注: 以下の翻訳の正確性は検証されていません。AIPを利用して英語版の原文から機械的に翻訳されたものです。
外部トランスフォーム
外部トランスフォームを使用すると、送信ポリシー、資格情報の値、輸出規制マーキングに直接リファレンスできます。新しいソースベースの外部トランスフォームは、これらの設定を含むData Connection sourceを単一のリソースにインポートすることで主に機能します。
ソースベースの外部トランスフォームの主な利点は以下の通りです。
- インターネットからアクセスできないシステムへの接続。
- コードを変更せずに資格情報をローテーション/更新する。
- 複数のリポジトリ間で接続設定を共有する。
- 選択したソースタイプに対する標準の Python クライアント。
- 外部トランスフォームリポジトリの有効化と管理のためのガバナンスワークフローの改善と簡素化。
- Data Lineageにおいて外部ソースに接続された外部トランスフォームの可視化。
ソースベースの外部トランスフォームの使用に関する詳細は、ドキュメントを参照してください。
Code Repositories で Python トランスフォームを使用して、コード内で直接外部システムに接続できます。たとえば、外部システムと対話するための複雑なロジックが必要な場合や、サードパーティが提供するソフトウェア開発キット(SDK)を使用したい場合に役立ちます。外部トランスフォームを使用して、REST API を使用したスケジュールされた同期やエクスポートを実行することをお勧めします。
続行する前に、Python transforms code repositoryを作成し、以下の指示に従って構成してください。
外部システムに接続するトランスフォームは、Foundry の入力を使用しない場合にのみ、Code Repositories のプレビュー ヘルパーを使用してプレビューできます。
Code Repositories で外部接続を設定する
このセクションでは、外部トランスフォームを使用するために必要な構成について説明します。
外部トランスフォームは、SECURE モードで実行されているリポジトリでのみ使用できます。代替のセキュリティモードについては、Palantir の担当者にお問い合わせください。
外部システムとの対話を有効にする
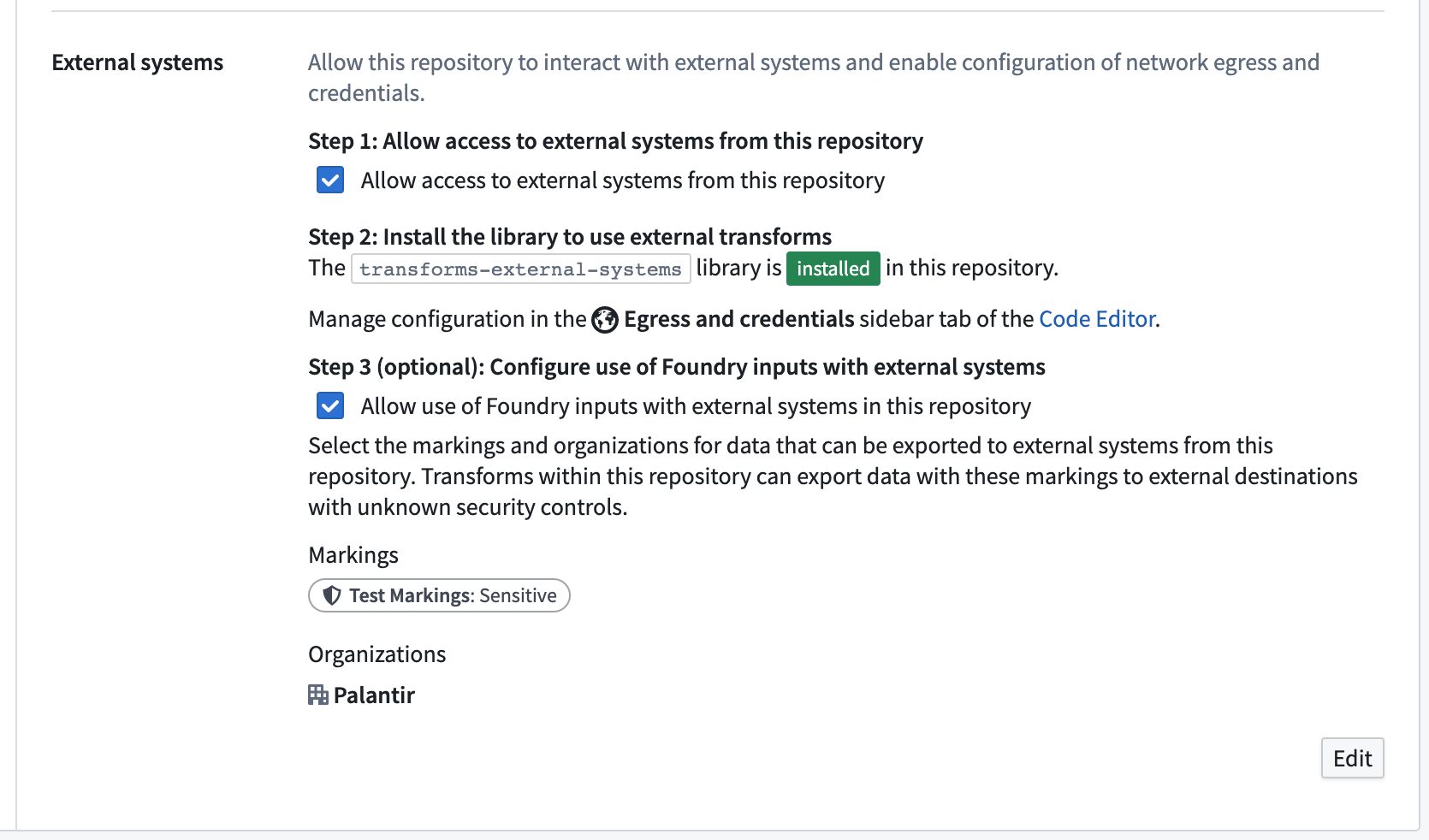
作成したコードリポジトリ内で、Information Security Officer ロールを持つ Foundry ユーザーが、リポジトリ Settings タブに移動し、Repository > External systems に移動して、Allow access to external systems from this repository オプションをオンにします。
Information Security Officer は Foundry のデフォルトロールです。ユーザーは Control Panel の Enrollment permissions で Information Security Officer ロールを付与されることができます。

データセット入力を有効にする
Information Security Officer ロールを持つ Foundry ユーザーは、オプションで外部トランスフォームでの入力の使用を許可することができます。
データセットが外部システムと通信できるトランスフォームの入力として使用される場合、そのデータセット内のデータは Foundry を離れる可能性があります。Information Security Officer ロールを持つ Foundry ユーザーは、このリポジトリで外部トランスフォームの入力として許可されるデータに対して、セキュリティマーキングと組織マーキングのセットを選択する必要があります。
