注: 以下の翻訳の正確性は検証されていません。AIPを利用して英語版の原文から機械的に翻訳されたものです。
お知らせ
**リマインダー:**Foundry Newsletterに今すぐサインアップして、新製品、新機能、プラットフォーム全体での改善の要約を直接ユーザーの受信トレイに受け取ることができます。サブスクライブ方法の詳細については、Foundry Newsletter および Product Feedback channels announcementを参照してください。
Code Workspaces GA での JupyterLab® と RStudio® のサポートを紹介、2024年3月リリース予定
公開日:2024-02-22
私たちはCode Workspacesを作成しました。ユーザーは広く知られたツールを使用して効果的な探索的分析を行いながら、Palantir Foundryのパワーをシームレスに活用できます。3月4日の週に一般に利用可能となるCode Workspacesは、JupyterLab®とRStudio®のサードパーティIDEをFoundryに導入し、ユーザーが生産性を向上させ、データサイエンスと統計のワークフローを加速することを可能にします。Code Workspacesは、比類のないスピードと柔軟性を提供することで、Foundry内で包括的な探索的分析を行うための決定的なハブとなります。
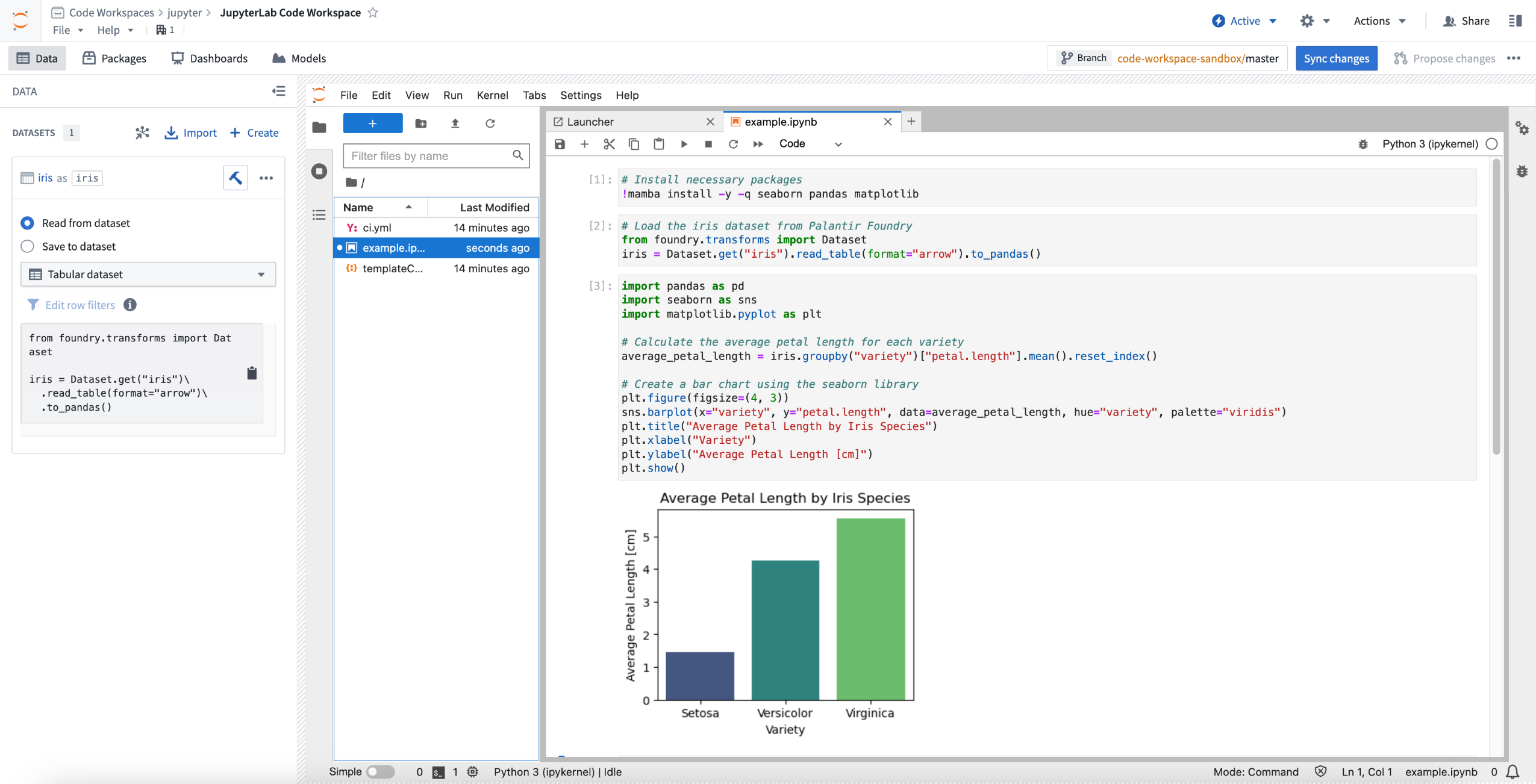
Jupyter® Code Workspace used for data science.
柔軟で効率的な探索的分析
Code WorkspacesはJupyterLab® NotebooksやRStudio® Workbenchのような広く使用されているツールをPalantirエコシステムのパワーと統合し、Foundry内で効率的な探索的分析を行うための主要な場所として確立します。 以下の機能を近々利用できるようになります:
- 広く採用されているデータサイエンスと機械学習のツールを使用し、RStudio®とJupyter®をユーザーの組織のデータの上にシームレスに統合します。
- Foundryの世界クラスのセキュリティ、由来、ガバナンス、データフローの原理を活用しながら、任意のデータセットからデータをロードします。
- インタラクティブなコード開発と書き戻し、インスタントフィードバックループ、セルごとの分析とREPLターミナルコマンドによるプレビュー。
- データ、可視化、レポート、洞察を変換または生成し、それらをPalantirプラットフォームの残りの部分で消費できるようにします。
- プロダクションで使用する前に、機械学習モデルを効率的に訓練、最適化、実装します。
- Conda、pip、CRANをサポートする対話型、統合パッケージマネージャーソリューションを使用して、PythonとRの環境を完全にカスタマイズします。
- Code Repositoriesが提供するネイティブGitバージョン管理と協調機能を使用します。
- Dash、Streamlit®、Shiny®ダッシュボードを作成して、同僚と分析を共有し、意思決定を促進します。
- 処理するデータのスケールに合わせて、ユーザーの計算設定を完全にカスタマイズします。
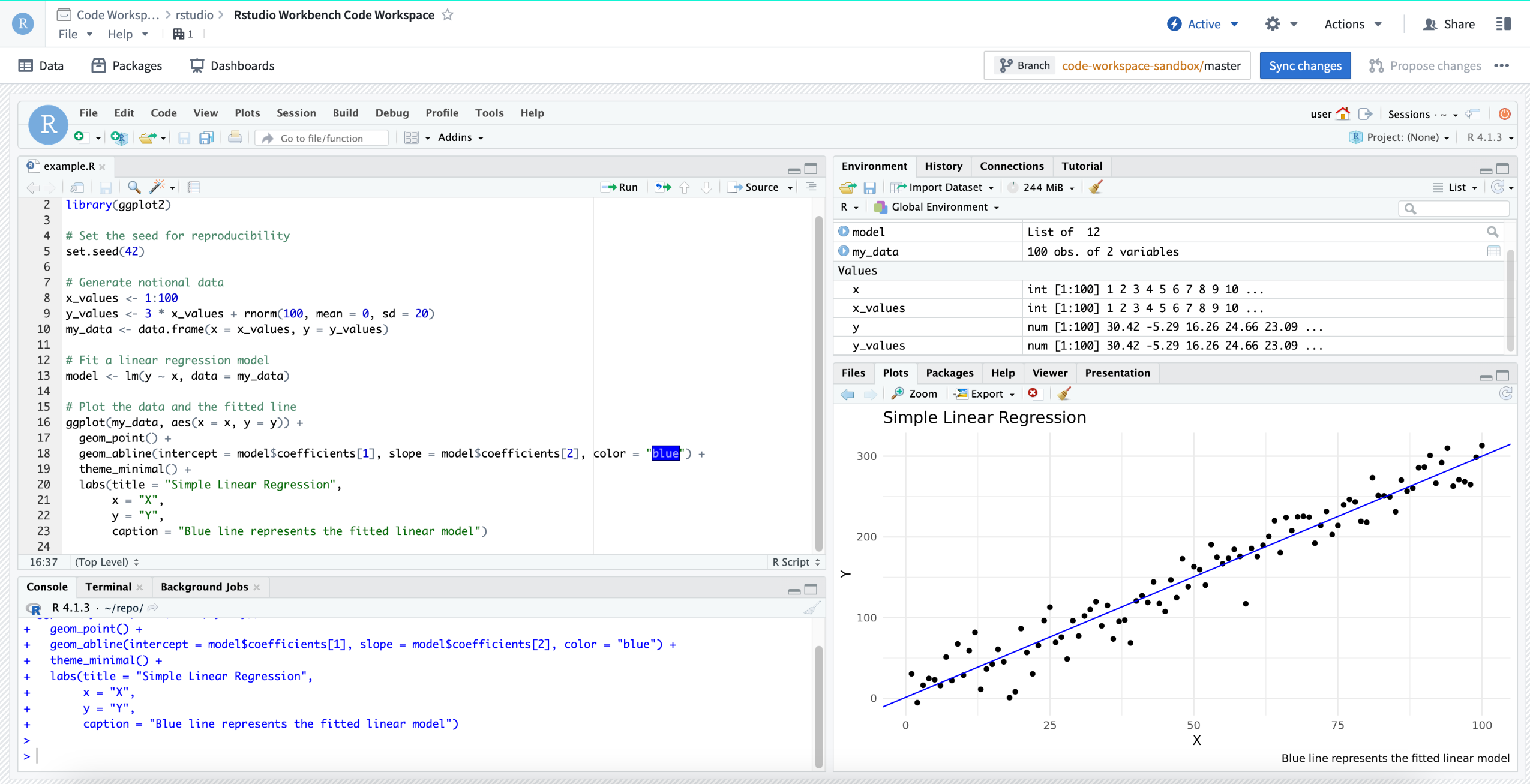
RStudio® Code Workspace used for machine learning training.
いつCode Workspacesを使用するべきか?
Code Workspacesは、ユーザーのデータに対して素早く効率的な反復的な分析を行うための包括的なツールセットを提供し、サードパーティのツールの最善の部分をPalantirの幅広い組み込みデータ分析機能とシームレスに統合します。データ可視化、プロトタイピング、レポート作成、反復的なデータ変換に使用します。Code RepositoriesとPipeline Builderは、これらのデータ変換を堅牢なプロダクションパイプラインに変換するために使用できます。 ほとんどのワークフローでは、Code Workspacesと他のFoundryツールは互いに補完し、任意のパイプラインの出力がCode Workspaces分析の入力として受け入れられ、その逆も同様です。Code RepositoriesとCode Workspacesは同じGitバージョン管理システムに依存します。大規模なRパイプライン、モデル訓練、または広範な可視化ワークフローは、その分散Sparkアーキテクチャを活用するためにCode Workbookにエクスポートすることもできます。
影響を及ぼす実世界の使用事例
以下の例は、Code Workspacesを活用する実世界の使用事例の選択リストです。
- 大手保険小売業者がCode Workspacesを使用して、保険料金モデルの微調整を行っています。
- 医療委員会がCode WorkspacesのStreamlitダッシュボードを使用して、多重免疫蛍光データの空間分析を、計算初心者の生物学者でもアクセスできるようにしています。
- 小売会社がJupyter® Code Workspacesを使用して、販売データの探索的分析を行い、予測モデルを開発しています。
- 製薬会社がRStudio® Code Workspacesを使用して、完全に再現可能な実験レポートを生成し、試験薬の効果を詳細に説明しています。
Code Workspacesで何ができるかについて詳しく知りたい場合は、関連するドキュメンテーションを参照してください:
開発ロードマップに何があるのか?
以下の機能は現在積極的に開発中です:
- Code Workspaces変換: JupyterLab® NotebookまたはRStudio® Rスクリプトの内容を取得し、Palantirの堅牢なビルドインフラストラクチャを活用して再現可能なパイプラインとして永続化します。
- Palantir管理モデルとの統合: Foundry内の他の場所で開発されたモデルをロードして使用します。
- AIP統合: AIPが直接サポートする任意の言語モデルにCode Workspacesからコールアウトします。
- オントロジーサポート: オントロジーの力を完全に活用し、オブジェクトをCode Workspacesにロードして探索的分析を行います。
- 一流のレポート作成ソリューション: データ分析をレポートに変換し、それを共有してユーザーの組織全体での意思決定を情報提供します。
