Python functions
Python functions are currently in a beta state and may not be available on all enrollments.
You can write Python functions in Code Repositories and reuse them across Pipeline Builder and ontology-based applications like Workshop.
If you cannot manipulate your data with existing transformation options in Pipeline Builder, want to incorporate external Python libraries, or have complex logic you want to reuse across pipelines, you can create your own Python user-defined function (UDF).
Python functions also enable you to write logic that can be executed quickly for Workshop, Slate, and other ontology-based applications to empower decision-making processes.
Python functions can be reused between Workshop and Pipeline Builder as long as the input and output types are both supported. For example, objects and functions using objects as inputs or outputs are not supported in Pipeline Builder.
Author a Python function
To create a Python functions repository, first navigate to a Project in which you would like to save the repository.
Then, select New and choose Code Repository. Select Functions -> Python Functions and then Initialize repository.
Declare your function
Open the my_function.py file from the default repository template. There, you will see a function that looks like:
Copied!1 2 3 4 5from functions.api import function, String @function def my_function() -> String: return "Hello World!"
Notice that the function adheres to the following constraints:
- The function must be annotated with
@functionfrom thefunctions.apipackage to be recognized as a Python function. You may have multiple Python files with multiple functions in each file, but only the functions with this annotation will be registered as Python functions. - The function must declare the types of all of its inputs and the type of its output, either using the type from the functions API package or its corresponding Python type (see table below). For instance, the example’s output type is declared as a
stringfrom the functions API, but it may also be declared as the corresponding Python typestr.
Even if you declare the type of an argument with the API type (for example, string), your function will be passed the corresponding Python type at runtime (in this example, str).
Below is the full list of currently supported functions API types, their corresponding Python types, and whether that type can be declared using its corresponding Python type instead of the functions API type:
| Functions API type | Can declare as Python type? | Corresponding Python type |
|---|---|---|
| Array | Yes | list |
| Binary | Yes | bytes |
| Boolean | Yes | Boolean |
| Byte | No | int* |
| Date | Yes | datetime.date |
| Decimal | Yes | decimal.Decimal |
| Double | No | float* |
| Float | Yes | float |
| Integer | Yes | int |
| Long | No | int* |
| Map | Yes | dict |
| Set | Yes | set |
| Short | No | int* |
| String | Yes | string |
| Timestamp | Yes | datetime.datetime |
