注: 以下の翻訳の正確性は検証されていません。AIPを利用して英語版の原文から機械的に翻訳されたものです。
Pipeline Builder でバッチパイプラインを作成する
このチュートリアルでは、Pipeline Builder を使用して、フライトアラート情報の単一のデータセットを出力するシンプルなパイプラインを作成します。その後、この出力データセットを Contour や Code Workbook などのツールで分析して、最も混乱のリスクが高いフライト経路を特定することができます。
以下で使用されるデータセットは、データセットのインポート手順で名前で検索でき、ユーザーの Foundry ファイルシステム内の Foundry Reference Project にあります。
Foundry Training and Resources/Foundry Reference Project/Tutorial Reference Examples/Track: Data Engineering/Datasource Project: Flight Alerts/datasets。
このチュートリアルを終えると、以下のようなパイプラインができます。
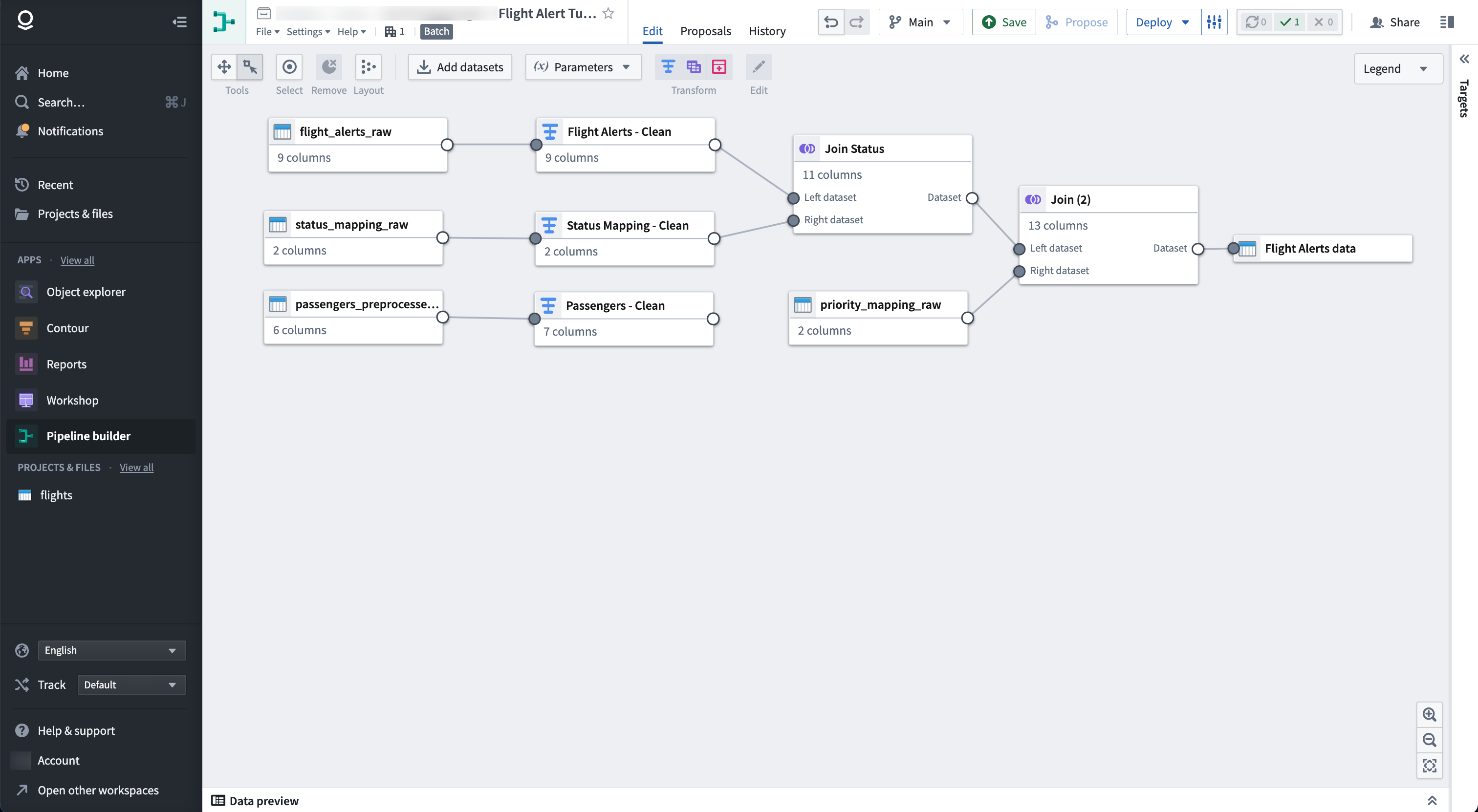
パイプラインは、Flight Alerts Dataという新しいデータセット出力を生成し、さらなる探索に使用できます。
パート 1: 初期設定
まず、新しいパイプラインを作成する必要があります。
-
Foundry にログインしたら、左側のナビゲーションバーの Apps の下にある Pipeline Builder にアクセスします。もし見つからなければ、View all をクリックして Build & Monitor Pipelines セクションの Pipeline Builder を探します。
-
次に、Pipeline Builder のランディングページの右上で、New pipeline をクリックして新しいパイプラインを作成します。Batch pipeline を選択します。
