注: 以下の翻訳の正確性は検証されていません。AIPを利用して英語版の原文から機械的に翻訳されたものです。
変更データキャプチャ (CDC)
変更データキャプチャ ↗ (CDC) は、リレーショナルデータベースから他のコンシューマーにリアルタイムで更新をストリームするために使用されるエンタープライズデータ統合パターンです。
Foundry は、変更データキャプチャフィードを生成するシステムからデータを同期、処理、および保存することをサポートしています。プラットフォーム全体のコンポーネント、たとえば データコネクター、ストリーム、パイプライン、および Foundry オントロジー は、元データの スキーマ に構成されたメタデータを使用して、この変更ログデータをネイティブに扱うことができます。
変更ログメタデータには、以下の属性がデータに必要です:
- 1 個以上の主キー列
- 変更ログデータには、同一の主キー列を持つ多くのエントリが含まれます。これは、主キーを持つレコードに発生したすべての個別の変更を伝えるためです。変更データキャプチャは、不変または追加専用のデータフィードよりも、編集されているデータに特に有用です。
- 1 個以上の順序列
- 順序列は数値でなければならず、特定の主キーセットを持つレコードの変更の相対的な順序を決定するために使用されます。順序列はしばしば long 表現のタイムスタンプですが、必ずしもそうとは限りません。最大値が最も新しいと見なされますが、順序列がタイムスタンプでない場合でも同様です。
- 削除列
- 削除列は、特定の主キーセットを持つレコードが削除されたかどうかを判断するために使用されます。これは、レコードが削除された場合は true でなければならず、それ以外の場合は false である必要があります。
この変更ログメタデータは、変更ログをソースシステムの現在のデータビューに解決するための解決戦略を指定するために使用されます。変更データキャプチャの解決戦略は次のように機能します:
- 主キー列に基づいてデータをグループ化します。
- 順序列で最大値を持つエントリを見つけます。
- このエントリが削除列で true の値を持つ場合、それを削除します。
これらの手順の後、変更ログは、変更ログを生成している上流のソースシステムで見るのと同じビューに圧縮されるはずです。変更ログメタデータと解決戦略は、以下に示すように、さまざまな Palantir コンポーネントによって異なる方法で使用されます。