Although both Integer and Long correspond to the Python type int, any fields marked as int directly in your Function signature will be registered with type Integer. Therefore, we recommend using either the Integer or Long types from the API to register numerical data types instead. Similar guidelines apply to Float and Double — using the Python type float directly in your function signature will be registered as Float by default.
Another example function with inputs is shown below:
Copied!1 2 3 4 5 6from functions.api import function, Long, String, Timestamp @function def get_end_day_of_week(start_time: Timestamp, elapsed_millis: Long) -> String: # function logic here pass
As seen in the above table, this function could also be declared using only built-in Python types:
Copied!1 2 3 4 5 6 7from functions.api import function from datetime import datetime @function def get_end_day_of_week(start_time: datetime, elapsed_millis: int) -> str: # function logic here pass
Or using a combination of built-in and API types:
Copied!1 2 3 4 5 6 7from functions.api import function, Long, String from datetime import datetime @function def get_end_day_of_week(start_time: datetime, elapsed_millis: Long) -> String: # function logic here pass
Lastly, you could use custom types:
Copied!1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16from dataclasses import dataclass from functions.api import Float, Integer, String, function @dataclass class InventoryItem: """Class for keeping track of an item in inventory.""" name: String unit_price: Float quantity_on_hand: Integer = 0 def total_cost(self) -> Float: return self.unit_price * self.quantity_on_hand @function def custom_type_with_init_from_decorator(inventory_item: InventoryItem) -> Float: return inventory_item.total_cost()
Use Python libraries
If you want to use Python libraries in your code, you can either add the name of the library to the requirements → run section of the meta.yaml file:
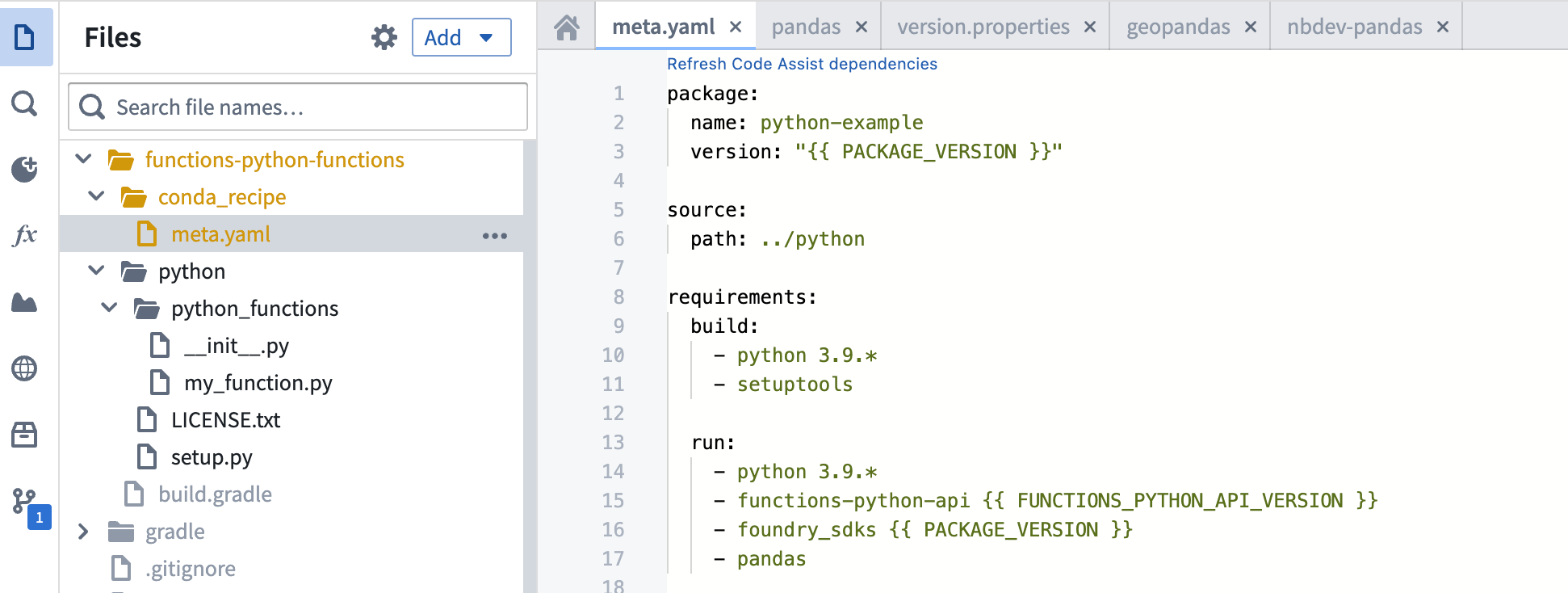
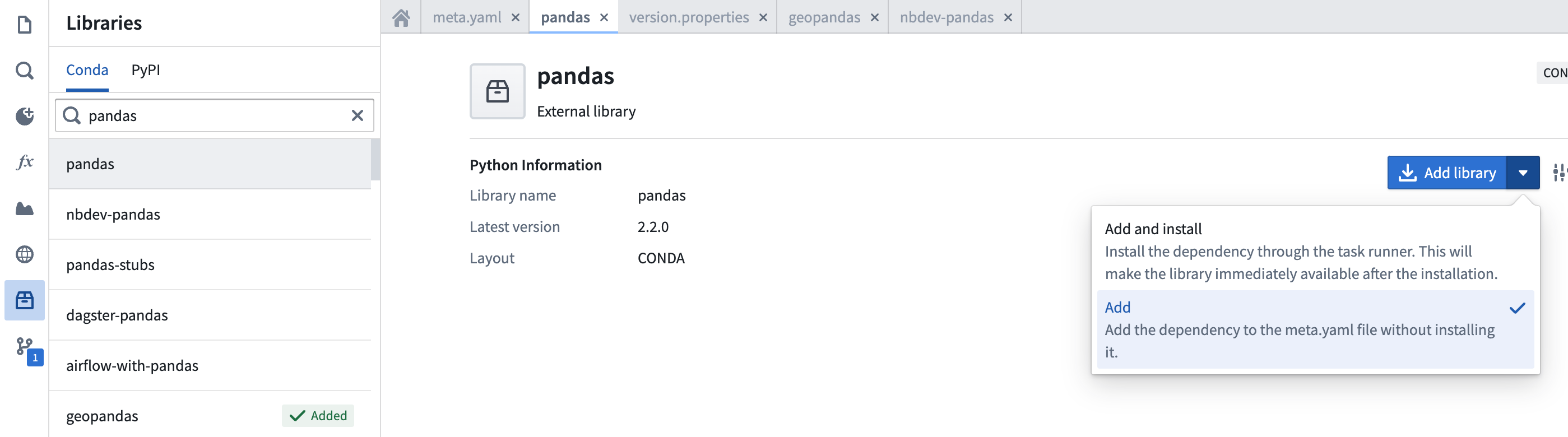
Or you can navigate to the Libraries section of the sidebar, search for the library, and select Add & install:
Release a version
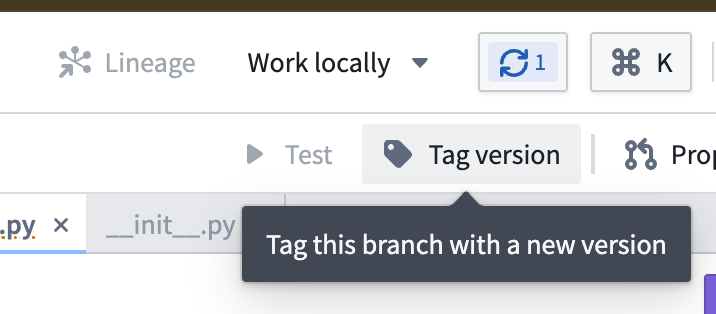
For your functions to be usable, you must first tag a version of them for release. Commit your work, then select Tag version:
Choose what you want this version of your functions to be called:
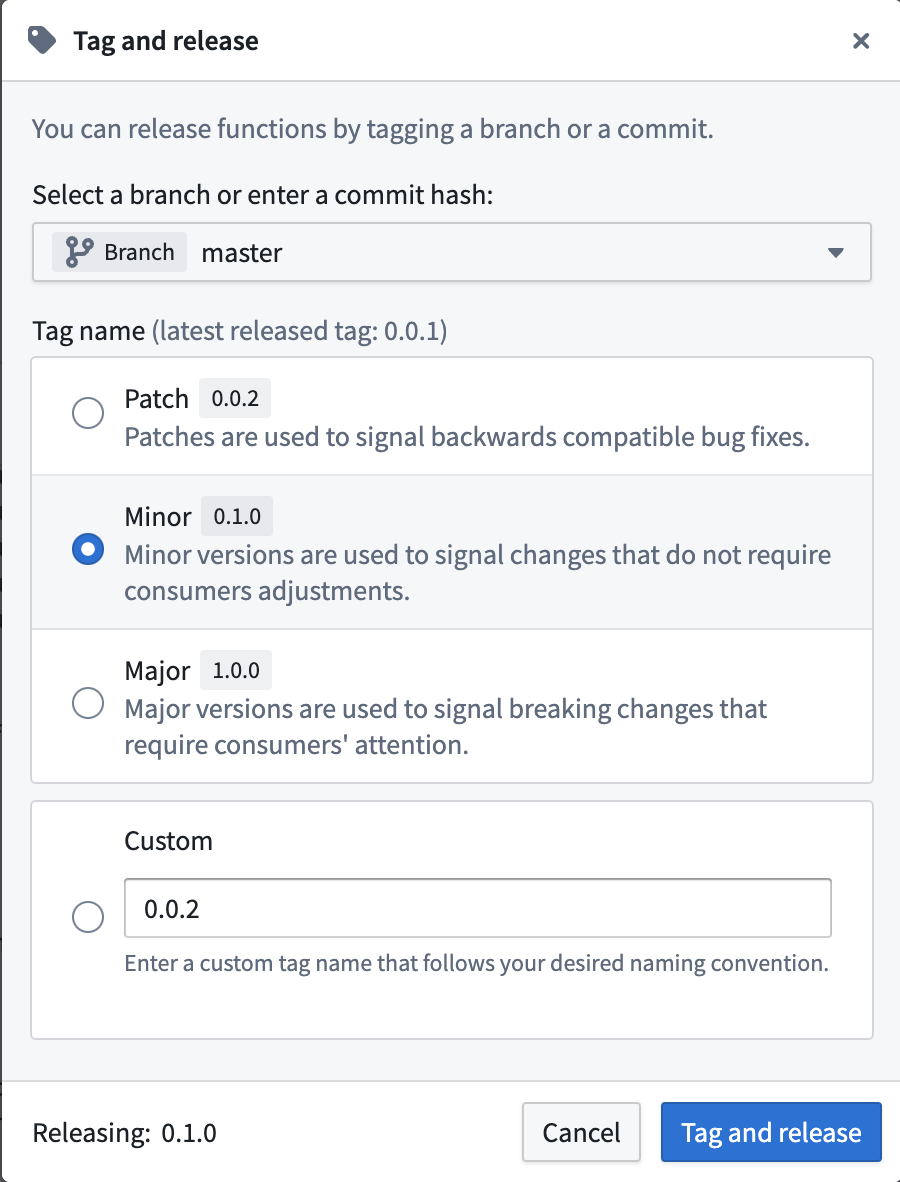
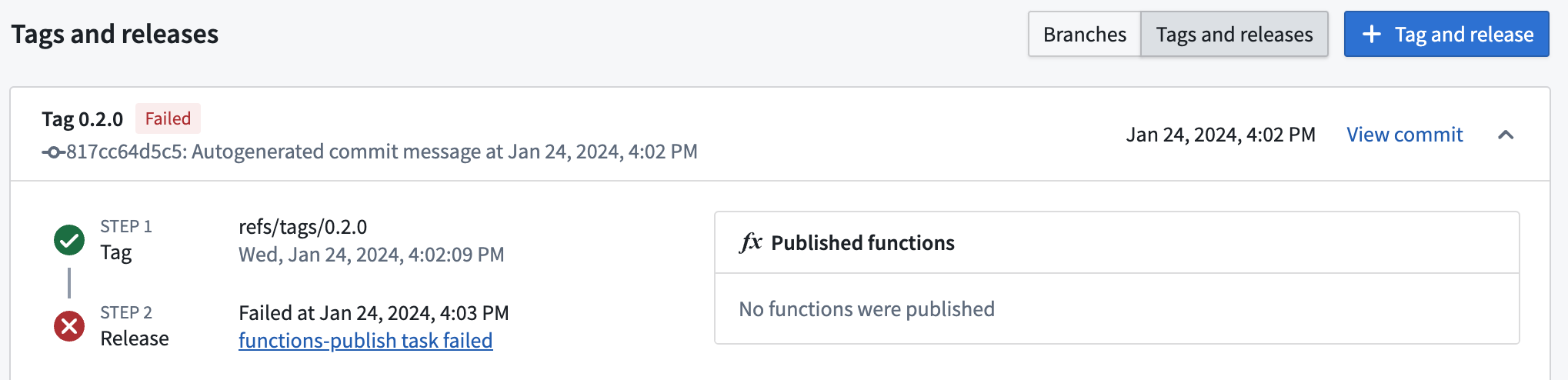
Once you select Tag and Release, select View in the pop-up to monitor the progress of the release. Alternatively, you can select the Branches tab, then select Tags and releases. If your release succeeds, you should be able to view all of the functions published here.
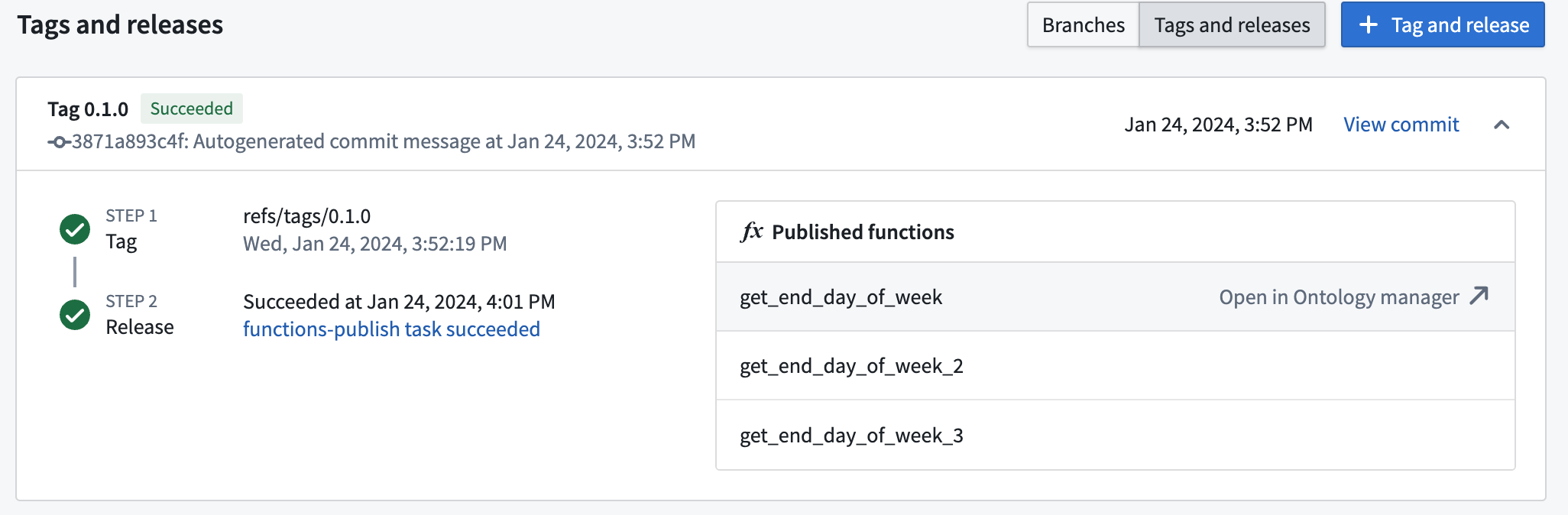
Otherwise, you can inspect the failed build to see the error that occurred.
Use Python functions in Pipeline Builder
To import your functions in Pipeline Builder, go to Reusables > User-defined functions > Import UDF.