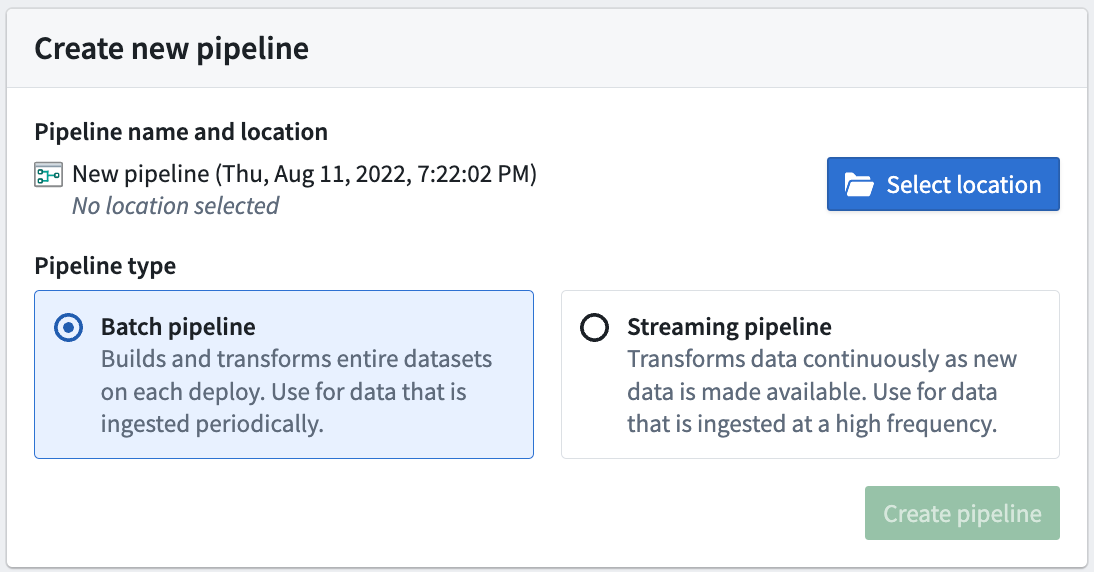
ストリーミングパイプラインの作成機能は、すべての Foundry 環境で利用できるわけではありません。ユースケースにそれが必要な場合は、Palantir の担当者にお問い合わせください。
- パイプラインを保存する場所を選択します。パイプラインは個人用フォルダーには保存できません。
- Create pipeline をクリックします。
パート 2: データセットの追加
これで、パイプラインワークフローにデータセットを追加することができます。このチュートリアルでは、概念的またはオープンソースのデータのサンプルデータセットを使用し、すべてのデータセットはユーザーの Foundry ファイルシステム内の Foundry Reference Project の一部として利用できるはずです。
Pipeline Builder ページから、Foundry から Add datasets をクリックします。
または、コンピュータからファイルをドラッグアンドドロップしてデータセットとして使用することもできます。
このウォークスルーの例では、passengers_preprocessed、flight_alerts_raw、および status_mapping_raw データセットを追加します。データセットの選択範囲を追加するには、データセットを選択してインラインの + アイコンをクリックするか、Add to Selection をクリックします。
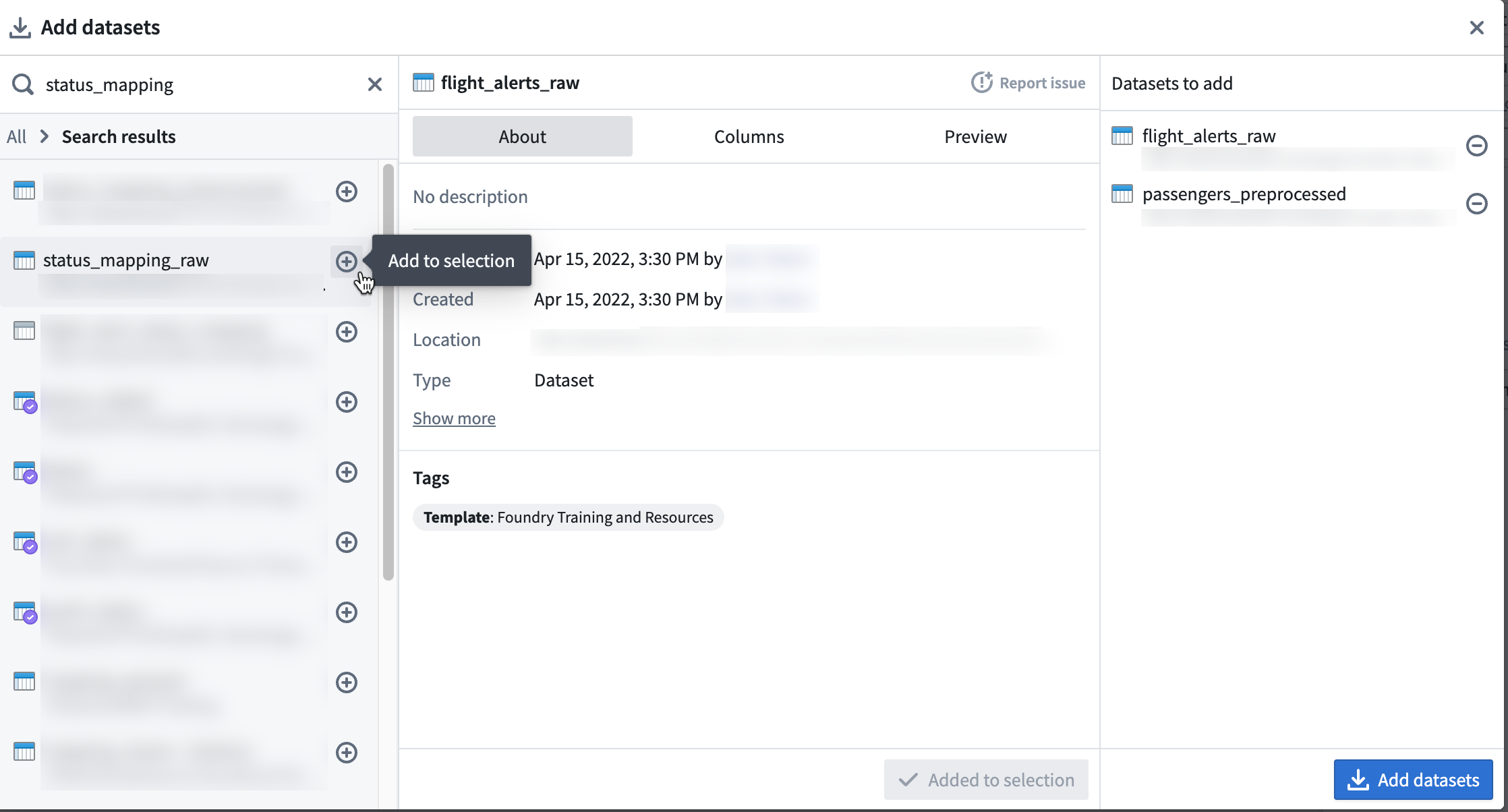
必要なすべてのデータセットが選択されたら、Add datasets をクリックします。
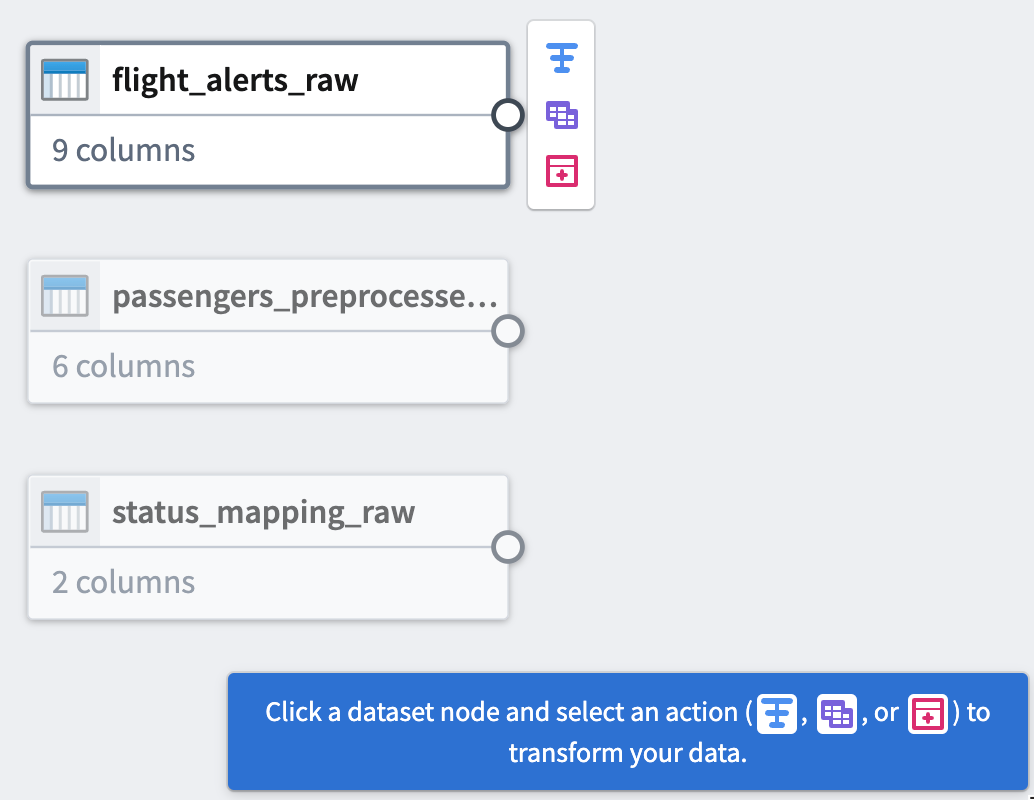
パート 3: データのクリーニング
生データセットを追加した後、パイプラインの定義を続けるために基本的なクリーニング変換をいくつか実行できます。生データセットのうち 3 つを変換します。