たとえば、Palantir 組織の Sensitive マーキングを持つデータセットがあるとします。このデータセットを外部トランスフォームで使用するには、Information Security Officer がコードリポジトリ設定のステップ 3、Configure use of Foundry inputs with external systems で Sensitive マーキングと Palantir 組織の両方を追加する必要があります。
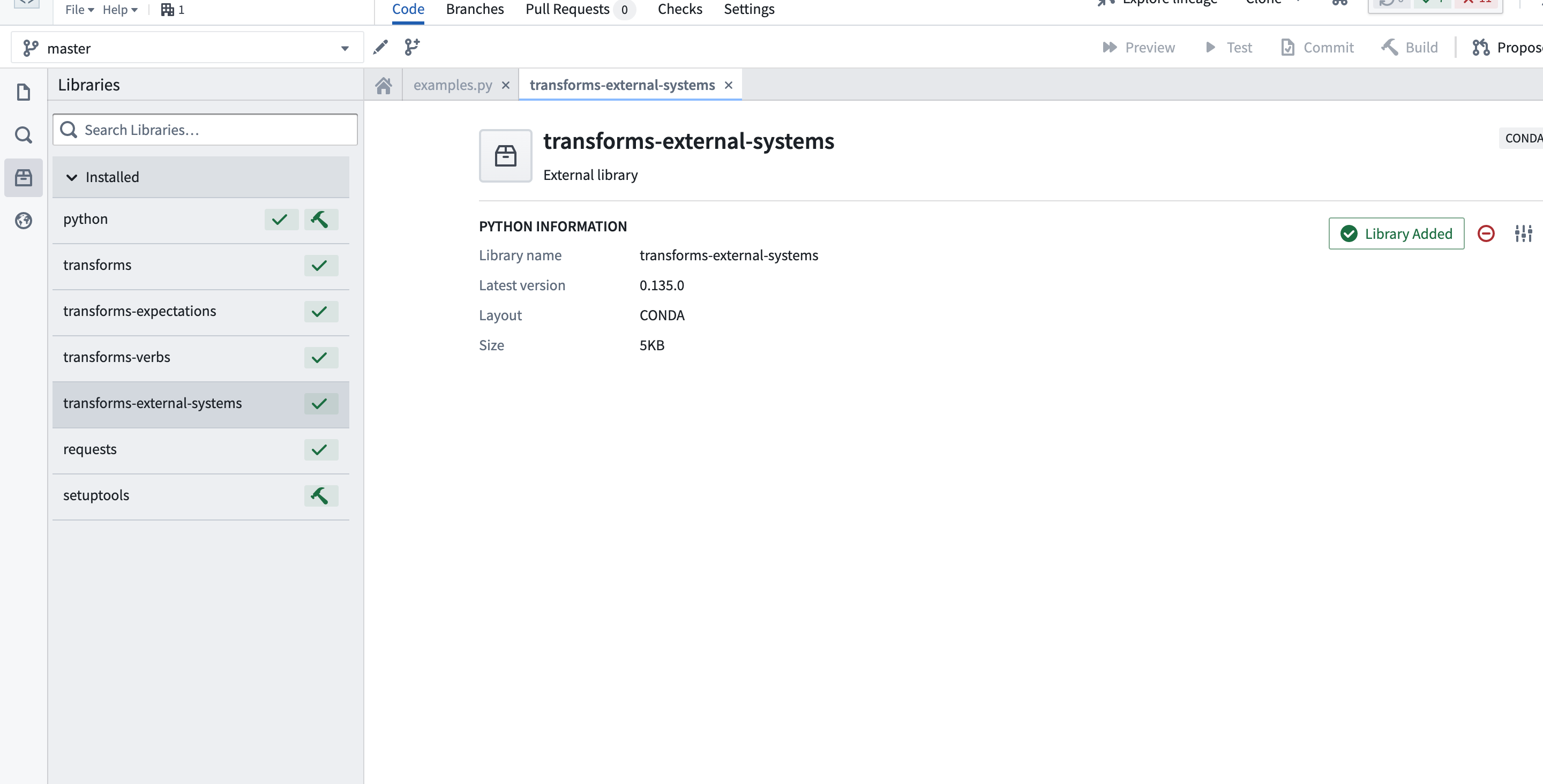
transforms-external-systems ライブラリを追加する
コードリポジトリで外部システムの対話が有効になったら、コードインターフェースの左側にある Libraries サイドバータブ から transforms-external-systems ライブラリを追加する必要があります。
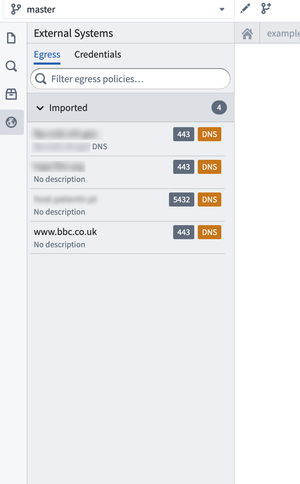
送信ポリシーと資格情報を構成する
ライブラリを追加した後、コードインターフェースの左側に新しい Egress and Credentials タブにアクセスできます。
このタブで、コードから呼び出されるエンドポイントに必要なネットワーク送信ポリシーを設定し、リポジトリで使用する資格情報を追加できます。すべてのエンドポイントが資格情報を必要とするわけではないことに注意してください。
ネットワーク送信ポリシーと資格情報を使用する
送信ポリシーを追加する
Foundry では、ユーザーが作成したコードから開始されるすべての接続が、外部の宛先に到達する際にネットワーク送信ポリシーに付属する必要があります。ネットワーク送信ポリシーにより、ユーザーが作成したコードから開始された許可された接続が Foundry 外の宛先に到達できます。
セルフサービス送信がユーザーのエンロールメントで有効になっている場合は、Control Panel で送信ポリシーを作成および管理できます。接続に新しいネットワークルートを追加する必要がある場合は、送信ポリシーの詳細を持って Information Security Officer または Palantir の担当者に連絡してください。
Foundry インスタンスでセルフサービス送信が有効になっていない場合は、Palantir の担当者に連絡して、エンドポイントを内部的に有効にし、ポリシーを構成してください。
外部トランスフォームに送信ポリシー(グローバルまたは非グローバル)を使用する前に、コードリポジトリの Egress and Credentials パネルの Egress タブからそれらをインポートする必要があります。Egress タブには、ユーザーが権限を持つすべてのポリシーが表示され、3 つのカテゴリに分類されます。
- Imported: 現在のコードリポジトリでトランスフォームから使用するために準備されたネットワーク送信ポリシー。
- Importable: ネットワーク送信ポリシーにプロジェクトのリファレンスを追加する必要があります。
- Access request required: ポリシーに対する
Viewer権限を持っているがImporter権限を持っていない場合。
このタブ内で、目的のネットワーク送信ポリシーを検索します。ポリシーが Importable とマークされている場合、それを選択し、Import egress policy to project を選択します。