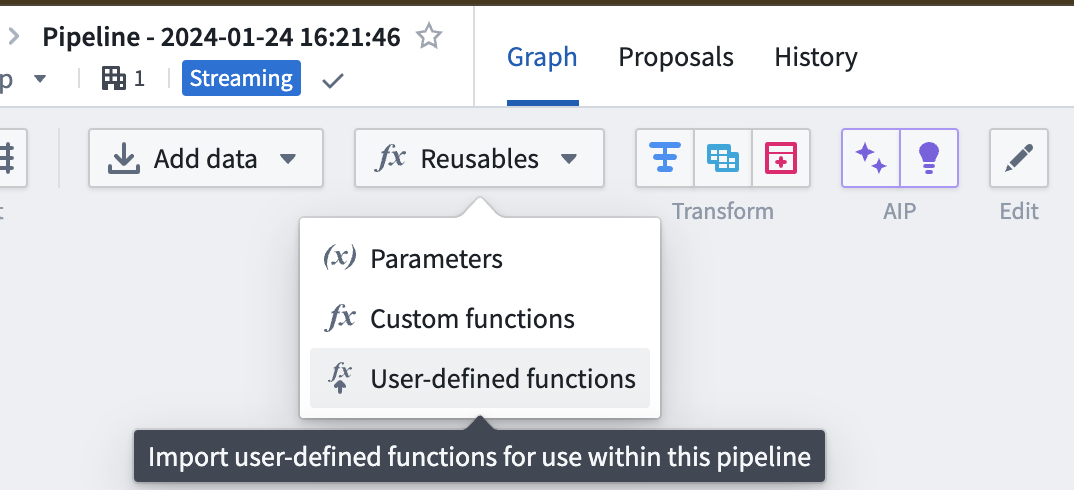
Select your function(s) from the list and select Add:
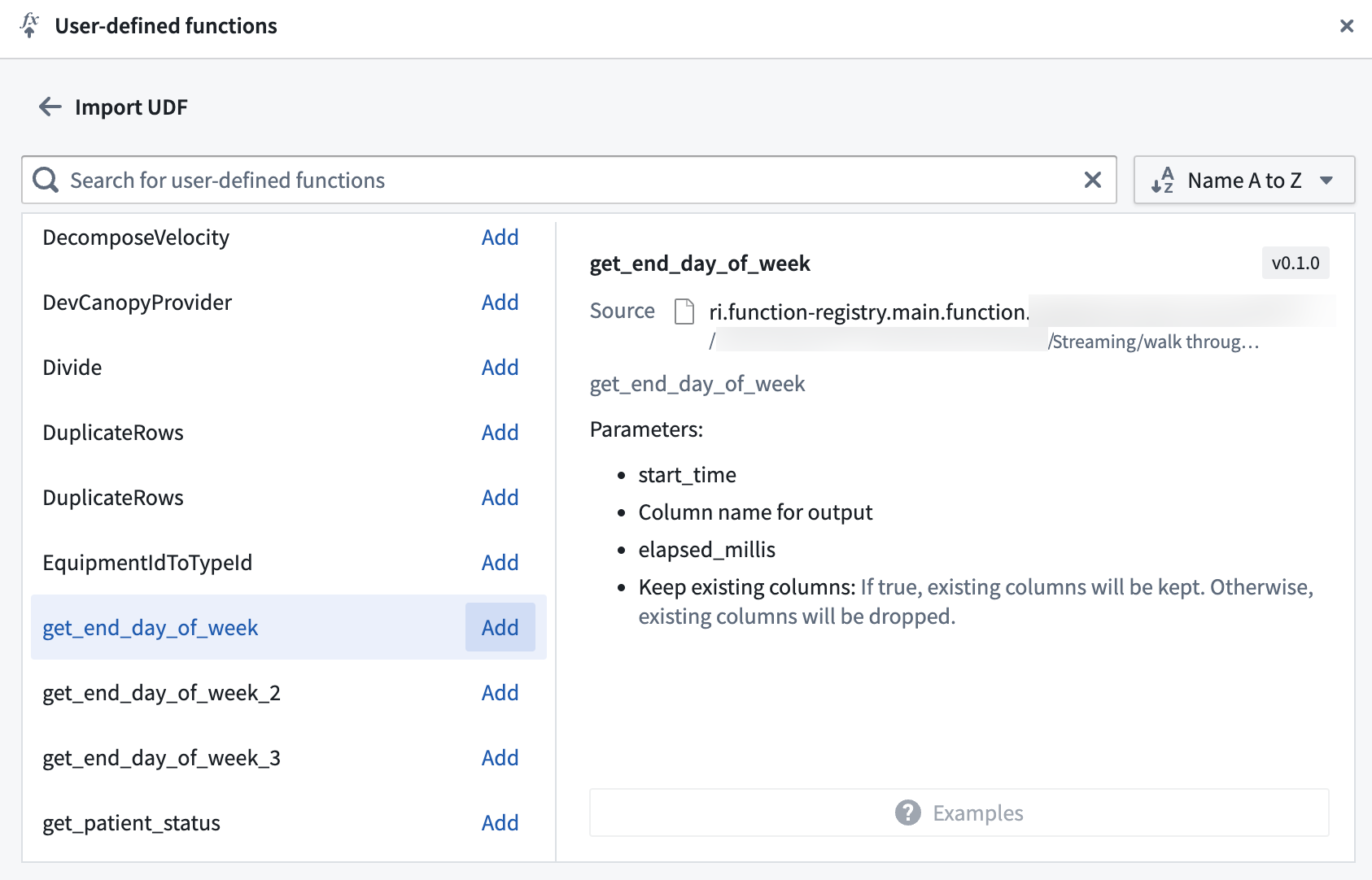
Your functions should now be visible in the transform picker alongside built-in transforms to be used in your pipeline as normal.
