append(Row(name=pokemon["name"])) startUrl = responseJson["next"] # 外部システムから取得し、解析したデータを出力データセットに書き込む return ctx.spark_session.createDataFrame(data)
外部トランスフォームで Foundry 入力を使用する
外部トランスフォームでは、Foundry の入力データを使用することがよくあります。たとえば、表形式のデータセットの各行に対して追加のメタデータを収集するために API をクエリする可能性があります。または、Foundry のデータを外部のソフトウェアシステムにエクスポートする必要があるワークフローがあるかもしれません。
このようなケースは、安全な Foundry データを未知のセキュリティ保証および切断されたデータフローを持つ別のシステムにエクスポートする可能性があるため、輸出規制 ワークフローと見なされます。ソース接続を設定するとき、ソース所有者は Foundry からのデータがエクスポートできるかどうかを指定し、セキュリティマーキングと組織のセットを提供する必要があります。Foundry は、開発者がセキュリティ意図を明確にコード化できるように、そして情報セキュリティオフィサーが外部システムとやり取りするワークフローの範囲と意図を監査できるように、ガバナンス制御を提供します。
ソースの輸出規制を設定する
輸出は セキュリティマーキング を使用して制御されます。ソースを設定するとき、輸出設定は外部システムにエクスポートするのに安全なセキュリティマーキングと組織を指定するために使用されます。これは、データ接続アプリケーションでソースに移動し、次に 接続設定 > エクスポート設定 タブに移動することで行われます。次に、このソースへのエクスポートを有効にする オプションをオンにし、エクスポートする可能性があるマーキングと組織のセットを選択する必要があります。
これを行うには、エクスポートは Foundry 内のデータのマーキングを削除することと同等と見なされるため、関連するデータと組織のマーキングを削除する権限が必要です。
以下の操作を許可するために、このソースへのエクスポートを有効にする の設定をオンにする必要があります:
- このソースをインポートする Python トランスフォームコードへの入力としてデータセット、メディアセット、ストリームを使用する。
- Python トランスフォームでこのソースに登録された仮想テーブルを使用する。
以下は、Palantir 組織からのデータを、追加のセキュリティマーキングなしで PokeAPI にエクスポートできるようにする PokeAPI ソースのエクスポート設定の例です:
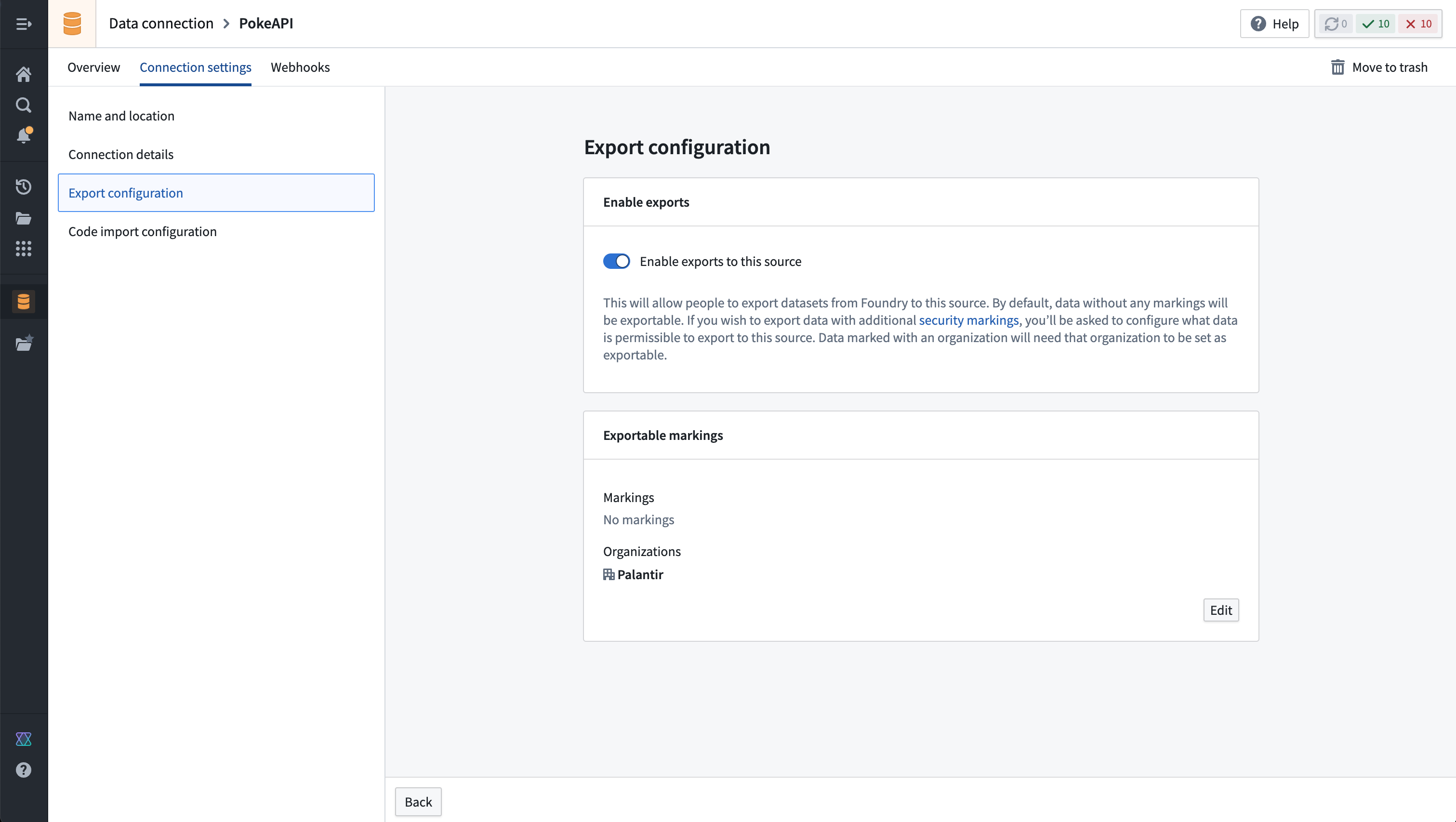
実際にはこのシステムにデータをエクスポートしない場合でも、同じ計算ジョブに Foundry データ入力を許可し、このシステムへの開放接続を意味するため、このソースへのエクスポートを有効にする はオンにしなければなりません。これは、データがエクスポートされる可能性があることを意味します。