- Jupyter®、JupyterLab®、およびJupyter®のロゴはNumFOCUSの商標または登録商標です。
- RStudio®とShiny®はPosit™の商標です。
- Streamlit®はSnowflake Incの商標です。
すべての第三者商標(ロゴおよびアイコンを含む)は、各所有者の財産です。関連性または推薦は暗示されません。
Code WorkspacesでのPalantir提供の言語モデルのサポートを紹介
公開日:2024-02-22
Palantirが提供する言語と埋め込みモデルのセットが、変換と同様にCode WorkspacesのJupyter®ノートブックで使用できるようになりました。この新機能により、ユーザーはPalantirが提供するモデルに対してインタラクティブに推論を実行してテキスト補完と埋め込みを生成し、完全なプロダクションパイプラインをデプロイする前に言語モデルを素早くプロトタイプ化できます。
Code Workspacesで言語モデルを使用する
Modelsビューを使用して、ノートブックの作成者は簡単にPalantirが提供するモデルをユーザーのコードワークスペースにインポートし、palantir_models Python SDKを使用してそれらのモデルのバインディングにアクセスできます。
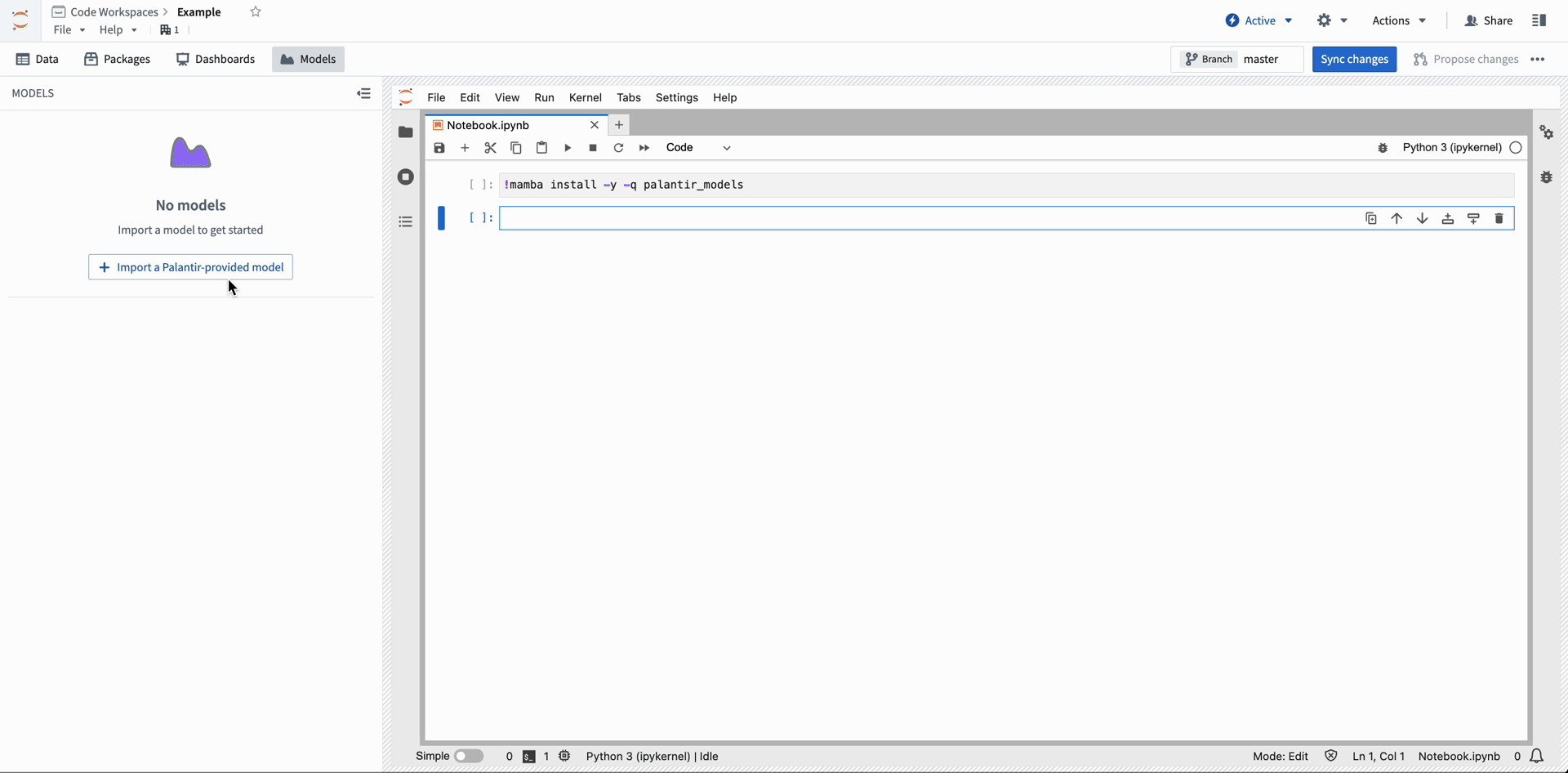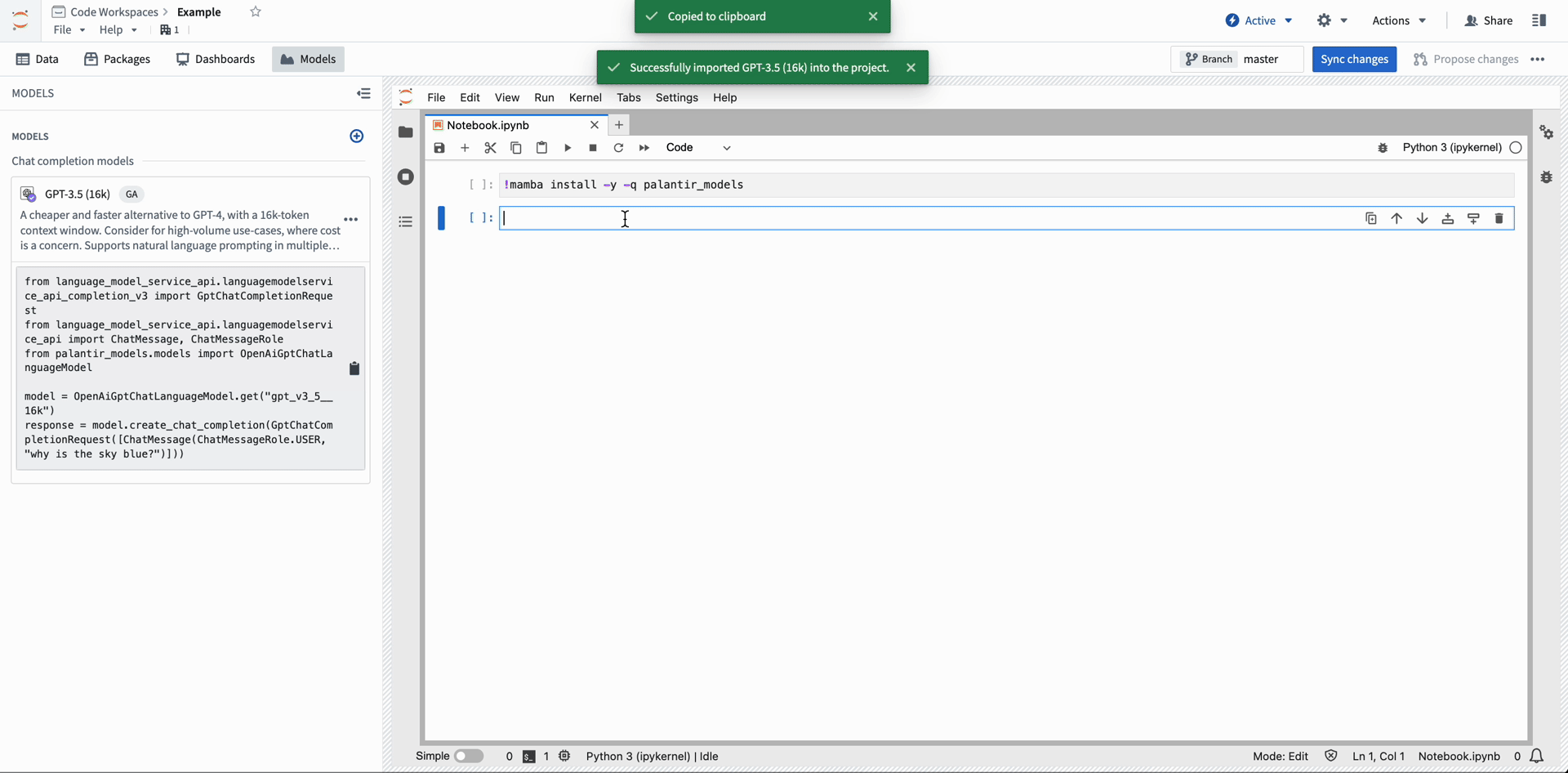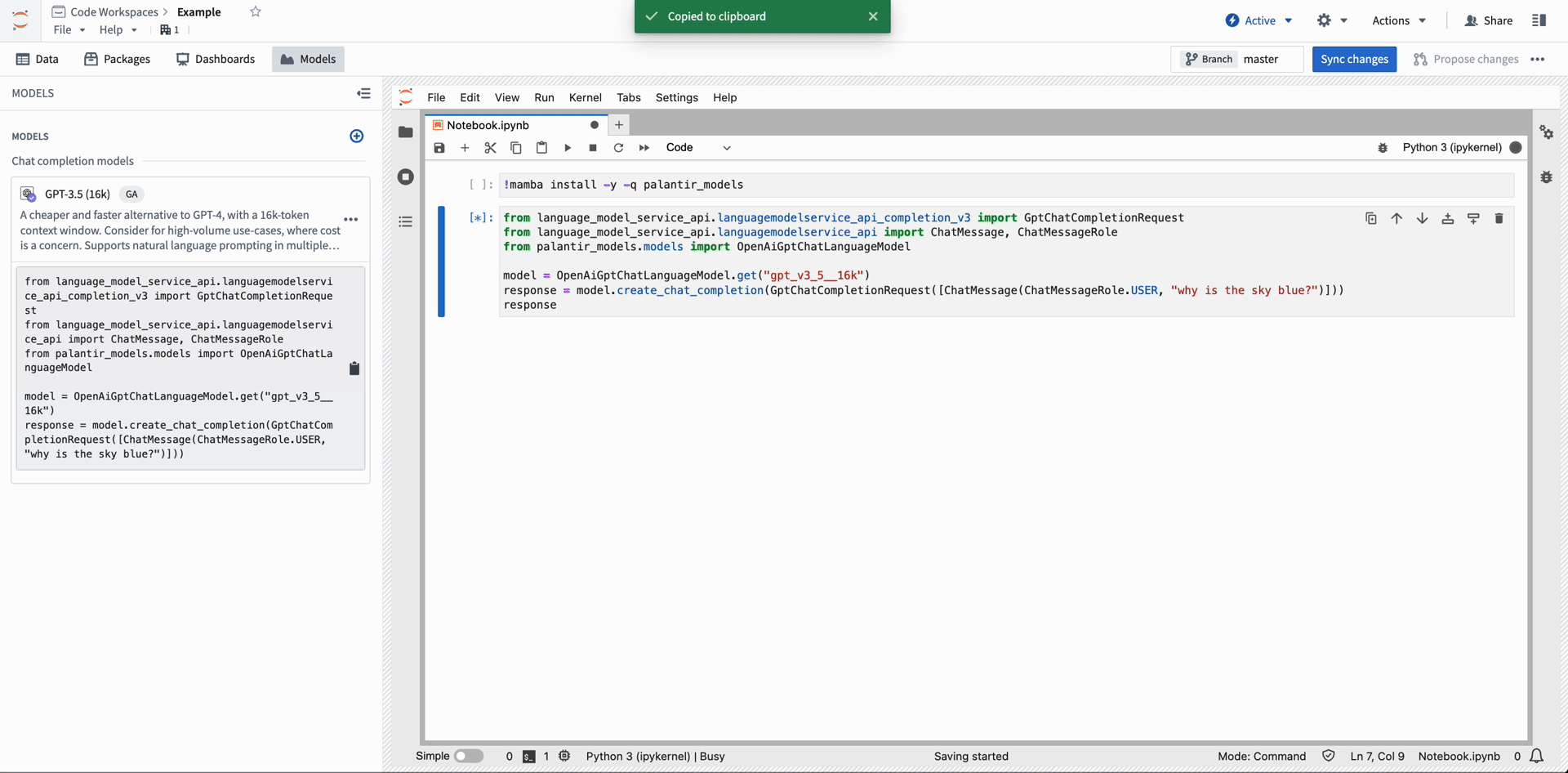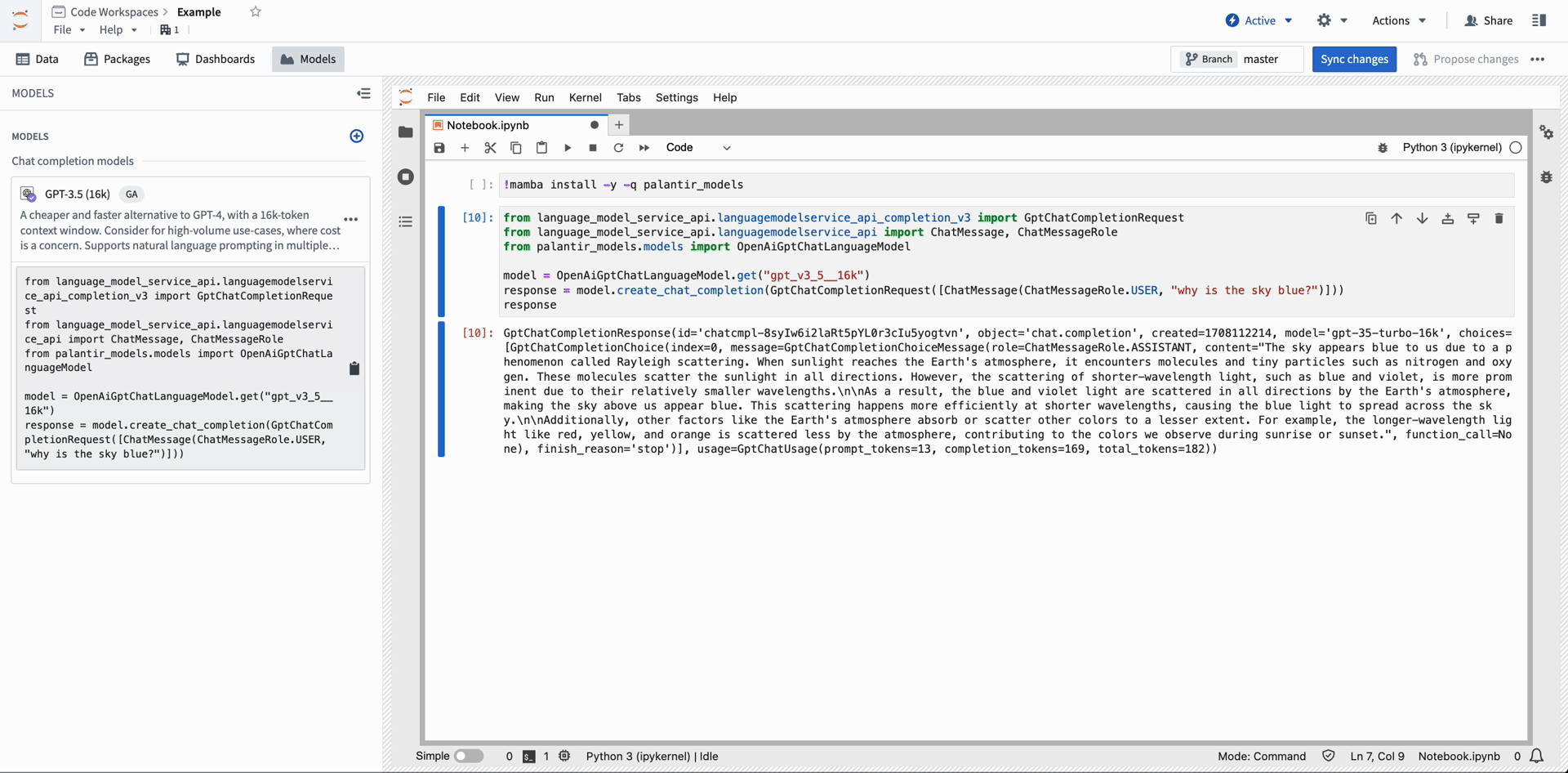
Import Palantir-provided models into Code Workspace from the Models menu.
ノートブックセルの例
以下のコードスニペットは、開発者がOpen AI's GPT-4(外部)をノートブックで使用する方法を示しています。モデルをCode Workspaceにインポートした後、推論を実行するために提供されたスニペットをセルにコピーして貼り付けます。
# language_model_service_apiから必要なクラスをインポートします
from language_model_service_api.languagemodelservice_api_completion_v3 import GptChatCompletionRequest
from language_model_service_api.languagemodelservice_api import ChatMessage, ChatMessageRole
# palantir_modelsからOpenAiGptChatLanguageModelをインポートします
from palantir_models.models import OpenAiGptChatLanguageModel
# "gpt_v4"という名前のモデルを取得します
model = OpenAiGptChatLanguageModel.get("gpt_v4")
# "why is the sky blue?"というユーザーメッセージでチャットの完成を作成します
response = model.create_chat_completion(GptChatCompletionRequest([ChatMessage(ChatMessageRole.USER, "why is the sky blue?")]))
# 応答から最初の選択肢のメッセージコンテンツを取得します
response.choices[0].message.content
Palantir が提供するモデルの使用方法についての詳細は、Jupyter® ノートブック内の Palantir 提供モデルに関するドキュメントを参照してください。
Jupyter®、JupyterLab®、および Jupyter® ロゴは NumFOCUS の商標または登録商標です。 参照されているすべてのサードパーティの商標(ロゴやアイコンを含む)は、それぞれの所有者の財産です。提携または承認を意味するものではありません。
2025 年 10 月 31 日の削除に先立ち、foundry_ml Python ライブラリを palantir_models ライブラリに置き換えて廃止予定
公開日: 2024-02-22
本日より、Python ライブラリ foundry_ml は、サンセット期間が開始されました。foundry_ml ライブラリは、2025 年 10 月 31 日に廃止予定となり、Python 3.9 の予定された廃止と一致します。代わりに、プラットフォーム内でモデルの開発、テスト、および提供に palantir_models フレームワークを使用することをお勧めします。
palantir_models フレームワークとは何ですか?
palantir_models フレームワークは、Foundry ワークフロー用にモデルをカスタマイズするためのはるかに柔軟な方法を提供し、以下を含みます:
- 幅広いモデルと推論モードを簡単にサポートするカスタムシリアライゼーション、API、および推論ロジック
- マルチ入力およびマルチ出力モデル
- 即時デプロイ用のPython 依存関係の自動バンドル
- Foundry でのモデル評価と推論用の外部ホストモデルのファーストクラスラッピング
- 非常に大きなまたは非常にカスタムなモデリングフレームワークを有効にするコンテナを利用したモデル
- モデル推論のためのメディアセットへの直接アクセス
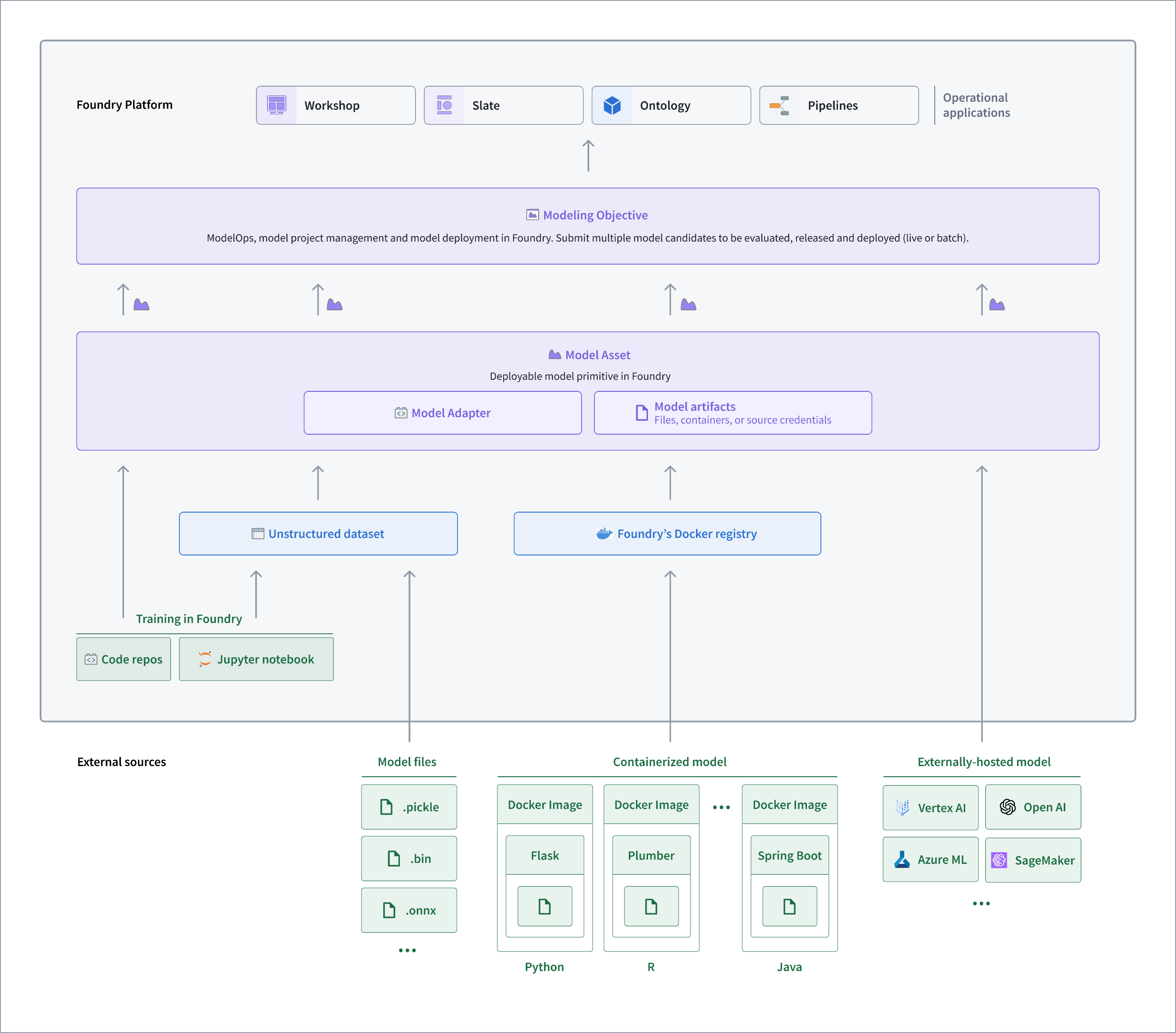
Foundry での palantir_models の使用方法のアーキテクチャダイアグラム。
foundry_ml で開発された多くのモデルは、Code Repositories の Model Training テンプレートとドキュメントに記載された例のモデルアダプターのいずれかを使用して、最小限の追加コードで palantir_models に移行できます。
- Code Repositories で scikit-learn を使用してバイナリ分類モデルをトレーニングする
- 例: コンテナモデルアダプターの実装
- 例: Amazon SageMaker モデルの統合
ただし、他のモデルでは palantir_models フレームワークへの手動移行が必要になる場合があります。詳細については、以下のコンテンツを確認してください。
palantir_models に移行する方法は?