Use Python functions in Workshop and Ontology applications
To use your function in Workshop you will need to deploy it. From your published functions under Tags and Releases, select Open in Ontology Manager. In Ontology Manager, select the version of the function repository you want to use in applications, then select Create and start deployment.
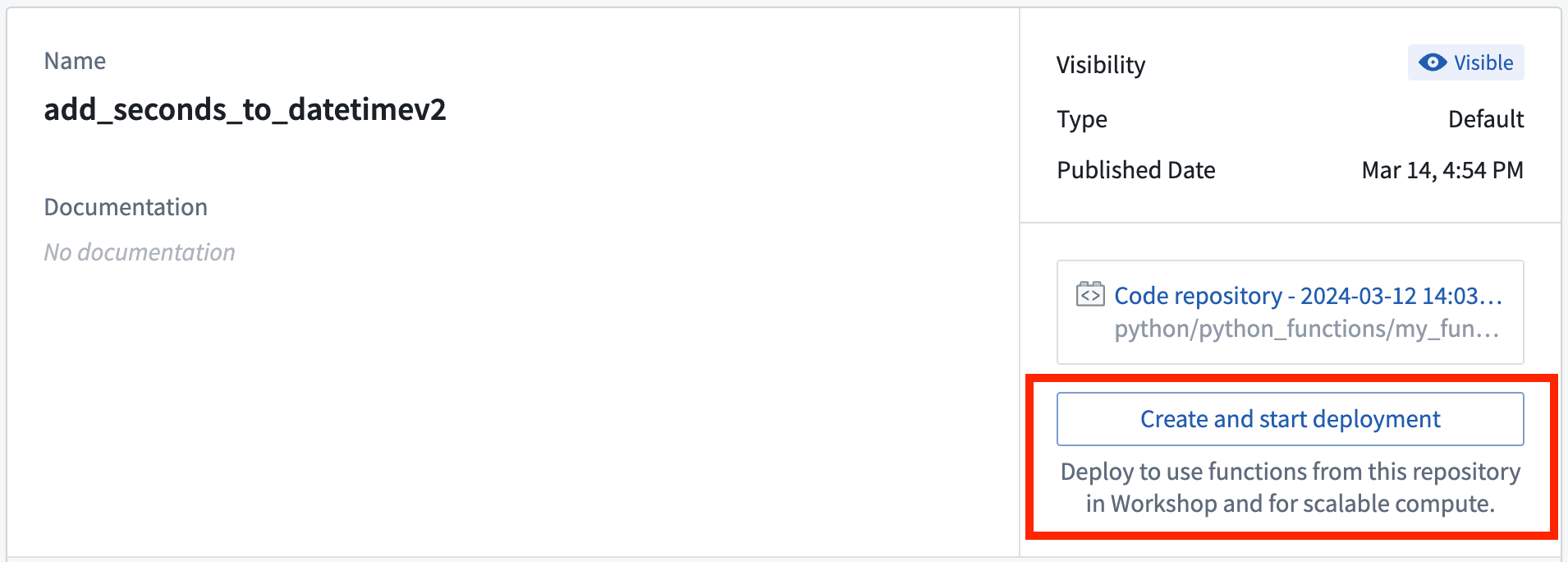
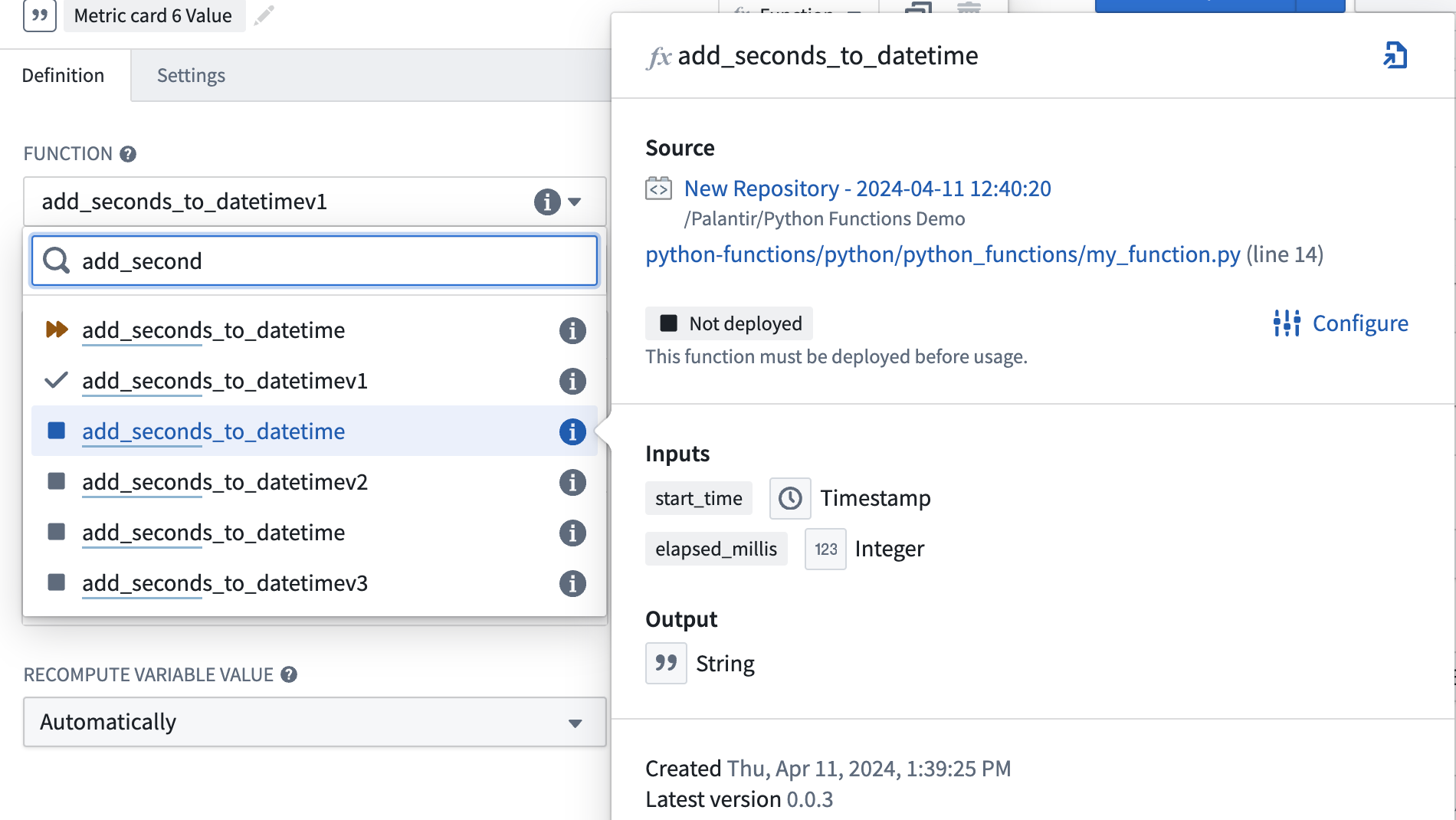
In Workshop, search for the function as usual. For functions that are deployed there will be an icon with one of three states for both the function and the function version.
- Running: This function and version can serve requests.
- Stopped: This function and version are not available. In the function picker, hover over the information icon, select Configure and then Create and start deployment to make the function available.