Data Connection における変更データキャプチャ
Data Connectionで利用可能なソースは、変更ログメタデータが適用されたストリームとしてシステムからのデータ同期をサポートすることがあります。ソースが変更ログデータの同期機能を実装できるかどうかは、ソースシステムが必要な属性(主キー列、順序列、削除列)を持つログデータを生成できるかどうかに依存します。
MySQL、PostgreSQL、Oracle、Db2、および SQL Server を含む多くの一般的に使用されるデータベースは、CDC 変更ログデータを生成できます。これらのシステムのための Foundry のデータコネクターは、これらの変更ログを直接同期することをサポートする場合としない場合があります。コネクターが現在 CDC 同期をサポートしていない場合でも、Kafka やその他のストリーミングミドルウェアを介してデータを同期し、Foundry に到着したデータを変更ログとして使用することができます。
Data Connection で現在 CDC 同期をサポートしているソースタイプは次のとおりです:
- Microsoft SQL Server
- PostgreSQL
さらに、実験的なコネクターを通じて次のシステムでも CDC 同期が利用可能です。このコネクターを使用したい場合は、Palantir の担当者にお問い合わせください。
- Oracle
- MySQL
Kafka、Kinesis、Amazon SQS などの他のソースから変更ログ形式のデータが利用可能な場合や、ストリームとのプッシュベースの統合の場合は、Pipeline Builder のキー・バイ・ボードを使用して変更ログメタデータを手動で構成する方法を参照してください。
外部データベースで変更データキャプチャを有効にする
サポートされているソースタイプから変更ログフィードを同期するには、関連するテーブルおよび場合によってはデータベース全体に対して適切な設定を有効にする必要があります。
たとえば、Microsoft SQL Server の変更データキャプチャを有効にするには、CDC をデータベースで有効にするコマンドを実行する必要があります:
Copied!1 2 3 4 5 6 7-- データベースを指定する USE <database> GO -- 変更データキャプチャ (Change Data Capture, CDC) を有効にするシステムストアドプロシージャを実行する EXEC sys.sp_cdc_enable_db GO
次に、変更ログを記録する必要がある各テーブルで別のコマンドを実行します。
EXEC sys.sp_cdc_enable_table
@source_schema = N'<schema>' -- ソーススキーマ名を指定
, @source_name = N'<table_name>' -- ソーステーブル名を指定
, @role_name = NULL -- キャプチャーの役割名(NULLの場合はデフォルトの役割が使用される)
, @capture_instance = NULL -- キャプチャーインスタンス名(NULLの場合はデフォルトのインスタンス名が生成される)
, @supports_net_changes = 0 -- ネット変更のサポート(0の場合はサポートしない)
, @filegroup_name = N'PRIMARY'; -- キャプチャーデータの保存先ファイルグループを指定
GO
上記の例は、ソースシステムが変更ログデータを生成するために必要な事項を高レベルで説明しています。特定のシステムで変更データキャプチャログを有効にする方法についての詳細は、該当システムが提供するドキュメントを参照してください。
変更データキャプチャ用のソース接続を設定する
次に、変更ログをキャプチャしたいシステムに接続する Data Connection でソースを設定します。例を続けると、以下のように Microsoft SQL Server コネクターを使用して接続を設定します。
変更データキャプチャ同期を作成する
ソースの概要ページに CDC Syncs の空のテーブルが表示されます。
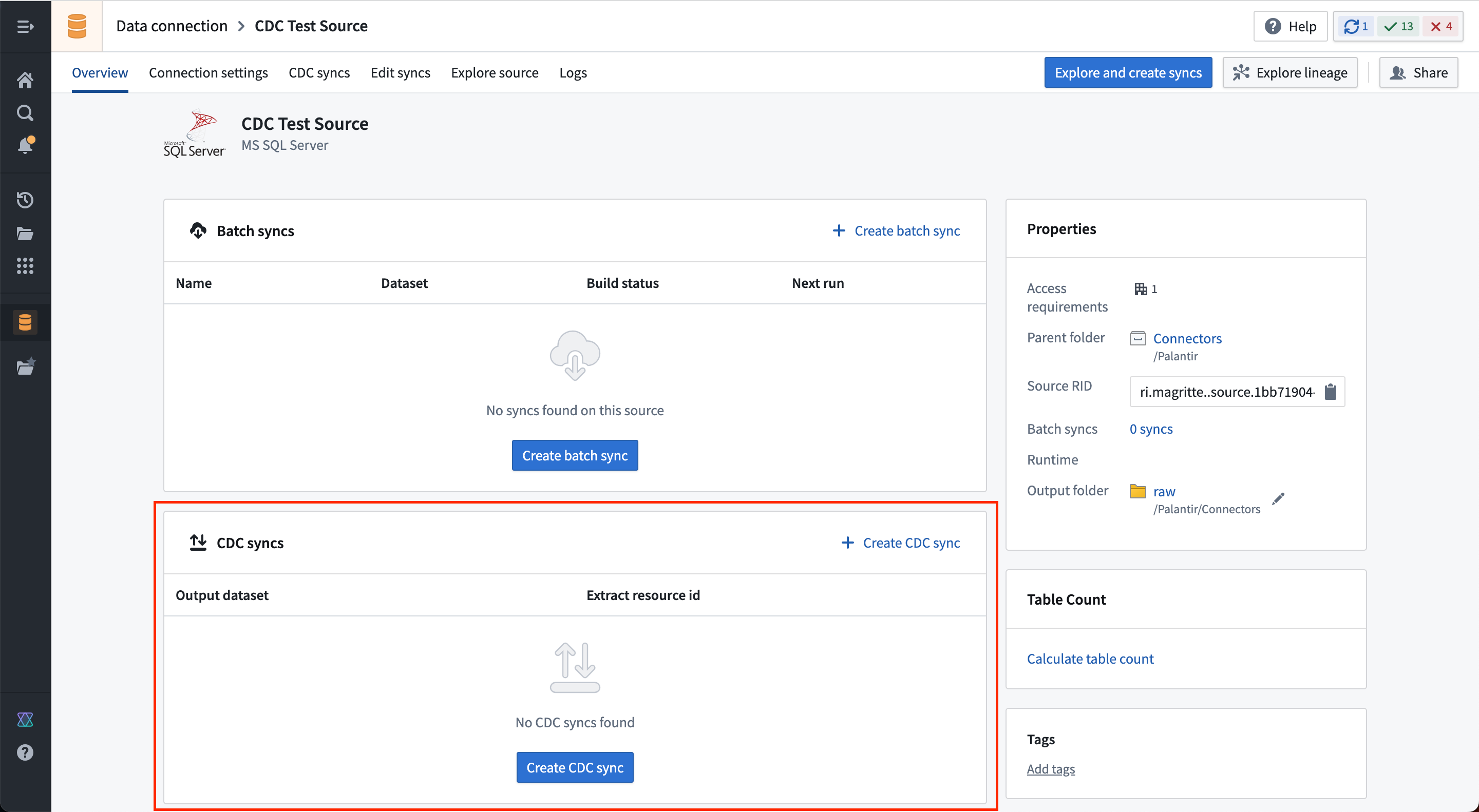
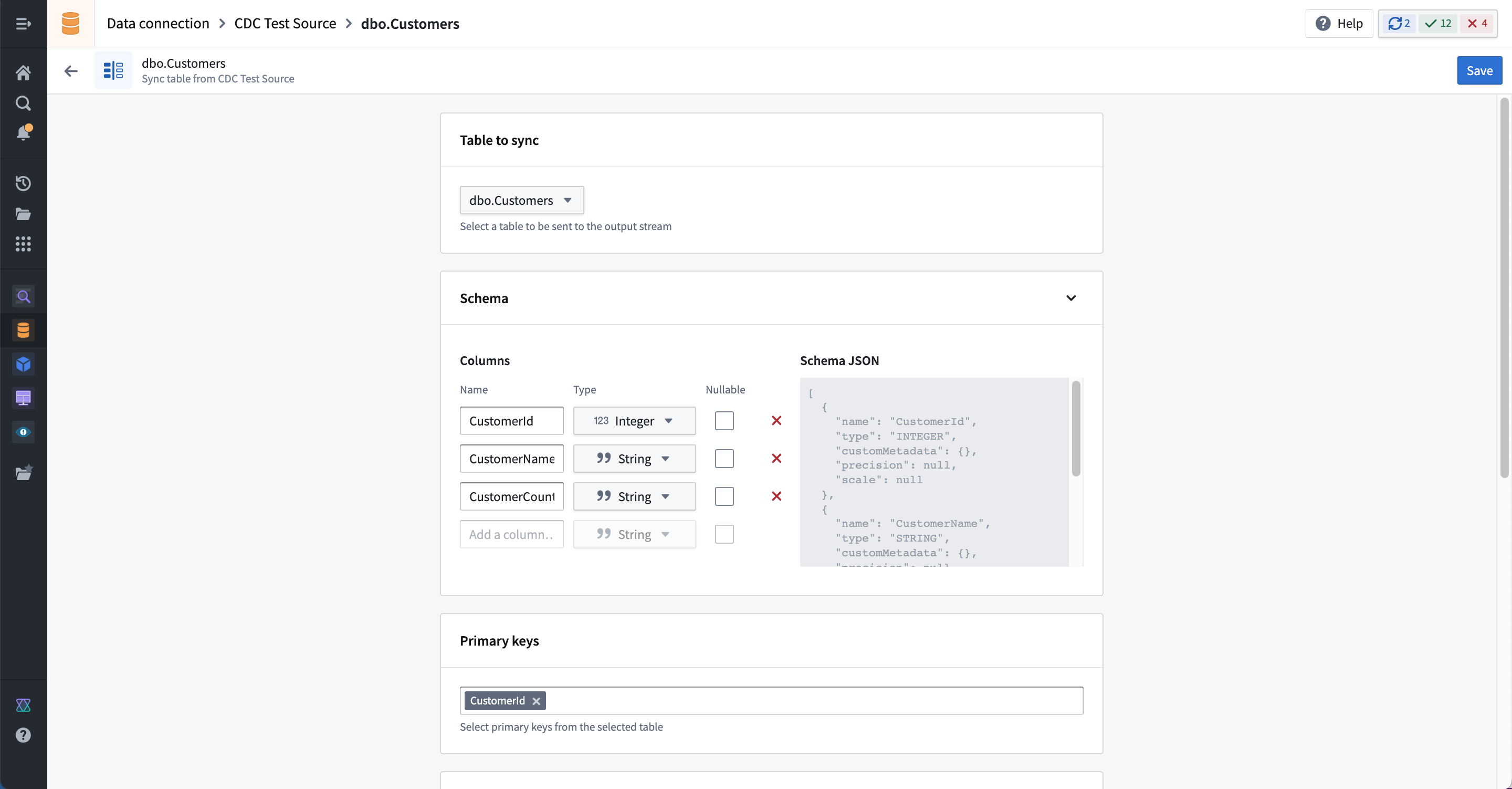
Create CDC sync を選択して新しい変更データキャプチャ同期を追加します。同期したいテーブルを指定すると、以下の情報がコネクターによって自動的に導出されます。
- 出力ストリーミングデータセットのスキーマ
- 主キー列、順序列、および削除列を含む変更ログメタデータ