データセット 1
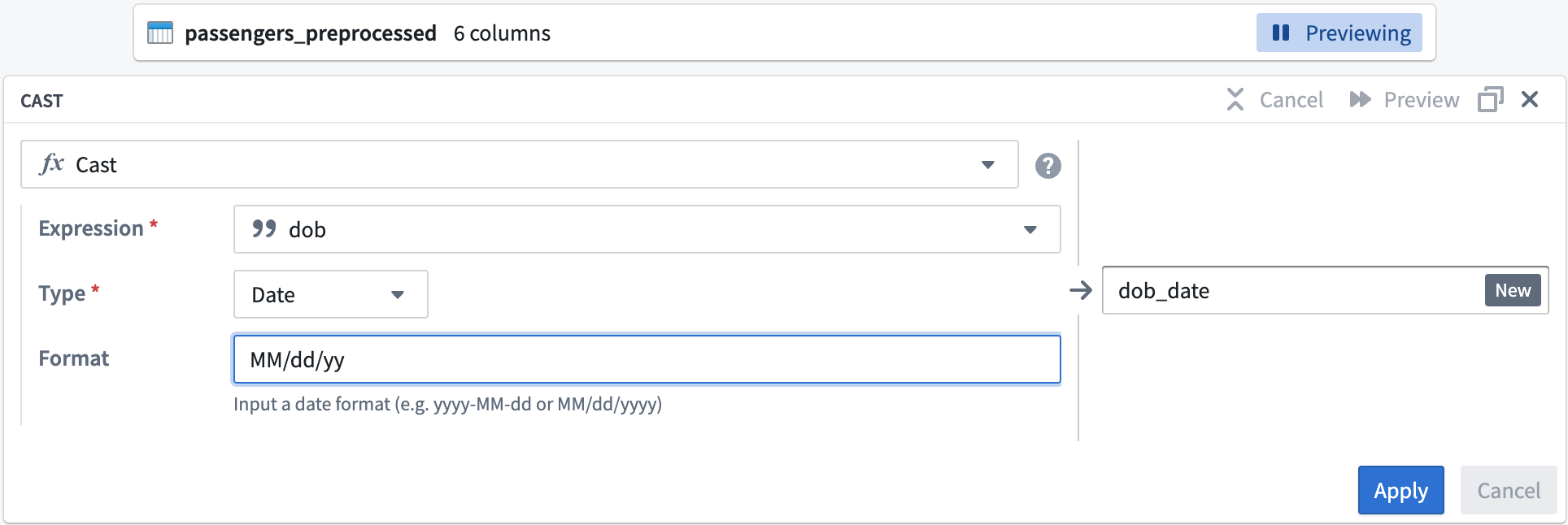
まず、passengers_preprocessed データセットをクリーニングしましょう。dob 列名を dob_date に変更し、値を MM/dd/yy 形式に変換するキャスト変換の設定を開始します。
キャスト変換
-
グラフ内の
passengers_preprocessedノードをクリックします。 -
Transform をクリックします。

-
ドロップダウンから cast 変換を検索して選択し、キャスト設定ボードを開きます。
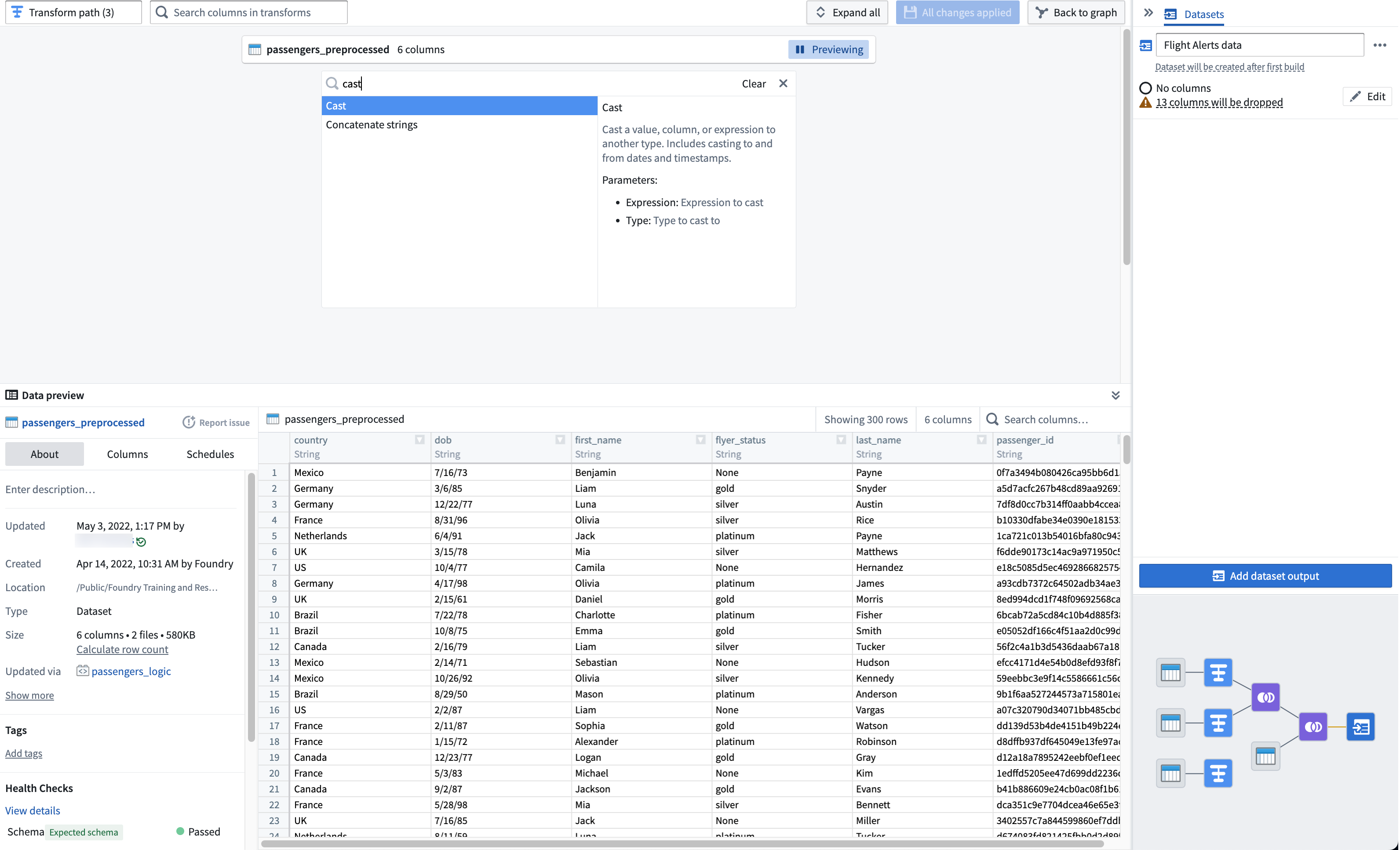
-
Expression フィールドから
dobを選択し、Type ではDateを選択します。 -
Format タイプに
MM/dd/yyを入力します。キャスト変換が成功することを確認するために、大文字のMMを使用してください。出力列名をdob_dateに変更します。キャストボードは以下のようになります:
-
変換をパイプラインに追加するには、Apply をクリックします。
タイトルケース変換
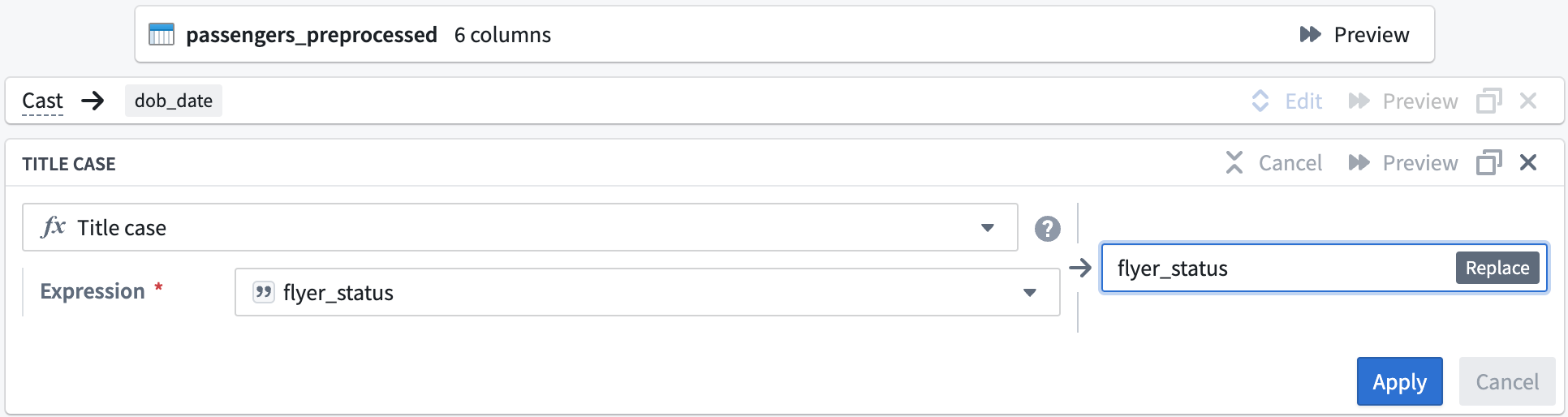
次に、flyer_status 列の値を大文字で始めるようにフォーマットします。
-
変換検索フィールドで、Title case 変換を検索して選択し、タイトルケース設定ボードを開きます。
-
Expression フィールドで、ドロップダウンから
flyer_status列を選択します。タイトルケースボードは以下のようになります:
-
変換をパイプラインに追加するには、Apply をクリックします。
-
変換設定ウィンドウの左上隅で、変換の名前を
Passengers_Cleanに変更します。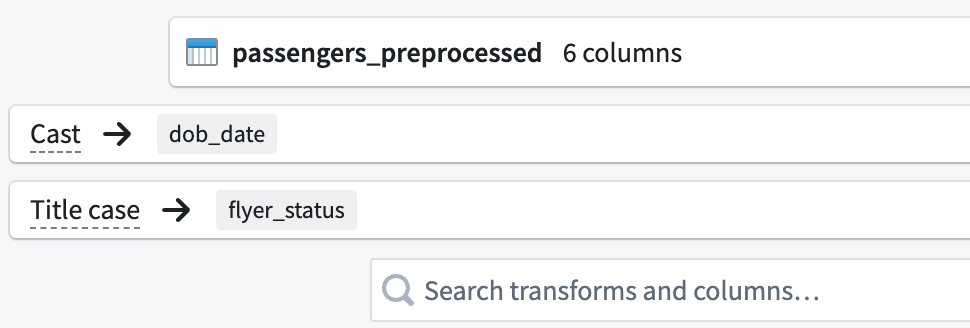
-
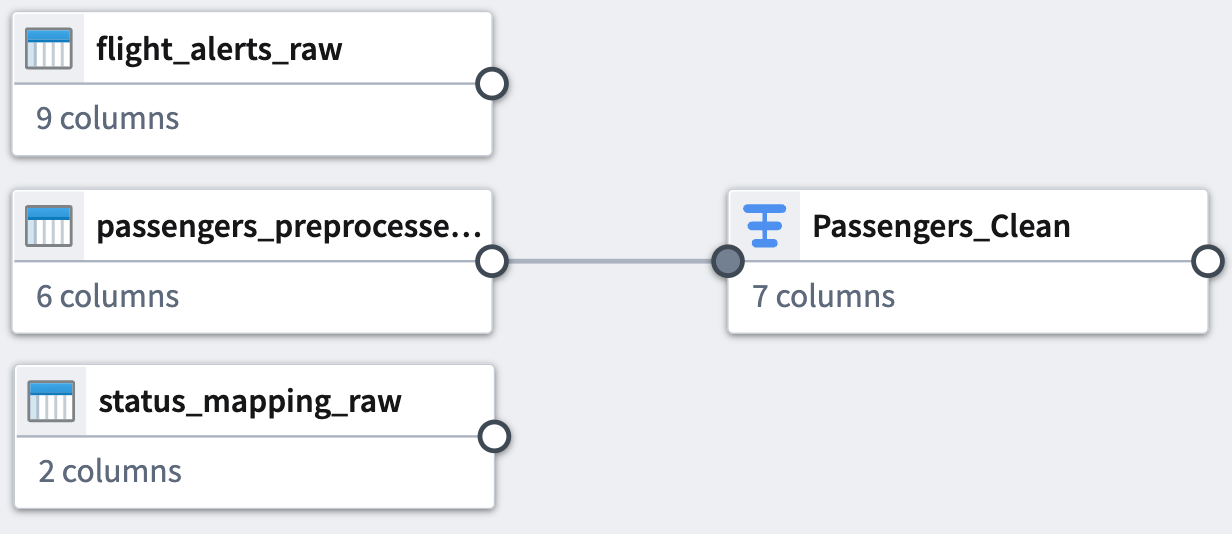