- Upgrading: This function and version are not available yet.
Cut a new release
Only one version of the function’s repository is hosted at a given time. To make changes to functions with no downtime, we recommend adding a new function (like function_v1) with the changes and tagging as outlined above. From your published functions, under Tags and Releases, select Open in Ontology Manager.
In Ontology Manager, select the version of the function repository you want to use in applications, then select Upgrade.
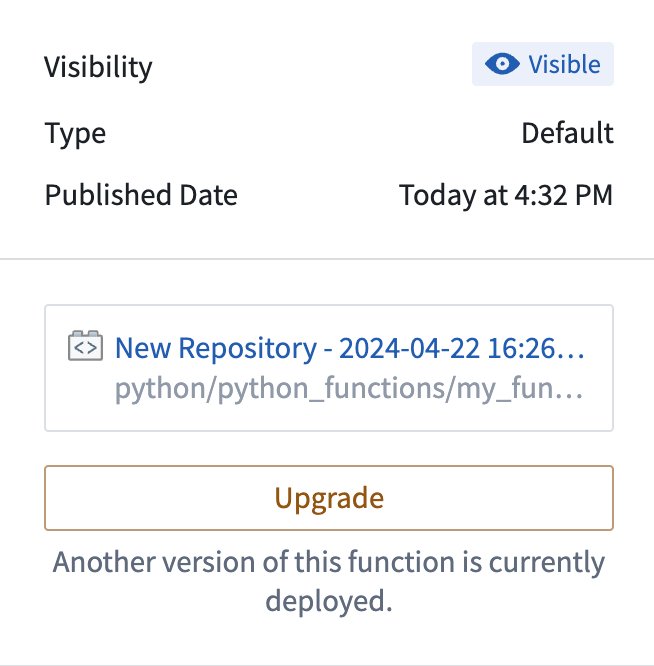
This will allow you to have function_v0 and function_v1 available at the same time while you make changes to downstream applications. When function_v0 is no longer used, you can delete the function.