他のストリームと同様に、作成時に予想される スループット を指定する必要があります。スループットは同期作成後に変更できないため、ストリームが予想される変更ログデータのボリュームをサポートするように設定されていることを確認してください。デフォルトのボリュームは 5MB/s で、ほとんどの変更データキャプチャワークフローには通常これで十分です。リレーショナルデータベースの変更は「人間スケール」で生成されることが多いため、ボリュームと頻度は「機械スケール」のセンサーや機器データと比べてはるかに小さくなります。
同期設定を保存して、指定された出力場所に新しいストリームを作成します。
現在、CDC ジョブは変更後に手動で再起動する必要があります。すべての CDC 同期は単一のマルチアウトプット抽出ジョブとして実行されるため、フィードを追加または削除するたびに同じソースからの既存の CDC ストリームを一時的に停止する必要があります。ストリームは、ストリーミング同期ジョブが停止している間に変更されたデータに追いつくようにスムーズに再開します。
出力ストリームを開始すると、変更ログデータが流れ始め、出力ストリーミングデータセットのライブビューに表示されるはずです。
ストリームにおける変更データキャプチャ
変更ログメタデータを持つストリームは、データに対して 2 つのビューを表示します。
- 変更ログエントリの完全展開リストを表示する ライブビュー
- データが解決戦略に従って解決され、現在の最新ビューに圧縮された アーカイブビュー
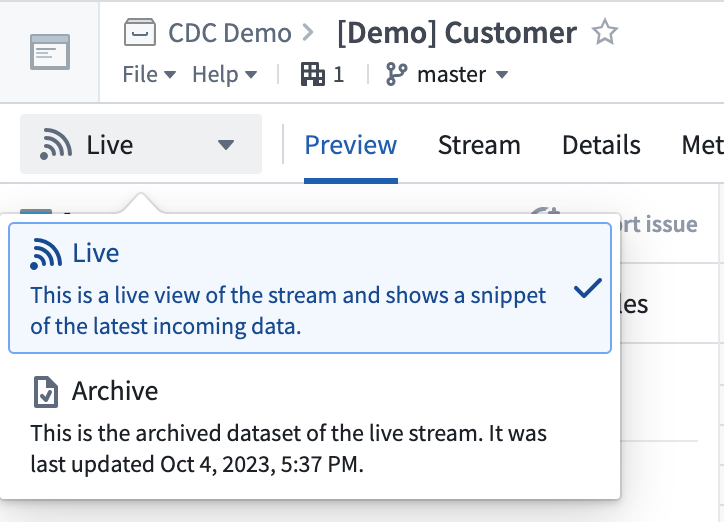
スキーマは、詳細ビューで主キー解決戦略として変更ログメタデータを表示します。
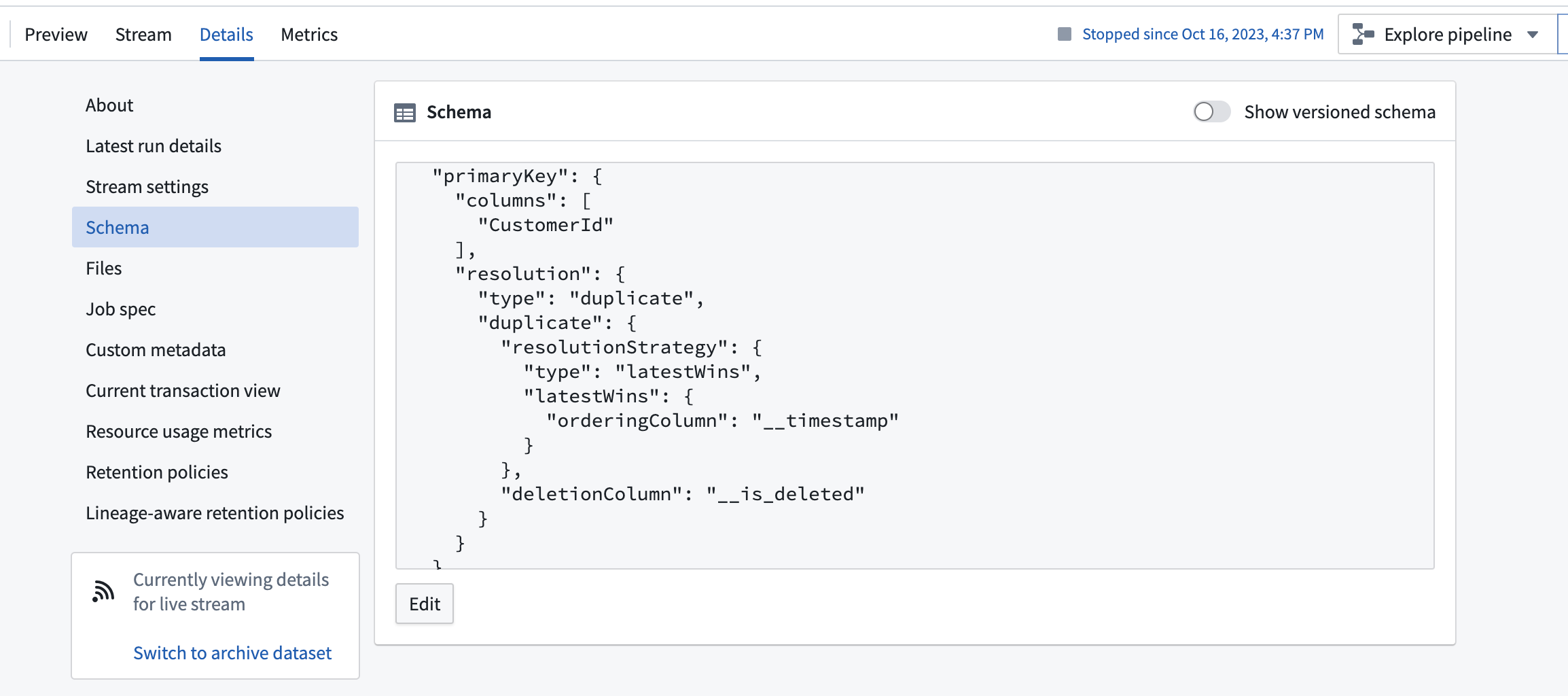
現在、ストリームは順序列を使用して解決を行います。これは、データが順序列に従ってアーカイブで解決されることを意味し、データが順不同で受信された場合でも同様です。この動作は、Foundry オントロジーの変更ログデータの動作とは異なり、オブジェクトタイプを支援するストリームでの到着順にデータをインデックス化します。
Pipeline Builder における変更データキャプチャ