2025 年 10 月 31 日までに、foundry_ml でトレーニングされたモデルは、palantir_models フレームワークを使用するように更新する必要があります。同様に、foundry_ml で開発されたモデルは、モデリング目的、Python 変換、またはモデリング目的のデプロイでサポートされません。palantir_models で新しいモデルを構築することによる移行に関するガイダンスは、Code Repositories でモデルをトレーニングする方法を確認してください。
リマインダーとして、Palantir は、2024 年 10 月に影響を受けるチームに通知するUpgrade Assistant 介入キャンペーンを開始します。palantir_models フレームワークへのワークフローの移行に関する懸念がある場合は、Palantir サポートにお問い合わせください。
Automate AIP Logic インテグレーションと手動実行機能を紹介 [GA]
公開日: 2024-02-20
Foundry Logic 関数は、オートメーションに対応しており、オントロジー編集を自動的に適用するか、ユーザーのレビューを待機することができます。これらの自動化は、既存のオブジェクトや新しいオブジェクトが作成されたときにトリガーすることができます。この機能により、AIP Logic 関数を利用したアクション(例:オントロジー編集)を最大 100k のオブジェクトに自動的に適用できます。
どのように始めればよいですか?
AIP Logic ダッシュボードから新しい自動化を作成できます。右側のメニューにある Automations オプションを選択します。このオプションを選択すると、ロジックの指示に基づいて自動化フローが事前に入力された新しいビューが開きます。条件は、オブジェクトセットを監視し、新しいオブジェクトが追加されるたびに、または既存のオブジェクトがある場合に AIP Logic 関数の効果をトリガーします。
また、以下の画像のように、Automate ユーザーインターフェースから直接自動化を作成することもできます。
右側のメニューにある Automation アイコンに移動して、自動化を作成します。
Automate の手動実行を使用して、既存のオブジェクトのセットに対して効果を実行する
Automate は、既存のオブジェクトセットに対して効果(アクションや AIP Logic 関数など)を実行し、通知をトリガーする機能もサポートしています。この機能は、既存のオブジェクトのバッチに対して AIP Logic 関数を自動的に実行して、オントロジー編集提案を生成するか、オントロジー編集を直接行う場合に役立ちます。
効果をどのように設定しますか?
自動化を作成した後、左側のメニューから Execute を選択します。次に、効果を即時に実行するオブジェクトを定義します。オブジェクトセット内のオブジェクトタイプは、自動化の設定時に使用されたオブジェクトセットと一致している必要があります。最初に、希望するバッチサイズを設定し、Execute を選択します。最大 100k のオブジェクトを含むオブジェクトセットで自動化を実行できます。スケジュールされたジョブが表示され、既存のバッチの進行状況の詳細を表示できます。
新しいオブジェクトに対して効果が実行されないようにするには、画面の右上にあるドロップダウンメニューから Mute オプションを選択して、自動化を無効化する必要があります。
新しいオブジェクトに対して自動化の効果が実行されないようにするには、ドロップダウンメニューから自動化をミュートします。
自動化の設定方法についての詳細は、Automate ドキュメントを参照してください。
Quiver ダッシュボード用の Foundry DevOps サポートを紹介 [Beta]
公開日: 2024-02-20
Foundry DevOps と Marketplace は、Foundry で構築されたデータバックのワークフローのパッケージを迅速に開発およびデプロイするためのツールです。今回、Quiver ダッシュボード に対する初期サポートを発表できることをうれしく思います。これは 2 月中旬までにすべてのエンロールメントで利用できます。
オブジェクトアナリティクスカード、オブジェクトベースのビジュアライゼーション、変換テーブルを使用したダッシュボードは、現在 Foundry DevOps を介して Marketplace 製品としてパッケージ化およびデプロイできます。さらに、ダッシュボードは他のコンテンツと一緒にパッケージ化できます。例えば、Workshop モジュールと埋め込まれた Quiver ダッシュボードは、一緒にパッケージ化できます。
ダッシュボードのパッケージ化方法
ダッシュボードの設定ペインの右側から、Marketplace テンプレート化オプションを有効に選択します。次に、ヘッダーで利用可能な Run Validation オプションを使用して、Marketplace テンプレート化の問題がある場合に特定します。
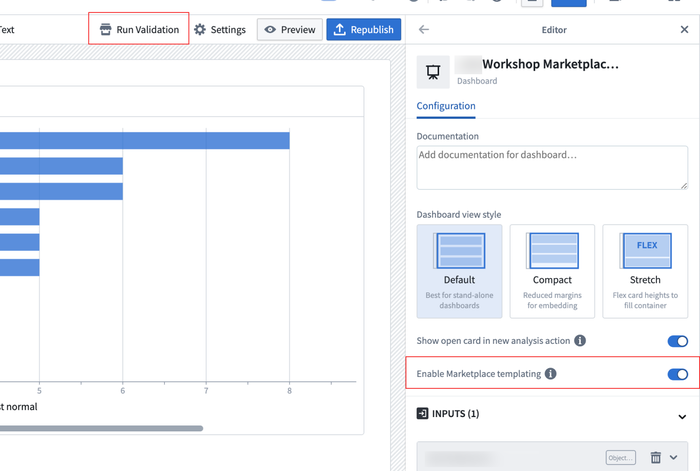
Workshop での Marketplace テンプレート化とテンプレート検証を有効にするオプション。
バリデーターがエラーを表示しない場合、ダッシュボードの Publish または Republish オプションは、新しいまたは既存の Marketplace 製品で使用される Marketplace 対応バージョンのダッシュボードを保存します。
ダッシュボードの履歴を表示する
Analysis History ダイアログのダッシュボードセクションでは、パッケージ化が検証されたダッシュボードのバージョンも表示されます。
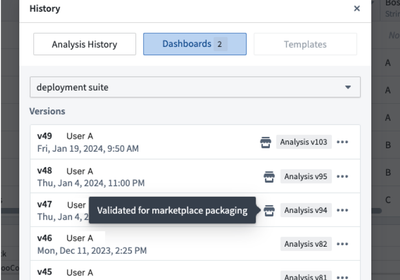
ダッシュボードの履歴は、Marketplace パッケージ化に検証されたバージョンを示します。
開発ロードマップに何がありますか?
サポートされるカードの数を積極的に拡大しており、近い将来には時系列とマテリアリゼーションカードを追加することを目指しています。さらに、インストールされたダッシュボードから新しい Quiver 分析を作成する方法を提供する予定です。
詳細については、[Beta] ドキュメントで Quiver ダッシュボードを Marketplace 製品に追加する方法を参照してください。
Slate のヘルスチェックダイアログの紹介 [GA]
公開日: 2024-02-20
新しい Slate Health Check ダイアログを使用すると、アプリケーションビルダーは、失敗したクエリや関数をすばやく特定し解決することができ、ウィジェット内の古いデータや誤ったデータを防止できます。以前はエラーがクエリまたは関数パネルでのみ表示されていたため、気付かれないことがありましたが、この新しい機能では、Slate のクエリと関数からのすべてのエラーと警告をまとめて、エラーを発見しやすくなり、他のアプリケーションコンポーネントへの影響をよりよく理解できるようにします。
すぐに問題を発見する