目的のネットワーク送信ポリシーが Access request required とマークされている場合は、Information Security Officer ロールを持つ Foundry ユーザーが Control Panel の Network egress ページでユーザーに Importer ロールを付与する必要があります。Importer ロールを付与するには、Information Security Officer がまず目的のネットワークポリシーを選択し、次に Actions > Manage Sharing を選択してユーザーをポリシーの Importer として追加する必要があります。
資格情報を追加する
外部システムがアクセス権を得るために認証済みの資格情報(ユーザー名とパスワード)を必要とする場合は、Egress and Credentials サイドパネルの Credentials タブを使用して資格情報のセットを追加し、コードで使用できます。
ソースエンドポイントに許可リストプロセスがある場合は、Foundry IP アドレスを許可リストに追加する必要があります。必要な IP アドレスについては、Palantir の担当者にお問い合わせください。
証明書を渡す
外部システムが SSL/TLS 証明書を渡す必要がある場合は、証明書を資格情報に保存し、外部トランスフォームロジックで資格情報を使用できます。
外部トランスフォームロジックを書く
Python データトランスフォームを外部システムに書き込む準備が整いました。外部トランスフォームを書く前に、Python データトランスフォームを書く ための基本的な指示を確認することをお勧めします。
transforms.external.systems パッケージから、必要な use_external_systems デコレータと EgressPolicy および Credential(必要な場合)入力をインポートします。transforms-api から、トランスフォームデコレータと Output をインポートします。外部ソースが資格情報を必要としない場合、ロジックに Credential 入力を追加する必要はありません。
外部トランスフォームロジックを正常に書くには、use_external_systems デコレータを使用する必要があります。
以下の例は、2 つのデコレータの使用方法を示しています。
Copied!1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17# transforms.apiからtransform, Outputをインポートします from transforms.api import transform, Output # transforms.external.systemsからuse_external_systems, EgressPolicy, Credentialをインポートします from transforms.external.systems import use_external_systems, EgressPolicy, Credential # 外部システムを使用するためのデコレータ。エアグレスポリシーと認証情報を指定します @use_external_systems( egress=EgressPolicy('<policy RID>'), # ここにポリシーのRIDを入力します creds=Credential('<credential RID>') # ここに認証情報のRIDを入力します ) # transformデコレータ。出力データセットのパスを指定します @transform( output=Output('/path/to/output/dataset') # ここに出力データセットのパスを入力します ) # 主要な計算機能 def compute(egress, creds, ...): # egressとcredsとその他の引数を受け取ります # ...