Pipeline Builder は、変更データキャプチャ (CDC) ストリームを処理および構成するための強力な機能を提供します。このセクションでは、完全な CDC ストリームを処理するシナリオと、バックフィルが必要な部分的な CDC ストリームを扱うシナリオについて説明します。
完全な CDC ストリームを処理する
Pipeline Builder でストリーミングトランスフォームを使用する場合、メタデータを保持しながら変更ログデータを処理できます。トランスフォーム中にメタデータ列(主キー、順序、削除)が変更されない限り、変更ログメタデータは自動的に出力に伝播されます。
バックフィルデータセットを使用した部分的な CDC ストリームを構成する
場合によっては、CDC ストリームにすべての履歴データが含まれていないことがあります。その代わり、特定の時点からの変更のみが含まれていることがあります。完全なデータセットを作成するには、バックフィルデータセットを継続的な CDC ストリームと組み合わせる必要があります。以下の手順を使用してこれを実現します。
-
バックフィルデータセットを準備する:
- 同じ Data Connection ソースを使用してデータのスナップショットを取り込みます。
- バックフィルデータセットにタイムスタンプ列が含まれていることを確認します。ソースデータに存在しない場合は、SQL 関数(たとえば
CURRENT_TIMESTAMP())を使用して生成します。
-
Pipeline Builder でデータセットを組み合わせる:
- Union トランスフォームを使用して、バックフィルデータセットと継続的な CDC ストリームを組み合わせます。
-
CDC メタデータを構成する:
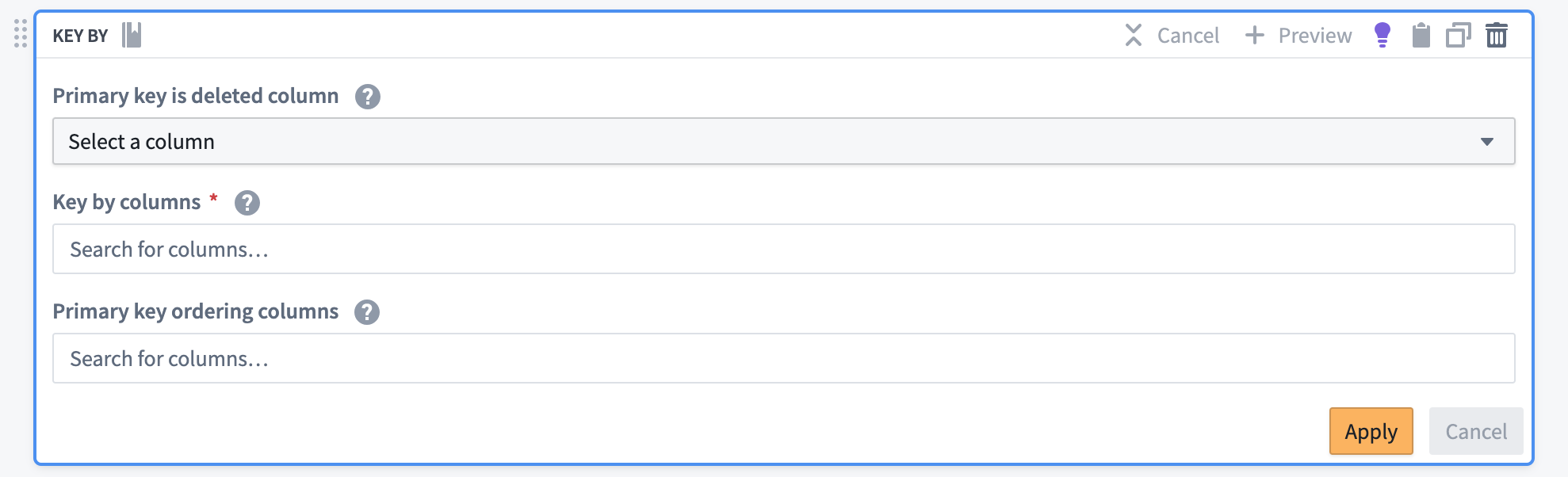
- Key By トランスフォームボードを使用して、合成データをオントロジーに同期するために準備します。
- ソースシステムと一致するように主キー列を設定します。
- 順序列としてタイムスタンプ列を選択します。
- 該当する場合は、削除列を指定します。
-
削除と順序の処理:
- Key By ボードがタイムスタンプ列でデータを順序付けるように構成されていることを確認します。
- ソースデータに明示的な削除情報が含まれていない場合、連続したスナップショットを比較するなどして、削除を推測するロジックを実装する必要があります。
Key By トランスフォームボードは、以下を含む必要な CDC メタデータをストリームに追加します。