Slate アプリケーションが編集モードで開かれると、アプリケーションはすべてのクエリと関数の正常なランタイムをロード時に自動的にチェックします。ただし、デフォルトのアプリケーション状態では条件が満たされない場合、条件付きクエリは実行されないことに注意してください。検出されたエラーや警告は、ページの上部にあるアクションバーに表示されます。

Slate アプリケーション内のエラーや警告は、アクションバーに表示されます。
問題のアイコンを選択して Health Check ダイアログを開きます。ここから、キャンバス上または依存関係グラフビューのクエリまたは関数に直接ジャンプして、問題の原因を調査できます。
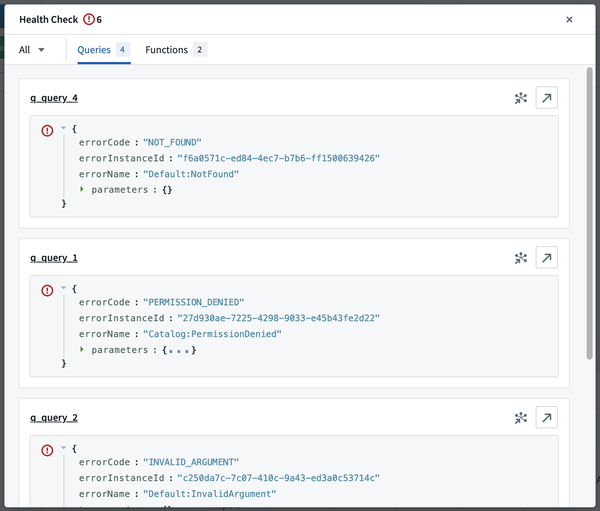
問題を起こしているクエリまたは関数に直接ジャンプします。
これにより、新しい Health Check ダイアログは、特に数百のクエリを持つ大規模なアプリケーションの保守性が向上します。この強化により、問題の発見と解決が容易になり、より洗練されたユーザーエクスペリエンスが実現されます。
詳細については、Slate アプリケーションのデバッグのドキュメントを確認してください。
Claude、Llama2、および他の Palantir がホストするオープンソースモデルを承認済みのエンロールメントで紹介
公開日: 2024-02-15
Palantir AIP は現在、Claude、Llama2、および Mistral などの Palantir がホストする LLM モデル をデフォルトでサポートしています。各エンロールメントで有効にされているデフォルトのモデルは異なる場合があり、適用可能な場合、より寛容なオープンソースライセンスの下でリリースされる代替モデルを利用できます。
新しいコントロールパネル機能が開発されており、2 月末までに利用可能になる予定です。これにより、条件を承認し、新しいモデルを有効にすることができます。
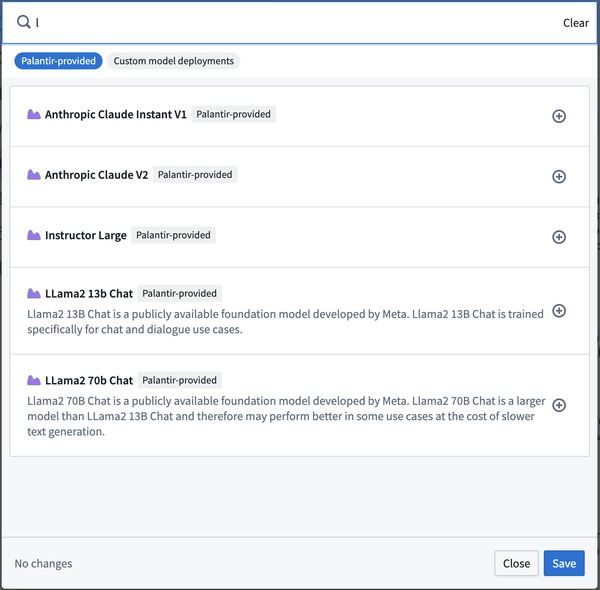
これらのモデルは、Functions と変換でサポートされています。
詳細については、Palantir が提供する大規模言語モデルを確認してください。
Vega-Lite プロット選択の導入
公開日:2024-02-13
Quiver は、Vega-Lite(外部)または Vega(外部)ライブラリを使用して、完全にカスタマイズ可能なビジュアライゼーションを作成できるようにするツールです。これまで、Vegaプロットは選択をサポートしていませんでしたが、これはインタラクティブなビジュアライゼーションを構築するための非常に強力で高度にカスタマイズ可能な機能です。 このたび、Vega-Liteプロットを選択データを出力するように設定することができるようになりました。ユーザーは選択データを利用して、下流のカードをパラメータ化したり、ドリルダウンワークフローを構築したり、分析を続行したりできます。 Vega-Lite 選択では、次の2種類の選択を利用してチャートと対話できます。
- ポイント選択: 単一の点を選択するか、
Shift+clickで複数の点を選択します。 - インターバル選択: キャンバス上の範囲をドラッグして選択します。
選択パラメーターの定義
Vega-Lite の仕様にカスタム選択パラメーターを記述し、quiverDefaultClick または quiverDefaultBrush という名前で変換テーブルの出力に接続します。選択するエンコーディングフィールド(x、y、shape など)を定義します。
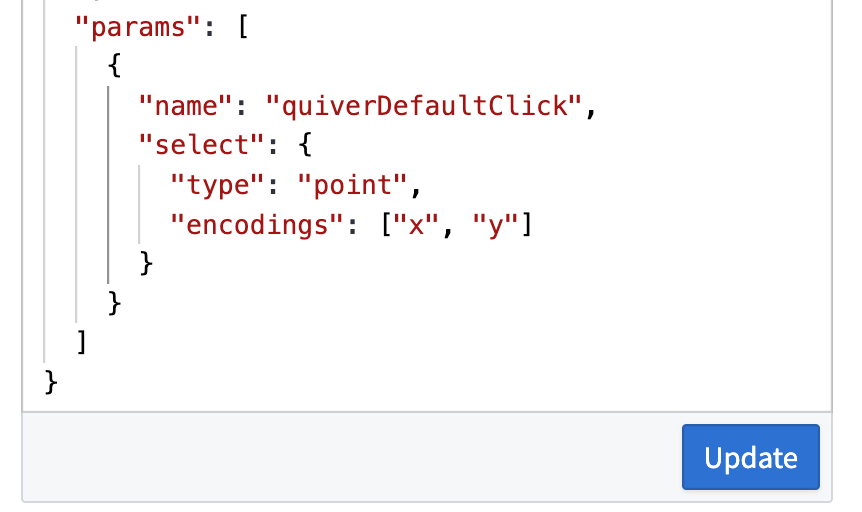
Vega-Lite 仕様にカスタム選択パラメーターを記述します。
選択データを変換テーブルとして出力する
ポイント選択は、フィールドと値のテーブルとして出力され、各列がフィールドに対応し、各行が選択されたポイントを表します。
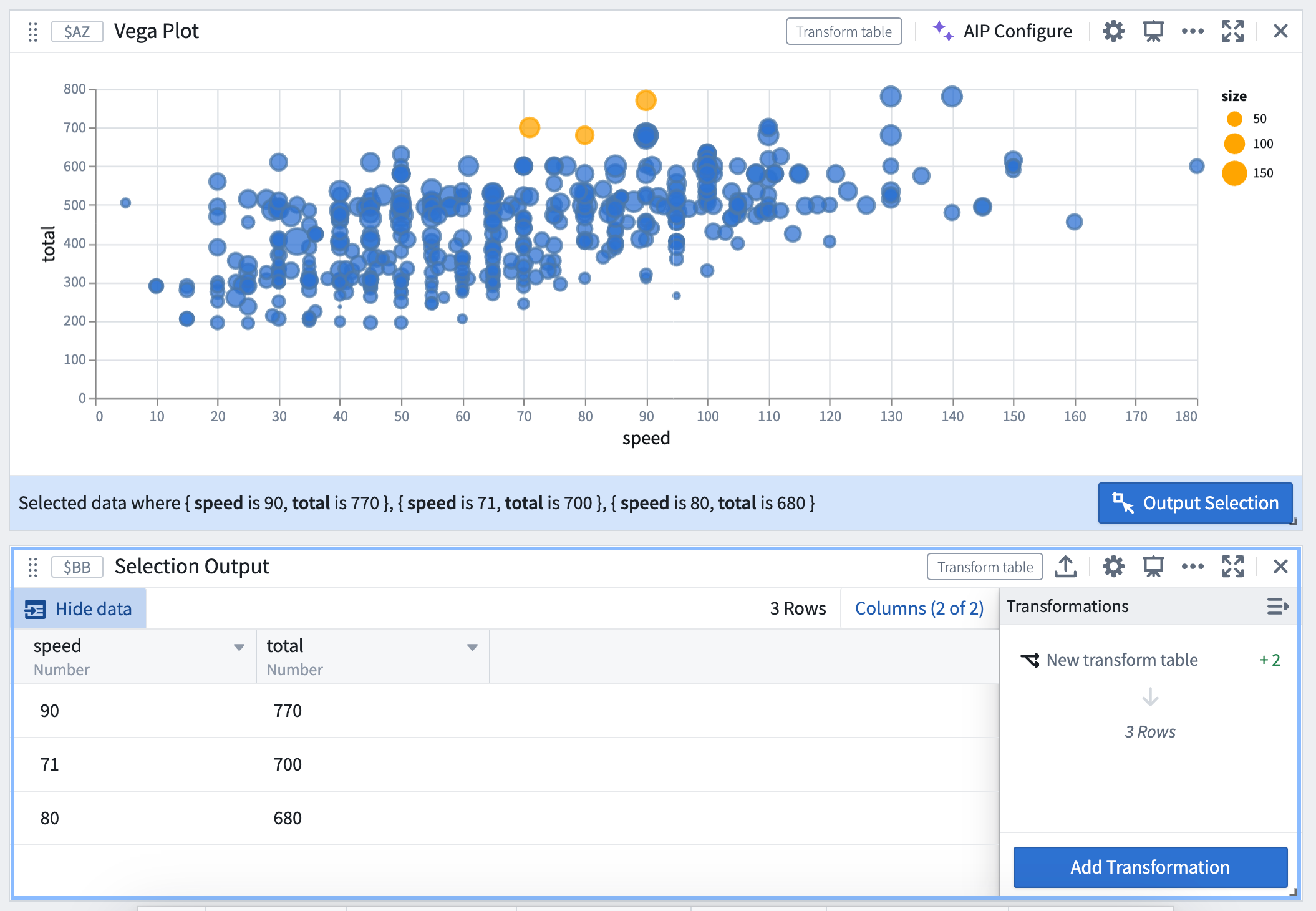
インターバル選択は、フィールドが連続の場合はインターバルの範囲として出力され、フィールドが離散の場合は値の配列として出力されます。
ドリルダウンワークフローの構築
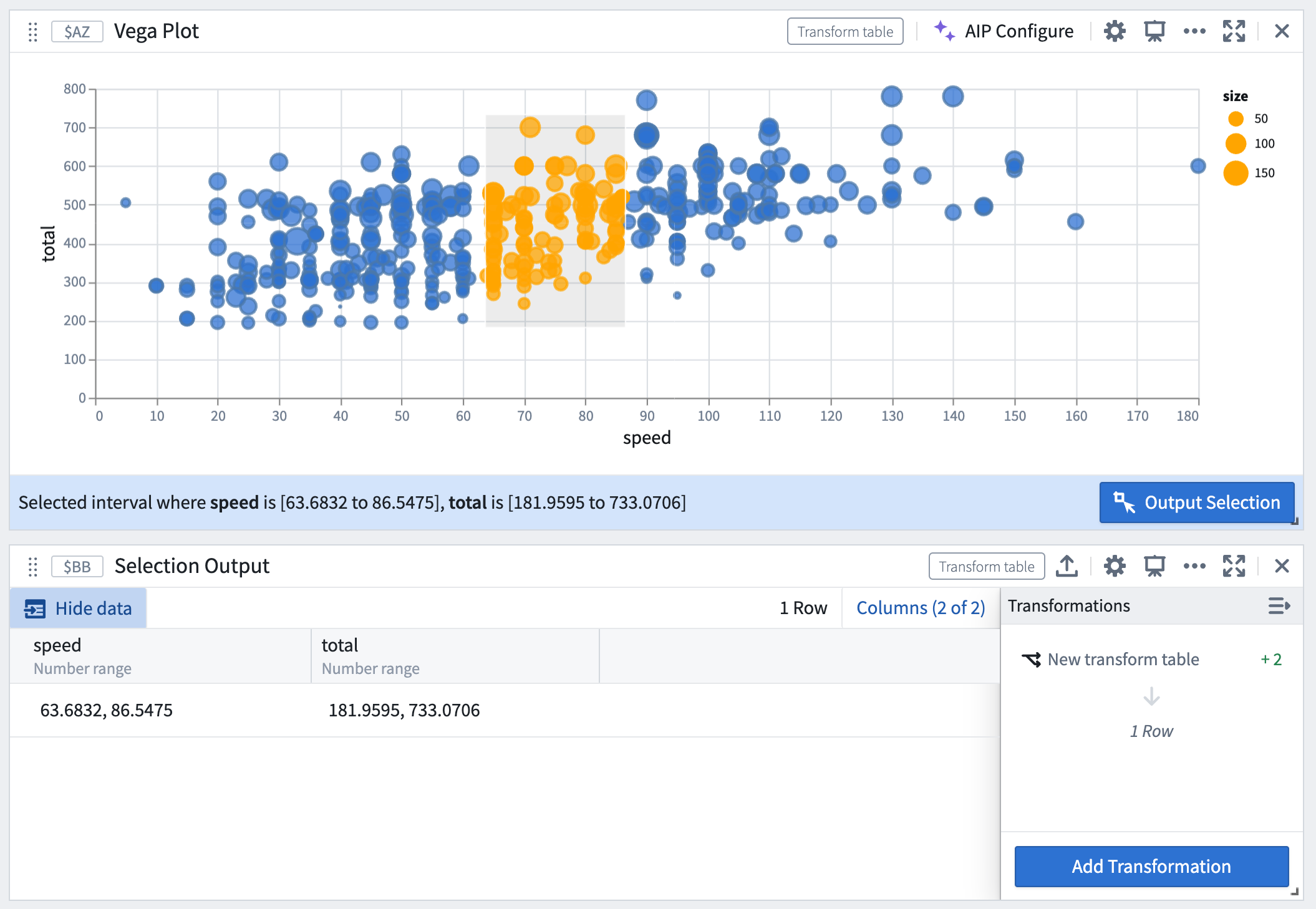
Vega-Lite プロットからの選択データは、チャート選択がフィルターとして機能し、ユーザーが選択されたデータのサブセットに基づいて上流の選択を解析を続行できるドリルダウンワークフローの構築に使用できます。
たとえば、以下の画像は、Vega プロットの選択が下流の変換テーブルにリアルタイムでフィルター処理されるワークフローを示しています。
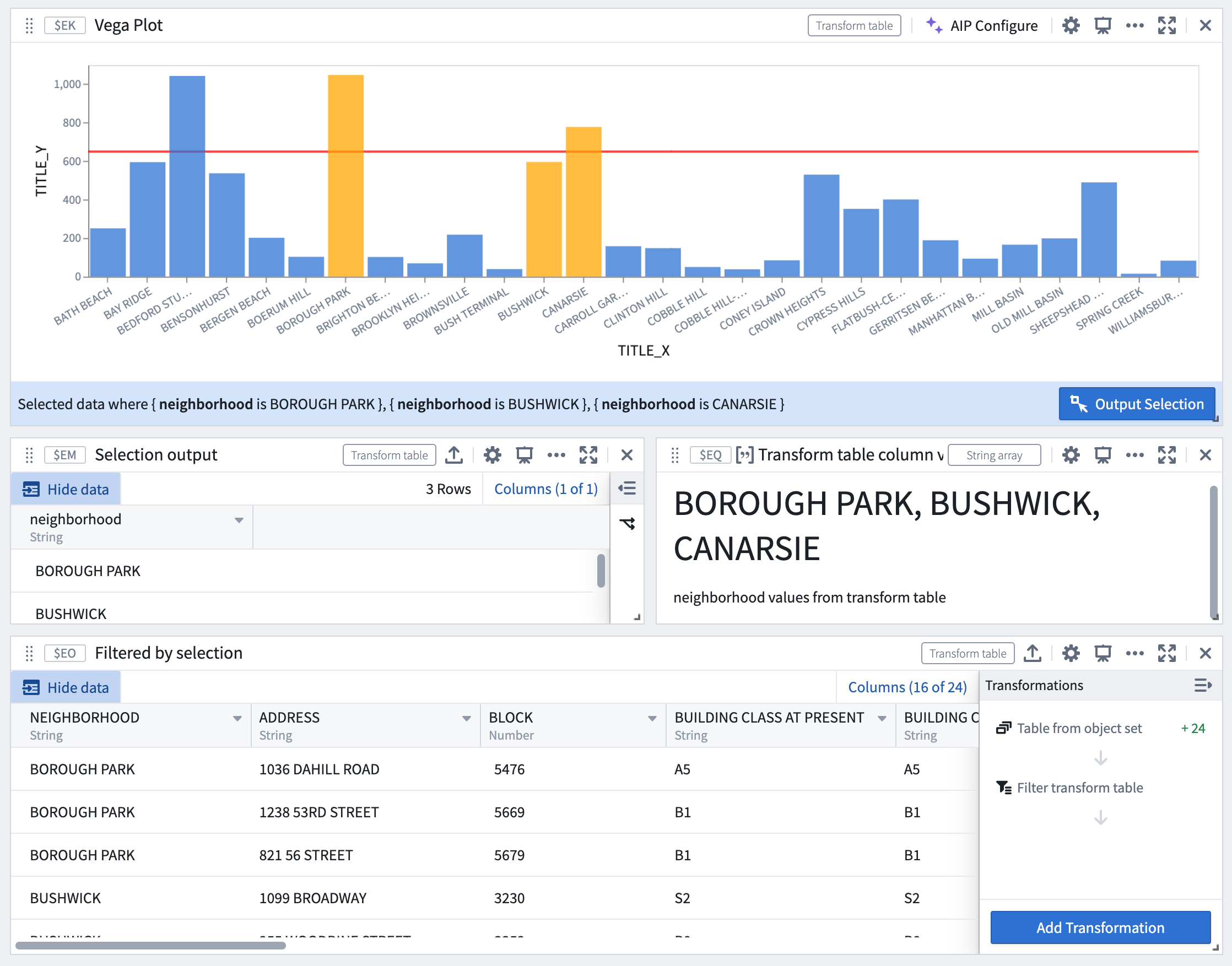
Vega プロットの選択がリアルタイムでフィルター処理される。
選択動作のカスタマイズ
選択パラメーターは、異なるフィールドで選択したり、異なるマウスイベントでトリガーされるようにカスタマイズすることもできます。
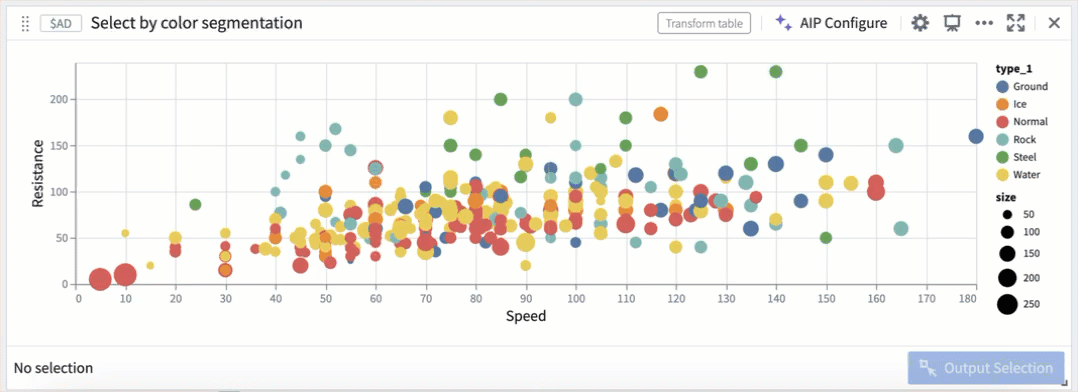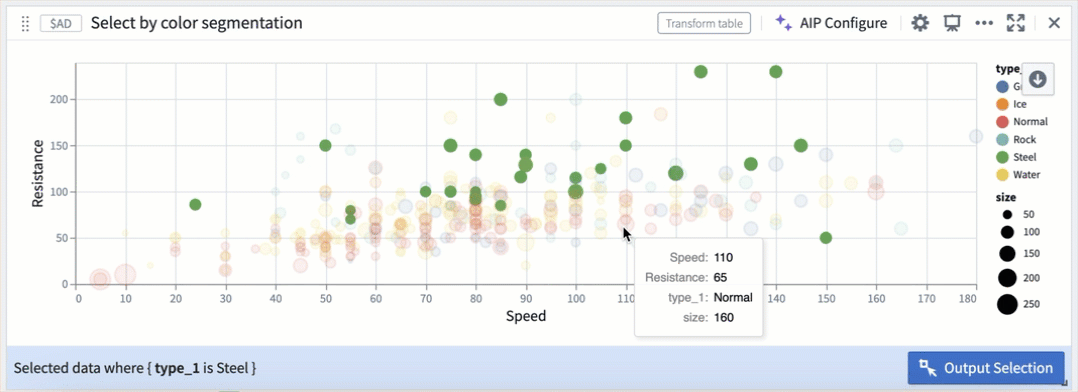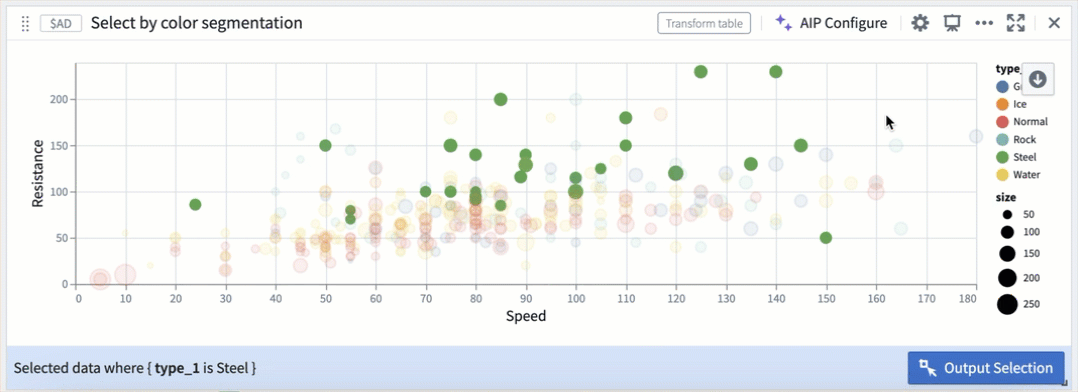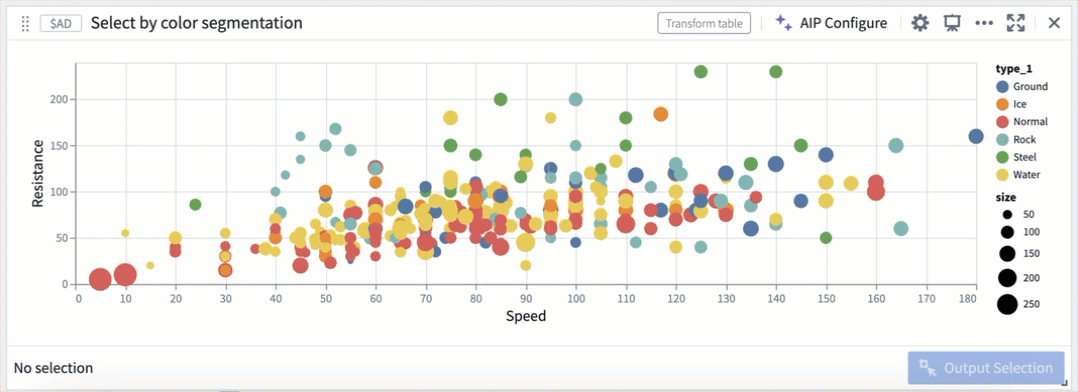
散布図内のカラーセグメントによる選択。
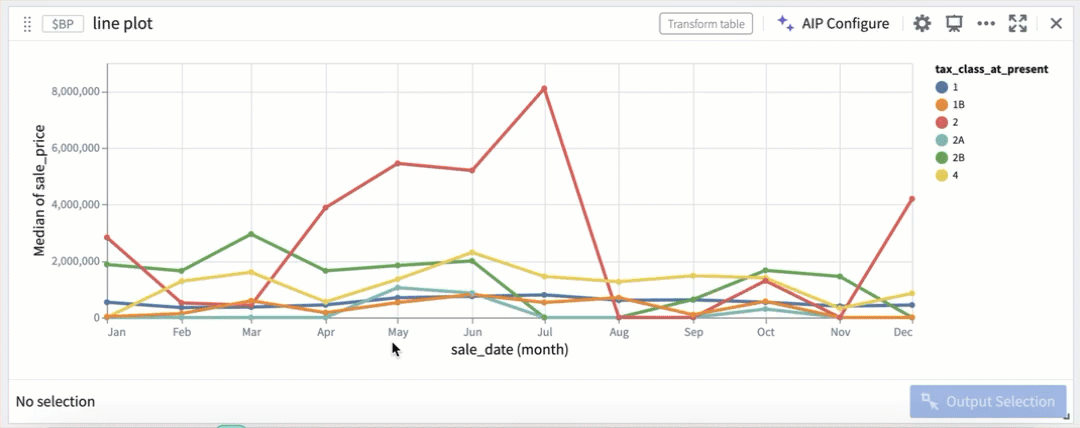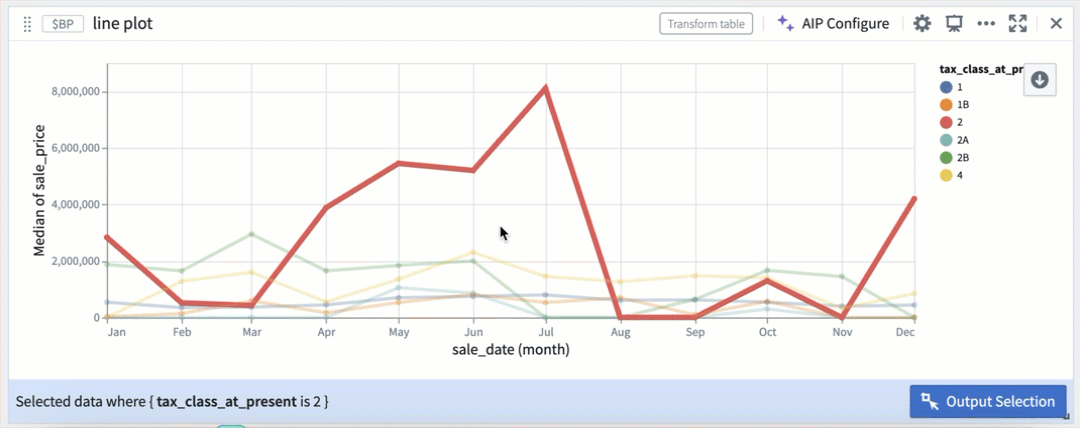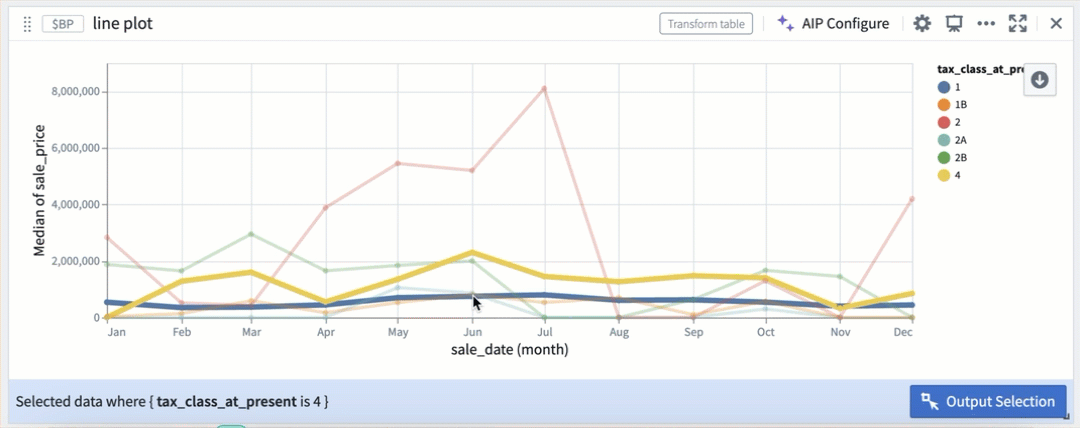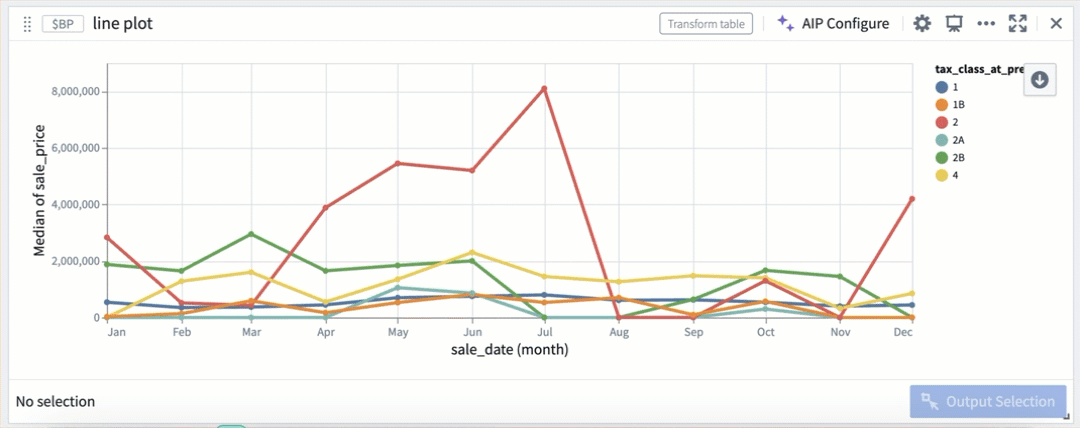
折れ線グラフ内のカラーセグメントによる選択。
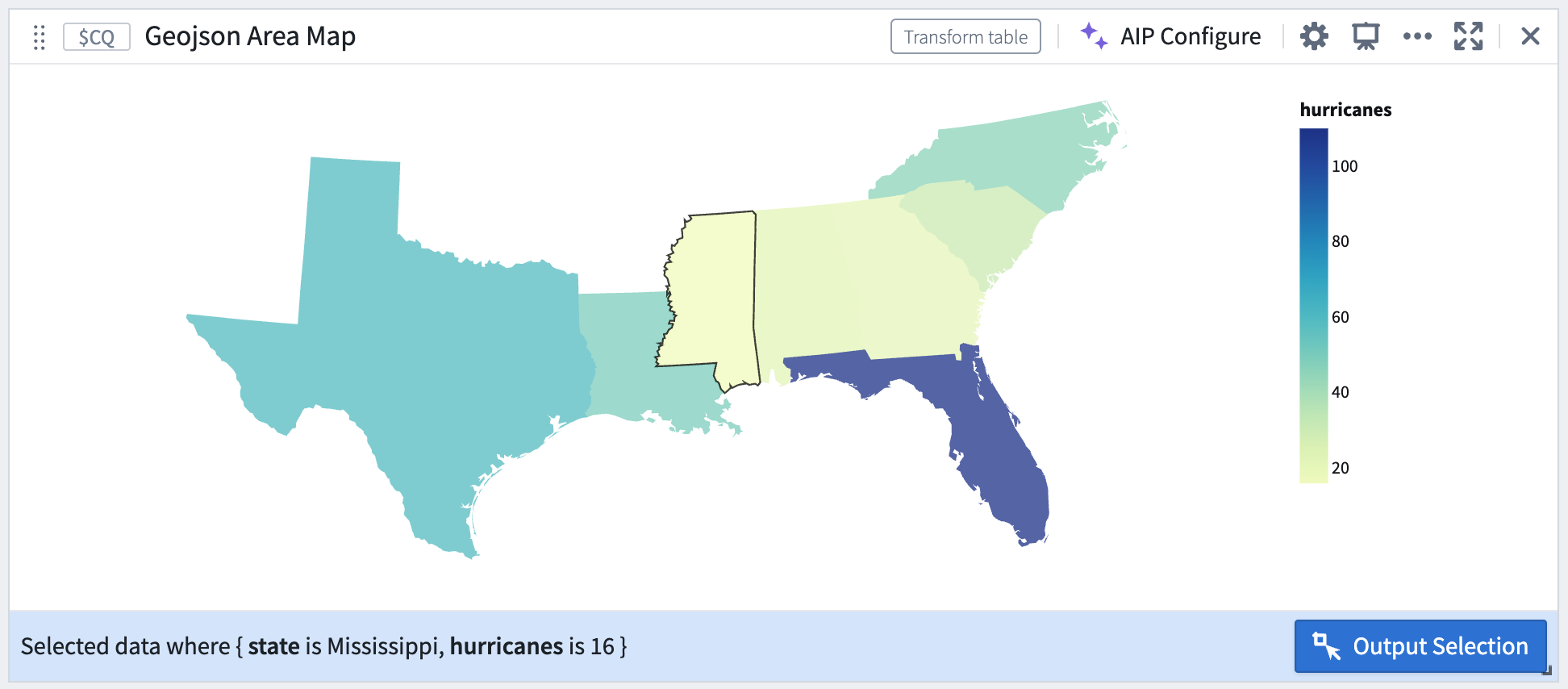
地理的エリアによる選択。
Quiver の Vega プロットの使用に関する詳細は、ドキュメント を参照してください。
機密データスキャナーの導入 [GA]
公開日:2024-02-08
機密データスキャナー(「SDS」、旧称「Foundry Inference」)は、Foundry 内のデータセット全体で機密データを発見し、保護するのに役立ちます。ガバナンスユーザーは、SDS を使用して、機密データのパターンを定義し、それらを識別し、一致するデータが発見されたときに実行されるアクションを自動化できます。また、ユーザーは、開始したスキャンを正確に追跡および監視するための更新されたインターフェースも利用できます。
機密データスキャナーは、Foundry エンロールメント全体で 2 月 19 日の週に一般に利用可能になります。
機密データスキャナーのワンタイムスキャンの概要。
機密データの発見と保護を自動化する
機密データスキャナー(SDS)は、Foundry 内の機密データを発見し、保護するための管理者向けツールです。機密データのスキャンの設定は簡単で、技術者および非技術者の両方が実行できます。まず、AIP 用の自然言語プロンプトを提供するか、正規表現を直接入力して、機密データのパターンを指定します。次に、パターンに一致するデータが見つかったときに Foundry が実行する自動アクションを設定します。