パイプライングラフに戻るには、右上の Back to graph をクリックします。
データセット 2
次に、flight_alerts_raw データセットをクリーニングしましょう。まず、flight_date 列の値を MM/dd/yy 形式に変換するための別のキャスト変換を設定します。
キャスト変換
-
グラフ内の
flight_alerts_rawデータセットノードをクリックします。 -
Transform をクリックします。
-
ドロップダウンから cast 変換を検索して選択し、キャスト設定ボードを開きます。選択ボックスの右側にリストされている関数定義を読むことで、関数について詳しく知ることができます。
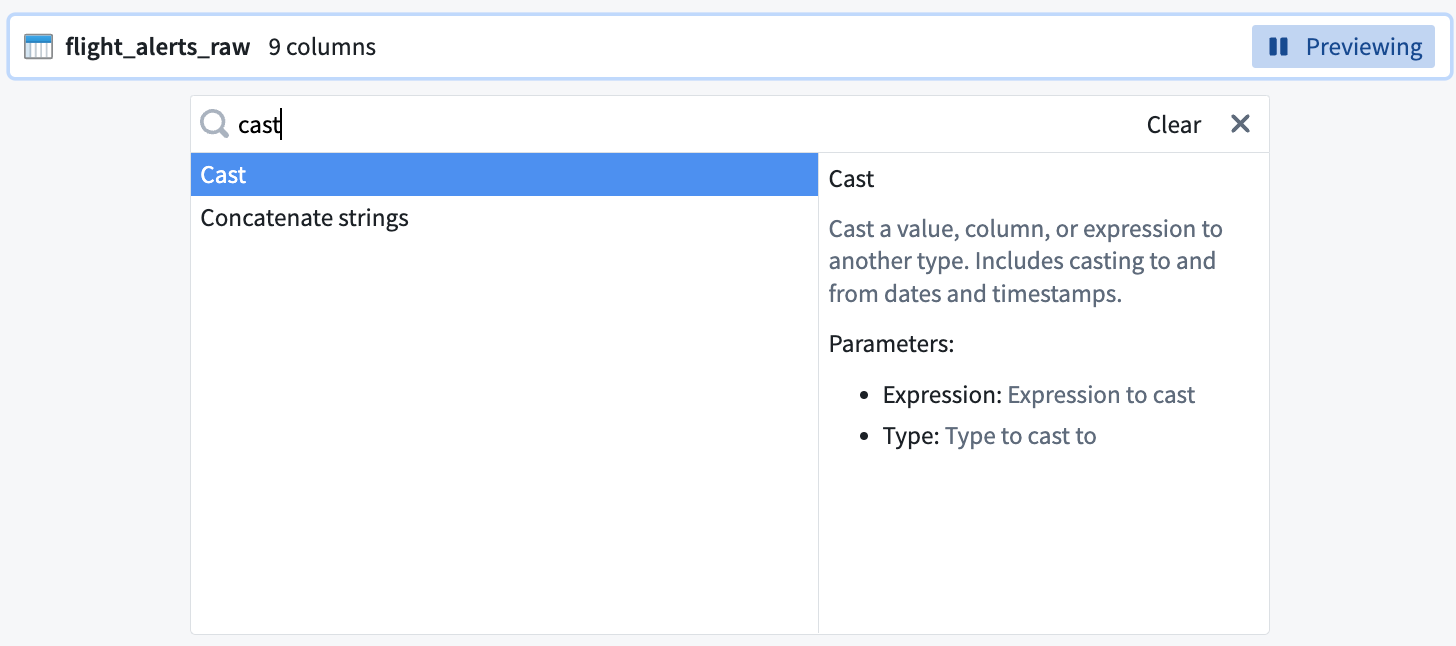
-
Expression フィールドで、ドロップダウンから
flight_date列を選択します。 -
Type フィールドのドロップダウンから
Dateを選択します。 -
Format タイプに
MM/dd/yyを入力します。キャスト変換が成功することを確認するために、大文字のMMを使用してください。キャストボードは以下のようになります:
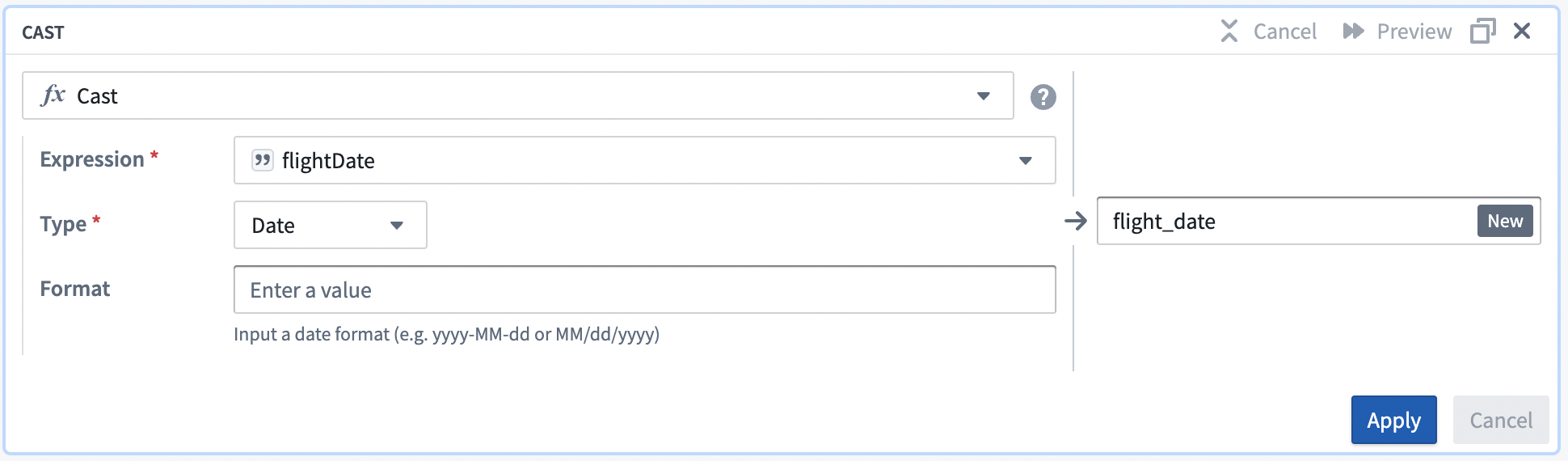
-
変換をパイプラインに追加するには、Apply をクリックします。
Clean string 変換
次に、category 列の値から空白を削除する Clean string 変換を追加します。例えば、変換では delay··· 文字列の値を delay に変換します。
-
ドロップダウンから clean string 変換を検索して選択し、clean string 設定ボードを開きます。
-
Expression フィールドで、ドロップダウンから
category列を選択します。 -
Clean actions オプションのすべての 3 つのチェックボックスを選択します:
- 空の文字列を null に変換
