注: 以下の翻訳の正確性は検証されていません。AIPを利用して英語版の原文から機械的に翻訳されたものです。
マーキングの削除に関するガイダンス
プラットフォーム上のリソースへのアクセス要件は、マーキング によって制御されています。マーキングは、リソースにアクセスするために、ユーザーが適用されたすべてのマーキングのメンバーである必要があるという 全てまたは無し の方法でアクセスを制限します。さらに、マーキングはファイル階層と直接依存関係の両方で 継承 されます。適切な権限がある場合、リソースから直接マーキングを削除し、直接依存関係に沿ってマーキングを削除することができます。
マーキングは、プラットフォーム全体で読みやすく、直接依存関係に沿って伝播するため、頻繁に使用されます。これにより、機密データが保護されます。いくつかの状況では、パイプラインの早い段階でマーキングが適用され、後の段階で削除する必要がある場合があります。このページでは、パイプラインの構造に応じてマーキングを削除する方法について詳しく説明します。
- パイプラインにマーキングを適用し始める場合は、以下の シナリオ セクションを読むことをお勧めします。これにより、誤ってエンドユーザーをロックアウトしないようにすることができます。
- また、マーキングの適用と削除に際して ベストプラクティス に従い、継承されたマーキングと組織を削除する方法 に関するドキュメントを参照して、詳細な情報を入手することをお勧めします。
シナリオ
以下に、パイプラインの早い段階でマーキングを適用し、後の段階でそれを削除することに関連する3つのシナリオを示します。
シナリオ1:マーキング削除による切断の置き換え
このシナリオは、パイプラインが以下の条件を満たしている場合に適用されます。
- すでにマーキングが適用されている
- マーキングが切断によって削除される
- プロジェクトレベルの伝播ビュー要件の権限がオンになっていない
したがって、継承されたマーキングを削除することで、切断(非推奨の機能)から移行しています。
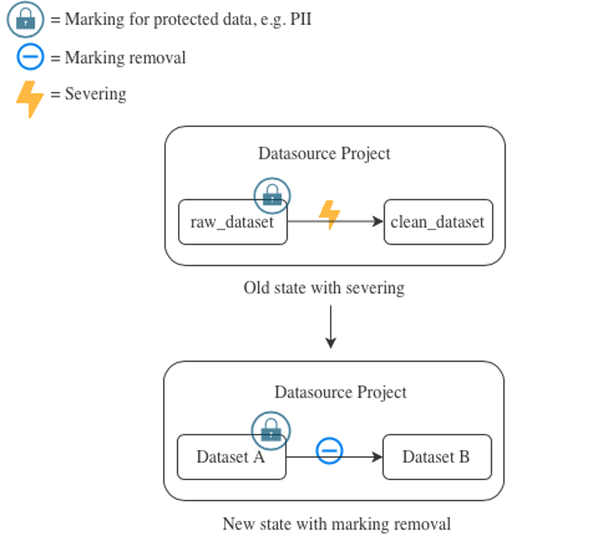
上記の例で示すように、古い状態では、切断がマーキングの伝播を防ぐために使用されています。切断がマーキングを削除するためだけに使用されている場合、マーキング削除 に切断を置き換えることを強くお勧めします。上記の例の新しい状態のように、マーキングを削除する際には、マーキング削除トランスフォームを含むリポジトリの 承認モード 設定について考えることが役立ちます。
伝播ビュー要件が有効になっている場合は、以下のシナリオ2を読んでください。
シナリオ2:マーキングを適用した後、「伝播ビュー要件」を無効にするためにマーキングを削除する
このシナリオでは、パイプライン内のデータセットにマーキングを適用し、プロジェクトレベルの伝播ビュー要件の設定を無効にすることが含まれています。

上記のように、新しいプロジェクトでは、伝播ビュー要件 オプションがデフォルトで無効になっています。これらの新しいプロジェクトでは、ビュー要件は下流の派生データセットに対して強制されません。具体的には、この設定が無効になっているプロジェクトで上流データにアクセスする必要がある別のプロジェクトの下流バージョンのデータにアクセスするユーザーには影響しません。
マーキングは常に伝播します。新しいプロジェクトのデータにマーキングがある場合、そのマーキングは下流のすべてのデータセットに伝播します。「伝播ビュー要件」の設定に関係なく。

上記の画像のように、伝播ビュー要件 オプションが有効になっているプロジェクトがある場合、これらのプロジェクトのデータセットに対してビュー要件が伝播しています。つまり、別のプロジェクトの下流バージョンのデータにアクセスするユーザーは、この設定が有効になっている上流プロジェクトにもアクセスする必要があります。
マーキング を使用することをお勧めしますので、ビュー要件の伝播 を 無効 にすることを強くお勧めします。
ビュー要件の伝播を無効にし、パイプラインにマーキングを導入する前に、ビュー要件の伝播を有効にすることの元々の目的について考慮することが価値があります。
- "ビュー要件を伝播する"を有効にする明確な理由がないかもしれません。その場合、この設定を単純に無効にし、ユーザーが明示的にアクセスが必要なデータセットのみにアクセスを許可するようにすることができます。ユーザーは、以前ビュー要件を伝播していた上流のデータセットに対するアクセスを必要とすることはもうありません。
