注: 以下の翻訳の正確性は検証されていません。AIPを利用して英語版の原文から機械的に翻訳されたものです。
Foundry Streaming によるコンピュート使用量
Foundry Streaming は、新しいメッセージの受信を常に待ち受け、ユーザー定義のロジックを適用し、それらをパイプラインの次のステージにプッシュする、高スループット、低レイテンシのコンピュート形式です。
Foundry のストリームは、分散並列ワーカーベースのアーキテクチャに依存しており、並列ワーカーはそれぞれが特定のストリーミングジョブに専用のリソースを持っています。ストリームのリソース要件は、アクティブなストリームの最大スループットとそれが処理するメッセージの総数に応じてスケールします。
コンピュートの測定方法
ストリーミングコンピュートの使用量は、次の2つのタイプに分けられます:
-
ライブ処理コンピュート: ライブデータに対してユーザー定義のトランスフォームを実行するプロセス。このソースタイプは「ストリーミング」と呼ばれます。
-
アーカイブコンピュート: データをストリーミングレイヤーから Foundry のストレージレイヤーに移動するプロセス。アーカイブコンピュートはバッチプロセスであり、「トランスフォーム」として表示されます。
Foundry の使用料を支払う際には、デフォルトの streaming_usage_rate は 0.5 です。これは、ユーザー定義のトランスフォームがライブデータで実行されるレートです。Palantir とエンタープライズ契約を結んでいる場合は、コンピュート使用量の計算を進める前に、Palantir の担当者に連絡してください。
Foundry のストリームのライブ処理コンピュートは、その全期間で使用するコンピュート秒数によって実時間で測定されます。したがって、ストリーミングジョブでより多くの計算リソース(例:vCPUs、メモリー、並列化)を使用すると、ジョブのコストが上昇します。ジョブが長く実行されるほど、それが使用するコンピュートは多くなります。ストリームは、データを継続的に処理するために継続的に実行するように設計されているため、ユーザーによって終了されるまでコンピュートを使用し続けます。
ストリームは静的に割り当てられています。ストリームが実行中である間、コンピュート秒数は実時間の秒数ごとに一定の数値を使用します。ストリームは、ピークの需要を満たすように調整されることも多いため、ストリームからのコンピュート使用量は、データボリュームの変動に影響されません。データがストリームを通過していない場合でも、ストリームはコンピュート秒数を使用します。
ストリームの使用量は、単一のジョブマネージャーと多数のタスクマネージャーが使用した総秒数の合計として計算することができます。各並列ワーカーは、同一の計算リソースを持つことに注意してください。
ジョブマネージャーのコンピュート秒数は、次のように計算されます:
max(num_vCPU, gib_ram / 7.5) * streaming_usage_rate * stream_duration_seconds
タスクマネージャーのコンピュート秒数は、次のように計算されます:
max(num_vCPU, gib_ram / 7.5) * streaming_usage_rate * stream_duration_seconds * (num_parallel_task_managers + 1)compute_seconds = job_manager compute_seconds + task_manager_compute_seconds