- 複数の空白文字のシーケンスを単一の空白に削減
- 文字列の先頭と末尾の空白を削除
clean string ボードは以下のようになります:
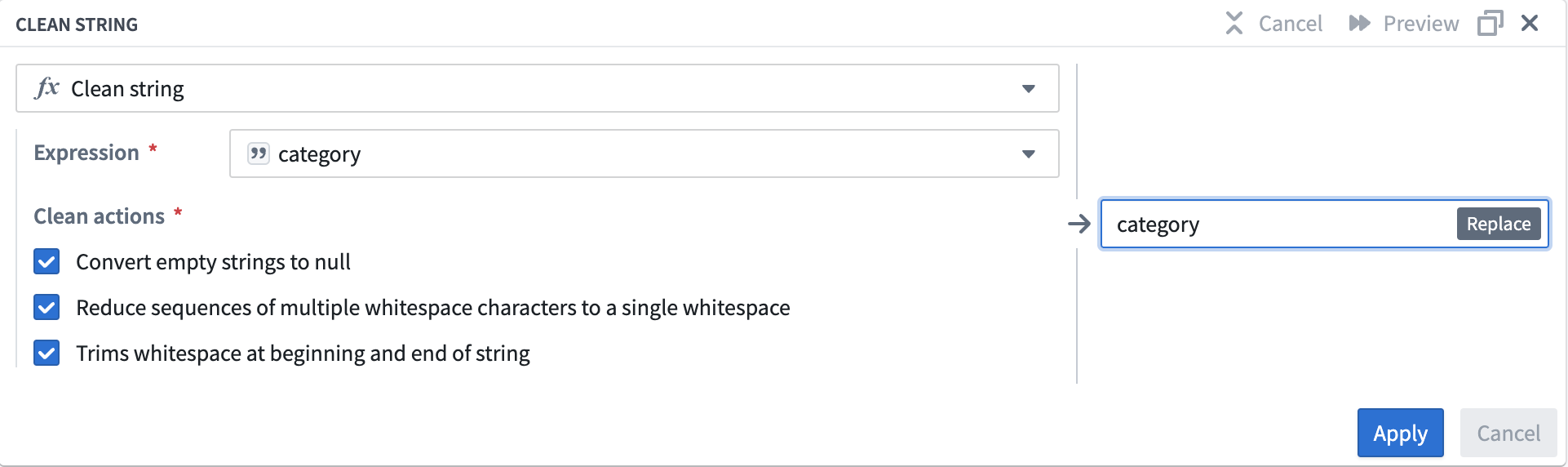
-
変換をパイプラインに追加するには、Apply をクリックします。
-
変換設定ウィンドウの左上隅で、変換の名前を
Flight Alerts - Cleanに変更します。 -
パイプライングラフに戻るには、右上の Back to graph をクリックします。
データセット 3
最後に、status_mapping_raw データセットをクリーニングしましょう。
Clean string 変換
このデータセットには Clean string 変換のみを適用します。
-
グラフ内の
status_mapping_rawデータセットノードをクリックします。 -
Transform をクリックします。
-
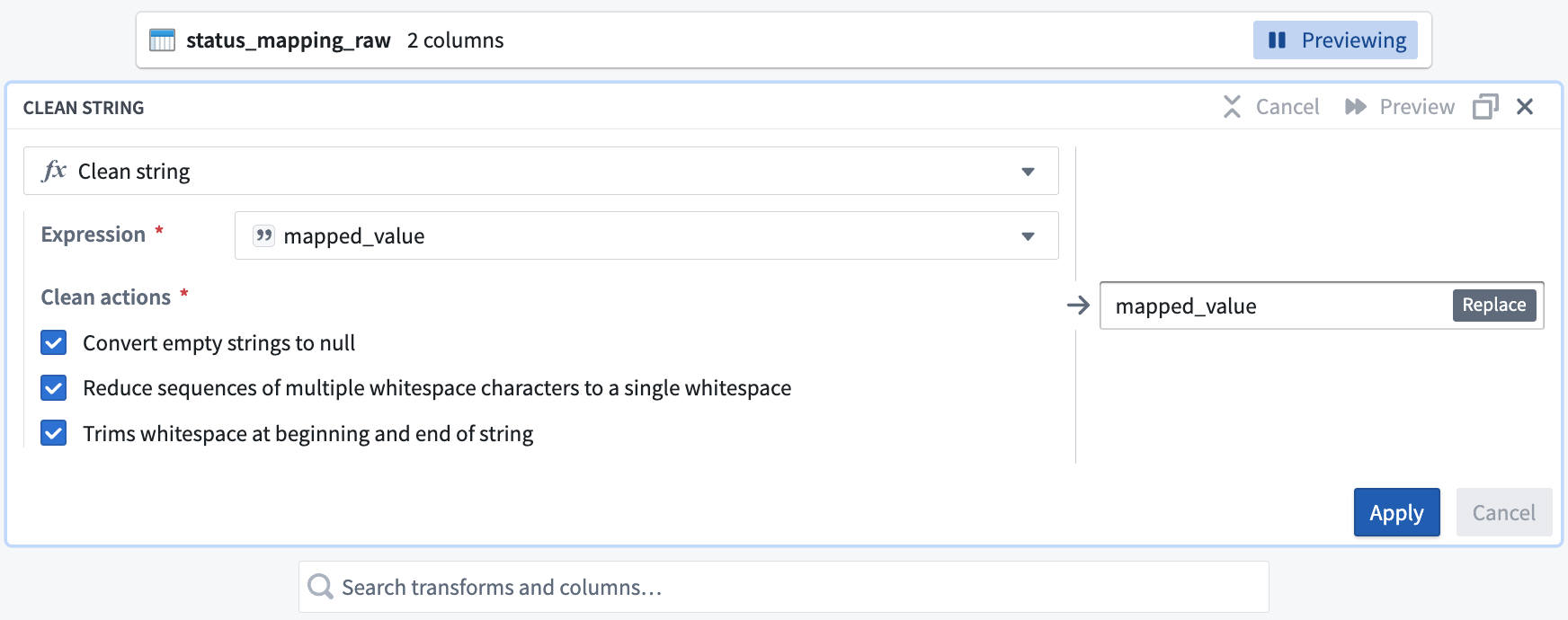
Search transforms and columns... フィールドで、ドロップダウンから
mapped_value列を選択します。
-
同じフィールドで、ドロップダウンから clean string 変換を検索して選択します。
-
Clean actions オプションのすべての 3 つのチェックボックスを選択します:
-
空の文字列を null に変換
-
複数の空白文字のシーケンスを単一の空白に削減
-
文字列の先頭と末尾の空白を削除
clean string ボードは以下のようになります:
-
変換をパイプラインに追加するには、Apply をクリックします。
-
変換設定ウィンドウの左上隅で、変換の名前を
Status Mapping - Cleanに変更します。 -
パイプライングラフに戻るには、右上の Back to graph をクリックします。
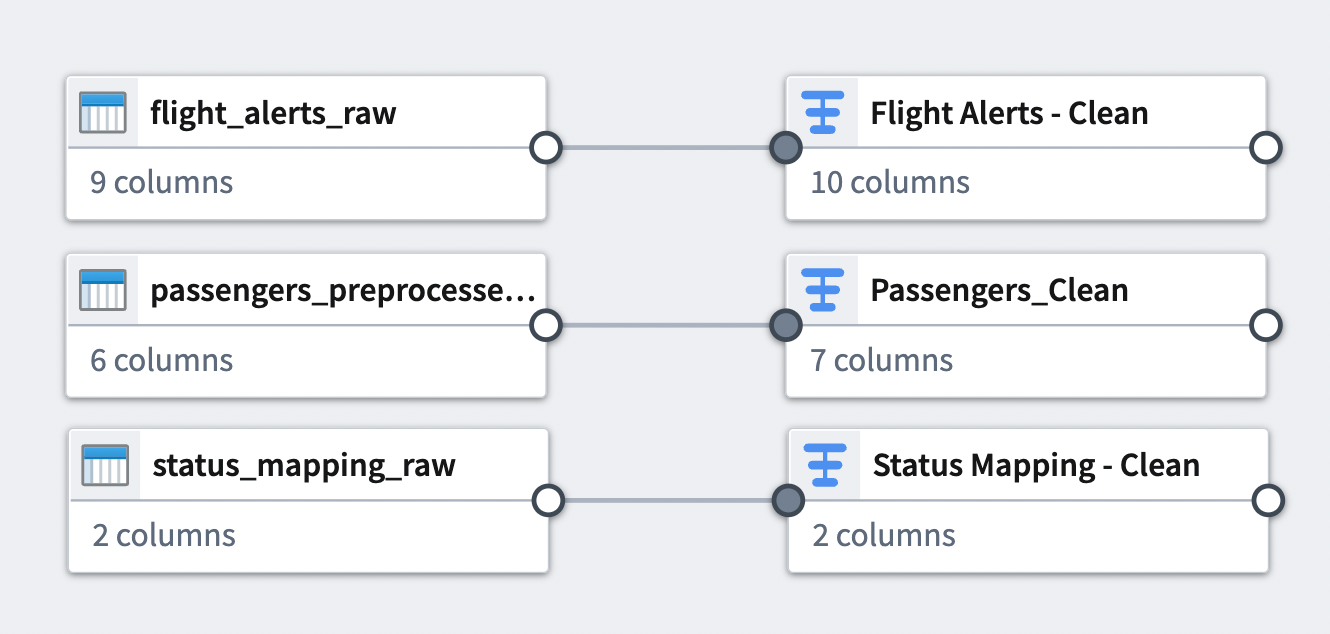