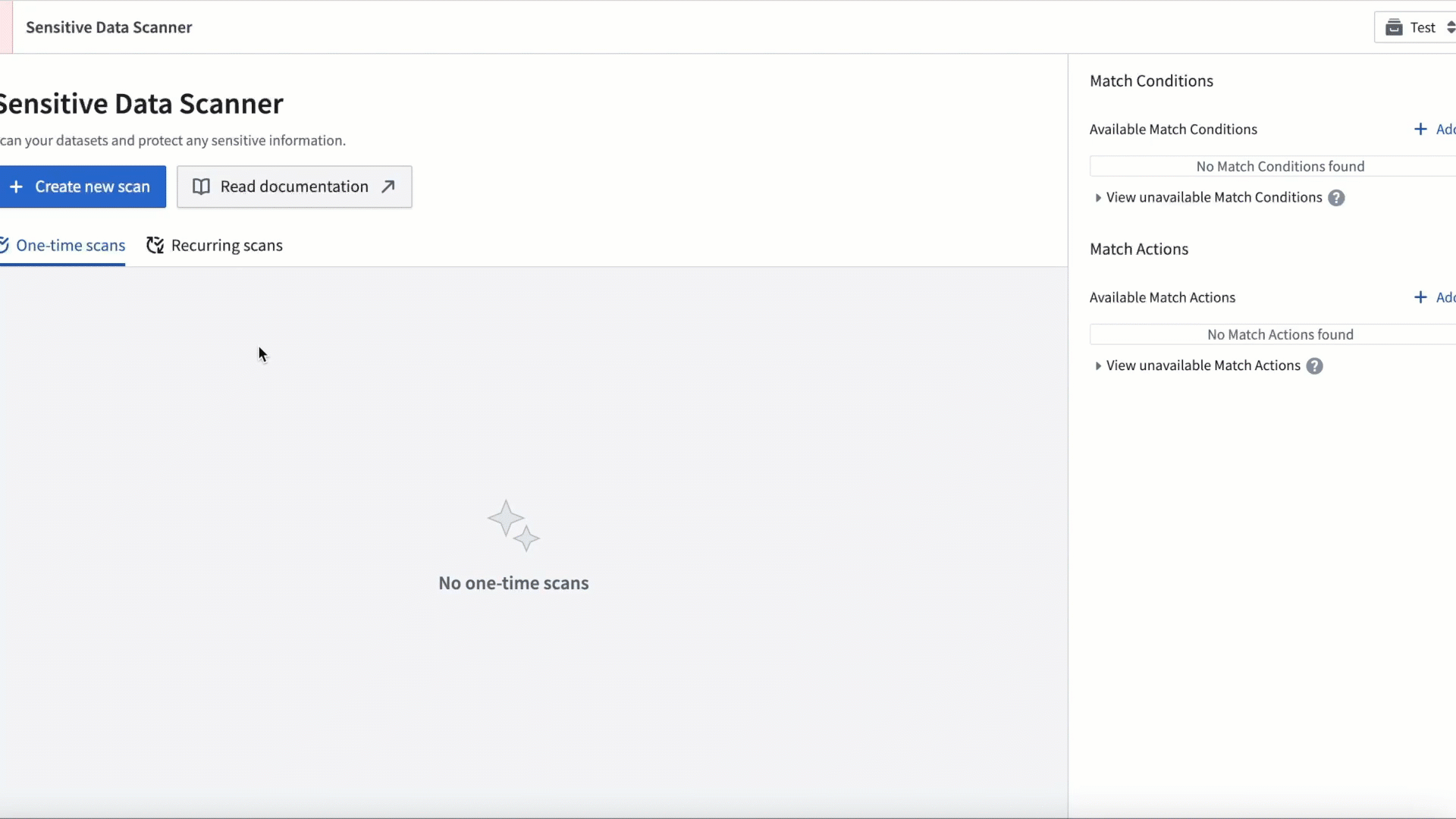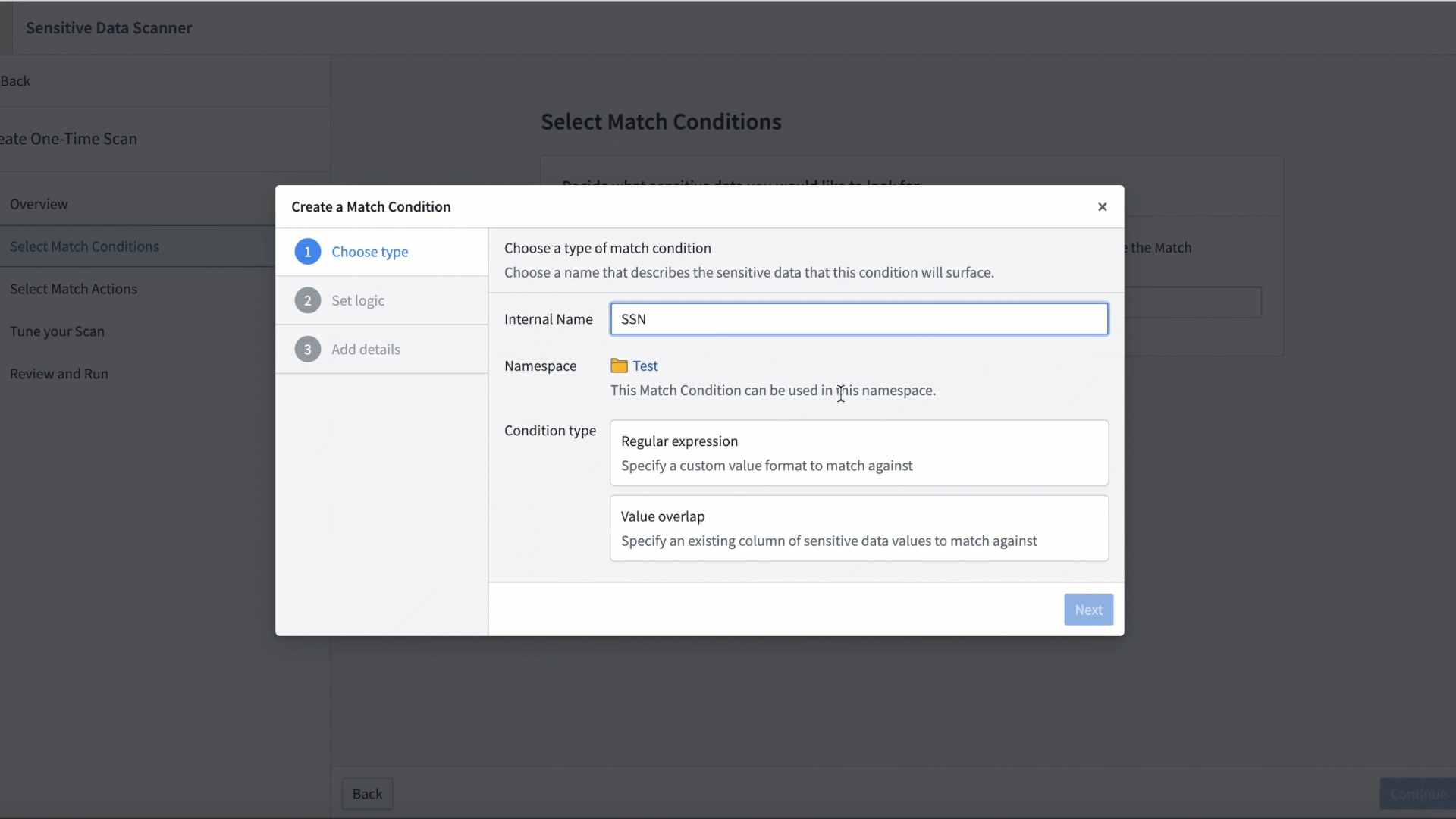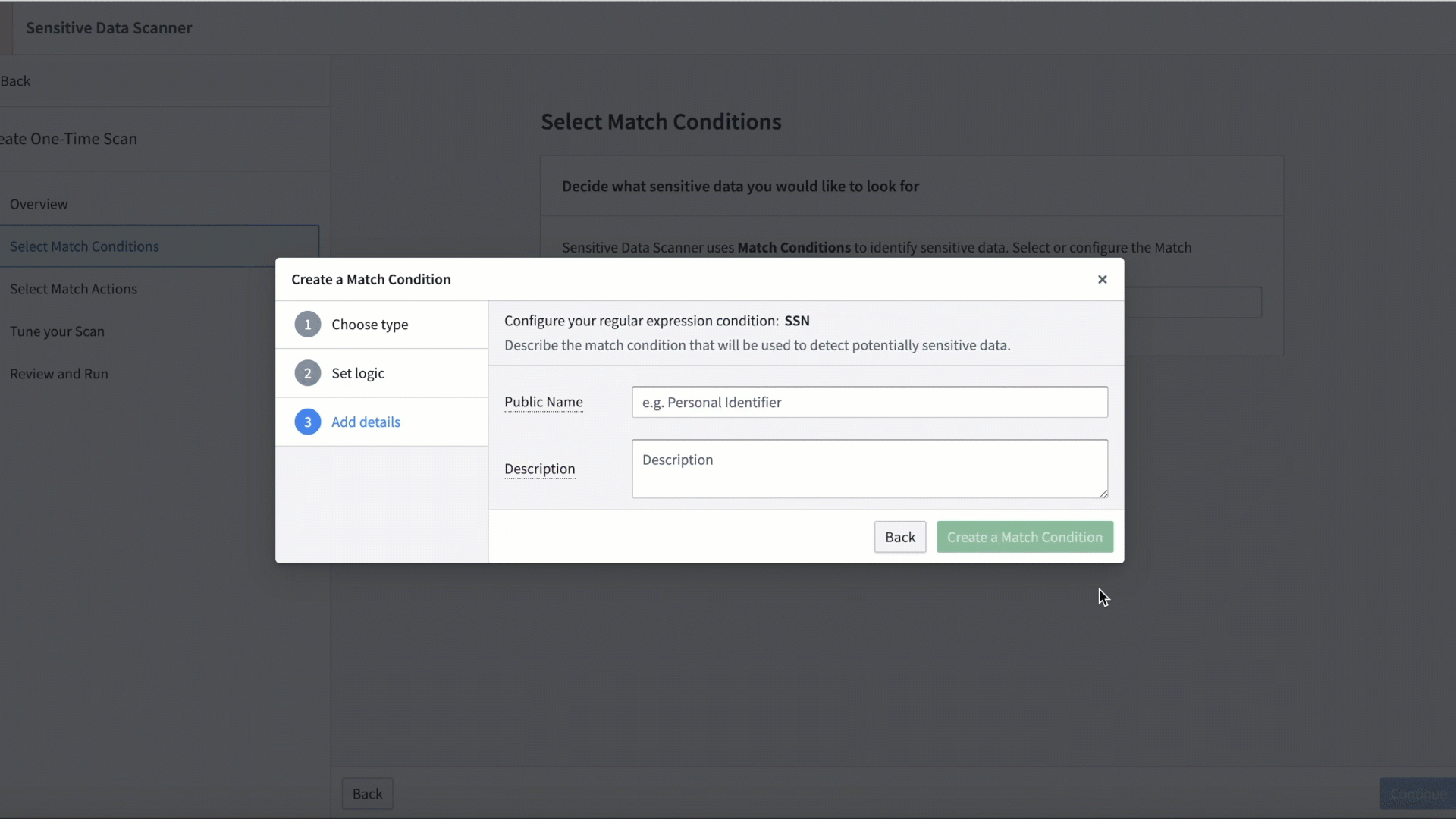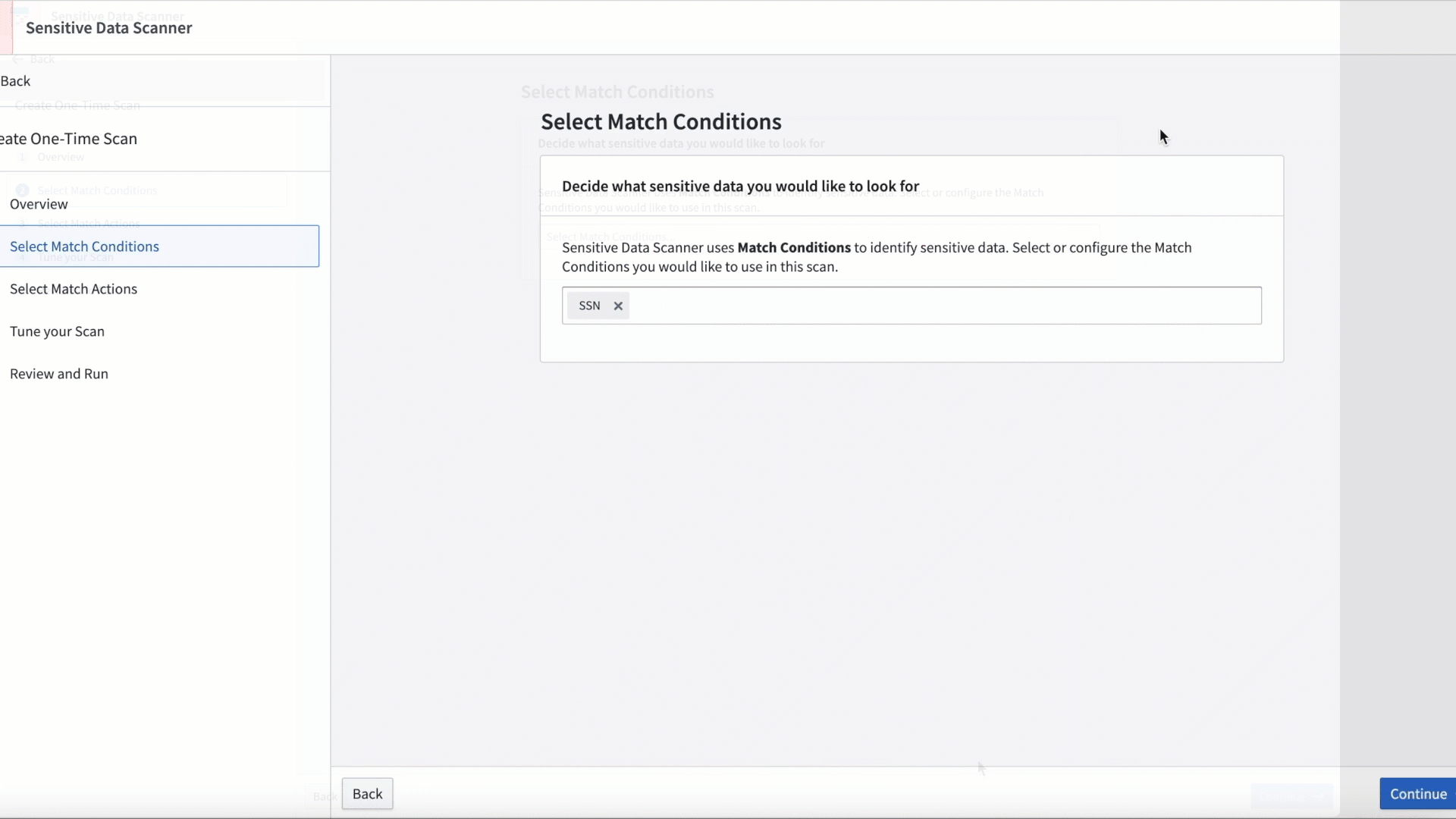
SDS マッチ条件の作成。
SDS は、アドホックなスキャンや、プラットフォームに新しいデータが追加されるたびに定期的に実行されるスケジュールされたスキャンで使用できます。
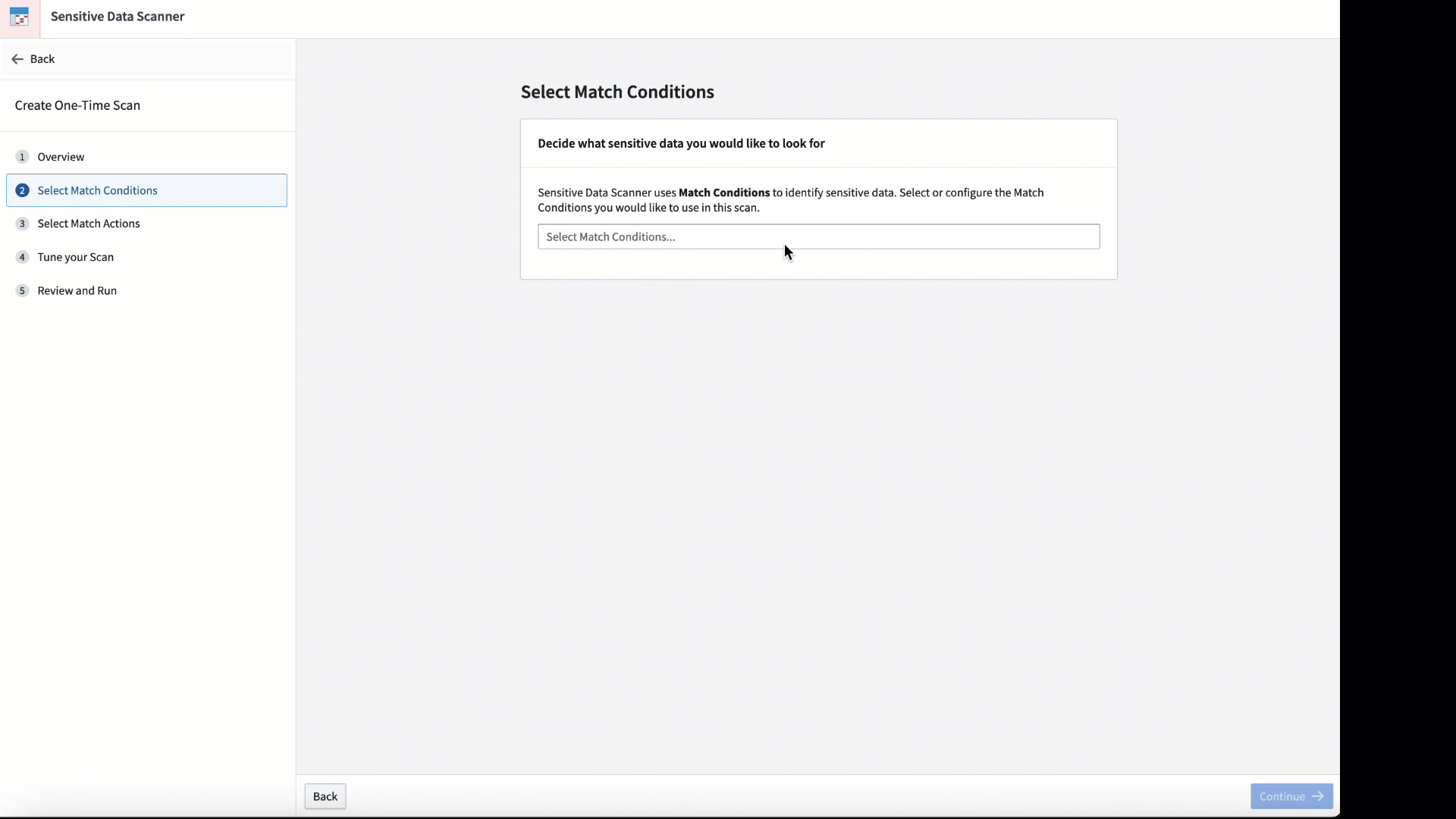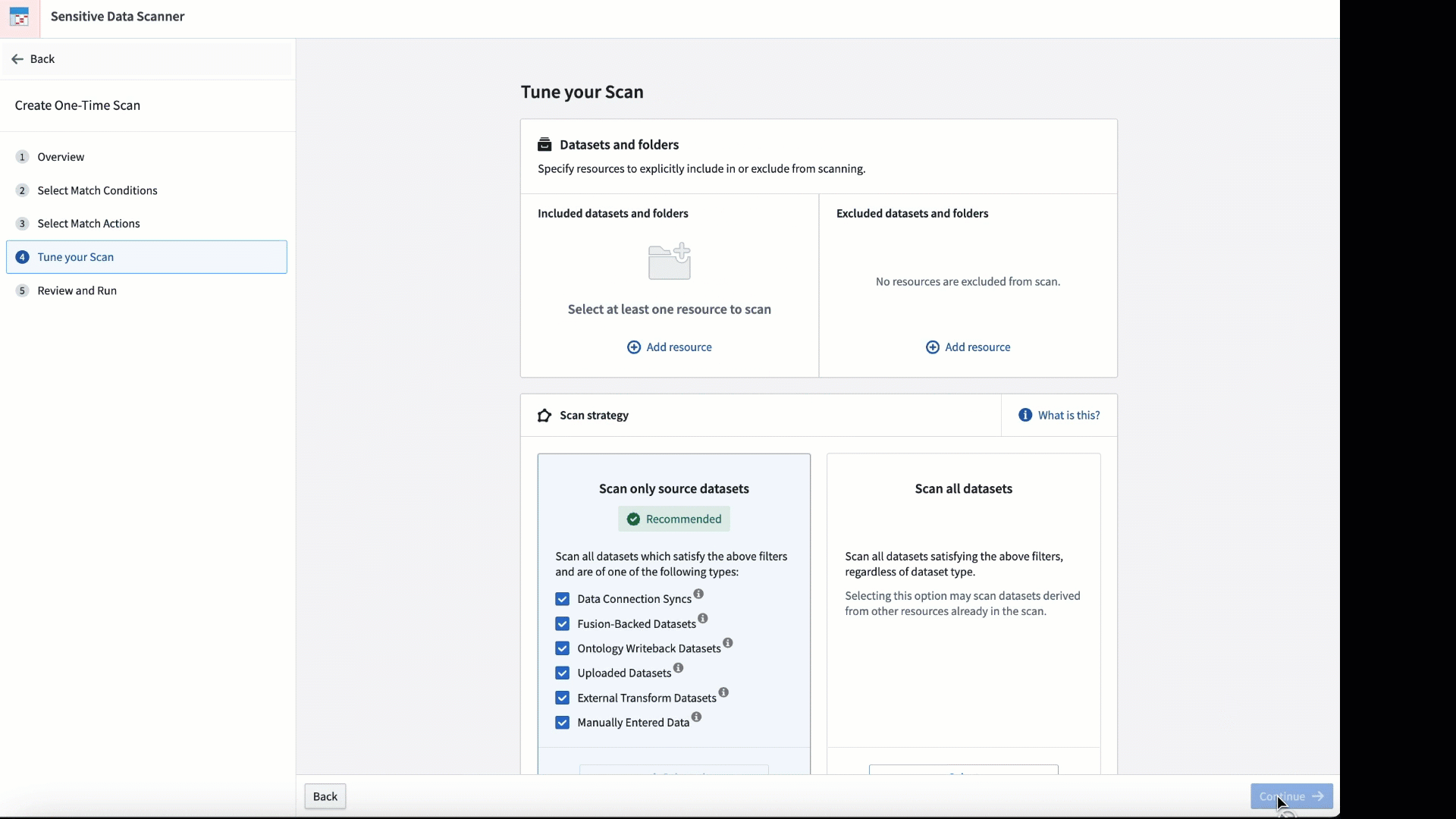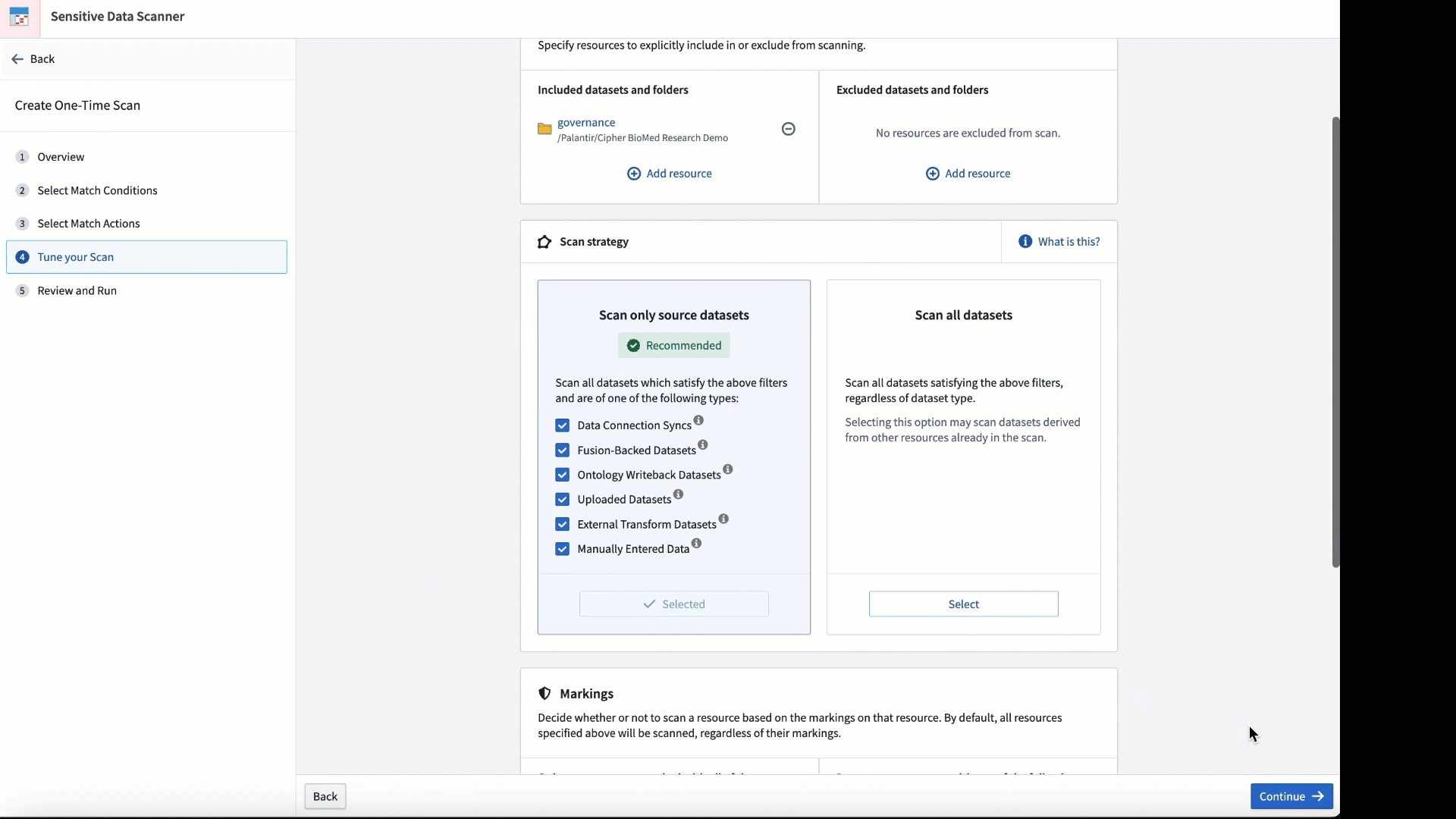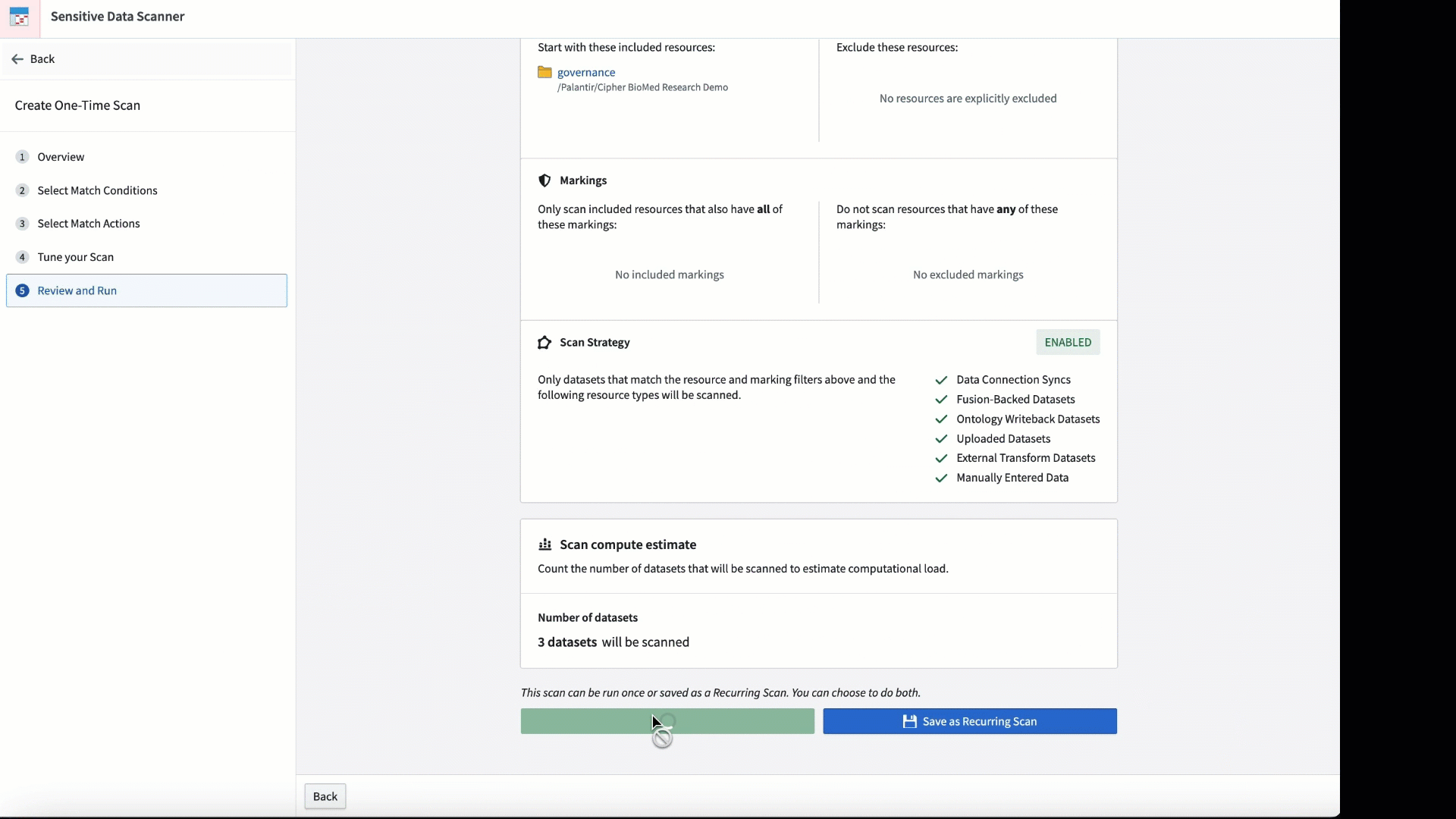
マッチ条件とスキャンの実施頻度を調整して、スキャンをカスタマイズします。
複数のアプリケーションで安心
機密データスキャナーは、データを保護するために使用できます。以下に、概念的な例をいくつか紹介します。
- 手動アップロードや Magritte インジェストを通じて、個人識別情報(PII)を含むデータを定期的に取り込む組織は、新しいデータセットにマーキングを設定するのを忘れることがあります。定期的な SDS スキャンを使用して、PII が大勢の不正なユーザーに漏れるのを防ぐことができます。
- 機密データを取り扱う組織のデータガバナンスチームは、SDS を使用して、適切なパラメーターセットを使用してデータセットの定期的なスキャンを実行し、高度に機密な情報をロックダウンできます。チームのメンバーは、スキャンのためのオーバーラップマッチ条件を作成し、最も機密性の高いデータが分析のために安全で制限されたままであることを確認できます。
- AIP を利用して LLM を用いた運用ワークフローを開発する組織は、SDS を適用して、OCR で抽出された文書からのテキストをオントロジーオブジェクトに統合する前に調べることができます。これにより、機密情報を LLM に送信するのを防ぐことができます。
詳細については、機密データスキャナーのドキュメントをご覧ください。
Developer Console での Web ホスティングの導入 [ベータ]
公開日:2024-02-08
Developer Console は間もなく、静的 Web サイトのホスティングをサポートする予定です。静的 Web サイトには、事前に定義された数のファイル(たとえば、HTML、CSS、JavaScript)が含まれており、これらのファイルは、保存されたままの状態でエンドユーザーのブラウザに直接ダウンロードされ、レンダリングされます。これまで、OSDK を使用して作成された静的 Web アプリケーションをホストするには、React(外部)などのフレームワークを使用した外部 Web ホスティングソリューションを使用する必要がありました。この新機能により、開発者は Foundry を使用して Web サイトを直接ホストおよび提供できるようになり、外部 Web ホスティングインフラストラクチャの必要性がなくなり、ワークフローが簡素化されます。
この機能は、Foundry 管理ドメイン全体でベータ機能として 2 月中旬までに利用可能になる予定であり、今年後半に一般提供される予定です。
Foundry で直接サイトをホストする
Developer Console での静的 Web サイトホスティングの設定は、いくつかの簡単な手順で完了できます。まず、左側のメニューで Website hosting を選択し、次に以下の手順を実行します。
- サイトにアプリケーションドメインを設定し、ユーザーがサイトにアクセスする URL を定義します。
- サイトを Foundry にアップロードします。
- アップロード結果をプレビューし、サイトに公開します。
また、設定ページから直接、Web サイトへのアクセスを設定したり、サイトに対して高度な Content Security Policy(CSP) 設定を設定することもできます。
Developer Console での静的 Web サイトホスティングのサポートが間もなく登場します。
Web サイトホスティングを設定できるのは誰ですか?
Developer Console の編集権限を持つユーザーやオーナーの役割を持つユーザーは、静的 Web サイトホスティングを設定できます。アプリケーションのサブドメインアドレスは、Enrollment Information Officer(EIO)によって承認される必要があります。承認リクエストは、Developer Console の設定内で管理でき、EIO は Control Panel を介して承認を行います。
開発ロードマップでは何が行われていますか?
顧客所有のドメインでの Web ホスティングを有効にする作業を行っています。また、CI/CD パイプラインからこの Web ホスティングサービスへのサイトデプロイを統合する API も積極的に開発されています。
Web サイトホスティングの設定について詳しくは、「Foundry 上での Ontology SDK アプリケーションのデプロイ(ベータ)」を参照してください。
Python コードリポジトリでの Code Assist 起動とチェックの大幅な高速化
公開日:2024-02-01
Python リポジトリの Code Assist とチェックは、Python 環境のキャッシュを共有するようになり、Code Assist 起動時の大幅なパフォーマンス向上と、より高速なチェック(CI)が実現されました。すべてのエンロールメントで利用可能なこの改善を利用するには、コードリポジトリをアップグレードしてください。
次のワークフローは、新しいパフォーマンス向上の対象となります。
-
チェックの実行: ユーザーがチェックをトリガーすると、環境が構築され、キャッシュされます。Code Assist の起動は、チェックによって公開されたキャッシュ環境を使用して、より高速に実行されます。
-
Code Assist の起動: Python 環境が作成され、キャッシュされます。これにより、Code Assist によって公開されたキャッシュ環境を使用して、チェックがより高速に実行されます。さらに、後続の Code Assist 起動も同じキャッシュを使用してパフォーマンスを最適化します。
以下の 2 つの例の時間グラフを参照してください。
- チェックキャッシュを使用した Code Assist 起動:
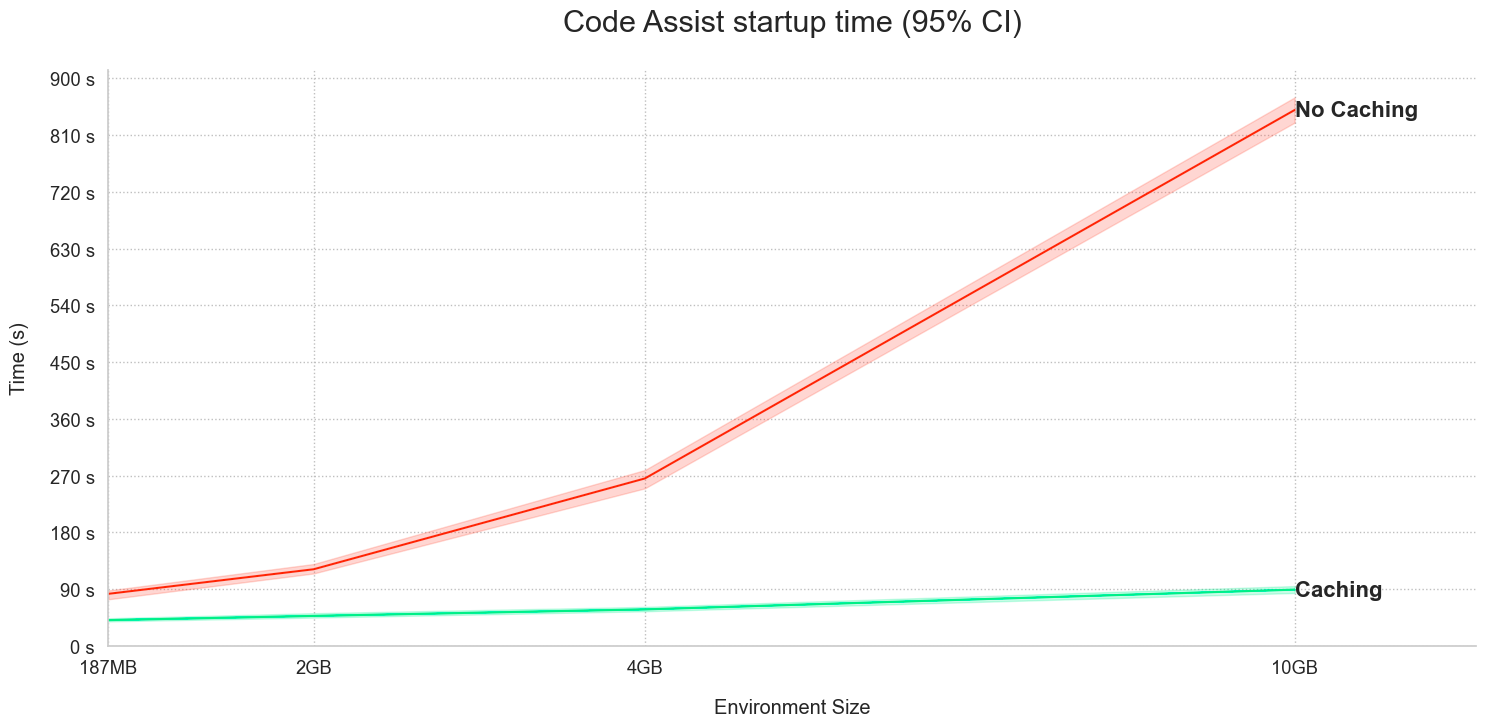
- Code Assist キャッシュを使用したチェックのパフォーマンス:
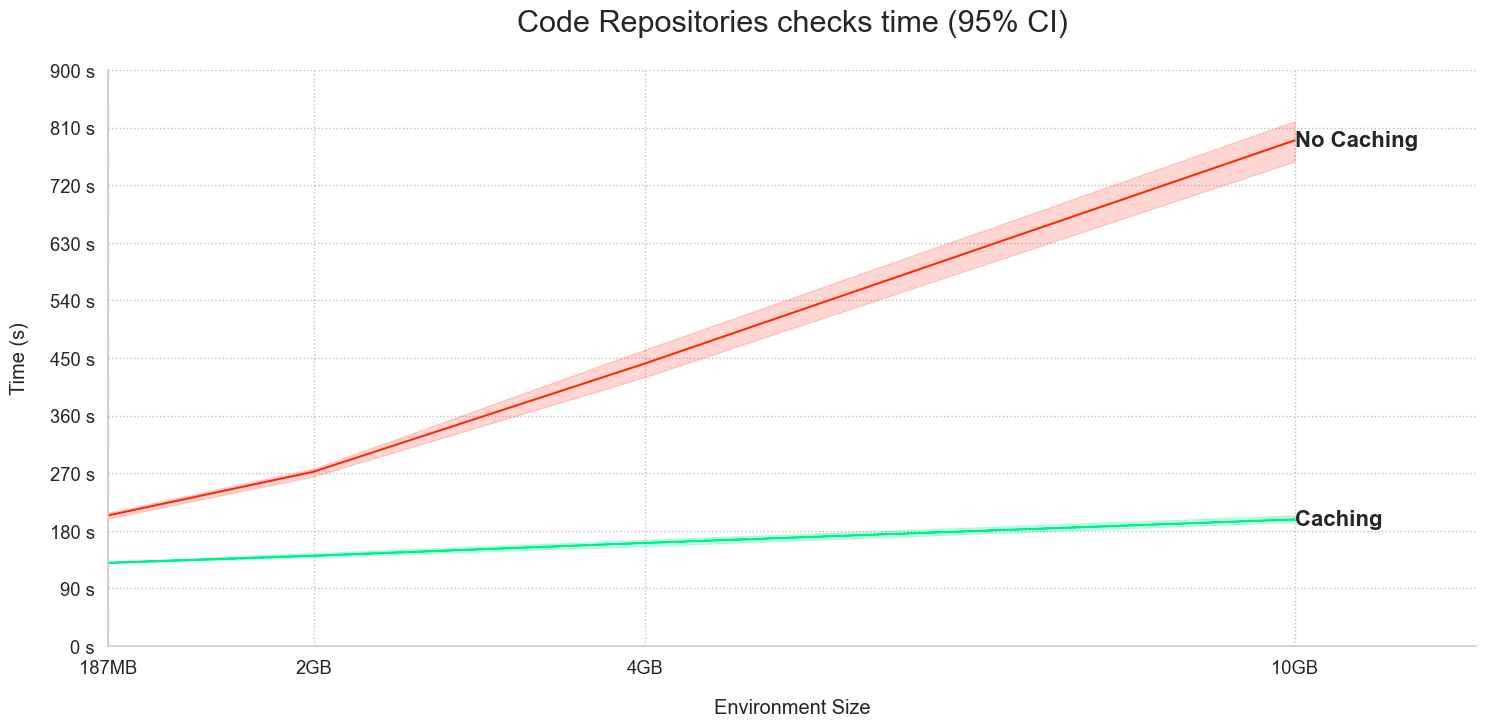
この機能は、現在、Task Runner を使用して依存関係をインストールする場合には利用できません。
ライトウェイトトランスフォームの新しい拡張機能
公開日:2024-02-01
ライトウェイトトランスフォームは、さまざまなデータ処理エンジンや、独自のコンテナ(BYOC)ワークフローをサポートしています。