- プロジェクトにはいくつかのセンシティブなデータセットがあります。この場合、センシティブなデータセットと非センシティブなデータセットを分離し、以下に概説されている手順に従うのがベストです。これらの手順では、ビュー要件の伝播をマーキングに置き換える方法を示しています。マーキングは、これらのシナリオに適したセキュリティプリミティブです。
- 下記の手順がユーザーのニーズを満たさない場合は、Palantirの担当者に連絡してください。
下の例では、Datasource プロジェクトで "ビュー要件を伝播する" を無効にすることが目標です。上記の手順を経て、プロジェクトで "ビュー要件を伝播する" が有効になっている理由は、raw_dataset_1 データセットがセンシティブなデータを持っているためであることが分かりました。
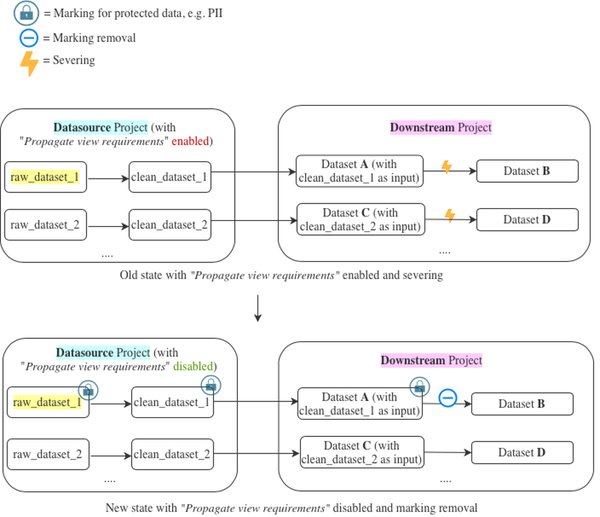
古い状態では、データセット A の内容を表示するには、少なくとも Datasource プロジェクトと Downstream プロジェクトの両方に "viewer" アクセスが必要でした。その後、データセット B のビュー要件伝播を削除するために切断が使用されました。
新しい状態では、データセット A の内容を表示するには、少なくとも Downstream プロジェクトに "viewer" アクセスが必要であり、マーキングにアクセスする必要があります。"ビュー要件を伝播する" が無効になっていることに注意してください。データセット C と D へのアクセスを必要とするだけで、Downstream プロジェクトに "viewer" アクセスが必要です。
この変更により、セキュリティマーキングを使用して "ビュー要件を伝播する" を無効にすることが可能になります。以下の提案された解決策では、raw_dataset_1 にマーキングを適用し、そのマーキングを 直ちに raw_dataset_1 の非切断トランザクションを入力として持つすべての下流のデータセットに伝播します。ここでは、切断がすでに行われていたという前提があり、切断はマーキングの削除によって置き換えられるだけです。あなたの状況でこれが真でない場合は、シナリオ 3を参照してください。ここでは、データセットにマーキングを適用する際の影響について詳しく説明しています。
この変更を導入するための以下の手順が推奨されています。これにより、Datasource プロジェクトで "ビュー要件を伝播する" を無効にした後、マーキングが追加されたときにユーザーがデータセット B へのアクセスを失うことを防ぎます。
- 新しいマーキングを作成し、関連するユーザーにマーキングへのアクセスを許可します。
raw_dataset_1にマーキングを適用します。- マーキングが適用されたので、Datasource プロジェクトで "ビュー要件を伝播する" を安全に無効にすることができます。
- トランスフォームで切断をマーキングの削除に置き換え、切断とマーキングの削除が同時に行われることを確認します。
- パイプライン内のすべてのデータセットがビルドされていることを確認します。
- それ以上アクセスを必要としないユーザーを Datasource プロジェクトから削除します。
シナリオ 3: 新しいマーキングの適用後、データセットレベルでのマーキングの削除
この潜在的に複雑なシナリオでは、既存のパイプラインの早い段階で新しいマーキングを導入し、パイプラインの後のユーザーを誤ってロックアウトすることなく、新しいマーキングを導入します。
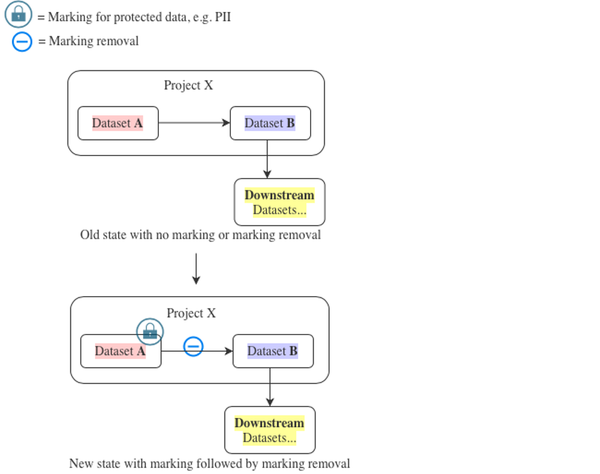
データセット A で導入されたマーキングは、すぐにそのデータセットの下流にあるすべてのリソースに伝播します。ユーザーは、マークされたデータセットから派生したものにアクセスするために、マーキングが必要になります。
これをより良く理解するために、上記の例を次のようなパイプラインで拡張しましょう:データセット A → データセット B → Downstream データセット:
- データセット A は、マーキング対象となる原始データセットです。
- データセット B は、データセット A から派生し、センシティブなデータが削除されています(したがって、マーキングを削除することができます)。