これで、追加した変換と適用したデータセットとの間の接続が表示されます。
パート 4: データセットを結合する
これで、joins を使ってクリーニングしたデータセットを組み合わせることができます。結合では、少なくとも 1 つの一致する列を持つデータセットを組み合わせることができます。パイプラインワークフローに 2 つの結合を追加します。
結合 1
最初の結合では、クリーニング済みのデータセットを 2 つ組み合わせます。
-
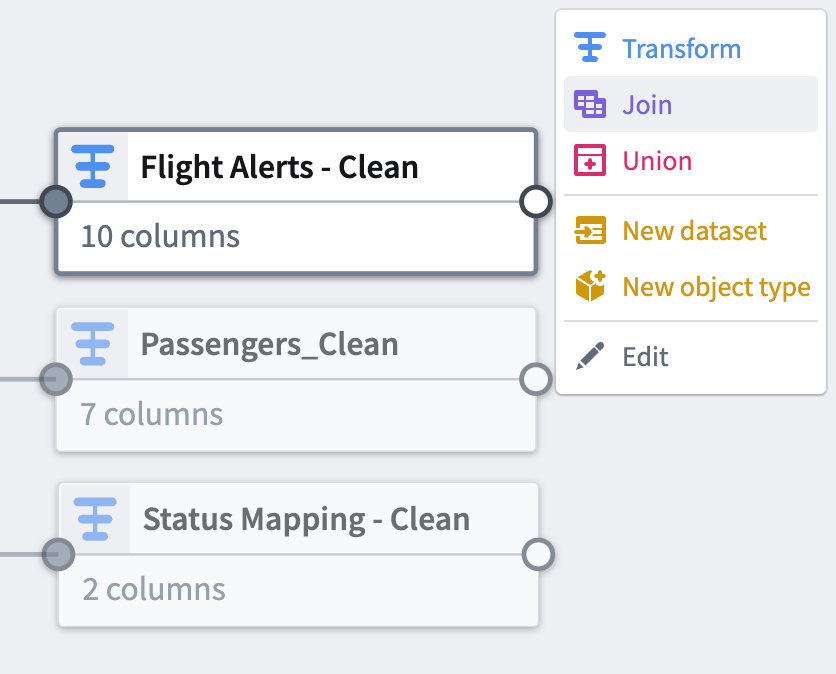
Flight Alerts - Clean変換ノードをクリックします。これが結合の左側になります。 -
Join を選択します。
-
Status Mapping - Cleanノードをクリックして、結合の右側に追加します。 -
Start をクリックして、結合設定ボードを開きます。

-
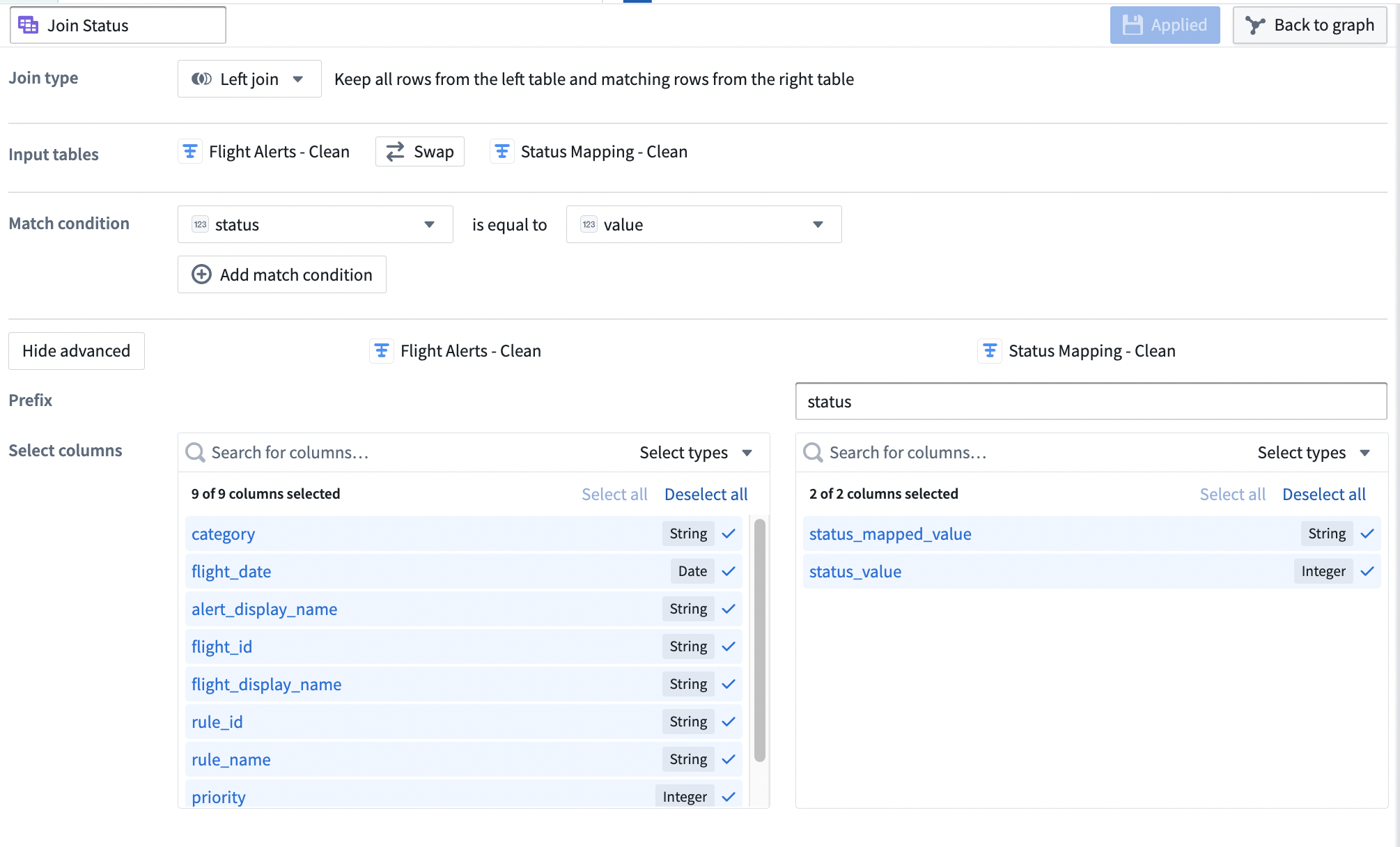
Join type が
Left joinに設定されていることを確認します。 -
Match condition 列を
statusとvalueが等しいように設定します。 -
追加の設定オプションを表示するには、Show advanced をクリックします。
-
右側の
Status Mapping - Cleanデータセットの Prefix をstatusに設定します。結合設定ボードは以下のようになります:
-
結合をパイプラインに追加するには、Apply をクリックします。
-
結合出力テーブルのプレビューを設定ウィンドウの下部にある Preview ペインで表示します。
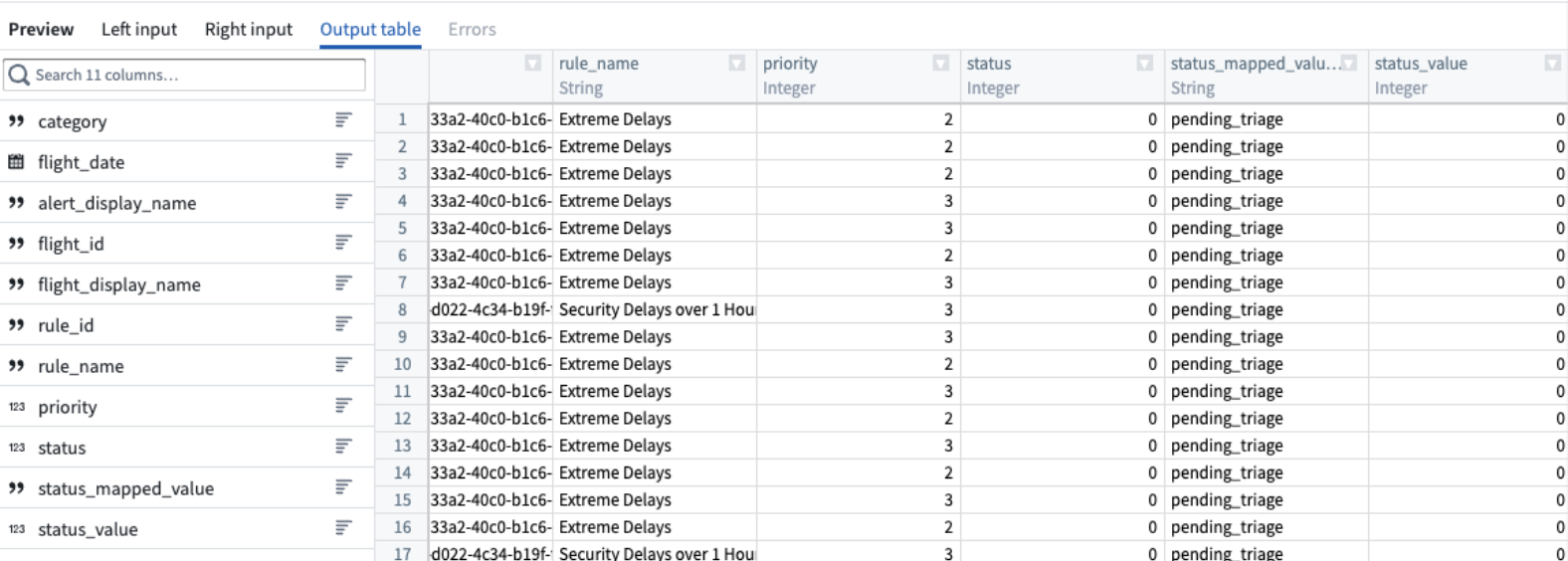
-
結合設定ウィンドウの左上隅で、結合の名前を
Join Statusに変更します。 -
パイプライングラフに戻るには、右上の Back to graph をクリックします。
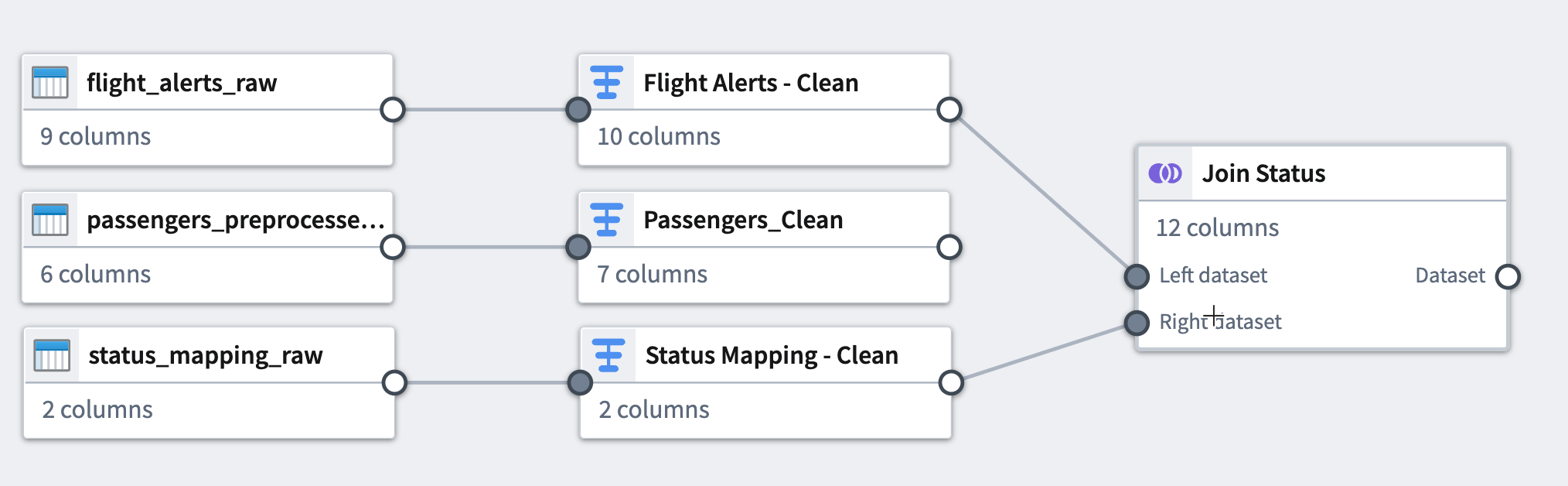