その後、APIにアクセスするためのシンプルなトランスフォームを設定できます:
Copied!1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20from transforms.api import transform, Output from transforms.external.systems import EgressPolicy, use_external_systems, Credential import requests @use_external_systems( egress=EgressPolicy('<policy RID>'), # 外部システムへの出口ポリシーを設定 creds=Credential('<credential RID>') # 認証情報を設定 ) @transform( output=Output('/path/to/output/dataset') # 出力データセットのパスを設定 ) def compute(egress, output, creds): # 関数定義 username = creds.get('username') # ユーザー名を取得 password = creds.get('password') # パスワードを取得 # APIからのレスポンスを取得(認証情報とタイムアウト設定付き) response = requests.get('https://<API URL>', auth=(username, password), timeout=10).text # レスポンスをJSONファイルとして出力 with output.filesystem().open('response.json', 'w') as f: f.write(response)
また、以下の例に示すように、1つのトランスフォームで複数のエグレスポリシーや資格情報を指定することもできます。
Copied!1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16from transforms.api import transform, Output from transforms.external.systems import use_external_systems, EgressPolicy, Credential # 外部システムを利用するためのデコレータを設定します @use_external_systems( egress1=EgressPolicy('<first policy RID>'), # 第1のエグレスポリシー egress2=EgressPolicy('<second policy RID>'), # 第2のエグレスポリシー creds1=Credential('<first credential RID>'), # 第1の資格情報 creds2=Credential('<second credential RID>') # 第2の資格情報 ) @transform( output=Output('/path/to/output/dataset') # 出力データセットへのパスを指定します ) def compute(egress1, egress2, creds1, creds2, ...): # ここにコードを記述してください # ...