コンピュート使用量を計算するために使用される値について詳しくは、memory-to-core ratio を参照してください。
アーカイブジョブは、各ストリームと並行して実行されるバッチ処理ジョブです。アーカイブジョブは、ストリームのホットストレージレイヤーから定期的に読み取り、データを Foundry のストレージに移動して、堅牢な持続性と履歴の追跡を提供します。アーカイブジョブはストリームそのものと同じ低レイテンシの要件を持っていないため、スケジュールに従って実行され、アーカイブするデータが存在するときだけコンピュートを使用します。
アーカイブジョブの使用量は、単一の Spark ドライバに基づいており、次の式で計算することができます:
compute_seconds = max(num_vcpu, gib_ram / 7.5) * num_seconds- アーカイブジョブは小さい。アーカイバは常に1 vCPU と 4 GiB の RAM で最小限のプロファイルで実行されます。
Foundry Streaming の使用量を調査する
ストリームの総使用量を表示するには、まず Resource Management application に移動します。次に、Usage by resource セクションでストリームを見つけ、Details を選択して、個々のデータセットごとの使用量を表示します。
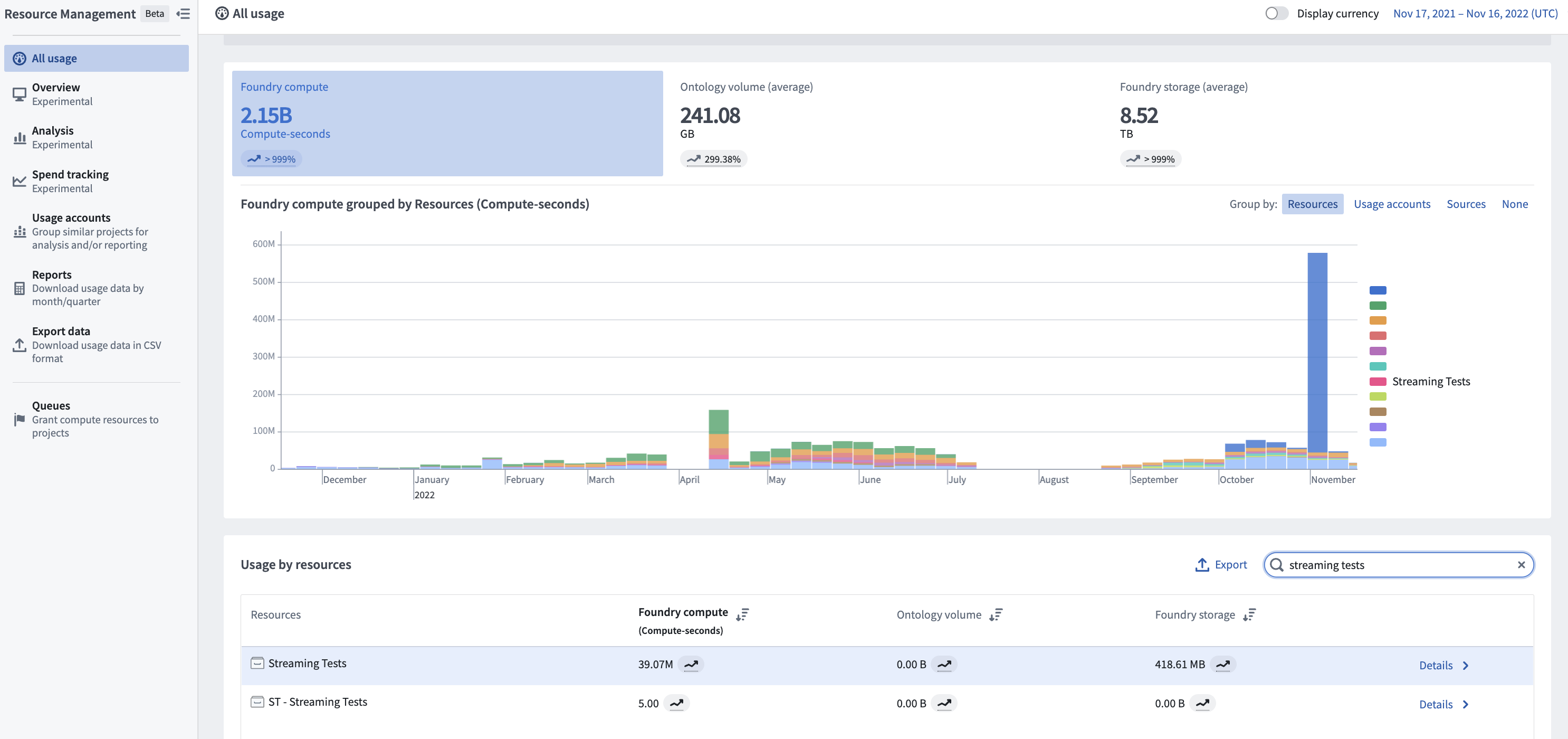
ストリームのコストは、ストリームが生成するチェックポイントデータセットに帰属します。このデータセットは、そのストリームの処理の永続的な使用記録として機能します。このデータセットのストリーミング使用量は、Resource Management アプリケーションの「ストリーミング」カテゴリーに含まれます。
ストリームが実行されるたびに、それはユーザーによって停止されるまで継続的に実行されます。ユーザーがストリームを停止すると、その実行はデータセットの History タブの下に表示されます。各個のストリームのプロファイルを調査して、過去のストリーム実行のパフォーマンスとコンピュート使用量を理解することができます。
歴史的なアーカイブが実行されるたびに、それはそのコンピュート指標を Builds application で公開します。Builds アプリケーションを使用して、実行された各アーカイブのリソース割り当てを調査します。
使用量の主要な要因を理解する
ストリームの使用量の主要な要因は、ストリーム自体の計算リソースフットプリントです。この場合、コンピュートリソースには、タスクマネージャーごとの vCPUs の数、パーティションごとの GiB の RAM、およびストリーム内のパーティションの数が含まれます。これらのリソースはストリームのプロファイルで設定され、ストリームの期間全体で持続します。
- ストリームのリソースは、入力ストリームのピークスループットを満たすように割り当てるべきです。入力メッセージのボリュームが、計算リソースが効果的にサービスを提供するために必要なものを超えている場合、ストリームは遅れます。
- ストリームが使用するリソースを変更するには、リソースプロファイルを変更してストリームを再起動する必要があります。