-
グラフを読みやすくするために、Layout アイコンをクリックしてデータセットを自動的に整列させるか、手動で 2 つの接続されたデータセットを隣同士に配置します。
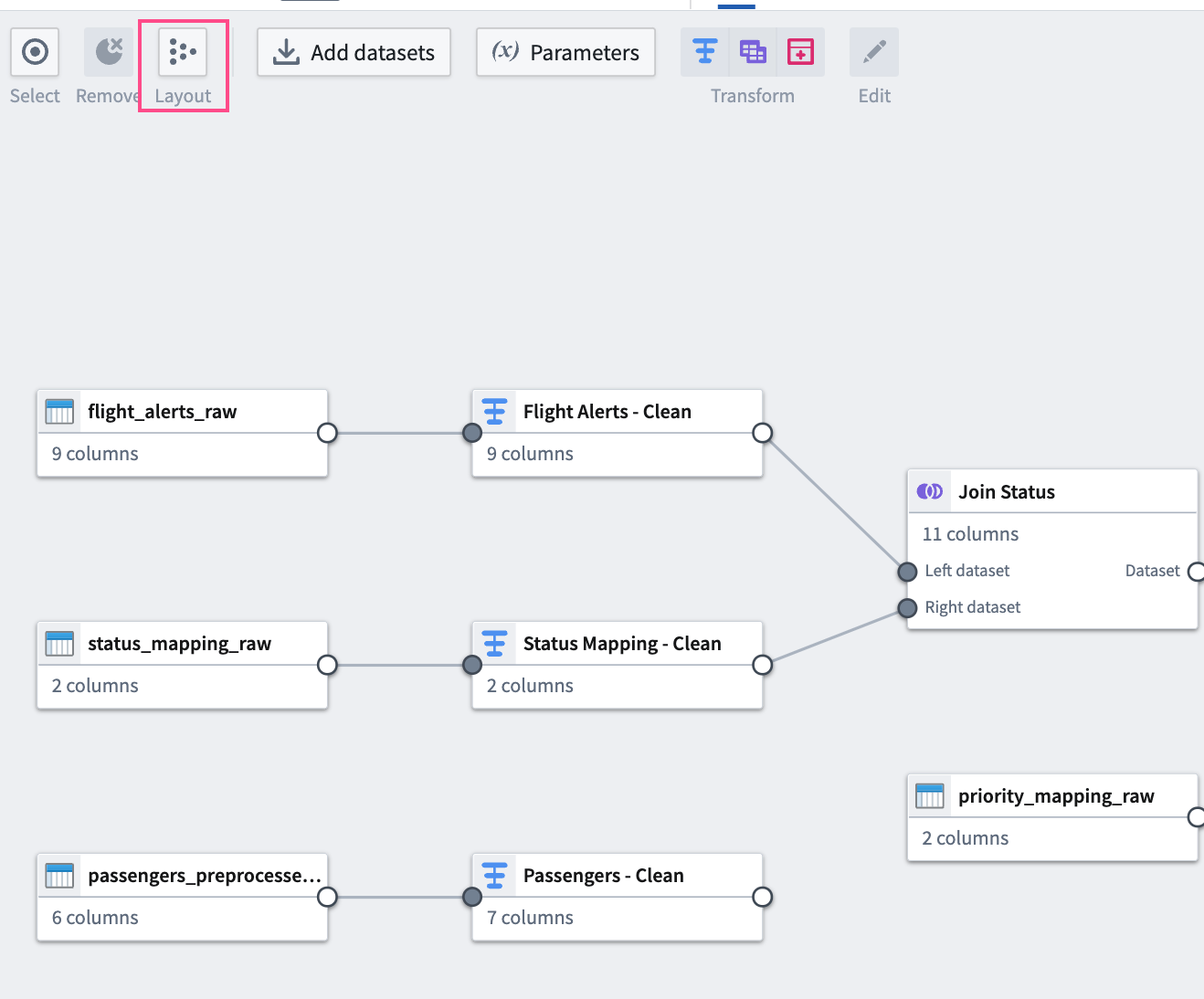
結合 2
2 番目の結合では、最初の結合出力テーブルを別の生データセットと組み合わせます。
-
Add datasets をクリックして、グラフに
priority_mapping_rawデータセットを追加します。 -
先ほどグラフに追加した
Join Statusノードをクリックします。これが結合の左側になります。 -
Join を選択します。
-
priority_mapping_rawデータセットノードをクリックして、結合の右側に追加します。 -
Start をクリックして、設定ボードを開きます。

-
Join type が
Left joinに設定されていることを確認します。 -
Match condition 列を
priorityとvalueが等しいように設定します。 -
追加の設定オプションを表示するには、Show advanced をクリックします。
-
右側の
priority_mapping_rawデータセットの Prefix をpriorityに設定します。結合設定ボードは以下のようになります:
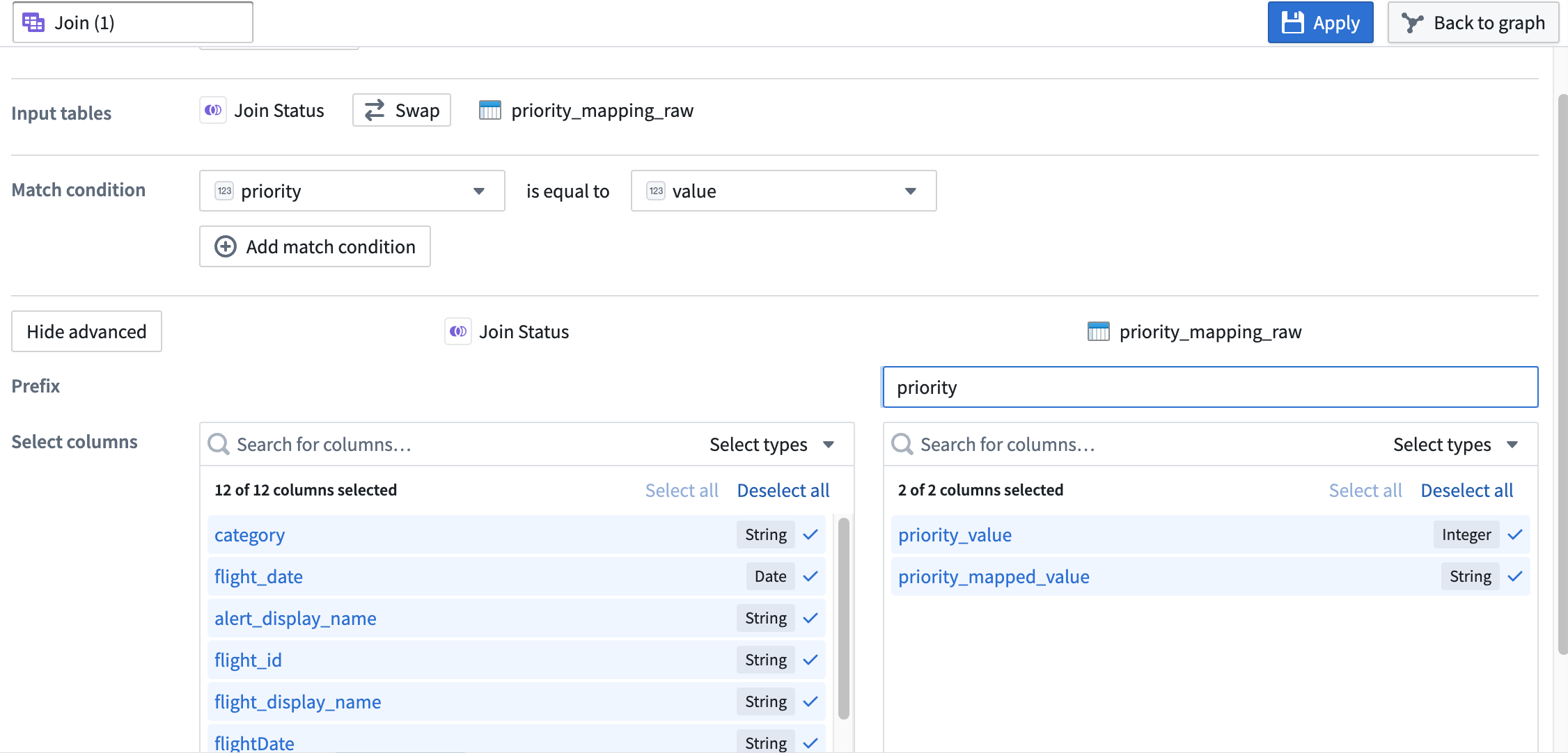
-
結合をパイプラインに追加するには、Apply をクリックします。
-
結合出力テーブルのプレビューを設定ウィンドウの下部にある Preview ペインで表示します。
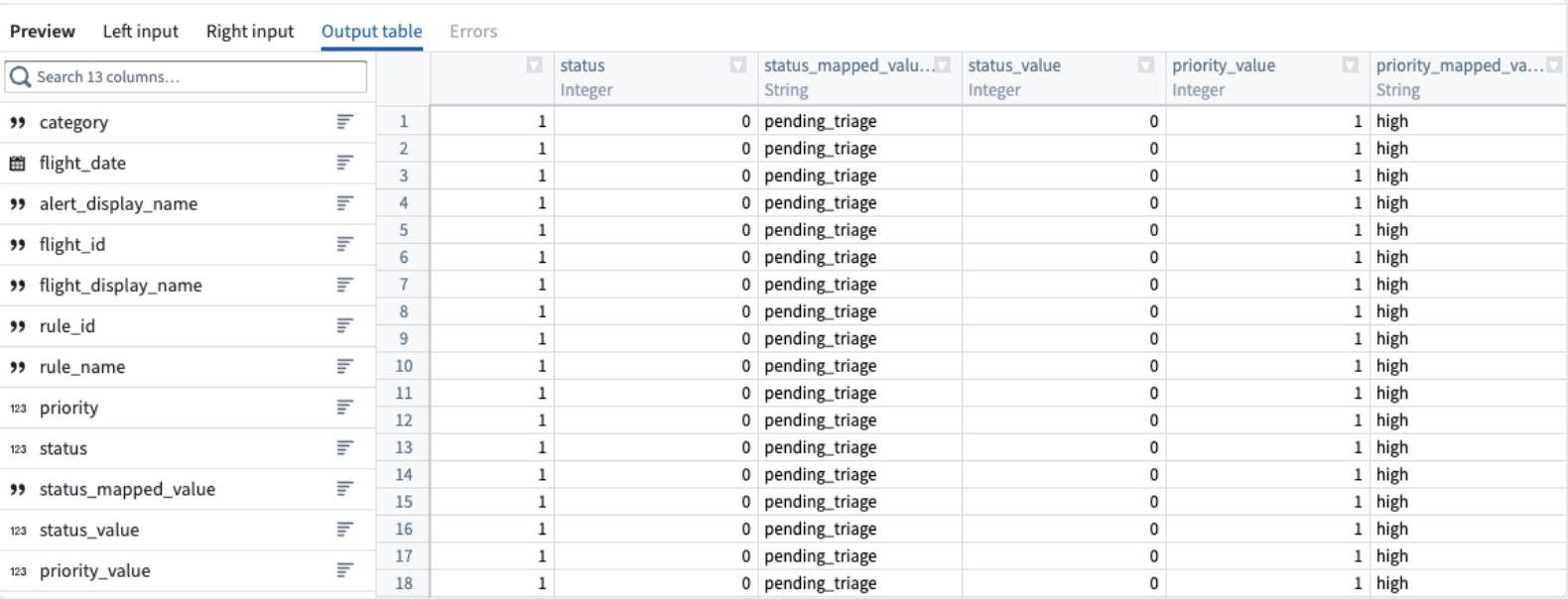
-
結合設定ウィンドウの左上隅で、結合の名前を
Join (2)に変更します。 -
パイプライングラフに戻るには、右上の Back to graph をクリックします。
これで、追加した結合と適用したデータセットとの間の接続が表示されます。