- Downstream データセットは、ユーザーがアクセスを必要とするデータセット B から派生したデータセットです。
この例での目標は、Downstream データセットがデータセット A のマーキングを継承しないようにすることです。
まず理解する必要があるのは、データセット A をマーキングする(またはデータセット A を囲むフォルダーをマーキングする)ことは、データセット A のすべての歴史の中でのすべてのトランザクションを効果的にマーキングすることです。その結果、データセット B と Downstream データセットはすぐにマーキングを継承します。
以下の手順を実行すると:
- データセット A → データセット B の変換にマーキングの削除を追加し、
- データセット B のコードを更新し、そして
- データセット B を再スナップショットする ...
... すると、データセット B の最新のスナップショットトランザクションはマーキングがなくなりますが、データセット B の古いトランザクションはすべてマーキングが残ります。
データセットをマーキングすると、そのすべてのトランザクションがマーキングされますが、トランスフォームでマーキングを削除すると、その出力トランザクションのマーキングだけが削除されます。この挙動は、対称的ではありません。
これは、データセット B の古いトランザクションから派生したデータを含む Downstream データセット、たとえば増分的にビルドされる Downstream データセットは、まだマーキングを継承するということを意味します。
各増分 Downstream データセットがマーキングされないようにするためには、データセット B 上のマーキングを削除するトランスフォームと増分 Downstream データセットの間のすべてが、データセット B にマーキングを削除するトランスフォームが適用された後に再スナップショットされる必要があります。これにより、各 Downstream データセットは、以前の(マークされた)トランザクションではなく、データセット B の最新の(マーキングされていない)トランザクションにのみ依存することを保証します。単純な再ビルドは 十分ではありません。
Downstream データセットの数が手動で再スナップショットをトリガするのに不可能な場合、以下の手順を提案します:
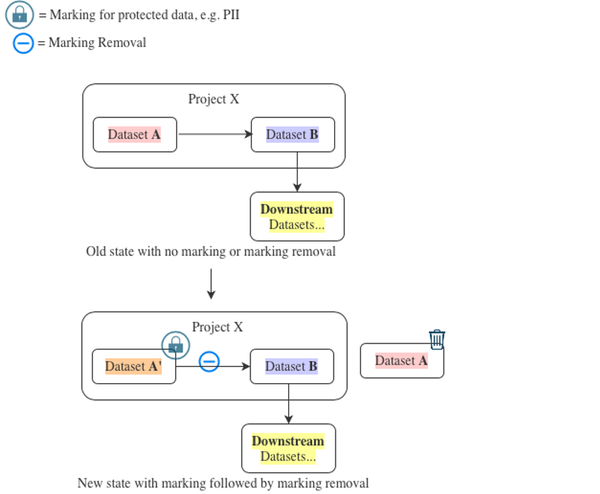
- データセット A′ を作成し、その内容がデータセット A と同一であることを確認します。
- データセット B のコードを書き換えて、データセット A の代わりにデータセット A′ を入力として使用します。同時に、適切なマーキングの削除をトランスフォームに追加し、その直後にデータセット B をビルドします。データセット B のスナップショットビルドは必要ありません。
この交換を行う際のパフォーマンスの影響を考慮してください。なぜなら、これによりデータセット B の SNAPSHOT ビルドがトリガされる可能性があるからです。
- データセット A′ にマーキングを追加します。
- データセット A をゴミ箱に移動します。
- この時点で、これ以上の再ビルドは必要ありません。
重要なパイプラインでこれらの変更を行っている場合や、これらの手順について不確かな点がある場合は、Palantirの担当者に連絡して支援を求めてください。
ベストプラクティス
- リポジトリを "再承認不要" モードに設定することは 避けてください 。
- このモードを有効にする必要がある場合は、そのリポジトリのエディタの集合を 最小限にして 、この設定に対する承認を得ることを 確認してください 。
- リソースがマーキングを必要とするかどうかを決定する明確で、よく定義された基準を 持っていてください 。
- マーキングが必要なデータを積極的に選択するマーキング除去トランスフォームを 作成してください
- マーキングが必要なデータをフィルター処理するマーキング除去トランスフォームを 作成しないでください 。これは、新しいデータが上流で一般的に導入され、それがあなたのマーキング除去トランスフォームを通じて誤って流れることを防ぐ必要があるからです。
- "フィルター処理する" アプローチの例(推奨):
Copied!