ライトウェイトトランスフォームは、速さに加えて、任意のデータ処理ソリューションに簡単に接続できます。Pandas や Polars だけでなく、DuckDB や Ibis、DataFusion、cuDF など、Arrow や Parquet といった業界標準のデータ形式に依存するデータ処理エンジンと、Foundry データセットを素早く統合するための新しい API セットが導入されました。 新しい API は、ニーズに基づいて選択したエンジンでトランスフォームを実行するための追加オプションを提供します。Spark トランスフォームとは対照的に、@lightweight トランスフォームを介したこれらのシステムとの統合では、シリアル化およびデシリアル化のオーバーヘッドが発生しません。 たとえば、以下のスニペットは、ライトウェイト API を使用して Apache DataFusion と統合する方法を示しています:
Copied!1 2 3 4 5 6 7 8 9 10 11 12 13@lightweight @transform(my_input=Input('/input'), my_output=Output("/output")) def my_datafusion_transform(my_input, my_output): # データフュージョンのセッションコンテキストを作成 ctx = datafusion.SessionContext() # parquetファイルを読み込んでテーブルを作成 table = ctx.read_parquet(my_input.path()) # テーブルから"name"カラムが"John"で始まる行をフィルタリングして、Arrow形式のテーブルに変換し、出力に書き込む my_output.write_table( table .filter(starts_with(col("name"), literal("John"))) .to_arrow_table() )
さらに、Lightweight transformsでは、Foundryに任意の環境を持ち込み、以前はサポートされていなかった実行可能ファイルを実行できるBYOCワークフローがサポートされています。次のコードスニペットは、COBOLプログラムをコンパイルしてデータを生成する方法を示しています:
Copied!1 2 3 4 5 6 7 8 9 10 11 12 13@lightweight(container_image='my-image', container_tag='0.0.1') @transform(my_output=Output('my_output')) def compile_cobol_data_generator(my_output): """Condaを通じて得るのが難しい依存関係を持つことができることを示します。""" # Cobolプログラムをコンパイルします # (srcフォルダーからのすべてのものは $USER_WORKING_DIR/user_code で利用可能です) os.system("cobc -x -free -o data_generator $USER_WORKING_DIR/user_code/resources/data_generator.cbl") # プログラムを実行してdata.csvを作成し、データを入力します os.system('$USER_WORKING_DIR/data_generator') # 結果をFoundryに保存します my_output.write_table(pd.read_csv('data.csv'))
上記の2つの例の詳細な解説は、軽量な例をご覧ください。さらに、Reference Resources マーケットプレイスストアの Lightweight examples 製品にも追加の例があります。
新しい Lightweight API の全機能を使用するには、リポジトリを最新バージョンにアップグレードし、最新バージョンの foundry-transforms-lib-python をインストールしてください。詳細は、ドキュメンテーションをご覧ください。
SMB コネクター [Beta] の紹介
公開日:2024年2月1日
SMB コネクター [Beta]を使用すると、Server Message Block (SMB) ファイル共有に接続し、ファイルを Palantir プラットフォームに取り込むことができます。SMB ファイル共有の一般的な例には、Windows File Server、Samba File Server、およびほとんどの商用 NAS デバイスが含まれます。
これまで、SMB ファイル共有に接続するための推奨パターンは、共有を Foundry Agent's サーバーのディレクトリとしてマウントし、その後 Directory Connector を使用してファイルを取り込むことでした。古いパターンを使用している方は、新しい SMB コネクターに移行することをお勧めします。
ファイルシステムのマウントに対する SMB コネクターの利点:
- エージェントへの SSH アクセスが不要
- 直接接続として実行可能
- エージェントサーバー上に資格情報をプレーンテキストとして保存しない
- サーバー再起動時にも継続可能
詳細については、パブリックドキュメンテーションの Server Message Block (SMB) [Beta] をご覧ください。
追加のハイライト
モデル統合 | モデリング
公開日:2024年2月22日
モデリングに Python 3.9 サポートを追加 | モデリングでは Python 3.9 のサポートを導入し、ユーザーが Python 3.9 の最新機能と強化を活用し、Foundry 内でのモデルの作成と管理をさらに改善することが可能になりました。
アプリ構築 | Workshop
公開日:2024年2月22日
画像注釈ウィジェットが一般利用可能に | Workshop の画像注釈ウィジェットが一般利用可能となり、ユーザーはメディア URL やメディア参照プロパティを介して画像を表示し、関心領域をマーキングすることで注釈を作成できるようになりました。注釈は、注釈オブジェクトの作成、変更、または削除のアクションパラメーターとして簡単に参照でき、1つの画像あたり最大1000の注釈をサポートしています。このウィジェットは、注釈の色付けや注釈作成時のイベントトリガーのオプション設定も提供しています。詳細を学ぶ
アプリ構築 | Workshop
公開日:2024年2月22日
マークダウンのオブジェクト参照:一般利用可能 | Workshop 内の Markdown ウィジェットには、オブジェクト参照が含まれており、ユーザーはテキストにオブジェクトをリンクし、オンクリックイベントを設定できます。このアップデートにより、オントロジーの権威あるオブジェクトにそれを接続することで、書かれたまたは AI によって生成されたコンテンツの信頼性が向上します。オブジェクト参照のカスタムレンダリングは、リスト、バッククォート、テーブルなどの標準的なマークダウン機能と互換性があります。ドキュメンテーションで詳細を見つける

データ統合 | コードリポジトリ
公開日:2024年2月22日