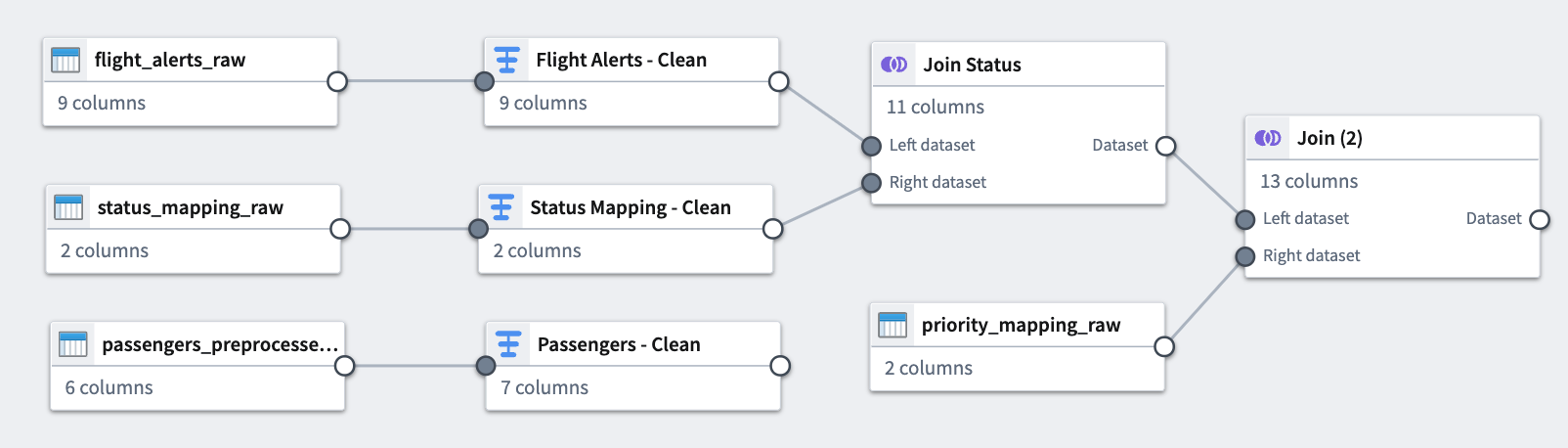
パート 5: 出力を追加する
データの変換と構造化が完了したので、出力を追加しましょう。このチュートリアルでは、データセット出力を追加します。
-
Pipeline Builder グラフの右側にある Pipeline outputs サイドバーで、出力の名前を
Flight Alerts dataに設定します。次に、Add dataset output をクリックします。 -
Join (2)から出力にリンクするために、結合ノードの右側にある白い円をクリックし、Flight Alerts dataデータセットに接続します。 -
既存のスキーマを使用するには、Use input schema をクリックします。
-
ここから、保持するデータの列を選択します。今回の場合、すべてのデータを一緒に保持します。
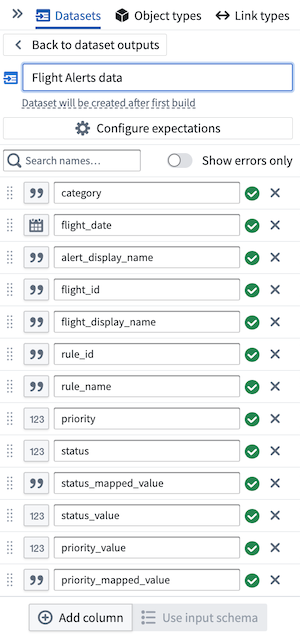
パート 6: パイプラインの構築
パイプラインを構築するには、Save をクリックし、次に Deploy > Deploy pipeline をクリックしてください。
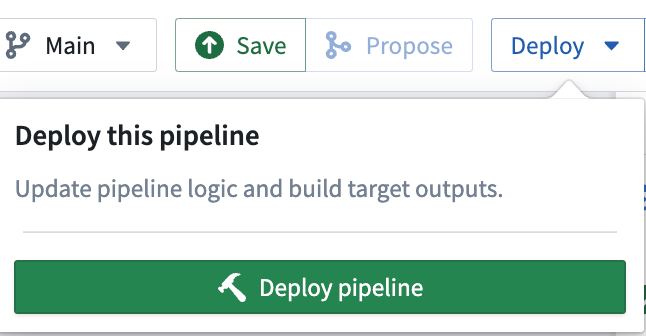
デプロイが成功したことを示す小さなアラートが表示されるはずです。アラートボックス内の View をクリックして、Build progress ページを開きます。
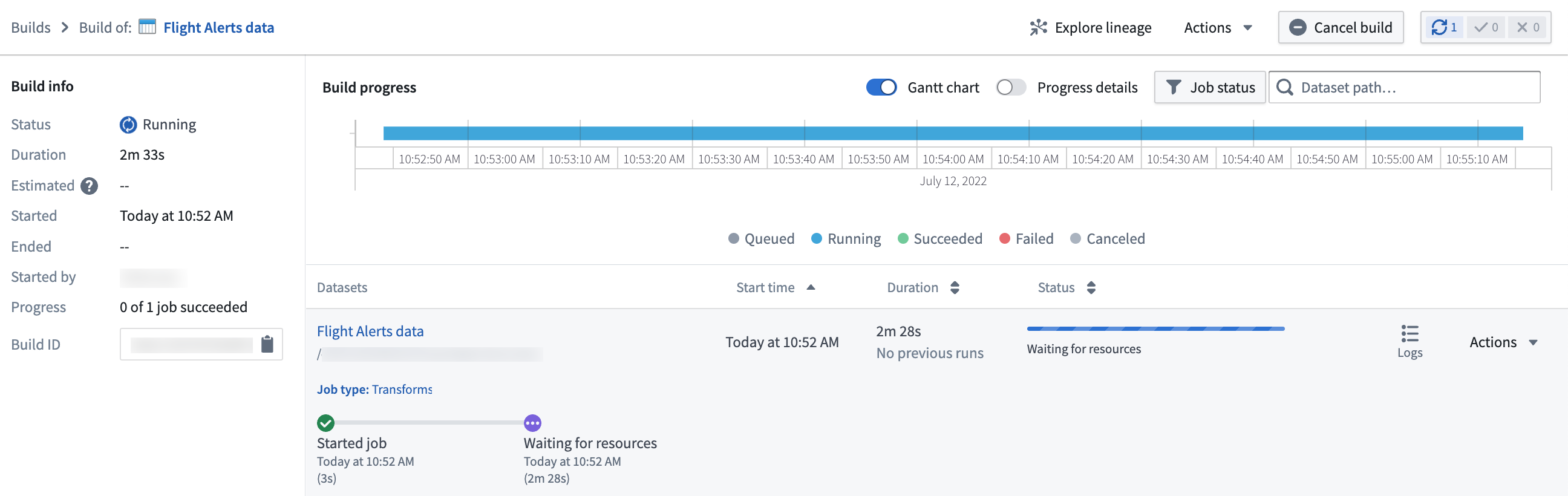
このページから、データセット出力が準備できるまでビルドの進行状況を監視できます。
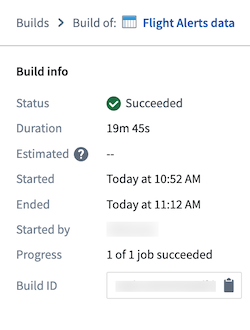
データセットにアクセスするには、Actions > Open をクリックします。
この最後のステップで、パイプライン出力が生成されました。この出力は、Foundry 内の他のアプリ Contour や Code Workbook などでさらに探索するためのデータセットです。