- 主キー解決戦略
- 順序列
- 削除列
この設定により、データがオントロジーに同期される際に正しく解決され、タイムスタンプ順に基づいて各レコードの最新状態が維持されるようにします。
CDC メタデータを非 CDC データに適用する
入力ストリームに変更ログメタデータがない場合や、トランスフォーム中にメタデータ列が変更された場合でも、Key By ボードを使用して出力に変更ログメタデータを適用できます。これにより、任意のデータセットを CDC ストリームとして扱うことができ、強力なデータ統合およびリアルタイム更新機能が可能になります。
オントロジーにおける変更データキャプチャ
オントロジーは、ストリーミングデータソースによって支援される Object Storage V2 のオブジェクトタイプにデータをインデックス化するために変更ログメタデータを使用します。ストリームに到着するデータは解決され、オントロジーでクエリを実行した際に利用可能な最新の現在ビューにインデックス化されます(たとえば、Workshop モジュールに表示するため)。
変更ログメタデータを持つデータソースで retention が構成されている場合、保持期間内に更新されないレコードはオントロジーから消えます。
現在、オントロジーは変更ログメタデータで指定された順序列を無視します。代わりに、Object Storage V2 は基となるデータソースに到着した順序に基づいてデータをインデックス化します。具体的には、ある主キーに対して、順序値 2 のログエントリが t1 に data_column=foo で到着し、その後順序値 1 のログエントリが t2 に data_column=bar で到着すると、ソースシステムでは最新の値が data_column=foo であるにもかかわらず、オントロジーには data_column=bar として表示されます。このため、データが順不同で到着した場合、オントロジーはソースシステムのデータを正確に反映できないことがあります。
Palantir で使用されるコネクターはデータを順序通りに配信することが保証されており、Foundry ストリームは順序を維持するため、このオントロジーの動作は、カスタムセットアップや古いストリーミング変更ログを手動でバックフィルして再順序付けせずに同期する場合にのみ影響を与える可能性があります。この状況に遭遇した場合は、オントロジーに同期する前に Pipeline Builder でデータを再順序付けするトランスフォームを適用することをお勧めします。
