注: 以下の翻訳の正確性は検証されていません。AIPを利用して英語版の原文から機械的に翻訳されたものです。
Amazon S3
Foundry を AWS S3 に接続して、S3 と Foundry 間でデータを読み取りおよび同期します。
サポートされている機能
| 機能 | ステータス |
|---|---|
| 探索 | 🟢 一般提供 |
| 一括インポート | 🟢 一般提供 |
| 増分 | 🟢 サポートされているファイル形式に対して一般提供 |
| メディアセット | 🟢 一般提供 |
| Virtual tables | 🟢 一般提供 |
| File exports | 🟢 一般提供 |
設定
- Data Connection アプリケーションを開き、画面右上の + New Source を選択します。
- 利用可能なコネクタタイプから S3 を選択します。
- インターネット経由で direct connection を使用するか、中間エージェントを介して接続 するかを選択します。
- 以下のセクションの情報に従って、コネクタの設定を続行するための追加の設定プロンプトに従います。
Foundry での コネクタの設定 についてさらに詳しく学びます。
接続の詳細
| オプション | 必須? | 説明 |
|---|---|---|
URL | はい | S3 バケットの URL。データ接続は s3a プロトコルをサポートしています。末尾にスラッシュを含める必要があります。詳細については AWS の 公式ドキュメント ↗ を参照してください。 たとえば: s3://bucket-name/ |
Endpoint | はい | S3 にアクセスするために使用するエンドポイント。 たとえば: s3.amazonaws.com または s3.us-east-1.amazonaws.com |
Region | いいえ | AWS サービスを設定する際に使用する AWS リージョン。STS ロールを使用する場合に必要です。警告: リージョンを指定し、かつリージョンを含む S3 エンドポイントを指定すると、失敗する可能性があります。 たとえば: us-east-1 または eu-central-1 |
Network connectivity | はい - 直接接続の場合のみ | ステップ 1: Foundry イーグレスポリシー バケットに Foundry イーグレスポリシー を添付して、Foundry が S3 へイーグレスできるようにします。Data Connection アプリケーションは、提供された接続の詳細に基づいて適切なイーグレスポリシーを提案します。 たとえば: bucket-name.s3.us-east-1.amazonaws.com (ポート 443) ステップ 2: AWS バケットポリシー さらに、S3 からアクセスするために関連する Foundry IP および/またはバケットの詳細を許可リストに追加する必要があります。Foundry の IP 詳細は Control Panel アプリケーション の Network Egress で確認できます。S3 でバケットポリシーを設定する方法の詳細については、公式 AWS ドキュメント ↗ を参照してください。 注: Foundry エンロールメントと同じリージョンにホストされている S3 バケットへのアクセスを設定するには追加の設定が必要です。これらの要件については、network egress ドキュメント を参照してください。 |
Client certificates & private key | いいえ | クライアント証明書と秘密鍵は、接続のセキュリティを確保するためにソースによって必要とされる場合があります。 |
Server certificates | いいえ | サーバー証明書は、接続のセキュリティを確保するためにソースによって必要とされる場合があります。 |
Credentials | はい | オプション 1: アクセスキーとシークレット S3 への接続に必要なアクセスキー ID とシークレットを提供します。 資格情報は、AWS アカウントで Foundry 用の新しい IAM ユーザーを作成し、その IAM ユーザーに S3 バケットへのアクセス権を付与することで生成できます。 オプション 2: OpenID Connect (OIDC) 表示されたソースシステム構成手順に従って OIDC を設定します。OpenID Connect の詳細については公式の AWS ドキュメント ↗ を参照し、OIDC が Foundry とどのように連携するかについては ドキュメント を参照してください。 AWS IAM ユーザーを作成する方法の詳細については、公式の AWS ドキュメント ↗ を参照してください。Foundry がユーザーに期待する AWS の権限については、S3 の権限 を参照してください。 |
STS role | いいえ | S3 コネクタはオプションで Security Token Service (STS) ロール ↗ を使用して S3 に接続できます。詳細については STS ロールの設定 を参照してください。 |