Foundry データセットの入力を追加
場合によっては、Foundry の入力データを処理する外部トランスフォームを書くと便利なことがあります。たとえば、表形式のデータセットの各行に対して追加のメタデータを収集するために API をクエリする場合などです。また、Foundry のデータを外部のソフトウェアシステムにミラーリングする必要があるワークフローがあるかもしれません。
このようなケースは、安全な Foundry データを未知のセキュリティ保証とデータフローの切断がある他のシステムにエクスポートする可能性を開くため、輸出規制ワークフローと考えられます。エクスポートワークフローのセキュリティを評価し、Foundry を離れるデータが外部システムで正しく保護されていることを確認するのは、トランスフォーム開発者の責任です。Foundry は、開発者が明確にセキュリティの意図をコード化できるようにし、情報セキュリティオフィサーが外部システムとやり取りするワークフローの範囲と意図を監査できるように、ガバナンスコントロールを提供します。
輸出規制を適用するためには、ExportControl をユーザーの外部トランスフォームに適用します。ExportControl は、エクスポートを意図したセキュリティマーキングと組織 ID のリストを受け入れます。その後、上流のデータに追加のセキュリティマーキングが付けられている場合、トランスフォームジョブは必ず失敗します。コードリポジトリでサポートされるエクスポート可能なマーキングのセットを拡張するには、情報セキュリティオフィサーがリポジトリの設定を調整する必要があります。設定 > リポジトリ タブに移動します。次に、外部システムセクションで、ステップ 3 の下の このリポジトリで Foundry の入力を外部システムと使用を許可する を選択します。
セキュリティマーキングと組織は両方ともマーキングとして実装されており、エクスポート制御の設定に一緒にリストアップする必要があります。欠落しているマーキングに関するエラーメッセージは、セキュリティマーキングまたは組織を指している可能性があります。
例として、Foundry データセットで指定された画像 URL をダウンロードするために、エクスポート外部トランスフォームを使用することができます。
Copied!1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27from transforms.api import transform, Input, Output from transforms.external.systems import use_external_systems, ExportControl, EgressPolicy from pyspark.sql.functions import udf import shutil # 外部システムを使用する設定 @use_external_systems( export_control=ExportControl(markings=['<marking ID>']), # エクスポート制御の設定 egress=EgressPolicy(<policy RID>), # エグレスポリシーの設定 ) @transform( images_output=Output('/path/to/output/dataset'), # 画像出力先のパス image_urls=Input('/path/to/input/dataset'), # 画像URL入力元のパス ) def compute(export_control, egress, images_output, image_urls): # 画像をダウンロードするUDF @udf def download(name, url): response = requests.get(url, stream=True) # 画像URLからデータを取得 with images_output.filesystem().open(f'{name}.jpg', mode='wb') as out_file: shutil.copyfileobj(response.raw, out_file) # データを出力先ファイルに書き込む return True # 画像URLのデータフレームにダウンロード結果を追加し、処理を実行 image_urls.dataframe().withColumn('downloaded', download(col('Name'), col('Url'))).collect()
Foundry メディアセットアウトプットの追加 (ベータ版)
メディアセットのアウトプットは開発のベータ段階にあり、ユーザーのエンロールメントには利用可能でない場合があります。
画像、オーディオ、PDFなどのメディアファイルを取り込むために外部トランスフォームを使用する際、ファイルを メディアセット に書き出したい場合があります。メディアアイテムを既存のメディアセットに書き込むには、プログラム的にアイテムを指定されたメディアセットアウトプットに置くことが必要です:
Copied!1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26from transforms.api import transform from transforms.mediasets import MediaSetOutput from transforms.external.systems import use_external_systems import requests import tempfile # 外部システムを使用するためのデコレータ @use_external_systems() # メディアセットを出力するためのデコレータ。出力パスを指定する。 @transform( media_set_output=MediaSetOutput('/path/to/output/media/set') ) def compute(media_set_output): # APIからデータを取得 response = requests.get('https://<API URL>') fname = 'my_image.png' # 一時ファイルを作成し、APIから取得したデータを書き込む with tempfile.NamedTemporaryFile() as tmp: tmp.write(response.content) tmp.flush() # 一時ファイルを読み込み、メディアセットとして出力 with open(tmp.name, 'rb') as tmp_read: media_set_output.put_media_item(tmp_read, path=fname)
外部システムへのさらなる接続方法
APIサービスとのやり取り
外部システム内に存在するAPIサービスにプログラムでアクセスして使用できます。たとえば、外部トランスフォームからMapbox Static Images API ↗を使用して、Foundryのデータセットに地図画像を出力できます。