- アーカイブジョブのコンピュート使用量は、ストリームを通じて流れるデータの量に応じてスケールします。アーカイブジョブは、最後のアーカイブ以降のすべてのデータを読み取ります。ストリームされたデータがない場合、アーカイブジョブはゼロのコンピュートを使用します。アーカイブジョブは、ストリームがアクティブな間、10分ごとに実行されます。
Foundry Streaming で使用量を管理する
特定のワークフローに対してストリーミングを選択するときとバッチを選択するときを理解することは重要です。ストリーミングは、秒単位のレイテンシと一定のコンピュートを必要とするワークフローのために設計されています。データが数分ごとに実行できる場合、ストリームと同じ量のデータをプッシュできる小さなマイクロバッチジョブを考慮してみてください。これは、コンピュート秒数のコストを削減し、データレイテンシを大幅に高めます。
- ストリームのサイズは、1回の実行あたりに使用される総コンピュート秒数に大きな影響を与えます。ストリームは、そのストリームに対して予想される最大同時負荷を処理できるように、十分なリソースで設定するべきです。
- ピークロードがサービスされ、過剰にプロビジョニングされていないことを確認しながら、ストリームのサイズを選択することが重要です。これには、各ジョブ(vCPUs とメモリー)のサイズと、ストリームのタスクマネージャーの総数を慎重に設定することが含まれます。
- ストリームは、停止されるまで実行されます。ストリーミングコンピュートのソースを慎重に監視して、ストリームが必要なときだけ実行されていることを確認します。
使用量の計算
次の例は、10分間実行される仮想のストリームのコンピュート使用量がどのように計算されるかを示しています。ほとんどのプロダクションストリームは継続的に実行されることに注意してください。
ストリームプロファイル
- ジョブマネージャー vCPUs: 0.5
- ジョブマネージャー gib_ram: 1
- タスクマネージャー vCPUs: 0.5
- タスクマネージャー gib_ram: 2g
- パラレリズム: 2
- gib_ram: 4
- ストリームの持続時間: 10分(600秒)
- streaming_usage_rate: 0.5
計算
- ジョブマネージャーのコンピュート秒数 = max(vCPUs, gib_ram / 7.5 gib_ram) * streaming_usage_rate * 600s = max(0.5, 0.133) * 0.5 * 600s = 150 コンピュート秒
- または、1秒あたり0.25コンピュート秒、1時間あたり900コンピュート秒
- タスクマネージャーのコンピュート秒数 = max(vCPUs, gib_ram / 7.5 gib_ram) * (parallelism + 1) * streaming_usage_rate * 600s = max(0.5, 0.267) * 3 * 0.5 * 600s = 450 コンピュート秒
- または、1秒あたり0.75コンピュート秒、1時間あたり2700コンピュート秒
このストリームが10分間実行されるための総コンピュート使用量は、150のジョブマネージャーコンピュート秒数と450のタスクマネージャーコンピュート秒数です。Foundry でのコンピュート使用量に影響を与える要因について詳しく学びましょう。