Connection timeout | いいえ | 接続を最初に確立する際にあきらめてタイムアウトするまでの待機時間(ミリ秒単位)。 デフォルト: 50000 |
Socket timeout | いいえ | 確立され開かれた接続上でデータ転送を待機する時間(ミリ秒単位)。接続がタイムアウトして閉じられるまでの時間。 デフォルト: 50000 |
Max connections | いいえ | 許可される最大のオープン HTTP 接続数。 デフォルト: 50 |
Max error retries | いいえ | 失敗したリトライ可能なリクエスト(例: 5xx エラー応答)の最大リトライ試行回数。 デフォルト: 3 |
Client KMS key | いいえ | AWS SDK を使用してクライアント側でデータ暗号化を行うために使用される KMS キー名またはエイリアス。このオプションを PCloud のエージェントで使用するにはプロキシ設定が必要です。 |
Client KMS region | いいえ | KMS クライアントに使用する AWS リージョン。AWS KMS キーが提供されている場合にのみ関連します。 |
Match subfolder exactly | いいえ | 指定されたサブフォルダーを S3 内の正確なサブフォルダーとして一致させるオプション。false に設定されている場合、foo/bar/ のサブフォルダー設定で s3://bucket-name/foo/bar/ と s3://bucket-name/foo/bar_baz/ の両方が一致します。 |
Proxy configurations | はい - エージェントベースの接続の場合のみ | S3 のプロキシ設定を構成します。 注: これは (a) ユーザーの Foundry エンロールメントが AWS にホストされている場合、(b) S3 バケットがユーザーの Foundry エンロールメントとは異なる AWS リージョンにホストされている場合、および (c) データ接続エージェント経由で接続している場合に必要です。詳細については S3 プロキシ設定 を参照してください。 |
Enable path style access | いいえ | Path スタイルアクセス URL (たとえば, https://s3.region-code.amazonaws.com/bucket-name/key-name) を使用し、Virtual-hosted-style アクセス URL (たとえば, https://bucket-name.s3.region-code.amazonaws.com/key-name) を使用しません。詳細については 公式 AWS ドキュメント ↗ を参照してください。 |
Catalog | いいえ | この S3 バケットに保存されているテーブルのカタログを構成します。詳細については Virtual tables を参照してください。 |
S3 の読み取りおよび同期に必要な権限
S3 バケットのインタラクティブな探索には、以下の AWS 権限が必要です。
Copied!1 2 3 4 5{ "Action": ["s3:ListBucket"], // "s3:ListBucket"というアクションを指定します。これは、バケット内のオブジェクトのリストを取得するためのアクションです。 "Resource": ["arn:aws:s3:::path/to/bucket"], // このポリシーが適用されるリソースを指定します。ここでは特定のS3バケットを指定しています。 "Effect": "Allow", // このポリシーにより定義されたアクション(この場合はバケットのリスト取得)を許可します。 }
以下のAWS権限は、バッチ同期、仮想テーブル、およびS3からのメディア同期に必要です:
Copied!1 2 3 4 5 6 7 8{ // "Action": アクションの配列(この場合はS3オブジェクトを取得するアクション) "Action": ["s3:GetObject"], // "Resource": リソースの配列(この場合は特定のS3バケットへのパス) "Resource": ["arn:aws:s3:::path/to/bucket/*"], // "Effect": ポリシーの効果(この場合は許可) "Effect": "Allow", }
Amazon S3 のバケットポリシーの設定方法の詳細については、公式の AWS ドキュメンテーションのポリシーと権限 ↗をご覧ください。
S3 プロキシ設定 (エージェントベースの接続)
データ接続エージェントを使用して S3 に接続する場合、プロキシ設定は以下の2つの方法で定義できます:
- ソース設定: 下記の表に示すように、ソース設定内で直接各プロキシ設定を定義します。
- エージェントのシステムプロパティ: フォールバックとして、エージェントのシステムプロパティ内でプロキシ設定を設定することができます。これを行うには、エージェントの詳細設定設定に適切な JVM 引数を含めます (例:
-Dhttps.proxyHost=example.proxy.com).