Debug errors
If your function is not working as expected and you are in Workshop, first check if the issue is related to the logic or the responsiveness of the function. If there is an issue with the logic, inspect the source code in the backing code repository. If there is an issue with the function being unresponsive or throwing an error, follow the steps below.
- Check if the version you have selected is currently running in the function selector dropdown.
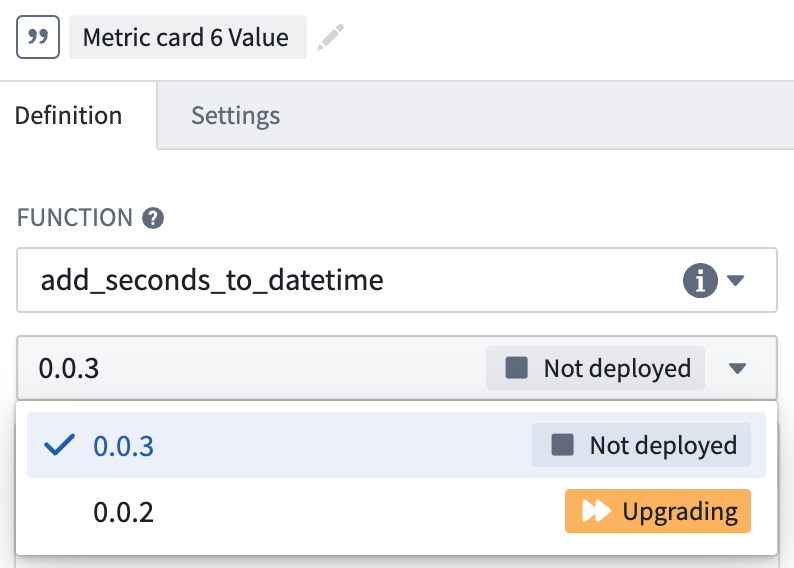
- If the function is
Not deployedorUpgrading, hover over the function’s information icon and select Configure. This will take you to Ontology Manager where you can select Start Deployment to get your function running again.
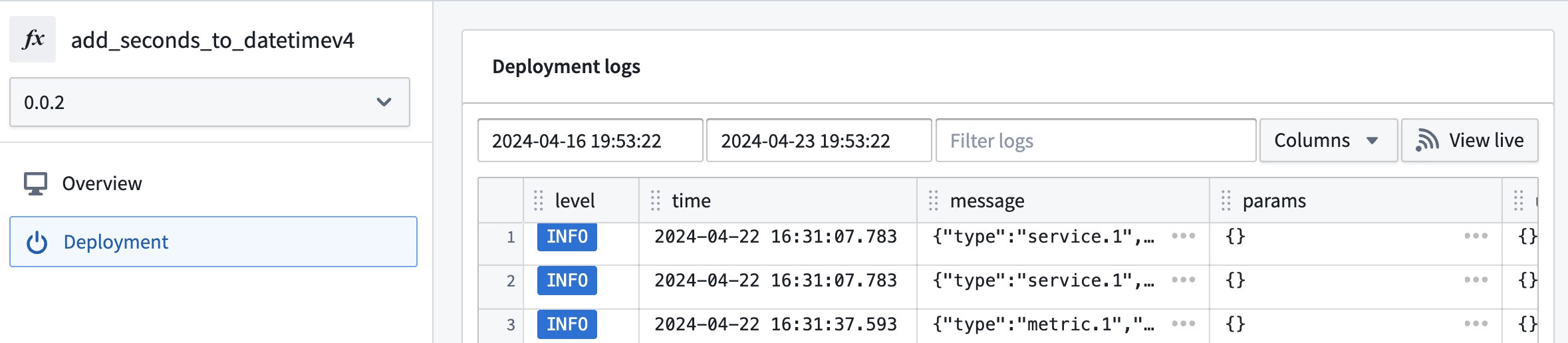
- If your function is Running or you need more information about the deployment’s behavior, select Deployment from the left panel in Ontology Manager to see detailed logs. SLS logs are also available if you select View live.
Resource allocation for deployed functions
Deploying a function allocates a cluster of nodes that serve all functions from your repository for a given version.
- The cluster will dynamically allocate resources based on load which allows you to handle concurrent requests with better performance.
- Deployed functions will typically incur higher costs than regular functions. Measures, like dynamic scaling, are taken to minimize these costs, but deployed functions are best suited to applications with higher load as the cost of running the cluster is amortized across usage.