コードリポジトリの TypeScript 関数のデバッグ機能強化 | コードリポジトリでは、TypeScript 関数のデバッグ機能が強化されました。新しい TypeScript Functions Debugger ツールを使用すると、リアルタイムでユニットテストを調査したり、実行を一時停止するブレークポイントを設定したり、関数とライブラリの理解を深めることができます。この機能の使用方法については、ブレークポイントの設定ドキュメンテーションを参照してください。
分析 | Quiver
公開日:2024年2月22日
Quiver で Duration Unit パラメーターを作成 | Quiver では、ユーザーが含めたいまたは除外したい持続時間単位を指定できる持続時間単位パラメーターの作成がサポートされています。設定プロセスは他の Quiver パラメーター設定と一貫しており、シームレスなユーザーエクスペリエンスを保証しています。
分析 | Notepad
公開日:2024年2月15日
テンプレートのソーティング機能強化 | Notepadテンプレートには、各行またはセクションジェネレーターに Sorting 設定フィールドが含まれています。この新機能により、ユーザーは、オブジェクトプロパティ値によってこれらのジェネレーターの出力をソートすることができ、ケース感度や昇順または降順といった追加の設定オプションを提供します。テンプレートからNotepadが生成されると、生成された行とセクションは設定されたプロパティに従ってソートされ、より整理され、カスタマイズ可能なユーザーエクスペリエンスを提供します。
セキュリティ | プロジェクト
公開日:2024年2月15日
パーミッションチェックの強化 | データフロー アプリケーションでは、オブジェクトタイプとオントロジーアクションのパーミッションチェックが強化されています。ユーザーは、オブジェクトタイプまたはそのタイプ内のオブジェクトを表示できるかどうかを確認できます。上流データソースからの制限も表示されます。また、ユーザーは、アクションの表示と提出の許可があるかどうか、および潜在的な提出制限があるかどうかを確認できます。
セキュリティ | チェックポイント
公開日:2024年2月13日
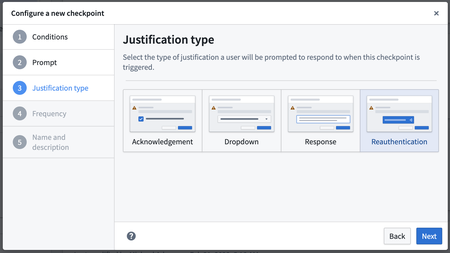
チェックポイントでの再認証理由がサポートされています | チェックポイントには、承認、フリーテキストの回答、ドロップダウン選択と並んで、再認証が 理由のタイプとして含まれています。この機能により、ユーザーは、プラットフォームでの再認証により、敏感なアクションを実行する際のチェックポイントを正当化できます。再認証が必要なチェックポイントに遭遇した場合、ユーザーは別のウィンドウで設定された Identity Provider (IdP) で再認証するように求められます。再認証プロセスが完了すると、ユーザーは意図したアクションを進めることができます。この再認証の理由の記録は、認証されたユーザーが チェックポイントアプリケーションでレビューできるようになります。再認証の理由は、ログインとスコープセッション選択タイプを除くすべての チェックポイントタイプと互換性があります。この正当化を使用してチェックポイントを作成する方法については、チェックポイントのドキュメンテーションを参照してください。
分析 | Quiver
公開日:2024年2月13日
Quiver 時系列チャート表示セクション | Quiver 時系列チャートエディターに Axes Options セクションを追加し、Y-Axes Compression エディターの名前を変更します。
データ統合 | データフロー
公開日:2024年2月13日
データフローのパーミッションチェック強化 | データフロー アプリケーションには、オブジェクトタイプとアクションのパーミッションチェックが強化されています。ユーザーは、自分がオブジェクトタイプにアクセスできるかどうか、上流データソースからの制限があるかどうかを確認できます。また、ユーザーは、アクションを表示または提出できるかどうか、提出制限があるかどうかを確認できます。他のユーザーの権限を表示するには、ユーザーはユーザー、基礎となるオブジェクトタイプ、アクション、および元データセットへのアクセスが必要です。
分析 | Contour
公開日:2024年2月13日
より大きなスケールでのパラメータークロスフィルタリングの強化 | Contour のパラメータークロスフィルタリングは、より大きなスケールを処理できるように大幅に改善されました。この強化により、パラメーター値が別のパラメーターによってフィルター処理されるときにカーディナリティ制限に達する可能性が減少します。ユーザーはパラメーターフィルタリンググループを作成し、数値パラメーターを編集または操作する際に、パラメーターの推奨値とのよりシームレスな対話を体験できるようになります。
モデル統合 | モデリング
公開日:2024年2月13日
モデルアセット自動シリアライゼーション | palantir_models パッケージは、モデル作成物の自動シリアライゼーションとデシリアライゼーションのデフォルトメソッドを含むように更新されました。モデルアダプターに新しい auto_serialize アノテーションを使用すると、モデルアダプターに save() と load() メソッドを手動で書く必要がなくなります。
アプリ構築 | Ontology SDK
公開日:2024年2月13日
Developer Console でのアプリケーション検索が利用可能 | ユーザーは Developer Console でアプリケーションを検索することができ、特定のアプリケーションを見つけてアクセスするためのより効率的な方法を提供します。
分析 | Quiver
公開日:2024年2月13日
Quiver で新しい Boolean フィルター変換 | Quiver では、Transform Tables の新しい Boolean 比較変換が2つサポートされており、ユーザーは Boolean 列値に基づいて行を比較し、フィルター処理することができます。
Foundry Advanced Search
公開日:2024-02-07
高度な検索機能の強化 | Advanced Search は、見つけにくいリソースを探すための Foundry の包括的で全画面表示の QuickSearch の拡張機能です。Advanced Search には、AI プラットフォームで動作するクエリのサポート、クエリの共有に便利なコピーペースト、および幅広い検索フィルタリングが含まれています。
セキュリティ | プロジェクト
公開日:2024-02-07
データマーキング権限のアクセスリクエストボタン追加 | データやファイルのマーキングが欠けているために権限の行き詰まりに直面したユーザーは、Approvals アプリケーションを使用して、プラットフォーム内で欠けているマーキングにアクセスするためのリクエストを送信できるようになりました。Approvals の詳細については、Approvalsのドキュメントを参照してください。
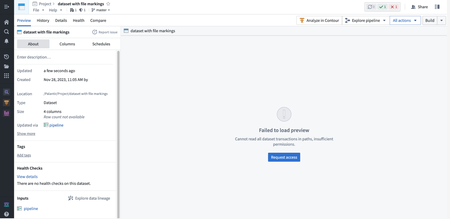
アプリビルディング | Workshop
公開日:2024-02-06