例:PokeAPI からのデータと並行して Foundry インポートを使用する
この例では、ポケモンの名前の入力データセットから始め、PokeAPI を使用して、各ポケモンの高さと重さを含む豊かなデータセットを出力します。また、レスポンスのステータスコードに基づく基本的なエラーハンドリングも示されています。
Copied!1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42from transforms.api import transform_df, Output, Input from transforms.external.systems import external_systems, Source from pyspark.sql import Row import json import logging logger = logging.getLogger(__name__) @external_systems( # 外部システムからの情報源 pokeSource=Source("ri.magritte..source.e301d738-b532-431a-8bda-fa211228bba6") ) @transform_df( # PokeAPIから取得した豊富なポケモンデータの出力データセット Output("/path/to/output/dataset"), # ポケモン名の入力データセット pokemonList=Input("/path/to/input/dataset") ) def compute(pokeSource, pokemonList, ctx): poke = pokeSource.get_https_connection().get_client() pokeUrl = pokeSource.get_https_connection().url def make_request_and_enrich(row: Row): name = row["name"] response = poke.get(pokeUrl + "/api/v2/pokemon/" + name, timeout=10) if response.status_code == 200: data = json.loads(response.text) height = data["height"] weight = data["weight"] else: # ステータスコードが200以外の場合、リクエストが失敗したと警告をログに出力します。 logger.warn(f"{name}のリクエストがステータスコード{response.status_code}で失敗しました。") height = None weight = None return Row(name=name, height=height, weight=weight) # ポケモンリストの各行に対してリクエストを作成し、データを補完します。 return pokemonList.rdd.map(make_request_and_enrich).toDF()