Workshop における変更データキャプチャ
Workshop は、オントロジーにデータが利用可能になるとすぐに頻繁に更新されるデータを表示するために auto-refresh をサポートします。Auto-refresh は CDC と互換性があり、変更データキャプチャを使用してストリーミングされたデータが Workshop アプリケーションで迅速に利用できるようにするために使用できます。
Auto-refresh は、Workshop モジュールが開いている間に頻繁に更新されることが期待されるデータに対して使用できます。Auto-refresh を使用するために、基となるデータソースに変更ログメタデータが必要ではありません。
変更データキャプチャを使用する際の考慮事項
CDC ワークフローを使用する前に、以下のバックフィル、障害、およびその他の既知の制限事項に関する情報を確認することをお勧めします。
バックフィル
すべての変更ログ同期は将来にわたってのみ処理され、自動バックフィルは実行されません。
多くの場合、変更ログの完全なバックフィルは不可能です。ほとんどのシステムはデフォルトで CDC を有効にしていないためです。変更ログが有効になっている場合でも、ほとんどのシステムには保持期間があり、その後変更ログは永久に削除され、回復不能になります。
完全なバックフィルが必要な場合は、以下の手順をお勧めします。
- CDC ストリームを将来的に設定します。
- バッチ同期を実行して、必要な履歴データを抽出します。
- 履歴バッチデータを各主キーの「作成」レコードのストリームに変換し、そのストリームを CDC ストリームに統合します。
バックフィルはデータが順不同になる可能性があり、オントロジーに同期する前にデータを手動で再順序付けするか、ストリームを再生する必要があるかもしれません。
障害
CDC ワークフローを使用する際に次のような障害に遭遇する可能性があります。
- ソースデータベースと Foundry エージェント間のネットワーク接続
- Foundry エージェントホストと Foundry 間のネットワーク接続
- Foundry の障害
- データベースの障害
- エージェントの障害