Workshop でのセマンティック検索の設定が簡単に | Workshop モジュールでのセマンティック検索のサポートがより簡単になりました。以前は、Workshop ビルダーは、ベクトル埋め込みプロパティを持つオブジェクトの上にセマンティック検索を行うために、カスタムの Typescript 関数を作成する必要がありました。現在では、Workshop の Object Set Definition パネルが、フロントエンドでのセマンティック検索フィルタリングをクリック数回で設定できるようになりました。
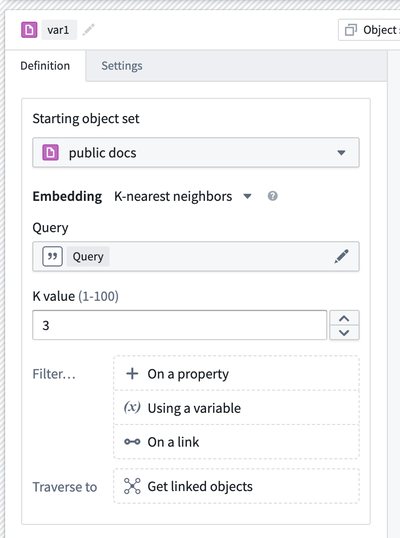
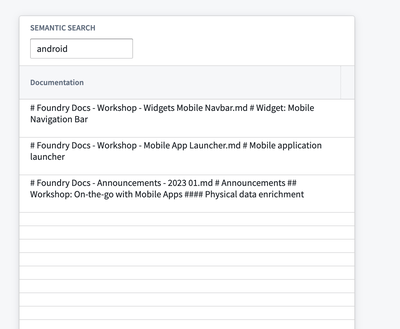
オントロジー | Vertex
公開日:2024-02-06
Vertex UI の改善 | Vertex のホームページ、レイアウト選択、タイムラインにいくつかの UI の強化が行われました。ユーザーは、より洗練されたインターフェースを体験できます。オブジェクトタイプ UI がより明確になり、レイアウト選択の視覚が改善され、タイムラインの点滅が減少しました。
オントロジー | オントロジー管理
公開日:2024-02-06
オントロジーマネージャーのプロパティタイプの強化検証 | オントロジーマネージャーには、Object Storage V1 に戻したときに無効なプロパティタイプを保存するのを防ぐための強化検証が含まれるようになりました。これにより、プロパティタイプの移行時にデータの整合性と一貫性が確保されます。
アナリティクス | Contour
公開日:2024-02-06
Top Values カスタムボード | Top Values カスタムボードを紹介します。これにより、ユーザーは、指定された数値またはパーセンテージに基づいて、列の上位または下位の値をフィルタリングして表示することができます。この新しいボードは、データを分析し、有益なレポートを作成するためのダイナミックな方法を提供します。
オントロジー | Vertex
公開日:2024-02-06
Vertex でのアノテーションの重複 | ユーザーは、Vertex で1つまたは複数の選択したアノテーションを複製できるようになりました。これにより、同様のスタイルのアノテーションを作成するのが簡単になります。
オントロジー | オントロジー管理
公開日:2024-02-06
オントロジーマネージャーのトップ 20 エラーのカスタムエラーメッセージ | オントロジーマネージャーは、ユーザーがオントロジーに変更を保存する際に最も一般的に遭遇するトップ 20 のエラーに対して、カスタムエラートーストメッセージを提供するようになりました。この強化により、より明確で具体的なエラーメッセージが提供され、ユーザーエクスペリエンスが向上します。
アナリティクス | Contour
公開日:2024-02-06
Contour: Visualization Timezone 機能の導入 | Contour には、新しい分析設定である Visualization Timezone が追加されました。この機能により、ユーザーは、日付や時刻のデータがユーザーインターフェースに表示される方法を決定できます。この設定は、分析内のすべてのボードに影響を与え、ユーザーのローカルタイムゾーンまたはすべてのユーザーに固定されたタイムゾーンに設定できます。これは、ボード内のタイムゾーン選択とは別のもので、データがどのようにバケット化されるかを決定します。以前は、ボードはタイムゾーン表示に関して異なる動作をしていましたが、この新しい設定により、この動作が統一されます。新しい分析では、データがユーザーのローカルタイムゾーンで表示されるように自動的に設定されますが、既存の分析では、手動で視覚化タイムゾーンを選択する必要があります。
オントロジー | オントロジー管理
公開日:2024-02-06
MDO エクスポートの入力データソースの更新 | ユーザーは、オントロジーマネージャーで、複数のデータソースオブジェクト(MDO)のエクスポートタイプの入力データソースを更新できるようになりました。これにより、複数のデータソースをバックアップとして持つオブジェクトタイプの入力データセットを変更する際の柔軟性が向上します。
オントロジー | Vertex
公開日:2024-02-06
Vertex のカスタムラベル名 | ユーザーは、Vertex でカスタムラベル名を定義できるようになりました。これにより、柔軟性とパーソナライゼーションが向上します。このアップデートにより、ユーザーは、自分にとって意味のあるラベルを使用して、データの整理と管理がより簡単になります。
アナリティクス | Contour
公開日:2024-02-06
分析サブメニュー内のデータセットアクセスの拡大 | ユーザーは、分析サブメニュー内のすべてのリソースセレクタードロップダウンメニューでデータセットにアクセスできるようになりました。これにより、結合およびユニオンボードで作業する際の利便性と効率が向上します。
アプリビルディング | Workshop
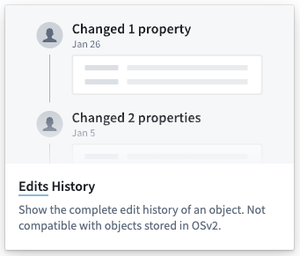
公開日:2024-02-06
Workshop: Edits History ウィジェットが利用可能に | Workshop に Edits History ウィジェットが導入されました。これにより、ユーザーはオブジェクトのプロパティに対して行われた編集を表示できます。Builder は、表示可能なプロパティのセットと、編集が表示される順序を設定できます。このウィジェットは、Objects Storage V1 を使用するオブジェクトタイプとのみ互換性がありますが、V2 のサポートは今年後半に予定されています。
データ統合 | コードリポジトリ
公開日:2024-02-06
TypeScript ユニットテストの強化デバッガー | TypeScript 関数のデバッグ機能が強化され、ユニットテストをデバッグモードで実行できるようになりました。コード全体でブレークポイントを設定し、実行プロセスをステップバイステップで確認して、バックグラウンドでの動作をより理解することができます。
オントロジー | オントロジー管理
公開日:2024-02-06
オントロジーマネージャーでの表示名の並べ替えの改善 | オントロジーマネージャーでは、表示名を大文字と小文字の結果を組み合わせて、より直感的に並べ替えるようになりました。以前は、大文字で始まるエンティティが小文字で始まるエンティティとは別に並べ替えられていました。新しい並べ替えの動作では、どのような文字で始まるエンティティもまとめてグループ化されます。
モデル統合 | モデリング
公開日:2024-02-06
ライブデプロイメントを関数として | ユーザーは、ライブデプロイメントを関数として公開し、新しいデプロイメントテーブルにアクセスして、より効果的な管理と組織化ができるようになりました。
アプリビルディング | Foundry Developer Console
公開日:2024-02-06
Developer Console での新しい権限ページ | Developer Console には、専用の権限ページが追加され、アプリの共有、ウェブサイトの共有、およびアプリケーションの検出を管理できるようになりました。将来的には、このページに OAuth クライアントロールの付与も移動されます。