Copied!1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33# 必要なライブラリをインポートします from transforms.external.systems import EgressPolicy, use_external_systems, Credential from transforms.api import transform, Output from mapbox import Static # 外部システムを使用するためのデコレータを設定します # EgressPolicyとCredentialは事前に設定が必要です @use_external_systems( egress=EgressPolicy('<policy RID>'), mapbox_creds=Credential('<credential RID>') ) # 出力先のパスを設定します @transform( output=Output('/Users/username/datasets/example_mapbox'), ) # メインの処理を行う関数を定義します def compute(output, egress, mapbox_creds): # Mapboxのアクセストークンを取得します mapbox_access_token = mapbox_creds.get('mapbox-token') # アクセストークンを使用してMapboxのクライアントを作成します client = Static(access_token=mapbox_access_token) # ロンドンの衛星画像を取得します london = client.image('mapbox.satellite', lat=51.5072, lon=0.0, z=12) # レスポンスコードをログに出力します with output.filesystem().open('london.log', 'w') as f: f.write(f'response code: {london.status_code}') # レスポンス画像の一時保存場所を作成します with open('london.png', 'wb') as f: f.flush() # 画像を最終的な出力先に保存します with output.filesystem().open('london.png', 'wb') as f: f.write(london.content)
データセットファイルとの対話
ユーザーは、通常のトランスフォームと同様に、プログラムでファイルを開き、ストリームし、対話することができます。非構造化ファイルの読み書きについて詳しくはこちらをご覧ください。
増分処理
ユーザーは、通常のトランスフォームと同様に、外部トランスフォームを増分的に実行することができます。
外部増分トランスフォームでは、実行間で状態を維持することがよく必要となります。通常の増分トランスフォームでは、入力ファイルが追跡され、最新のトランザクションと比較されます。外部増分トランスフォームでは、増分状態を明示的に別の方法で保存する必要があります。一つの選択肢は、最新の増分トランスフォームの状態を保持する状態ファイルを保存することです。以下の例をご覧ください:
Copied!1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63from transforms.api import transform, Input, Output, configure, incremental from pyspark.sql import Row from pyspark.sql import functions as F from pyspark.sql import types as T import logging import time import json log = logging.getLogger(__name__) @incremental() @configure(profile=["KUBERNETES_NO_EXECUTORS"]) @use_external_systems( egress=EgressPolicy('<policy RID>'), creds=Credential('<credential RID>') ) @transform( out=Output("<output_dataset>"), ) def compute(ctx, out, egress, creds): # 出力データセットのファイルシステムを取得して、ファイルを読み書きします: out_fs = out.filesystem() state_filename = "_state.json" # "_"で先頭につけることで隠しファイルとし、データセットのプレビューに表示しません。 state = {"last_seen" : 0} # 任意の開始状態 # 出力データセットから状態を取得しようとします: try: with out_fs.open(state_filename, mode='r') as state_file: data = json.load(state_file) # 取得した状態を検証します: state = data logging.info(f"state file found, continuing from : {data}") except Exception as e: logging.warn("state file not found, starting over from default state") # ここでは、API呼び出しを行い、カスタム処理を作成し、データフレームを生成して保存する、または直接出力データセットにファイルを保存するロジックを書く。 # 例として、以下ではデータフレームを生成し、出力データセットに保存しています(API呼び出しでデータを取得したかのように): out.write_dataframe(get_dataframe(ctx)) # 次の反復のために状態を更新します: state["last_seen"] = 1 + state["last_seen"] # 新しい状態を出力データセットに保存します: with out_fs.open(state_filename, "w") as state_file: json.dump(state, state_file) # この関数は例示のためのデータフレームを生成します。このステップは本番実装では不要です: def get_dataframe(ctx): # データフレームのスキーマを定義します: schema = T.StructType([ T.StructField("name", T.StringType(), True), T.StructField("age", T.IntegerType(), True), T.StructField("city", T.StringType(), True) ]) # 行のリストを作成します: data = [("Alice", 25, "New York"), ("Bob", 30, "San Francisco"), ("Charlie", 35, "London")] # PySparkデータフレームを作成します: df = ctx.spark_session.createDataFrame(data, schema=schema)