| パラメーター | 必須? | デフォルト | 説明 |
|---|---|---|---|
host | Y | HTTP プロキシホスト (スキームなし) | |
port | Y | HTTP プロキシのポート | |
protocol | N | HTTPS | 使用するプロトコル。HTTPS または HTTP |
nonProxyHosts | N | プロキシを使用しないホスト名 (またはワイルドカードドメイン名) のリスト。例: `*.s3-external-1.amazonaws.com | |
資格情報 | N | プロキシが基本的な HTTP 認証を要求する場合 ( HTTP 407 応答 ↗ によってプロンプト表示) 、このブロックを含めてください | |
資格情報.username | N | HTTP プロキシのプレーンテキストユーザー名 | |
資格情報.password | N | HTTP プロキシの暗号化されたパスワード |
STS ロール設定
STS ロール設定を使用すると、S3 から読み取る際に AWS Security Token Service ↗ を使用してロールを引き受けることができます。
| パラメーター | 必須? | デフォルト | 説明 |
|---|---|---|---|
roleArn | Y | STS ロールの ARN 名 | |
roleSessionName | Y | このロールを引き受ける際に使用するセッション名 | |
roleSessionDuration | N | 3600 秒 | セッションの期間 |
externalId | N | ロールを引き受ける際に使用する外部 ID |
クラウドアイデンティ設定
クラウドアイデンティ認証を使用すると、Foundry はユーザーの AWS インスタンス内のリソースにアクセスすることができます。クラウドアイデンティは、Control Panelの エンロールメント レベルで設定および管理されます。クラウドアイデンティを設定する方法を学びましょう。
クラウドアイデンティ認証を使用する場合、ロール ARN は資格情報セクションに表示されます。Cloud identity 資格情報オプションを選択した後、以下の設定も行う必要があります:
- ターゲットの Amazon AWS アカウント内で Identity and Access Management (IAM) ロールを設定します。
- ユーザーが接続を希望する S3 バケットに IAM ロールへのアクセスを許可します。通常、バケットポリシー ↗ を使用してこれを行うことができます。
- S3 ソース設定の詳細に、IAM ロールを Security Token Service (STS) ロール ↗ 設定の下に追加します。Foundry のクラウドアイデンティ IAM ロールは、S3 にアクセスする際に AWS アカウント IAM ロール ↗ を引き受けるように試みます。
- クラウドアイデンティ IAM ロールがターゲットの AWS アカウント IAM ロールを引き受けることを許可するための 対応する信頼ポリシーを設定します ↗。
仮想テーブル
このセクションでは、S3 ソースから 仮想テーブル を使用する際の追加詳細を提供します。このセクションは、Foundry データセットへの同期時には適用されません。
| 仮想テーブル機能 | ステータス |
|---|---|
| ソースフォーマット | 🟢 一般的に利用可能: Avro ↗, Delta ↗, Iceberg ↗, Parquet ↗ |
| 手動登録 | 🟢 一般的に利用可能 |
| 自動登録 | 🔴 利用不可 |
| プッシュダウンコンピューティング | 🔴 利用不可 |
| インクリメンタルパイプラインサポート | 🟢 Delta テーブルに一般的に利用可能: APPEND のみ (詳細)🟢 Iceberg テーブルに一般的に利用可能: APPEND のみ (詳細)🔴 Parquet テーブルでは利用不可 |
仮想テーブル を登録する際には、以下のソース設定要件を覚えておいてください:
- ソースを 直接接続 として設定する必要があります。仮想テーブルは 中間エージェント の使用をサポートしていません。
- ネットワーク接続性 セクションで説明されているように、双方向接続性と許可リストの設定が確立されていることを確認します。
- 仮想テーブルをコードリポジトリで使用する場合は、追加のソース設定の詳細については 仮想テーブルのドキュメンテーション を参照してください。
- バケットが
.を含む場合は、パススタイルアクセスを有効にし、適切な出力ポリシーを設定する必要があります。
詳細については、上記の 接続詳細 セクションを参照してください。
Delta