1 2 3 4 5 6# column-based df.select("salary","title","department") # row-based states_to_keep =["OH","CA","DE"] df.filter(df.state.isin(states_to_keep)) - "フィルター処理しない" アプローチの例( 推奨されません ):
Copied!
1 2 3 4 5 6# column-based df.drop("firstname","lastname") # row-based states_to_drop =["FL","TX","IL"] df.filter(~df.state.isin(states_to_drop))
- "フィルター処理する" アプローチの例(推奨):
- センシティブなデータの削除ロジックが実装されているトランスフォームでマーキングの削除を 行ってください 。
- このロジックを別のリポジトリで抽象化したり隠したりすることは ありません 。
- 同様に、別のマーキング除去リポジトリ(一連のアイデンティティトランスフォームとともに)を作成することは ありません 。マーキング除去ロジックは、マーキング除去PRレビュー中に明示的に承認されるべきです。
- データからマーキングを削除する場合は、マーキングを除去する プロジェクト内で 、マークされたデータセットがインポートとして追加されるできるだけ上流で、またはプロジェクトエクスポートを作成する直前の最後のステップで、できるだけ下流で行うことを してください 。
FAQ
コードのロジックが変更される度に、マーキングの削除について承認が必要ですか?
これは、マーキング除去トランスフォームを持つリポジトリに 再承認を必要とする か 再承認を必要としない 承認モードが設定されているかによります。承認モードについてもっと学ぶ。
マーキング除去ワークフローと "1 プロジェクトあたり 1 リポジトリ" の推奨はあまり相性が良くありません。マーキング除去ワークフローのために、プロジェクトあたり何個のリポジトリを設定すべきですか?
理想的には、マーキング除去トランスフォームの ロジック が変更されるたびに、それはセキュリティの承認を受けるべきです。承認プロセスの過度な摩擦と良好なセキュリティ姿勢の間でバランスを取るために、可能であれば、すべてのマーキング除去ロジック(データの難読化、行の削除など)を含むトランスフォームを別のリポジトリに移動し、その別のリポジトリを "再承認を必要とする" に設定することをお勧めします。
私はトランスフォームの出力にマーキング除去プロパティ(stop_propagating および stop_requiring)を追加できますか?
いいえ、これらは 入力 プロパティであり、出力に追加することはできません。特定の出力からマーキングを削除することが目的である場合、マーキングを持つすべての入力を特定し、それぞれに stop_propagating 文を追加する必要があります。詳細については、入力トランスフォームプロパティ のドキュメンテーションを参照してください。
どの言語がマーキングの削除をサポートしていますか?
以下の言語がマーキングの削除をサポートしています:
なぜマーキングの削除が切断よりも優先されるのですか?
機密情報の除去は慎重に行われ、プロジェクトやリポジトリに散乱させるべきではありません。プラットフォームのマーキング除去機能は、パーミッションの伝播変更に対する粒度の細かな制御を提供し、そのような変更が適切にレビューされることを保証します。
私たちはリポジトリを切断の代わりにマーキング除去を使用するように移行しています。新しいトランスフォームに対して切断を無効にする方法は何ですか?
これまで切断が有効になっていなかったデータセットに対して切断を追加することを禁止するように、Palantirの担当者に連絡してください。