データベースのレプリケーションログや変更ログの保持期間が予想される最大障害期間よりも長く設定されていれば、障害はスムーズに処理されます。
たとえば、Foundry への接続が数時間ダウンした場合、Microsoft SQL Server のログ保持期間が 1 日に設定されていれば、データベースは変更ログエントリを記録し続けます。Foundry が再接続されると、Microsoft SQL Server との接続が復旧し、すべての変更ログエントリが処理されるまで新しいデータは流れませんが、Palantir にほぼリアルタイムで変更が反映されるまでに若干の遅延が生じる可能性があります。
非変更ログソースからの変更ログ形式のデータの使用
データは変更ログとして取り込まれなくても、CDC ワークフローで使用できます。Palantir 内の任意のストリーミングデータは、変更ログメタデータを「キー付け」してからオントロジーに同期することで CDC データとして使用できます。
たとえば、ストリームプロキシを使用して手動で変更ログ形式のレコードをストリームにプッシュするプッシュベースの取り込みが可能です。
同様に、変更ログデータが Kafka トピックに存在する場合、標準(非 CDC)の同期を使用して取り込むことができます。その後、Pipeline Builder を使用して「キー付け」し、オントロジーおよびその他の場所で使用できます。
変更ログメタデータを削除する
場合によっては、変更ログメタデータを削除することが有用です。たとえば、変更ログによってキャプチャされたプロセスフローを分析したい場合、以下の方法のいずれかを使用して変更ログメタデータを削除できます。
- メタデータ列に対して任意のトランスフォームを実行する
- ストリーミングデータセットのスキーマから解決戦略を手動で削除する
CDC テーブルへのアクセスを有効にする
ソースシステムに接続する際には、Connection Details にユーザー資格情報を提供する必要があります。これらの資格情報はソースで設定された権限に関連付けられています。基本的なデータ取り込みには、計画しているデータセットに対する SELECT 権限がユーザーに必要です。ただし、CDC 接続では、取り込み対象のテーブルおよびそのスキーマに対して SELECT および EXECUTE 権限の両方がユーザーに必要な場合があります。