仮想テーブルでサポートされているパイプラインのインクリメンタルサポートを有効にするには、ソースの Delta テーブルで Change Data Feed ↗ を有効にすることを確認してください。Pythonトランスフォーム の current および added 読み取りモードがサポートされています。_change_type, _commit_version, _commit_timestamp 列が Pythonトランスフォームで利用可能になります。
Iceberg
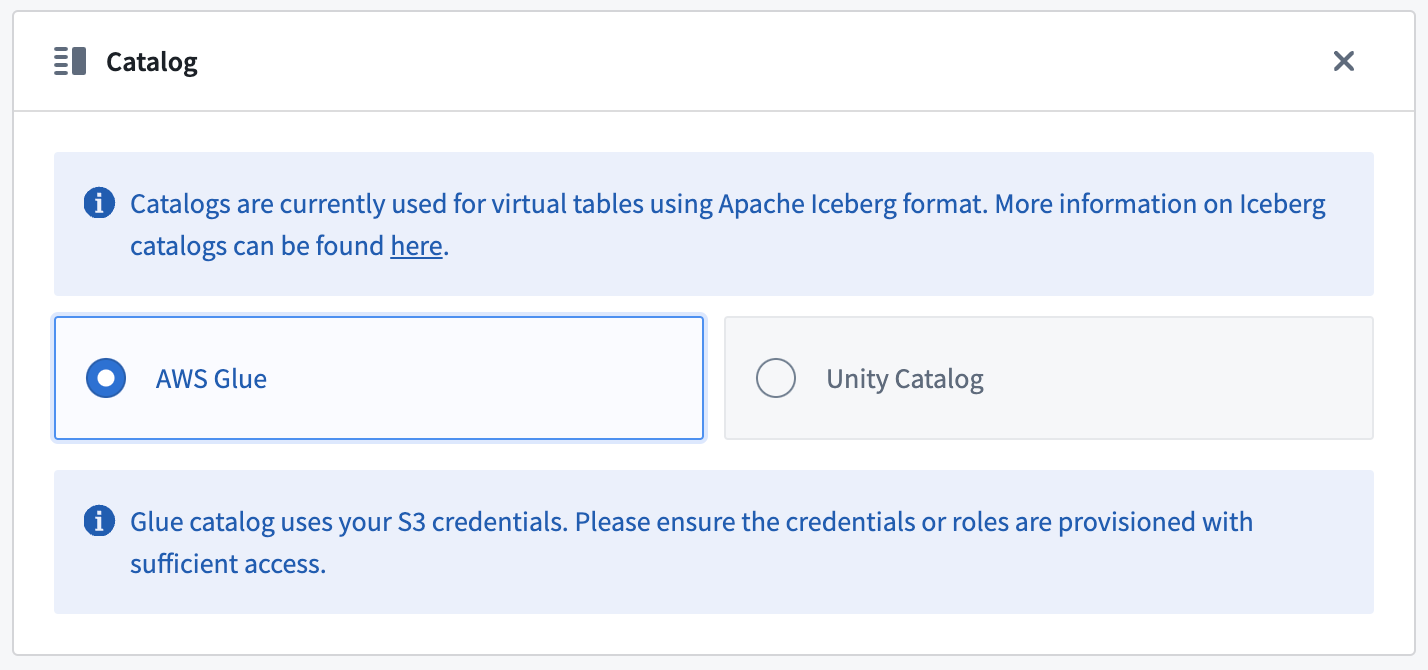
Apache Iceberg テーブルをバックにした仮想テーブルをロードするには、Iceberg カタログが必要です。Iceberg カタログについて詳しく知りたい場合は、Apache Iceberg ドキュメンテーション ↗ をご覧ください。ソースで登録されたすべての Iceberg テーブルは同じ Iceberg カタログを使用する必要があります。
デフォルトでは、テーブルは S3 の Iceberg メタデータファイルを使用して作成されます。テーブルを登録する際に、これらのメタデータファイルの場所を示す warehousePath を提供する必要があります。
AWS Glue ↗ を S3 に格納されているテーブルの Iceberg カタログとして使用することができます。この統合について詳しく知りたい場合は、AWS Glue ドキュメンテーション ↗ をご覧ください。ソースに設定された資格情報は、ユーザーの AWS Glue Data Catalog にアクセスする必要があります。AWS Glue はソース上の 接続詳細 タブで設定できます。このソースで登録されたすべての Iceberg テーブルは自動的に AWS Glue をカタログとして使用します。テーブルは database_name.table_name の命名パターンを使用して登録する必要があります。
Unity Catalog ↗ を Databricks の Delta Universal Format (UniForm) を使用している場合の Iceberg カタログとして使用することができます。この統合について詳しく知りたい場合は、Databricks ドキュメンテーション ↗ をご覧ください。AWS Glue と同様に、カタログはソース上の 接続詳細 タブで設定できます。Unity Catalog に接続するためにエンドポイントと パーソナルアクセストークン を提供する必要があります。テーブルは catalog_name.schema_name.table_name の命名パターンを使用して登録する必要があります。
インクリメンタルサポートは Iceberg の Incremental Reads ↗ に依存しており、現在は追加のみです。Pythonトランスフォーム の current および added 読み取りモードがサポートされています。
Parquet
Parquet を使用した仮想テーブルは、スキーマ推論に依存します。最大で 100 のファイルがスキーマを決定するために使用されます。
S3 へのデータエクスポート
S3 へのエクスポートを行うには、まず、ユーザーの S3 コネクターの エクスポートを有効にします。次に、新しいエクスポートを作成します。
S3 へのエクスポートに必要な許可
データを S3 にエクスポートするためには、次の AWS 権限が必要です:
Copied!1 2 3 4 5{ "Action": ["s3:PutObject"], // アクション: S3にオブジェクトを配置する "Resource": ["arn:aws:s3:::path/to/bucket/*"], // リソース: S3バケットのパス "Effect": "Allow", // 効果: 許可する }
Amazon S3 のバケットポリシーの設定方法の詳細については、公式の AWS ドキュメンテーションの Policies and Permissions in Amazon S3 ↗を参照してください。
エクスポート設定オプション
| オプション | 必須? | デフォルト | 説明 |
|---|---|---|---|
Path Prefix | いいえ | N/A | エクスポートされたファイルに使用するべきパスプレフィックス。エクスポートされたファイルの全パスは s3://<bucket-name>/<path-in-source-config>/<path-prefix>/<exported-file> として計算されます。 |
Canned ACL | いいえ | N/A | アップロードされたファイルに添付される AWS アクセス制御リスト(ACL)を設定します。それぞれの ACL の説明については、AWS ドキュメンテーション ↗を参照してください。 |